Ensemble learning이란
하나의 문제를 풀기 위해 여러개의 모델을 이용하는 방법을 말한다. 보통 여러 개의 weak learner를 이용하여 하나의 Strong learner를 만든다고 표현한다.
하나의 크고 좋은 모델을 쓰면 될 것 같은데?
모든 모델은(여기서의 모델은 굳이 딥러닝에 국한하지 않는다) 각기 데이터에 대한 Variance/Bias가 존재한다. 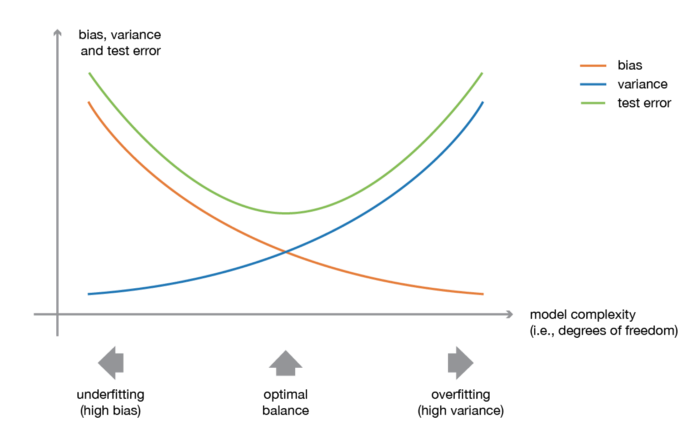
모델이 크면 Overfitting이 발생한다고 흔히 알고 있는데, 이건 모델이 학습 데이터만 잘 표현하는 모델을 학습시켰다는 뜻이다. (이 설명이 잘못되려면, 학습 데이터가 우리가 앞으로 직면할 수많은 데이터의 분포와 일치한다는 가정이 필요한데 그럴 일이 없다)
반대로 Underfitting은 학습 데이터에 대해 제대로 학습하지 못했다는 것을 의미한다. 그럼 그림에 나와있는 Variance/bias는 fitting과 어떤 관계가 있나?
Fitting과 variance/bias는 어떤 관계인가
먼저 모델을 학습한다는 의미를 간단하고 직관적으로 살펴보자. 모델의 추정값과 정답의 차이를 표현하는 수식인 MSE(Mean Squared Error)는 아래와 같은 과정을 통해 Variance와 Bias로 표현할 수 있다
정리하자면 모델의 오차(loss)는 [추정값 - 추정값 평균] + [추정값 평균 - 정답]으로 표현된다. (참고로 두 항 모두 제곱이므로 항상 +임을 보장하며, variance는 정답과는 관계가 없다!)
Loss를 줄여나간다는 것은 최소 Variance와 Bias 둘 중 하나를 줄인다는 것이고, 많은 경우에 적당히 복잡한 모델을 통해 둘 다 줄이는 것이 가능하다. 그렇다면 앞서 나온 Variance/Bias Trade-off는 무엇인가요? 그것은 바로 다른 데이터셋을 통해 해당 모델을 평가할 때 알 수 있다.
- Variance: 모델이 학습 데이터를 잘 설명하려 하면 할수록 복잡한 curve를 가지는 경우가 대부분이다. 그렇게 되면 다른 분포를 가진 여러 데이터에 대해서는 성능이 일정치 못하고 천차만별이 되는 경우가 많다(High Variance). 반면 모델이 심플하면 그만큼 학습 데이터를 잘 설명하지 못하는 것 같지만, 다른 여러 데이터에 대해서도 비교적 고른 분포의 성능을 내게 된다(Low Variance).
- Bias: 한편 Bias는 일관성을 말해준다. 학습 데이터에 대해 조금 설명력이 떨어지고 전체적으로 추정값들이 shift된 bias를 가질 수는 있지만, 이 모델은 다른 데이터를 평가할 때도 일관성 있는 성능을 보여줄 가능성이 있다.
이 모든 것은 학습과 평가 데이터가 서로 다른 분포를 갖기 때문에 발생하는 문제이다.
여기까지 읽으면 variance와 bias 둘 중 하나만 낮춘다고 해서 좋은 모델을 만들 수 있는게 아니라는 것을 이해할 수 있을 것 같다. 그래서 우리는 두 개념의 관점에서 더 나은 모델을 만드는 여러 방법들을 제시해왔고, 그 중 하나의 흐름이 Ensemble learning이다.
