
안녕하세요! 오늘은 Python에서 비동기 작업을 수행하는 방법 중 하나인 ThreadPoolExecutor를 활용하는 방법에 대해 이야기해보려 합니다. 이 글을 통해 ThreadPoolExecutor의 개념을 이해하고, 실제 활용 사례를 통해 어떻게 사용하는지 알아보겠습니다.
ThreadPoolExecutor란?
ThreadPoolExecutor는 Python의 concurrent.futures 모듈에 포함된 고수준 인터페이스로, 스레드 풀을 사용하여 비동기 실행을 관리합니다. 이를 활용하면 여러 작업을 병렬로 실행하여 I/O 바운드 작업의 성능을 크게 향상시킬 수 있습니다.
왜 ThreadPoolExecutor를 사용할까요?
동기적인 코드는 한 번에 하나의 작업만 처리할 수 있어서 I/O 작업과 같이 대기 시간이 긴 작업을 수행할 때 많은 시간이 소요될 수 있습니다. ThreadPoolExecutor를 사용하면 이러한 작업들을 동시에 실행하여 전체 실행 시간을 단축시킬 수 있습니다.
ThreadPoolExecutor 활용 예제: HTTP 요청 병렬 처리
웹 스크래핑이나 API 호출과 같이 여러 HTTP 요청을 동시에 처리해야 하는 상황을 생각해봅시다. ThreadPoolExecutor를 사용하면 이러한 작업을 효율적으로 처리할 수 있습니다.
코드 예제
from concurrent.futures import ThreadPoolExecutor, as_completed
import requests
# 처리할 URL 리스트
urls = [
"http://www.example.com",
"http://www.example.org",
"http://www.example.net"
]
# URL에 대한 HTTP 요청을 실행하는 함수
def fetch_url(url):
response = requests.get(url)
return url, response.status_code
# ThreadPoolExecutor를 사용하여 HTTP 요청 병렬 처리
with ThreadPoolExecutor(max_workers=5) as executor:
# 각 URL에 대해 fetch_url 함수를 실행하고, Future 객체를 생성
future_to_url = {executor.submit(fetch_url, url): url for url in urls}
# Future 객체가 완료될 때까지 기다린 후, 결과를 출력
for future in as_completed(future_to_url):
url = future_to_url[future]
try:
url, status = future.result()
print(f"{url} page returned status {status}")
except Exception as e:
print(f"Request to {url} generated an exception: {e}")
이 코드는 주어진 URL 리스트에 대해 비동기적으로 HTTP GET 요청을 수행하고, 각 요청의 HTTP 상태 코드를 출력합니다. ThreadPoolExecutor의 max_workers 파라미터를 조정함으로써 동시에 실행할 스레드의 수를 제어할 수 있습니다.
ThreadPoolExecutor의 이점
- 성능 향상: I/O 바운드 작업을 병렬로 실행하여 애플리케이션의 반응성과 처리량을 향상시킬 수 있습니다.
- 간결한 코드:
ThreadPoolExecutor와concurrent.futures모듈의 다른 기능들을 사용하면 복잡한 비동기 코드를 간결하고 이해하기 쉽게 작성할 수 있습니다. - 유연성: 작업의 개수나 스레드 풀의 크기 등을 쉽게 조정할 수 있어, 다양한 환경과 요구 사항에 맞게 애플리케이션을 최적화할 수 있습니다.
ThreadPoolExecutor의 객체지향 프로그래밍(OOP) 관점 이해
Python의 ThreadPoolExecutor를 이해하는 데에는 객체지향 프로그래밍(OOP)의 몇 가지 핵심 개념이 중요합니다. 이번 섹션에서는 ThreadPoolExecutor, 그리고 그것과 관련된 _base.py와 process.py 모듈들을 중심으로 OOP의 관점에서 설명을 추가해보겠습니다.
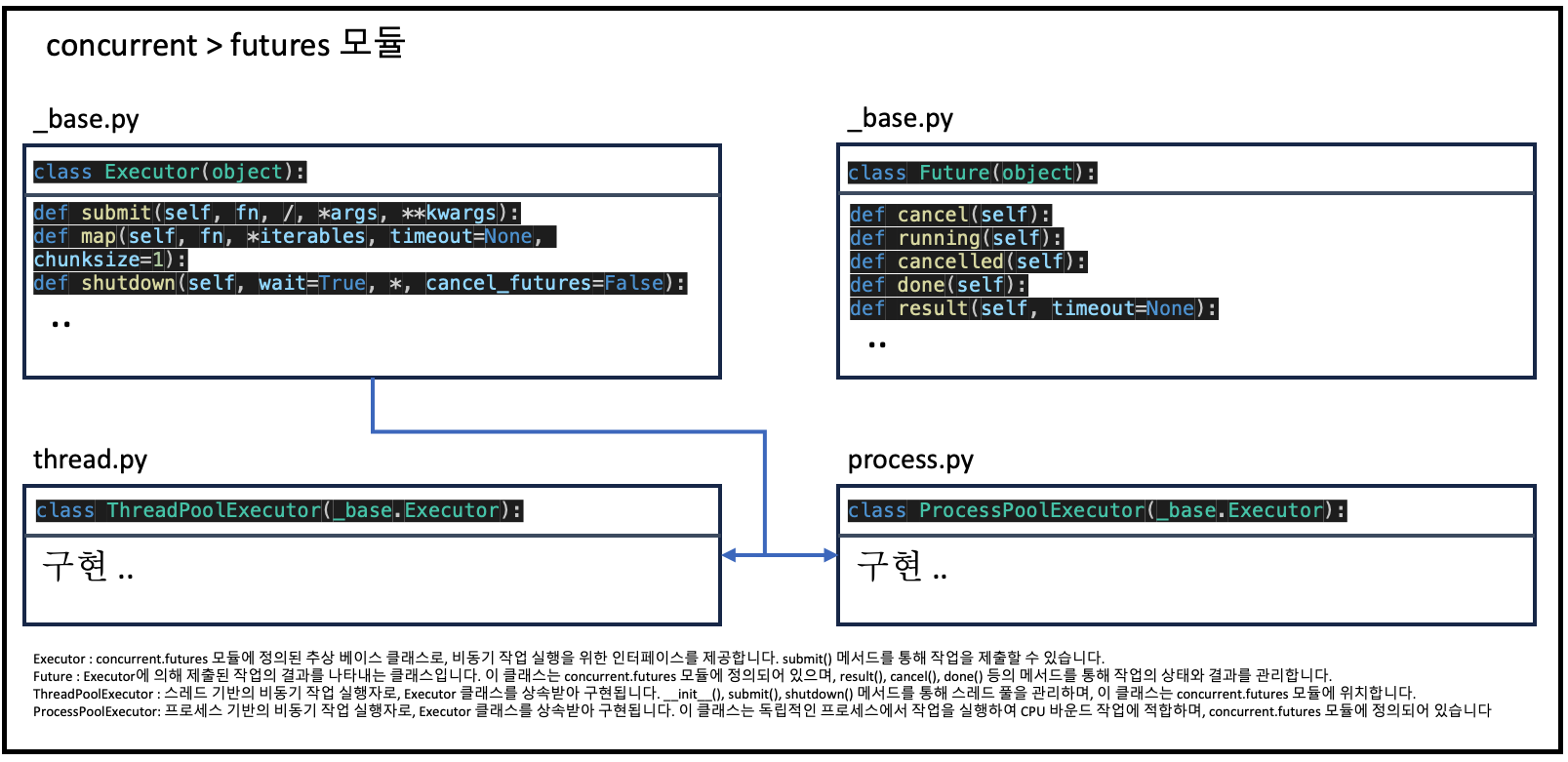
OOP의 핵심 개념
- 클래스와 인스턴스: 클래스는 객체를 생성하기 위한 템플릿입니다.
