TIL/코딩테스트
1.백준 11653. "소인수분해" 코드 최적화하기

정수 N이 주어졌을 때, N를 소인수분해하는 문제.N이 주어졌을 때, 2로 나누다가, 3으로 나누다가, ... 이렇게 쭉 올라가면 되지 않을까? 얼마나 나눠야할지는 어떻게 알 수 있을까? 한번 전수조사해보자! 내 첫번째 코드이다.math 라이브러리의 prod 함수를
2.백준 2775. "부녀회장이 될테야", 파스칼의 삼각형을 사용한 풀이, 재귀함수를 사용한 풀이 및 숏코딩 분석
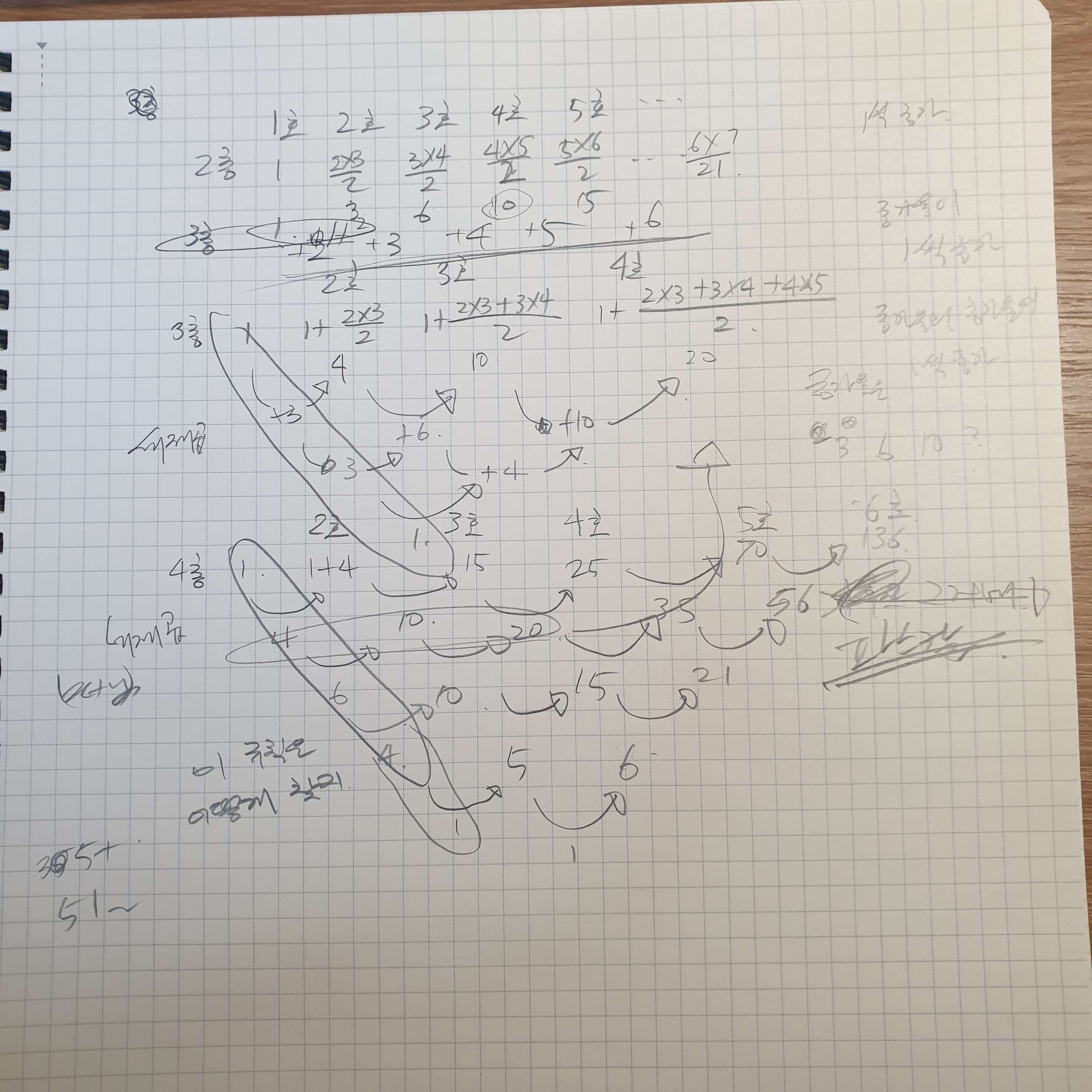
문제 링크 브론즈 레벨의 문제이지만 나름대로 고민하면서 수의 규칙을 찾아 풀려고 했다. 한층 한층 적어가던 중 어디서 봤던 것 같은 패턴이 눈에 들어오기 시작했다.바로 파스칼의 삼각형.처음엔 가우스와 관련된건줄 알고 가우스 키워드로 한참 찾아 헤매다가 파스칼의 삼각형인
3.백준 1929. "소수 구하기" 코드 분석
코드가 너무 느리다 젖먹던 힘까지 쥐어짜낸 내 코드가 메모리를 108MB씩이나 잡아먹고, 5984ms씩 걸리더라. 다른 사람들의 코드에서 배우려고 눈을 돌렸는데 rkddus96님의 코드가 눈에 들어왔다. 메모리 42.3MB, 시간 76ms.. 실로 엄청난 성능이다.
