
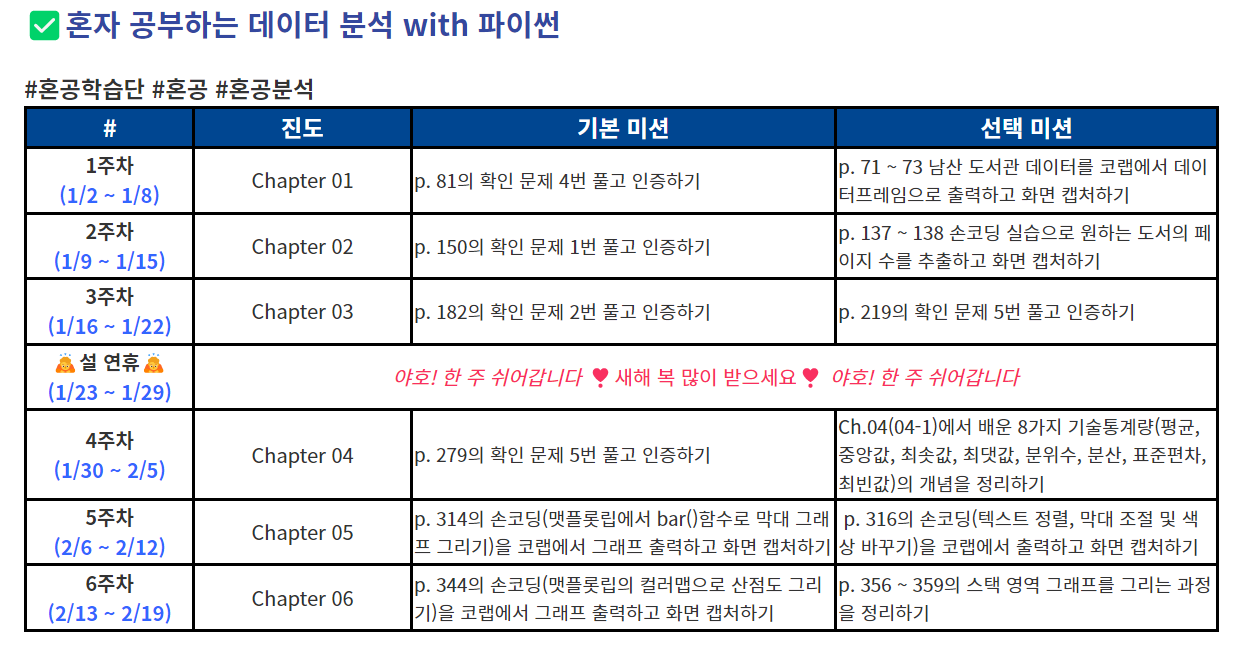
혼공학습단 커리큘럼
데이터 분석
- 유용한 정보를 발견하고 결론을 유추하거나, 의사 결정을 돕기위해 데이터를 조사, 정제, 변환, 모델링하는 과정
- 다양한 접근방법과 형태로 여러 비즈니스와 과학 분야에서 사용
- 현대 사회에서는 비즈니스 결정을 과학적으로 내리기 위한 도구로 사용
- 올바른 의사 결정을 돕기 위한 통찰을 제공하는데 초점을 맞춤
데이터 과학
- 통계학 데이터분석, 머신러닝, 데이터 마이닝 등을 아우르는 큰 개념
- 문제 해결을 위한 최선의 솔루션을 만드는데 초점을 맞춤
| 특징 | 데이터 분석 | 데이터 과학 |
|---|---|---|
| 범주 | 비교적 소규모 | 대규모 |
| 목표 | 의사 결정을 돕기위한 통찰을 제공 | 문제 해결을 위한 최선의 솔루션을 만드는 일 |
| 주요 기술 | 컴퓨터 과학, 통계학, 시각화 등 | 컴퓨터 과학, 통계학, 머신러닝, 인공지능 등 |
| 빅데이터 | 사용 | 사용 |
통계적인 관점의 데이터 분석
| 기술통계 | 관측이나 실험을 통해 수집한 데이터를 정량화 하거나 요약하는 기법 |
|---|---|
| 탐색적 데이터 분석 | 데이터를 시각적으로 표현하여 주요 특징을 찾고 분석하는 방법 |
| 가설검정 | 주어진 데이터를 기반으로 특정 가정이 합당한지 평가하는 통계 방법 |
데이터 분석가의 작업 과정

파이썬 필수 패키지
| 넘파이 | 고성능 과학 계산과 다차원 배열을 위한 패키지 |
|---|---|
| 판다스 | 엑셀의 시트처럼 숫자와 문자를 섞어 표 형태로 저장할 수 있는 데이터 프레임 |
| 맷플롯립 | 데이터 시각화를 위한 패키지 |
| 사이파이 | 수학과 과학 계산 전문 패키지로 미분, 적분, 확률, 선형대수, 최적화 등 |
| 사이킷런 | 머신러닝 패키지로 넘파이와 사이파이에 크게 의존 |
데이터 마이닝
- 데이터에서 패턴 혹은 지식을 추출하는 작업
- 추출된 지식, 패턴은 사람이 의사 결정을 내리기 위해 활용
머신러닝
- 데이터에서 자동으로 규칙을 학습하여 문제를 해결하는 소프트웨어를 만드는 기술
- 규칙이나 패턴을 사용하는 주체가 사람이 아닌 컴퓨터
- 머신러닝으로 학습한 소프트웨어 객체를 모델이라고 부름
공개 데이터 세트 사이트
- CSV, Excel, API로 데이터를 제공
국내 사이트
이름 주소 공공데이터포털 https://www.data.go.kr 통합 데이터 지도 https://www.bigdata-map.kr AI 허브 https://aihub.or.kr 국가통계포털 https://kosis.kr 해외 사이트
이름 주소 구글 데이터 세트 https://datasetsearch.research.google.com 캐글 데이터 세트 https://www.kaggle.com/datasets 위키피디아 머신러닝 데이터 세트 https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research 아마존 웹서비스 오픈 데이터 https://registry.opendata.aws UCI 머신러닝 데이터 저장소 https://archive.ics.uci.edu/ml 온라인 포럼
