데이터 정제
데이터에서 손상되거나 부정확한 부분을 수정하고, 불필요한 데이터를 삭제하거나 불완전한 값을 교체하는 등의 작업
- 데이터 랭글링 / 데이터 먼징 데이터를 분석 목적에 맞에 변환하는 작업
데이터 다운로드 및 데이터 프레임 얻기
import gdown
gdown.download('https://bit.ly/3RhoNho', 'ns_202104.csv', quiet=False)
import pandas as pd
ns_df = pd.read_csv('ns_202104.csv', low_memory=False)
ns_df.head()
열 삭제하기
마지막 Unnamed: 13 열 삭제
loc() 메서드
ns_book = ns_df.loc[:, '번호':'등록일자']
ns_book.head()불리언 배열 : 특정 열만 선택하기
# columns 확인
ns_df.columns
# 인덱스 클래스: 인덱스에 있는 열을 돌면서 비교함
selected_columns = ns_df.columns!= 'Unnamed: 13'
# Ture인 열의 모든 행을 선택
selected_columns = ns_df.columns!= '부가기호'
ns_book = ns_df.loc[:, selected_columns]
ns_book.head()
drop() 메서드 : 열 삭제
# axis가 0 이면 행삭제, 1이면 열삭제
ns_book = ns_df.drop('Unnamed: 13', axis=1)
# 여러개의 열 삭제
ns_book = ns_df.drop(['Unnamed: 13', '부가기호'], axis=1)
ns_book.head()
# 열 삭제 후 데이터 프레임에 덮어쓰기
ns_book.drop('주제분류번호', axis=1, inplace=True)dropna() 메서드 : NaN이 포함된 행이나 열 삭제
# NaN이 하나 이상 포함된 열이나 행 삭제
ns_book = ns_df.dropna(axis=1)
# 모든 값이 NaN 인 열을 삭제
ns_book = ns_df.dropna(axis=1, how='all')행 삭제하기
drop() 메서드 : 행 삭제
# 인덱스 0~1까지 2개의 행 삭제
ns_book2 = ns_book.drop([0,1])[]연산자와 슬라이싱
# 인덱스가 0~1까지를 제외한 나머지 선택
ns_book2 = ns_book[2:]💡 의문 : 책에서 loc 메서드에 슬라이싱을 사용하면 마지막 인덱스를 포함한다는 말이 2개의 매개변수중에 2번째 들어가는 매개변수가 포함된다는 말인지..?
[] 연산자와 불리언 배열
# 출판사가 한빛미디어 인 행만 추출
selected_rows = ns_df['출판사'] == '한빛미디어'
ns_book2 = ns_book[selected_rows]
# 조건문
ns_book2 = ns_book[ns_book['대출건수'] > 1000]중복된 행 찾기
duplicated() 메서드
처음 행을 제외한 나머지 행은 True로 그 외에 중복되지 않는 나머지 모든 행은 False로 표시한 불리언 배열을 반환