ThreadPoolExecutor클래스는concurrent.futures모듈에 정의되어 있으며, 이를 통해 생성된 객체(인스턴스)는 스레드 풀을 관리하고 작업을 실행하는 데 사용됩니다.
-
상속(Inheritance): 특정 클래스가 다른 클래스의 속성과 메소드를 물려받는 것을 말합니다.
ThreadPoolExecutor는_base.Executor클래스를 상속받아 그 기능을 확장하며,ProcessPoolExecutor역시 같은 방법으로_base.Executor의 기능을 확장합니다.


-
다형성(Polymorphism): 상속 관계에 있는 클래스들이 같은 이름의 메소드를 다른 방식으로 실행할 수 있는 능력을 의미합니다.
Executor클래스의submit()메소드는ThreadPoolExecutor와ProcessPoolExecutor에서 서로 다른 방식으로 구현됩니다.
3.1 ThreadPoolExcutor 클래스의 submit()def submit(self, fn, /, *args, **kwargs): # 스레드 풀이가 중단되지 않았는지 확인 with self._shutdown_lock, _global_shutdown_lock: if self._broken: raise BrokenThreadPool(self._broken) # 스레드 풀이가 이미 종료되었는지 확인 if self._shutdown: raise RuntimeError('cannot schedule new futures after shutdown') # 전역 종료가 되지 않았는지 확인 if _shutdown: raise RuntimeError('cannot schedule new futures after ' 'interpreter shutdown') f = _base.Future() w = _WorkItem(f, fn, args, kwargs) # 작업을 작업 큐에 추가 self._work_queue.put(w) self._adjust_thread_count() return f3.2 ProcessPoolExcutor 클래스의 submit()
def submit(self, fn, /, *args, **kwargs): # 스레드 풀이 중단되지 않았는지 확인 with self._shutdown_lock: if self._broken: raise BrokenProcessPool(self._broken) # 스레드 풀이 이미 종료되었는지 확인 if self._shutdown_thread: raise RuntimeError('cannot schedule new futures after shutdown') # 전역적인 종료가 되지 않았는지 확인 if _global_shutdown: raise RuntimeError('cannot schedule new futures after ' 'interpreter shutdown') f = _base.Future() w = _WorkItem(f, fn, args, kwargs) # 대기 중인 작업 항목에 추가 self._pending_work_items[self._queue_count] = w self._work_ids.put(self._queue_count) self._queue_count += 1 # 큐 관리 스레드를 깨움 self._executor_manager_thread_wakeup.wakeup() # 자식 프로세스를 동적으로 생성할 수 있는지 확인 if self._safe_to_dynamically_spawn_children: self._adjust_process_count() self._start_executor_manager_thread() return f
- 캡슐화(Encapsulation): 객체의 일부 구현 세부 사항을 숨기고, 사용자에게 필요한 인터페이스만을 노출하는 것입니다.
ThreadPoolExecutor의 내부 구현(예: 스레드 관리, 작업 큐 등)은 사용자로부터 숨겨져 있습니다.
마치며
ThreadPoolExecutor는 Python에서 비동기 프로그래밍을 할 때 유용한 도구입니다. 특히, 네트워크 요청, 파일 I/O와 같은 I/O 바운드 작업을 처리할 때 그 장점이 잘 드러납니다. 이 글이 ThreadPoolExecutor의 사용 방법을 이해하는 데 도움이 되었기를 바랍니다.
REF