코랩에 데이터 다운로드 하기
- gdown 패키지 사용
CSV 파일 출력
with open('파일명.csv') as f:
printf(f.readline())
// 에러출력
UnicodeDecodeError Traceback (most recent call last)
<ipython-input-4-8ccda7bd1ec6> in <module>
1 with open('남산도서관 장서 대출목록 (2021년 04월).csv') as f:
----> 2 print(f.readline())
/usr/lib/python3.8/codecs.py in decode(self, input, final)
320 # decode input (taking the buffer into account)
321 data = self.buffer + input
--> 322 (result, consumed) = self._buffer_decode(data, self.errors, final)
323 # keep undecoded input until the next call
324 self.buffer = data[consumed:]
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 0: invalid start byte에러발생 이유
- 파이썬의 open() 함수는 기본적으로 텍스트 파일이 UTF-8 형식을 사용한다고 가정
- 대부분의 한글 텍스트는 EUC-KR 형식을 사용
- 따라서 파일의 인코딩 형식 확인 필요
import chardet with open('파일명.csv', mode='rb') as f: d = f.readline() print(chardet.detect(d)) // 출력 {'encoding': 'EUC-KR', 'confidence': 0.99, 'language': 'Korean'}
인코딩 형식 지정하기
open 함수의 인코딩 매개변수를 읽고자하는 파일의 형식으로 맞춰준다
with open('파일명.csv', encoding='EUC-KR) as f:
print("첫번째 -",f.readline())
print("두번째 -",f.readline())
// 출력
첫번째 - 번호,도서명,저자,출판사,발행년도,ISBN,세트 ISBN,부가기호,권,주제분류번호,도서권수,대출건수,등록일자,
두번째 - "1","인공지능과 흙","김동훈 지음","민음사","2021","9788937444319","","","","","1","0","2021-03-19",맥에서 작성된 한글 파일
리눅스, 윈도우는 한글을 표현할때 NFC를 사용하지만 맥은 NFD를 사용 때문에 NFC방식으로 변경해주어야함
import os
import glob
import unicodedata