# 파이썬의 sum을 사용하면 True을 1로 인식하기때문에 행의 개수를 확인가능
sum(ns_book.duplicated())
# 특정 열을 기준으로 중복된 행 찾기
sum(ns_book.duplicated(subset=['도서명', '저자', 'ISBN']))
# 둥복된 모든 행을 True로 표시 기존엔 처음 하나만 True 였음
dup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN'], keep=False)
ns_book3 = ns_book[dup_rows]중복된 행 삭제
drop_duplicate() 메서드
duplicate 메서드와 같으며 subset, keep, inplace 매개변수를 제공
그룹별로 모으기
같은 도서의 대출건수는 하나로 합침
groupby()
by 매개변수에는 행을 합칠 때 기준이 되는 열을 지정, 기본적으로 NaN이 포함되어 있으면 해당 행을 삭제
# 특정 열의 데이터만 선택
count_df = ns_book[['도서명', '저자', 'ISBN', '권', '대출건수']]
# NaN이 포함되어 있어도 행을 삭제하지않음
group_df = count_df.groupby(by=['도서명', '저자', 'ISBN', '권'], dropna=False)
loan_count = group_df.sum()
# 혹은 아래와 같이 씀
loan_count = count_df.groupby(by=['도서명', '저자', 'ISBN', '권'], dropna=False).sum()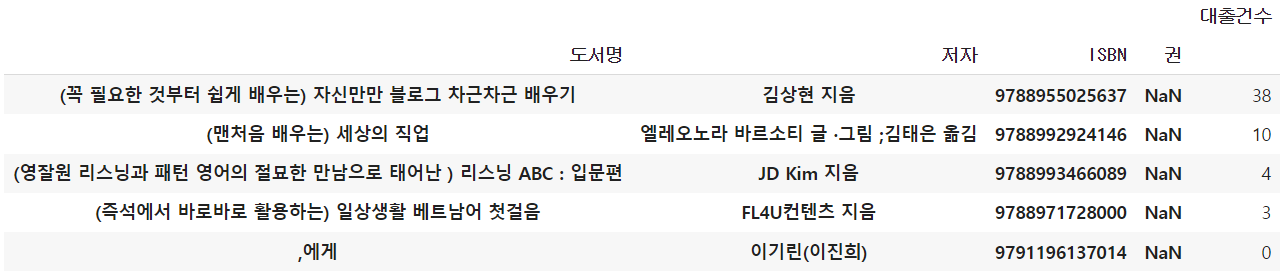
원본 데이터 업데이트 하기
원본 데이터에는 중복된 데이터가 있기 때문에 대출건수를 업데이트 하기전에 정제과정을 해야함
- duplicated() 메서드로 중복된 행을 True로 표시한 불리언 배열을 만듬
- 1에서 구한 불리얼 배열을 반전시켜 중복되지 않은 고유한 행을 True로 표시
- 2에서 구한 불리언 배열을 사용해 원본 배열에서 고유한 행만 선택
# 불리언 배열 반전 ~연산자 사용
dup_rows = ns_book.duplicated(subset=['도서명', '저자', 'ISBN', '권'])
unique_rows = ~dup_rows
# 고유한 배열 선택 copy() 메서드
ns_book3 = ns_book[unique_rows].copy()원본 데이터 프레임 인덱스 설정
loan_count 데이터 프레임의 인덱스와 동일하게 만듬
ns_book3.set_index(['도서명', '저자', 'ISBN', '권'], inplace=True)업데이트 : update() 메서드
# 원본 데이터 프레임 값을 업데이트
ns_book3.update(loan_count)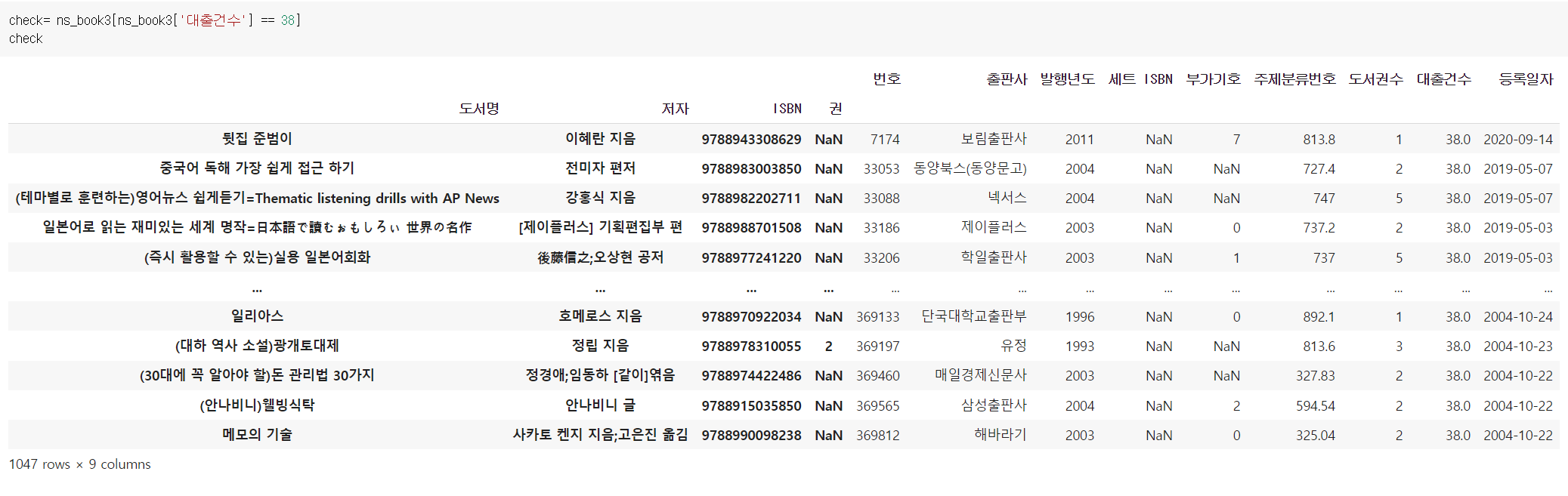
업데이트 후 인덱스열 해제
ns_book4 = ns_book3.reset_index()데이터프레임 열 재할당
ns_book4 = ns_book4[ns_book.columns]일괄 처리 함수
def data_cleaning(filename):
"""
남산 도서관 장서 CSV 데이터 전처리 함수