4.백준 4948. "베르트랑 공준" 코드 분석

이전 문제 1929. 소수 구하기에서 rkddus96님의 코드를 통해 소수 구하는 빠른 방법을 배우고 여기에 적용했다. 기록을 남기자면:그런데 성능이 메모리 36MB, 시간 216ms로 좀 더 최적화해야겠다는 생각이 들었다. 이번 문제에서도 rkddus96님의 코드가
5.백준 1697. 숨바꼭질 - BFS 재귀함수를 이용한 풀이 및 다른 코드 분석

내 코드 > 메모리: 136492 KB, 시간: 388 ms 두 개의 deque를 사용했다. 첫번째 큐에 시작점을 넣고 함수를 호출하며 시작한다. 주변 지점 ([v+1, v-1, v*2])에 대해 범위를 벗어나지 않는지 확인하며 두번째 큐에 추가한다. 두번째 큐와
6.꼬리재귀함수 반복문으로 바꾸기
꼬리재귀함수 반복문으로 바꾸기 아래는 백준 16928. 뱀과 사다리 게임에 사용한 get_destination 함수이다: 데이크스트라 알고리즘 사용에 앞서 그래프를 그리는데 사용한 재귀함수다. while문을 사용해 이렇게 바꿀 수 있다.
7.백준 이분 그래프 반례 및 답, 그리고 답안
기록을 위해 남김반례들:정답:Bitwise XOR 연산자를 사용해 노드들을 그룹지음.세트를 사용해 아직 탐색하지 않은, 떨어져 있는 그래프가 있는지 판단.
8.백준 1707. 이분 그래프 코드 분석
20210805님의 코드:메모리 약 53MB, 시간 1644ms메모리 약 54MB, 시간 1540ms확실히 반복문을 사용한 코드가 빠르다.
9.백준 10815. 숫자 카드 코드 분석
lycoris1600님의 코드:2chanhaeng님의 코드:buffer.read()가 빠른가?os.read는 unbuffered read. 즉 필요한 만큼만 따온다.sys.stdin.buffer.read()는 buffered read. 버퍼를 사용하면 작은 양의 데이터
10.프로그래머스 숫자 변환하기 DP 및 재귀적 접근
DP 외않되... > 문제 바로가기 왠지 DP로 풀 수 있을 것 같았다. BFS적 접근도 할 수 있지만, 한창 동적 계획법을 연습하고 있던 터라 시도해봤다. 결과는 실패. x부터 y까지 모든 인덱스에 대해 위 과정을 실행하면, 0이어야 할 경우에도 ls[y]에 숫
11.프로그래머스 혼자서 하는 틱택토
아래의 경우들을 제외하고 1을 리턴합니다.X가 더 많거나 O가 X보다 2이상 크면 0 리턴X가 이겼을 때는 무조건 숫자가 같아야 한다.O가 이겼을 때는 O가 X보다 1 많아야 한다.O가 한줄, X도 한줄인 경우.O가 두개의 대각선을 차지하는 경우.(X가 두개의 대각선을
12.프로그래머스 시소 짝꿍 코드 분석
일단 실패부터 해결해야겠다. 어디가 틀린거지?논리를 설명해보자.먼저 각 수가 몇개씩 있는지 센다. 여기서 radix를 사용하고 있으나 dict를 사용하면 메모리 최적화가 될 것 같다. 순서가 중요하지 않기 때문이다.각 수에 대해 2, 3, 4를 곱한 값을 그 수 인덱스
13.프로그래머스 연속 펄스 부분 수열의 합
오답 어디가 잘못된걸까? 정리해보자. 입력 리스트를 받아서 1에서 시작하는 펄스를 곱한 값을 pulse에 저장한다. itertools 모듈의 accumulate 함수를 사용해서 누적 합을 구하고, 그 중 가장 큰 값의 인덱스와 값을 저장한다. 구한 인덱스까지 다시
14.프로그래머스 개인정보 수집 유효기간 2가지 풀이
term에서 제시하는 기간을 O(1)로 호출할 수 있도록 terms_dict를 만든다. collections 모듈의 defaultdict를 활용한다. 키가 존재하는지 확인할 필요 없이 바로 추가할 수 있게 해주는 함수이다.privacies를 순회하며 날짜 계산을 실시한
15.백준 10431. 줄세우기
삽입 정렬 알고리즘을 사용해서 간단하게 풀 수 있는 문제다.삽입 정렬 알고리즘은 The Algorithms 깃허브를 참고했다. 필자가 예쁘다고 생각하는 구현 중 하나이다.