for filename in glob.glob('*.csv'):
nfc_cilename = unicodedata.normalize('NFC', filename)
os.rename(filename, nfc_filename)데이터 프레임 다루기
판다스
판다스는 csv 파일을 읽어 데이터프레임 이라는 표 형식 데이터로 저장
- 데이터 프레임
- 표 형식 데이터는 행과 열로 구성된 데이터 구조를 의미 하며 2차원 배열과 비슷
- 열마다 다른 테이터 타입을 사용할 수 있으며 같은 열에 있는 데이터는 모두 같은 종류여야 함, 한 열을 따로 선택하면 시리즈 객체가 될 수 있음
- 시리즈 1차원 배열과 매우 비슷하며 시리즈에 담긴 데이터는 모두 동일한 종류여야 함, 예로 모두 정수 혹은 문자열
CSV 파일 읽기
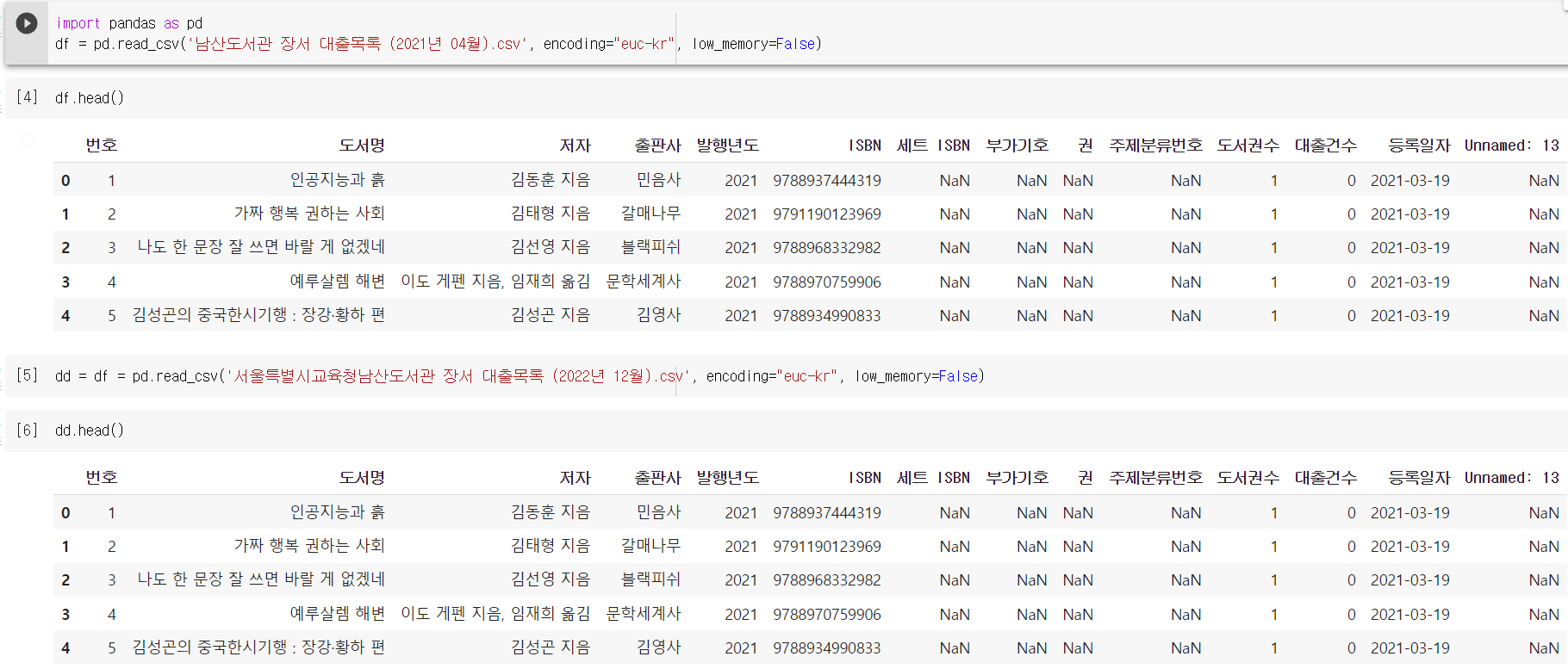
import pandas as pd
df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding="euc-kr")
// 에러출력
/usr/local/lib/python3.8/dist-packages/IPython/core/interactiveshell.py:3326: DtypeWarning: Columns (5,6,9) have mixed types.Specify dtype option on import or set low_memory=False.
exec(code_obj, self.user_global_ns, self.user_ns)에러발생 이유
- 판다스는 데이터를 읽을때 자동으로 타입을 인식하는데 메모리를 효율적으로 사용하기 위해 CSV를 조금씩 나누어서 읽음, 이때 자동으로 파악한 데이터 타입이 달라지면 경고가 발생
- 파일을 한번에 읽을 수 있게 지정
df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding="euc-kr", low_memory=False) - 혹은 타입을 문자열로 지정
df = pd.read_csv('남산도서관 장서 대출목록 (2021년 04월).csv', encoding="euc-kr", dtype={'ISBN': str, '세트 ISBN': str, '주제분류번호': str})
첫행에 열이 없는 경우
df = pd.read_csv('파일명.csv', header=None, name=[열이름 리스트])CSV에 이미 인덱스가 있는 경우
df = pd.read_csv('파일명.csv', index_col="인덱스열 번호", low_memory=False)데이터프레임을 엑셀로 저장
ns_df.to_excel('파일명.csv', index=False)
// 한글이 있는경우 아래를 사용
pip install xlsxwriter
ns_df.to_excel('파일명.csv', index=False, engine='xlsxwriter')미션
- 필수미션

- 선택미션

업무하면서 쌓인 노하우를 정리하는 블로그🚀 풀스택 개발자를 지향하고 있습니다👻