:param filename: CSV 파일이름
"""
# 파일을 데이터프레임으로 읽습니다.
ns_df = pd.read_csv(filename, low_memory=False)
# NaN인 열을 삭제합니다.
ns_book = ns_df.dropna(axis=1, how='all')
# 대출건수를 합치기 위해 필요한 행만 추출하여 count_df 데이터프레임을 만듭니다.
count_df = ns_book[['도서명','저자','ISBN','권','대출건수']]
# 도서명, 저자, ISBN, 권을 기준으로 대출건수를 groupby합니다.
loan_count = count_df.groupby(by=['도서명','저자','ISBN','권'], dropna=False).sum()
# 원본 데이터프레임에서 중복된 행을 제외하고 고유한 행만 추출하여 복사합니다.
dup_rows = ns_book.duplicated(subset=['도서명','저자','ISBN','권'])
unique_rows = ~dup_rows
ns_book3 = ns_book[unique_rows].copy()
# 도서명, 저자, ISBN, 권을 인덱스로 설정합니다.
ns_book3.set_index(['도서명','저자','ISBN','권'], inplace=True)
# load_count에 저장된 누적 대출건수를 업데이트합니다.
ns_book3.update(loan_count)
# 인덱스를 재설정합니다.
ns_book4 = ns_book3.reset_index()
# 원본 데이터프레임의 열 순서로 변경합니다.
ns_book4 = ns_book4[ns_book.columns]
return ns_book4데이터프레임 비교
new_ns_book4 = data_cleaning('ns_202104.csv')
new_ns_book4.equals(ns_book4)핵심 함수
| 함수 | 기능 |
|---|---|
| DataFrame.drop() | 데이터프레임의 행/열 삭제 |
| DataFrame.dropna() | 누락된 값이 포함된 행/열 삭제 |
| DataFrame.duplicated() | 중복된 행을 찾아 불리언 배열로 반환 |
| DataFrame.groupby() | 데이터프레임의 행을 그룹화 |
| DataFrame.sum() | 행/열 기준으로 합계 계산 |
| DataFrame.set_index() | 지정한 열 인덱스 설정 |
| DataFrame.reset_index() | 데이터프레임의 인덱스 재설정 |
| DataFrame.update() | 다른 데이터프레임을 사용해 원본 데이터프레임의 값을 업데이트, 다른 데이터프레임에 있는 NaN 값은 무시 |
| DataFrame.equals() | 다른 데이터프레임과 동일한 원소를 가졌는지 비교, 동일하면 True, 그렇지 않으면 False |
문제를 풀다가 오탈자를 찾음
4번 문제의 예시는 df2 데이터프레임이지만 사지선다에는 df로 나와있음, 5번 문제를 생각한다면 df가 맞는것으로 확인됨 또한 중복된 “열”을 삭제하는 명령이아닌 중복된 “행”을 삭제해야 하지 않는가..?
