
모델의 성능은 어떻게 측정할까? 저마다의 감상은 다를 수 있으나 숫자는 거짓말을 하지 않는다. 분류 모델을 중심으로 가장 흔하게 쓰는 Performance Metric에 대해 알아본다.
시나리오:
당신은 의사입니다. 환자가 암을 가지고 있는지 검사를 진행했고, 진단을 내렸습니다.
용어 뜻 True Positive(TP) 실제 True인 정답을 True라고 예측 (정답) False Positive(FP) 실제 False인 정답을 True라고 예측 (오답) False Negative(FN) 실제 True인 정답을 False라고 예측 (오답) True Negative(TN) 실제 False인 정답을 False라고 예측 (정답)
Recall, Precision, Accuracy, F1
Recall:
실제 True인 것 중에서 모델이 True라고 예측한 것의 비율
"내가 여기 모두를 암 환자라고 진단내리면 recall은 1이겠지?"
이처럼 Recall의 장점은 실제 case에 대한 coverage를 확인할 수 있다는 점이지만 단점으로는 위의 경우처럼 모두 다 암에 걸리셨다고 말하면 recall은 1이 되어도 좋은 진단이 아니다.
Precision:모델이 True라고 분류한 것 중에서 실제 True인 것의 비율
"내가 암에 걸렸다고 진단 내렸던 사람은 모두 실제로 암 환자였어. 난 천재인가?"
Precision은 내가 한 예측에 대한 성능을 말해준다. 하지만 암진단이 틀릴까봐 예측을 전체 환자의 5%만 했다고 하면... 과연 나는 훌륭한 의사일까?
Accuracy:실제 True는 True, False는 False라고 예측한 것의 비율
"암 환자는 암이 있다고 말하고, 없으면 없다고 잘 이야기했으니 난 과연 천재 의사인건가?"
Accuracy는 완벽해 보이지만 사실 그렇지 않다. 만약 95%의 환자가 암을 갖고 있고 나머지 5%의 사람은 멀쩡한데 전부 암환자라고 진단을 내리면 이게 맞는건가? 난 뻐꾸기마냥 전부 암환자라고 했을 뿐인데 나도 모르는 사이에 명의가 되어버렸다는 시나리오는 있을 수 없다.
F1-Score:Recall과 Precision의 조화평균
Recall만 봐서도 안되고 Precision만 봐서도 안된다면 두 지표를 조화롭게 고려한다면 되지 않을까? 실제로 F1은 accuracy가 해결하지 못한 데이터의 불균형 문제 또한 제대로 고려할 수 있는 지표로 사용된다.
정리
Metric 수식 정의 장점 단점 Recall 실제 True인 것 중에서
모델이 True라고 예측한 것의 비율내가 True를 얼마나
밝혀냈는지 알 수 있음다 True라고 해버리면
1이 되어버림Precision 모델이 True라고 분류한 것 중에서
실제 True인 것의 비율내가 낸 True의 정밀도를
파악할 수 있음확실한 경우에만 True를
내어버리면 1이 되어버림Accuracy- 실제 True는 True,
False는 False라고 예측한 것의 비율True와 False 두 경우에 대한
가장 직관적인 성능 지표Bias가 심한 경우에 취약하다 F1-Score Recall과 Precision의 조화평균 위의 단점들을 보완한 지표 -
FAR, FRR
FAR(False Acceptance Rate)는 false이므로 결국 오답이라는 이야기인데 accept했다는 뜻이다. 암이 없는데 암환자라고 진단한 비율을 말한다. FAR은 FPR(False Positive Rate)과 같은 용어이다.
FRR(False Rejection Rate)는 마찬가지로 false이므로 결국 오답이고, reject했다는 뜻이다. 암이 있는데 암환자가 아니라고 진단한 비율을 말한다.
FAR, FRR 두 지표 모두 낮을수록 좋지만 그건 매우 이상적인 이야기이고 서로 TRADE-OFF 관계에 있다. 그리고 FAR == FRR의 포인트를 따로 EER(Equal Error Rate)라고 부른다.
FAR, FRR은 주로 특정 판단이 이용자에게 치명적인 불이익을 줄 수 있을 때 많이 고려하게 된다. 예를 들어 지문인식 보안에 관련한 모델을 만들었는데 FAR이 높다면 아무나 와서 손가락을 갖다 대어도 보안이 뻥뻥 뚫린다는 이야기이다. 이런 심각한 상황을 막기 위해 등장하는 단골손님 지표다.
