[Spring][FastAPI] LLM 챗봇 비용 절감: RedisSearch + pgvector 활용한 최적의 캐싱
실무 Spring, Python, DB, 인프라

인트로: LLM 챗봇의 비용 문제와 캐싱 도입
우리 서비스에는 LLM을 활용한 법률 챗봇이 있다.
법률 도메인이라는 특성상 질문 유형이 어느 정도 한정적일 것이라 예상했지만, 실제 운영 데이터를 확인해보니 유사한 질문과 답변이 중복으로 여러 개 저장되고 있었고 이로 인해 LLM 호출 비용도 꾸준히 증가하고 있었다.
초기 MVP 단계에서는 매번 LLM을 호출해 답변을 생성하는 방식이었지만,
사용자 유입이 증가할 경우 비용 부담이 커지고 응답 속도도 느려질 것이 명확했다.
따라서, 불필요한 LLM 호출을 줄이고 빠른 응답을 제공하기 위해 "캐싱"을 도입하기로 결정했다.
단순한 문자열 기반의 캐싱이 아니라, 질문을 벡터화하여 의미적으로 유사한 질문을 빠르게 찾아주는 방식을 선택했다.
구현 방법: 벡터DB + RedisSearch 기반의 다단계 검색
이 문제를 해결하기 위해 다음과 같은 검색 전략을 설계했다.
1단계: AI 캐싱 (RedisSearch 활용)
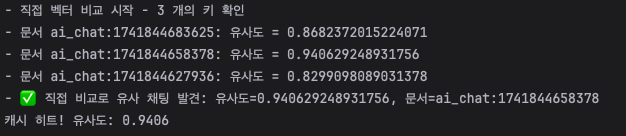
- 사용자가 24시간 내 동일하거나 유사한 질문을 입력한 경우, RedisSearch에서 즉시 검색하여 캐싱된 값을 반환한다.
- 임베딩 벡터를 기반으로 벡터 유사도 검색을 수행하여 비슷한 질문이 있다면 빠르게 응답.
- 사용한 기술: Redis + RediSearch + mxbai-embed-large (임베딩 모델)
2단계: RDBMS 검색 (PostgreSQL + pgvector)
- Redis에 캐싱된 값이 없을 경우, PostgreSQL의 pgvector 확장을 활용하여 저장된 임베딩 벡터와 비교한다.
- HNSW(탐색 최적화) 기반의 벡터 검색을 활용하여 LLM 호출 없이 기존 데이터를 찾아 응답.
- 사용한 기술: PostgreSQL + pgvector + HNSW Index
3단계: LLM 호출
- Redis와 RDBMS에서 모두 유사한 질문을 찾지 못한 경우에만 LLM을 호출한다.
- 이때 새롭게 생성된 질문과 답변은 임베딩하여 Redis & PostgreSQL에 저장하여, 다음 번에는 캐싱될 수 있도록 한다.
- 사용한 기술: OpenAI API, Llama-3 기반 모델, FastAPI 서버
기술 선택의 이유
우리는 단순한 문자열 기반 캐싱이 아니라, 의미 기반 검색을 수행해야 했다.
이를 위해 임베딩 벡터를 활용한 벡터DB 기반 캐싱을 설계했다.
왜 RedisSearch를 사용했는가?
- 빠른 검색 속도 – 인메모리 캐싱이므로 매우 빠르게 응답 가능
- 간단한 구축 가능 – 대규모 벡터 스토어 대비 운영 부담이 적음
- RediSearch의 KNN(Nearest Neighbor) 검색 기능 지원
왜 PostgreSQL + pgvector를 사용했는가?
- 우리 서비스의 규모상 대형 벡터DB (FAISS, Pinecone 등)까지는 필요 없음
- PostgreSQL의 pgvector 확장은 유지보수 부담 없이 쉽게 사용 가능
- HNSW 기반 인덱스 최적화 적용 가능
왜 mxbai-embed-large 모델을 선택했는가?
✔️ 초기에는 nomic-embed-text와 비교 테스트를 진행했으나,
✔️ 법률 도메인 특성상 보다 정확한 유사도 검색이 필요하여 mxbai-embed-large 모델을 선택했다.
✔️ 또한, 유사도 임계치를 0.9로 높게 설정하여 정확도가 높은 결과만 반환하도록 최적화했다.
구현 과정
1. RedisSearch를 활용한 벡터 캐싱
// 질문을 임베딩하여 Redis에 저장
public void saveAiChat(String query, String response) {
String normalizedQuery = normalizeTextForRedis(query);
String queryHash = hashQuery(query);
List<Double> embedding = generateEmbeddingAsList(normalizedQuery);
byte[] queryVectorBinary = convertToFloat32Binary(embedding);
String base64Vector = Base64.getEncoder().encodeToString(queryVectorBinary);
String key = "ai_chat:" + System.currentTimeMillis();
Map<String, String> chatData = new HashMap<>();
chatData.put("query", normalizedQuery);
chatData.put("query_hash", queryHash);
chatData.put("response", response);
chatData.put("query_vector", base64Vector);
redisModulesCommands.hset(key, chatData);
redisModulesCommands.expire(key, 86400); // 24시간 TTL 설정
}✔ 주요 포인트
✔️ 질문을 임베딩하여 Redis에 저장
✔️ query_vector 필드를 활용한 벡터 기반 검색
✔️ MD5 해시 기반의 빠른 문자열 매칭 검색도 함께 적용
2. PostgreSQL + pgvector 기반 RDBMS 검색
CREATE TABLE llm_chat_result (
id SERIAL PRIMARY KEY,
query TEXT,
response TEXT,
query_embedding VECTOR(1024) -- 벡터 저장
);
CREATE INDEX ON llm_chat_result USING hnsw (query_embedding vector_l2_ops);✔ 주요 포인트
✔️ gvector 확장을 활용하여 벡터 저장
✔️ HNSW 인덱스를 적용하여 검색 최적화
✔️ 벡터 유사도 검색을 통해 기존 질문 재활용
3. 전체 검색 흐름
public String findAiChat(String query) {
// 1. RedisSearch에서 검색
Optional<Map<String, String>> redisResult = findSimilarByVector(query);
if (redisResult.isPresent()) {
return redisResult.get().get("response");
}
// 2. PostgreSQL에서 검색
Optional<String> dbResult = findInPostgres(query);
if (dbResult.isPresent()) {
return dbResult.get();
}
// 3. LLM 호출
return callLlmAndCache(query);
}결과: 최적화 효과

결론:
✔️ 즉시 응답 가능 (Redis 캐싱 덕분에 100ms 내 응답)
✔️ 비용 절감 (반복되는 질문에 대한 LLM 호출 방지)
✔️ 확장성 강화 (pgvector를 활용한 유사 질문 검색 최적화)
느낀 점 & 개선 방향
✔️ 법률 도메인 특성상 질문이 유사하게 반복되므로, 벡터 기반 캐싱이 효과적
✔️ 임베딩 모델을 적절히 선택하는 것이 중요 (mxbai-embed-large vs nomic-embed-text)
✔️ 향후 FAISS/Pinecone 같은 대형 벡터 스토어 도입을 고려할 수 있음
마무리
이번 개선 작업을 통해,
LLM 챗봇의 비용을 절감하고, 응답 속도를 획기적으로 줄이는 데 성공했다.
이제 남은 과제는 더 정밀한 임베딩 모델 선택과, 벡터DB의 확장성 테스트가 될 것이다.
(아니 벨로그 마크다운 왜이래.... 이모티콘을 쓰게 만드네...)