잘못된 데이터 수정
판다스는 누락된 값을 기본적으로 NaN으로 표시하며 NaN을 확인하는 방법과 NaN을 채우는 방법
데이터프레임 정보 요약확인
# 데이터 다운로드 후 데이터프레임 화
import gdown
gdown.download('https://bit.ly/3GisL6J', 'ns_book4.csv', quiet=False)
import pandas as pd
ns_book4 = pd.read_csv('ns_book4.csv', low_memory=False)
ns_book4.info()
# 정확한 메모리 사용량
ns_book4.info(memory_usage='deep')
- RangeIndex : 전체 행 개수
- Non-Null : 누락된 값이 없는 행 개수
- dtypes : 사용하는 데이터 타입
- memory usage : 메모리 사용량
누락된 값 처리하기
isna() 메서드 : 누락된 값 개수 확인
Nan을 직접 카운트하는 역할, 각 생이 비어있는지 나타내는 불리언 배열을 반환
# sum 메서드로 True 개수를 카운팅
ns_book4.isna().sum()
notna() 메서드 : 누락되지 않은 값 확인
ns_book4.notna().sum()
None과 np.nan : 누락된 값으로 표시
임의로 누락된 값을 만든 후 NaN으로 표시하는 방법
ns_book4.loc[0, '도서권수'] = None
ns_book4['도서권수'].isna().sum()이때 판다스는 NaN을 특별한 실수 값으로 저장하므로 도서권수가 1.0으로 변경됨
따라서 정수형으로 다시 변환해주어야 함
NaN은 실수형으로만 표시가 됨
astype() 메서드 : 데이터 타입 지정
ns_book4.astype({'도서권수': 'int32', '대출건수':'int32'})np.nan : 데이터 프레임에 NaN표시
넘파이 패키지의 np.nan을 사용해야함 데이터 타입에 상관없이 NaN으로 표시됨
import numpy as np
ns_book4.loc[0, '부가기호'] = np.nan
ns_book4.head(2)누락된 값 바꾸기 - loc. fillna() 메서드
누락된 값을 NaN이 아닌 빈문자열(’’)로 변경
- loc와 불리언 배열을 이용한 변경방법
# 누락된 값을 찾아 불리언 배열로 반환
set_isbn_na_rows = ns_book4['세트 ISBN'].isna()
# 누락된 값을 빈문자열로 변경
ns_book4.loc[set_isbn_na_rows, '세트 ISBN'] = ''
# 누락된 값 확인
ns_book4['세트 ISBN'].isna().sum()- fillna() 메서드를 이용한 방법
fillna는 기본적으로 새로운 데이터프레임을 반환
# 모든 NaN을 '없음' 문자열로 변경
ns_book4.fillna('없음').isna().sum()
# 특정 열만 선택해서 NaN 변경
ns_book4['부가기호'].fillna('없음').isna().sum()
전체 데이터 프레임을 반환하려면 딕셔너리를 전달
ns_book4.fillna({'부가기호': '없음'}).isna().sum()
누락된 값 바꾸기 - replace() 메서드
NaN뿐만 아니라 어떤 값을 모두 바꿀 수 있는 메서드
- 바꾸려는 값이 하나
replace(원래 값, 새로운 값)
ns_book4.replace(np.nan, '없음').isna().sum()- 바꾸려는 값이 여러개
replace([원래 값1, 원래 값2], [새로운 값1, 새로운 값2])
ns_book4.replace([np.nan, '2021'], ['없음', '21'])
ns_book4.replace({np.nan: '없음', '2021': '21'})- 열 마다 다른 값
replace({열 이름: 원래 값}, 새로운 값)
ns_book4.replace({'부가기호': np.nan}, '없음')
ns_book4.replace({'부가기호': {np.nan, '없음'}, '발행년도':{2021: '21}})정규 표현식
- 숫자 찾기 숫자 기호 \d, 2021은 \d\d\d\d의 형태로 21의 부분만 변경할 경우 \d\d(\d\d)로 그룹화 \d{2}(\d{2})로 쓸수 있음
# 첫번째 그룹을 변경
ns_book4.replace({'발행년도': {r'\d\d(\d\d)': r'\1'}}, regex=True)[100:102]