ROC, PR curve, AUROC
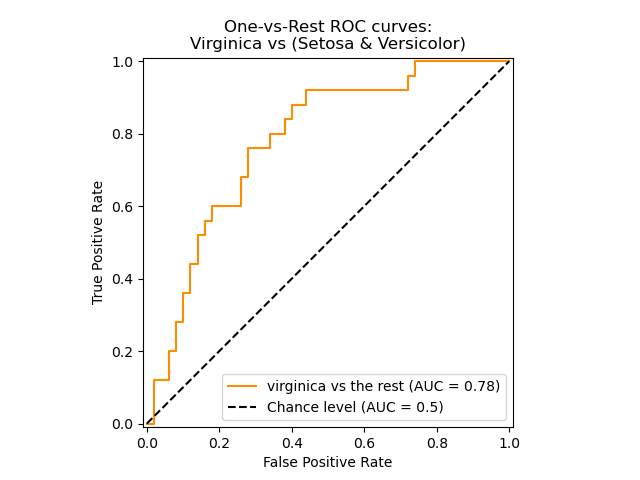
ROC(Receiver Operating Characteristic)
ROC 그래프는 가로축을 FP Rate (Specificity) 값의 비율로 하고 세로축을 TP Rate (Sensitivity) 로 하여 시각화 한 그래프이다. FP Rate은 FPR이고, TP Rate은 Recall을 의미한다.
그럼 가로축(FPR)이 커지면 어떤 의미인가?암이 없는데도 암환자라고 말하는 케이스가 늘어난다는 뜻이고 보통 이런 경우에는 아무나 다 암환자라고 말한다는 이야기이다.그런 분이 계시다면 세상 누구나 다 암환자라고 말할 확률이 높고,자연스럽게 Recall은 커지는 경우가 많다.
질문왜 그래프가 저렇게 계단식으로 생겼나요?
답변특정 임계값을 기준으로 값을 변화시켜가며 그래프를 그리기 때문. Recall/FPR에 영향을 줄 수 있는 threshold가 있다면 그걸 기준으로 ROC curve를 그릴 수 있다.
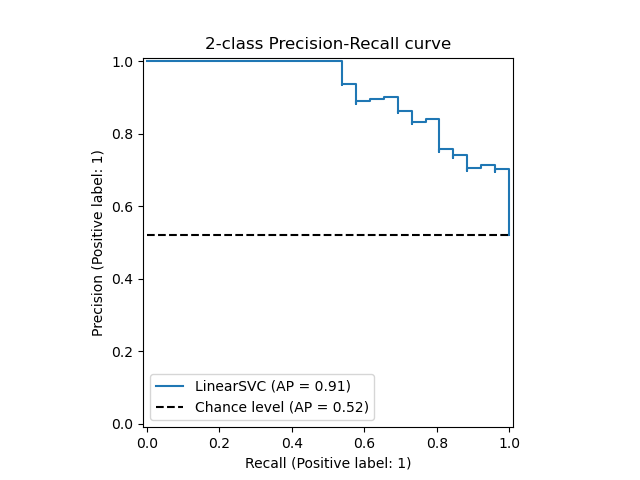
PR curve(Precision Recall curve)
이름에서 알 수 있듯 Precision과 Recall을 축으로 그린 curve를 의미한다. 마치 F1 score를 말하는 것 같지 않은가?
주로 데이터의 클래스 분포가 심하게 불균등 할때 사용한다.Accuracy에서 설명했듯, 실제 암 보유자와 아닌 사람의 분포가 심하게 차이가 난다면 ROC에서도 유의미한 결과를 얻기 어렵다. 왜냐하면 암이 없는게 정답이고 실제로 대부분의 환자들이 암이 없을 경우에 의사가 모든 환자에게 암이 없다고 했을 경우, FPR은 낮은데 Recall은 높은 아주 훌륭한 모델처럼 보일 수 있기 떄문이다.
질문왜 그래프가 저렇게 계단식으로 생겼나요?
답변ROC에서 설명했다
AUC(Area Under Curve) - AUROC / PRAUC
이건 단지 Curve아래 면적을 뜻하는 용어이다. 이 용어가 ROC, PR을 만났을 때 비로소 의미가 생긴다 - AUROC / PRAUC. 두 경우 모두 면적이 크면 클수록 좋은 모델임을 말해준다.
AP, mAP
AP(Average Precision)
질문Precision은 알고 있는데 이게 여러개 있어서 평균을 낼 수 있다는건가요?
답변네. recall을 변화시켜가며 조금씩 다른 precision을 얻을 수 있는데, 그것들의 평균입니다. PR curve를 생각하시면 되겠습니다.
mAP(Mean AP)
질문precision 평균까지 냈는데 또 mean은 뭔가요?
답변분류의 경우, 우리가 분류할 클래스(또는 객체)가 하나일 수도 있지만 여러개가 될 수도 있죠? 각 클래스(또는 객체)에 대한 AP의 mean값이 mAP입니다.
좋은 모델 vs. 좋은 테스트 결과
우리는 오늘 다양한 성능 지표들에 대해 알아보았다. 내가 가장 궁금했던 내용은
Precision,Recall,Accuracy,F1과 같은 단일 지표와ROC,PR과 같은 Curve의 차이였다.
질문그래서 차이가 뭔데요?
답변
- 단일 지표 Curve 종류 Precision,Recall,Accuracy,F1...ROC,PR특징 특정 설정에서 모델이 테스트 데이터를 얼마나 잘 분류하는가? 얼마나 강건한 모델을 만들었는가? 단점 특정 throughput(parameter)를 알고 지정해줘야 한다 많은 실험을 해야 한다
출처
https://sumniya.tistory.com/26
https://scikit-learn.org/stable/auto_examples/model_selection/plot_roc.html
https://bcho.tistory.com/1206