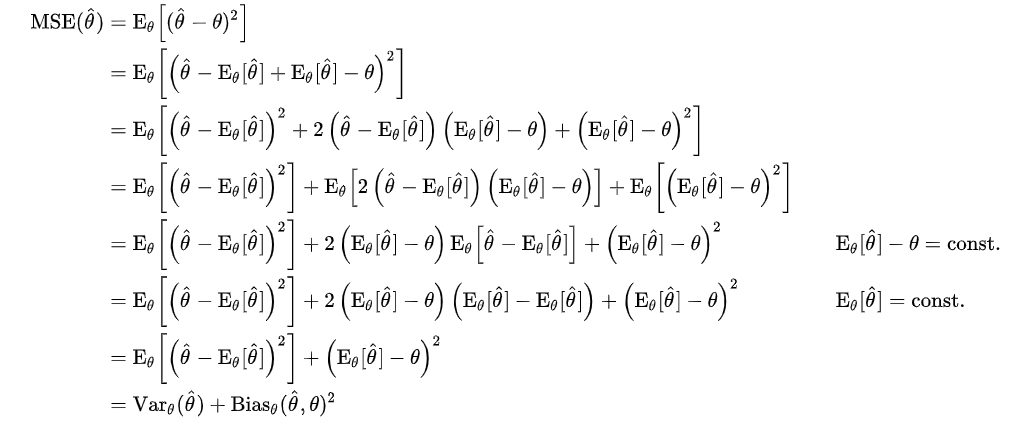
그럼 Ensemble learning은 어떻게 그걸 가능하게 하는건가요?
Ensemble learning은 여러 개의 weak learner(모델)를 방법에 따라 serial, parallel하게 구조를 만들고 학습시켜 더 좋은 결과를 얻을 수 있다. 대표적인 큰 개념으로는 Bagging, Boosting, Stacking이 있으며, 좀 더 자세하게 들어가보자.
1. Bagging
Bagging은 Bootstrap Aggregation으로 각 모델을 parallel하게끔 구조를 만들고 독립적으로 학습을 시킨 후, 각 모델에서 나오는 결과를 취합하는 방법이다. Bootstrap이란, 대체 B 관측값으로써 전체 데이터셋 N에서 크기 B의 샘플을 만드는 것을 말한다. 여기에는 몇가지 가정이 앞서야 한다 (반대로 가정을 만족하지 못하는 경우에는 bagging을 쓰는 것을 추천하지 않는다).
1. N이 충분히 커야만 샘플 데이테셋 B가 실제 데이터 분포와 비슷할 수 있다.
2. 각 B의 독립성을 키우기 위해 N은 B에 비해 충분히 커야 한다.
이 방법의 목적은 variance가 작은 모델을 얻기 위해 여러 weak learner에서 나온 결과를 평균 내어 variance를 줄이는 것이다. 여기서 여러 weak learner는 각각 독립적이어야 올바르겠지만 그건 정말 많은 학습 데이터가 있는 경우에 가능하고, 보통은 'random with replacement' 방식으로 임의의 Bn과 Bm에 일부 같은 데이터가 들어있는 것을 허락한다.
이렇게 얻은 여러 weak learner에서 나온 결과를 취합하는 방식은 여러 가지가 있다. 평균을 내는 방법도 있고, majority를 구하는 방법도 있다. 주로 regression은 평균화 기법, classification은 voting 기법을 이용한다 (classification에서 평균을 내는 기법도 있으며 이걸 soft voting이라고 한다).
2. Boosting
Boosting은 bias가 높은 weak learner를 serial하게 연결하여 bias를 낮추는 방법이다 (variance 또한 감소시킬 수 있다). 이 방법은 bagging과 같이 데이터를 나누지는 않는다. 대신에 학습 데이터가 선택적으로 추출되는 방식을 택한다. N개의 모델을 각각 D1, D2, ..., DN이라고 했을 때
1. D1을 가지고 있는 학습 데이터로 학습시킨다.
2. D1에서 틀린 데이터와 맞은 데이터를 적절히 섞어 D2를 학습시킨다.
3. D1과 D2에서 틀린 데이터를 모아 맞은 데이터와 함께 적절히 섞어 D3를 학습시킨다.
위와 같은 과정을 거쳐 DN까지 학습을 진행한다. 학습이 진행될수록 이전 모델에서 틀린 결과들의 비중이 높아지므로, 뒤에 있는 모델은 앞에서 맞추지 못했던 데이터들을 잘 학습하는 방향으로 유도될 수 있다. 이 과정을 반복함으로써 각 모델은 틀렸던 데이터에 대해 수정되어 간다. 최종적으로 모델을 평가할 때는 N개의 모델에서 나온 결과를 더하는 방식을 사용한다.
Boosting 알고리즘에는 여러 variation이 존재한다. 많이 알려져 있는 알고리즘으로는 AdaBoost, Gradient Boosting(GBM), XGBoost, LightGBM이 있다. 여기서는 두가지만 간략하게 소개한다.
- AdaBoost
기본적인 Boosting 방법에서 모델을 학습할 때, 각 모델 D1, D2, ..., DN이 내었던 정답률을 기반으로 가중치를 준다. 평가할 때도 각 모델에서 나온 결과에 가중치를 두어 더 정확한 모델이 더 강한 의사결정권을 갖게 된다.- Gradient Boosting
가중치를 계산하는 과정에서 AdaBoost는 정답률에 대한 log 함수를 사용했다면, GBM은 Gradient Descent방법을 이용하여 각 모델별 가중치의 최적값을 찾아나가는 방법이다.