ns_book4.replace({'발행년도': {r'\d{2}(\d{2})': r'\1'}}, regex=True)[100:102]
- 문자 찾기 모든 문자에 대응하는 표현식 문자는 마침표(.)임 갯수를 모를때는 (*)을 사용, 공백문자는 \s을 사용 \D는 모든 문자를 찾음
ns_book4.replace({'저자': {r'(.*)\s\(지은이\)(.*)\s\(옮긴이\)': r'\1\2'}, '발행년도': {r'\d{2}(\d{2})': r'\1'}}, regex=True)[100:102]잘못된 값 바꾸기
# 데이터 타입 지정
ns_book4.astype({'발행년도':'int32'})
# 에러발생
---------------------
ValueError Traceback (most recent call last)
<ipython-input-43-9e5d0a6804c4> in <module>
----> 1 ns_book4.astype({'발행년도':'int32'})
8 frames
/usr/local/lib/python3.8/dist-packages/pandas/_libs/lib.pyx in pandas._libs.lib.astype_intsafe()
ValueError: invalid literal for int() with base 10: '1988.'
# 잘못된 값 확인
ns_book4['발행년도'].str.contains('1988').sum()
# na True로 지정하여 연도가 누락된 행을 True로 표시, 누락된 값은 숫자이외의 문자라고 처리
invalid_number = ns_book4['발행년도'].str.contains('\D', na=True)
# 숫자 이외의 문자가 들어간 행의 개수를 출력
print(invalid_number.sum())
# 출력
1777
- 정규 표현식을 이용한 문자 제외
ns_book5 = ns_book4.replace({'발행년도': '.*(\d{4}).*'}, r'\1', regex=True)숫자 이외의 문자가 들어간 행의 개수와 데이터 확인
unkown_year = ns_book5['발행년도'].str.contains('\D', na=True)
print(unkown_year.sum())
ns_book5[unkown_year].head()
# 출력
6767개의 값은 NaN이거나 4자리 숫자가 아닌 값으로 임의로 -1값으로 바꾼다음 데이터타입 변경
ns_book5.loc[unkown_year, '발행년도'] = '-1'
ns_book5 = ns_book5.astype({'발행년도': 'int32'})gt() 메서드 : 전달된 값보다 큰 값 찾기
ns_book5['발행년도'].gt(4000).sum()
# 단군기원에서 서기로 변경
dangun_yy_rows = ns_book5['발행년도'].gt(4000)
ns_book5.loc[dangun_yy_rows, '발행년도'] = ns_book5.loc[dangun_yy_rows, '발행년도'] - 2333
# 나머지 값 -1로 변경
dangun_year = ns_book5['발행년도'].gt(4000)
ns_book5.loc[dangun_year, '발행년도'] = -1lt() 메서드 : 전달된 값보다 작은 값 찾기
# 발행년도가 0보다 크고 1900년보다 작은 도서
old_books = ns_book5['발행년도'].gt(0) & ns_book5['발행년도'].lt(1900)
ns_book5[old_books]
# 값 -1로 변경
ns_book5.loc[old_books, '발행년도'] = -누락된 정보 채우기
도서명, 저자, 출판사 열에 누락값이 있거나 발행년도 열이 -1인 행의 개수 확인
na_rows = ns_book5['도서명'].isna() | ns_book5['저자'].isna() | ns_book5['출판사'].isna() | ns_book5['발행년도'].eq(-1)
print(na_rows.sum())
# 뷰티플수프를 사용해 값을 채움
import requests
from bs4 import BeautifulSoup
def get_book_title(isbn):
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# URL에 ISBN을 넣어 HTML 가져옵니다.