16.프로그래머스 명예의 전당 (1) 두가지 풀이 그리고 파이썬 정렬 알고리즘의 구현에 관한 궁금증을 남긴다
score를 순회하며 각 값을 추가하면서 정렬하고, 길이를 k에 맞게 유지해주며, 마지막 값을 answer에 추가해 반환한다. 잘 아시다시피 파이썬 리스트의 sort() 메서드는 $O(NlogN)$의 시간 복잡도를 가진다.매번 정렬할 때, 거의 정렬된 ls에 원소 하나
17.백준 10816. 숫자 카드 - itemgetter, Counter
문제 링크메모리 약 152MB, 시간 784ms메모리 약 131MB, 시간 492msReturn a callable object that fetches item from its operand using the operand’s \_\_getitem\_\_() metho
18.백준 13549. 숨바꼭질 3 메모리 최적화를 향하여 - 데이크스트라 알고리즘을 사용한 풀이
visited 세트를 따로 만들지 않았다. 대신 딕셔너리 graph를 활용했다.그래프 키는 리스트로 만들었다. pop하면서 리스트의 크기를 줄여나가 메모리를 최적화했다.시작점으로부터 모든 노드까지 일일이 거리를 다 기록하지 않도록 작성했다.데이크스트라 알고리즘을 연습하
19.백준 1654. 랜선 자르기 코드 분석
메모리 약 32MB, 시간 72ms먼저 탐색할 범위를 정한다. 어떤걸 범위로 지정할 것인가? 이 질문에 답하기 위해 다른 질문에 대한 답을 명확히 해야 한다 : "무엇을 구해야 하는가?" 내가 구하고자 하는 것은 잘라진 랜선의 길이이다. 그런데 길이를 잘 구했는지 알기
20.백준 2075. N번째 큰 수 코드 분석
문제 링크 메모리 약 30MB, 시간 692msN // 2 - 1번째 줄 까지는 최대값만 lst에 추가한다.그 이후 마지막줄 이전까지는 내림차순으로 정렬해 (N+1)//(N-i)번째 숫자까지만 추가한다.마지막 줄은 그대로 추가한다.전체적으로 lst에 어떤 숫자들이 담기
21.백준 2108. 통계학 코드 분석
문제 링크 메모리 약 53 MB, 시간 376 ms최빈값을 구하는 부분을 눈여겨보자. Counter 클래스의 most_common() 메서드는 최빈값을 구해 최빈값과 빈도수 튜플을 담은 리스트로 반환(https://docs.python.org/3/library