r = requests.get(url.format(isbn))
soup = BeautifulSoup(r.text, 'html.parser') # HTML 파싱
# 클래스 이름이 'gd_name'인 a 태그의 텍스트를 가져옵니다.
title = soup.find('a', attrs={'class':'gd_name'}) \
.get_text()
return title
get_book_title(9791191266054)저자,출판사,발행연도를 추출하여 반환하는 함수
import re
def get_book_info(row):
title = row['도서명']
author = row['저자']
pub = row['출판사']
year = row['발행년도']
# Yes24 도서 검색 페이지 URL
url = 'http://www.yes24.com/Product/Search?domain=BOOK&query={}'
# URL에 ISBN을 넣어 HTML 가져옵니다.
r = requests.get(url.format(row['ISBN']))
soup = BeautifulSoup(r.text, 'html.parser') # HTML 파싱
try:
if pd.isna(title):
# 클래스 이름이 'gd_name'인 a 태그의 텍스트를 가져옵니다.
title = soup.find('a', attrs={'class':'gd_name'}) \
.get_text()
except AttributeError:
pass
try:
if pd.isna(author):
# 클래스 이름이 'info_auth'인 span 태그 아래 a 태그의 텍스트를 가져옵니다.
authors = soup.find('span', attrs={'class':'info_auth'}) \
.find_all('a')
author_list = [auth.get_text() for auth in authors]
author = ','.join(author_list)
except AttributeError:
pass
try:
if pd.isna(pub):
# 클래스 이름이 'info_auth'인 span 태그 아래 a 태그의 텍스트를 가져옵니다.
pub = soup.find('span', attrs={'class':'info_pub'}) \
.find('a') \
.get_text()
except AttributeError:
pass
try:
if year == -1:
# 클래스 이름이 'info_date'인 span 태그 아래 텍스트를 가져옵니다.
year_str = soup.find('span', attrs={'class':'info_date'}) \
.get_text()
# 정규식으로 찾은 값 중에 첫 번째 것만 사용합니다.
year = re.findall(r'\d{4}', year_str)[0]
except AttributeError:
pass
return title, author, pub, year누락된 값 업데이트
# 2개의 행먼저 업데이트
updated_sample = ns_book5[na_rows].head(2).apply(get_book_info, axis=1, result_type ='expand')
업데이트 되지 않은 행 삭제
ns_book5 = ns_book5.astype({'발행년도': 'int32'})
ns_book6 = ns_book5.dropna(subset=['도서명','저자','출판사'])
ns_book6 = ns_book6[ns_book6['발행년도'] != -1]데이터 프레임의 원소 비교 함수
| 메서드 | 부등호 | 내용 |
|---|---|---|
| gt() | > | 지정된 값보다 큰 값을 검사 |
| ge() | ≥ | 지정된 값보다 크거나 같은 값 검사 |
| lt() | < | 지정된 값보다 작은 값을 검사 |
| le() | ≤ | 지정된 값보다 작거나 같은 값 검사 |
| eq() | == | 지정된 값과 같은 값 검사 |
| ne() | ≠ | 지정된 값과 같지 않은 값 검사 |
일괄처리 함수
def data_fixing(ns_book4):
"""
잘못된 값을 수정하거나 NaN 값을 채우는 함수
:param ns_book4: data_cleaning() 함수에서 전처리된 데이터프레임
"""
# 도서권수와 대출건수를 int32로 바꿉니다.
ns_book4 = ns_book4.astype({'도서권수':'int32', '대출건수': 'int32'})
# NaN인 세트 ISBN을 빈문자열로 바꿉니다.
set_isbn_na_rows = ns_book4['세트 ISBN'].isna()
ns_book4.loc[set_isbn_na_rows, '세트 ISBN'] = ''
# 발행년도 열에서 연도 네 자리를 추출하여 대체합니다. 나머지 발행년도는 -1로 바꿉니다.
ns_book5 = ns_book4.replace({'발행년도':'.*(\d{4}).*'}, r'\1', regex=True)
unkown_year = ns_book5['발행년도'].str.contains('\D', na=True)
ns_book5.loc[unkown_year, '발행년도'] = '-1'
# 발행년도를 int32로 바꿉니다.
ns_book5 = ns_book5.astype({'발행년도': 'int32'})
# 4000년 이상인 경우 2333년을 뺍니다.
dangun_yy_rows = ns_book5['발행년도'].gt(4000)
ns_book5.loc[dangun_yy_rows, '발행년도'] = ns_book5.loc[dangun_yy_rows, '발행년도'] - 2333
# 여전히 4000년 이상인 경우 -1로 바꿉니다.
dangun_year = ns_book5['발행년도'].gt(4000)
ns_book5.loc[dangun_year, '발행년도'] = -1
# 0~1900년 사이의 발행년도는 -1로 바꿉니다.
old_books = ns_book5['발행년도'].gt(0) & ns_book5['발행년도'].lt(1900)
ns_book5.loc[old_books, '발행년도'] = -1
# 도서명, 저자, 출판사가 NaN이거나 발행년도가 -1인 행을 찾습니다.
na_rows = ns_book5['도서명'].isna() | ns_book5['저자'].isna() \
| ns_book5['출판사'].isna() | ns_book5['발행년도'].eq(-1)
# 교보문고 도서 상세 페이지에서 누락된 정보를 채웁니다.
updated_sample = ns_book5[na_rows].apply(get_book_info,
axis=1, result_type ='expand')
# 도서명, 저자, 출판사가 NaN이거나 발행년도가 -1인 행을 삭제합니다.
ns_book6 = ns_book5.dropna(subset=['도서명','저자','출판사'])
ns_book6 = ns_book6[ns_book6['발행년도'] != -1]
return ns_book6핵심 함수
| 함수 | 기능 |
|---|---|
| DataFrame.info() | 데이터프레임의 요약 정보 표시 |
| DataFrame.isna() | 누란된 값을 감지, None이나 NaN일경우 True 반환 |
| DataFrame.astype() | 데이터 타입 지정 |
| DataFrame.fillna() | 테이터프레임에서 누락된 원소의 값을 채움 |
| DataFrame.replace() | 데이터프레임의 값을 다른 값으로 변환 |
| Series.str.contains() | 시리즈나 인덱스에서 문자열 패턴을 포함하는지 검사 |
| DataFrame.gt() | 데이터프레임의 원소보다 큰 값을 검사 |
미션
- 필수미션

- 선택미션

소감
원래 소감을 잘 쓰지 않는데 이번 주차는 정말 양이 많아서 소감을 써야겠다..
데이터 정제라는 과정이 이렇게 까다로울줄은 몰랐다. 공부를 하면서 따라쳐보고 코드를 보면서 분석도 해봤지만 사실 계속 접했던 분야가 아니기 때문에 이해가 안가는 부분들도 꽤나 많았다.
이 부분은 사실 여러번 반복하면서 습득을 해야 나름...? 순조롭게 진행이 될거같다.
추가로 나같은 초보자가 데이터를 정제하면 잘못된 정제가 되어 잘못된 데이터 분석이 될 수 있으니 반복학습이 필요하다..
P.S. 오탈자를 찾은거 같은데 맞는지 모르겠다..
- 필수미션 4번의 표가 df2로 작성되어 있는데 4번과 5번의 내용을 봤을때는 df가 맞는거 같다.
- 필수미션 4번 질문에서 중복된 열을 삭제한다고 되어있는데 중복된 행이
이것때문에 틀렸다고 핑계를..아닌지...?
제가 찾은 오탈자가 오탈자가 맞다고 합니다!
다들 저에게 칭찬 해주세요.:)