22.백준 2805. 나무 자르기 코드 분석
문제 링크 메모리: 149680 KB, 시간: 4448 ms엄밀한 접근을 어떻게 해야 잘 할 수 있을까 고민하고 있었다. 특히 이분 탐색같은 경우 종료 조건과, 출력값이 이해가 잘 되지 않았다. 제일 먼저 생각해 본 것은, '가능한 케이스들을 어떻게 분류할 수 있을까'
23.백준 18111. 마인크래프트 코드 분석
문제 링크 두 가지 작업이 가능하다: 인벤토리에 있는 블록을 쌓는 것과 쌓여 있는 블록을 인벤토리에 넣는 것. 언제부터 언제까지 어떤 작업을 수행해야 할지 어떻게 알 수 있을까? 만약 B가 0보다 크면, 작으면... 언제 덜어야되고 언제 더해야될지 어떻게 알 수 있을까
24.백준 1717. 집합의 표현
문제 링크 메모리: 83212 KB, 시간: 356 ms자료 구조, 분리 집합메모리 약 72MB, 시간 184ms재귀함수가 아니라 반복문으로 parent 기록.union을 조건문으로 처리.a가 b보다 크다면 parent\[a]에 b를 기록그렇지 않다면 parent\[b
25.프로그래머스 181188. 요격 시스템 코드 분석
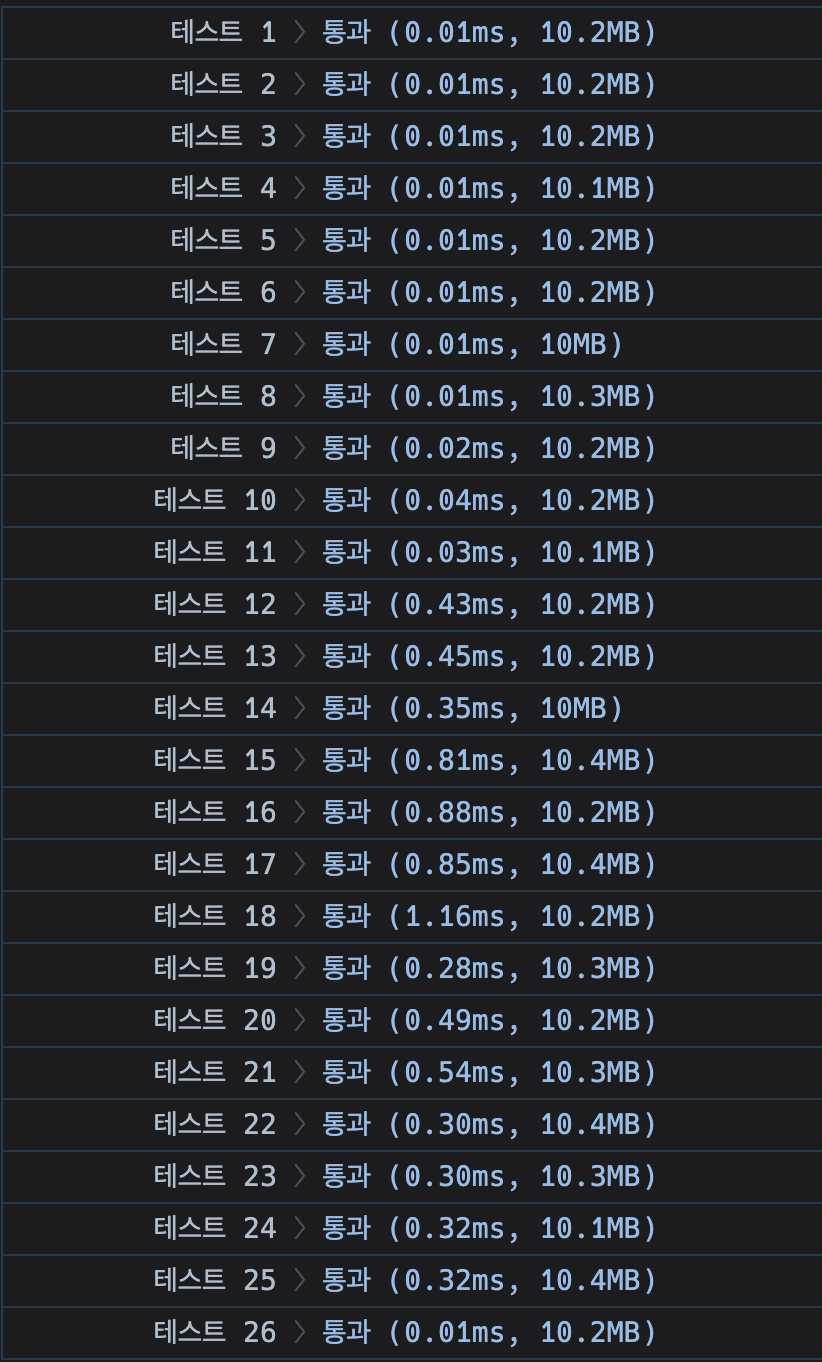
문제 링크 메모리: 10.2 MB, 시간: 0.00 ms\[\[1,2],\[2,3],\[3,4]]와 같은 단순한 예에서 시작했다. 이전 구간의 마지막보다 시작이 앞서면 answer에 1씩 더하면 된다. 그런데 이런 접근에서 한가지 문제가 발상핸다. 바로 다음 구간이 이
26.백준 1389. 케빈 베이컨의 6단계 법칙 코드 분석
문제 링크 메모리: 33376 KB, 시간: 64 ms노드 수가 최대 100이고, 관계가 최대 5000이라서 매트릭스 -> 플로이드 워셜로 접근했다. 각 그래프에 대해 최소값을 가진 노드 번호+1을 출력하면 끝. f 함수 대신 lambda x: sum(i for i i
27.백준 1463. 1로 만들기 코드 분석
문제 링크 메모리: 173364 KB, 시간: 1284 ms다이나믹 프로그래밍310\*\*6까지 기록할 수 있는 dp 테이블을 만들고, N-1까지 순회하며 다음 단계를 기록해나간다. 목표지점인 dp\[N]을 출력. \`i2에 대해선 N//2까지만 순회해도 되고, i\*