
Retrospect
3주차 회고! 3주차에서는 2주차까지 만든 API를 토대로 DB를 연동시켜봤다. (야호!) 회사에서 mysql에서 쿼리를 직접 쓰면서 코드를 작성했는데, 3주차에서는 JPA를 통해서 쿼리를 생으로 짜지 않고 연동시켜볼 수 있었다. (신기) MongoDB 때도 느꼈던 거지만 쿼리를 직접 안 짜니까 너무 편하긴 하다,,
DB에 대해 이론적으로 잠깐 배우고 라이브 코딩으로 넘어갔다. 너무 따라치기만 하면 실력이 덜 늘까봐 라이브 코딩에서 User에 관한 API를 하면, 나는 Order에 관한 API를 비슷하게 만들어보면서 2주차 내용도 복습할 겸 따라가면서 DB 연동까지 해보았다 :)
MenHel Study
3주차 스터디 전 멘헬 스터디에서는, 사전 과제로 DB를 각자 연동해보는 미션이 있었다. 참고 자료를 받아서 열심히..! 구글링까지 뒤져가면서 DB를 연동해보았다. 오.. 근데 DB 접속까지는 됐는데 테이블 연동이 안 되는 것 ㅋㅋ큐ㅠㅠ 스터디 시간에 같이 봤는데, 테이블 이름 잘못된거에,, url 잘못 넣은 거에,, 데이터 타입 문제와 입력값까지 자잘한 문제들로 에러 파티 WOW !! ㅋㅋ큐ㅠㅠㅠ 진짜.. 열심히 해야겠답.. 스터디 장과 멘토 분이 하나하나 연결에 성공할 때까지 끝까지 함께 봐주시고 심지어 에러 케이스를 많이 모아서 오히려 고맙다고 말해주셨다. 감덩..😭 (스터디 배울 맛 난다 ㅎㅎ) 진짜 멘헬 스터디에서 직접 부딪히면서 에러를 해결해보면서 많이 배웠다!!
- 유저 이름과 테이블 이름 잘 확인할 것 (철자 하나라도 다르면 데이터 변화 X)
- 데이터 타입 꼭꼭 확인하고 테스트에서 입력값 넣을 때 제대로 넣기
- 💥 DB 비밀번호 절대 잊어버리지 말 것 (잃어버리면 못 찾음..)
- 엔티티 클래스에 빈 생성자 넣을 것
Week3 Study
3주차 시작! 공부합시다~
🌱 DataGrip & Mysql 설치
DB를 연동하기 전에 먼저 사전 준비가 필요하다.
DataGrip은 JetBrains에서 개발한 DB GUI 툴인데, IntelliJ와 UI가 거의 비슷해서 금방 적응해서 사용하기 편하다. 아래 주소를 통해서 다운로드 받아주자-! (단, DataGrip은 유료판이다 ㅇㅁㅇ.. 하지만 학생 계정을 사용하면 무료로 사용할 수 있으니 학생 인증을 받은 계정으로 다운 받아줬다~!)
https://www.jetbrains.com/ko-kr/datagrip/
Mysql은 말해뭐해~ 너무 유명한 RDBMS(관계형 데이터베이스 관리 시스템)의 오픈소스..! 터미널을 열어서 설치해줍시당 ~.~ 아래 포스트를 참고해서 쉽게 설치했다 :)
https://memostack.tistory.com/150
🌱 Database (데이터베이스)
본격적으로 DB에 대해 배웠다. 대학 때 들었던 내용이 새록새록 기억나는 기분이었음 😚
데이터베이스
특정 데이터를 확인하고자 할 때 간단하게 찾아낼 수 있는 형태SQL
RDBMS (관계형 데이터베이스 관리 시스템)에서 데이터를 조작할 때 사용되는 언어관계형 데이터베이스
Row와 Column을 가지는 표 형식의 데이터를 저장하는 데이터베이스
(하나의 표를 테이블(table), 하나의 테이블을 엔티티(entity)로 볼 수 있음)
데이터를 조작할 때 관계 대수 활용
SOPT 세미나부터 코프링 스터디 2주차까지 최소 한번씩은 들었던 개념 내용 정리 ✨
좀 더 나아가서 DB를 논리적으로 설계할 때 고려해야 할 사항도 볼 수 있었다. (SQLD 자격증을 공부하면서 꽤 많이 보였던 내용들이었다)
각 테이블에는 고유한 키 (Primary Key)가 있어야 한다.
각 테이블에는 관계를 맺기 위해 키가 있어야하는데, 그 키는 테이블에서의 고유함을 나타내기 위해 unique 해야 하고 이러한 키를 Primary Key (PK, 주요키)라고 한다.
테이블 간에 row(속성)끼리 관계를 맺을 수 있다.
테이블 간의 관계 맺기! 예를 들어 수강 테이블과 과목 테이블에 과목 ID라는 속성이 있다고 하자. 그럼 수강 테이블의 과목 ID는 과목 테이블의 과목 ID 속성을 참조하여 과목 정보를 확인할 수 있다. (1:1, 1:N, N:N 형태 중 하나로 관계를 맺을 수 있음)
무결성도 DB 설계에서 중요한 사항 중 하나이다. 고려해야 할 무결성은 다음과 같다.
데이터 무결성
- 개체 무결성
모든 테이블은 주요키(PK)를 가져야 하고, PK는 null 일 수 없다.- 참조 무결성
외래키(FK) 값이 특정 테이블의 PK를 참조할 때, 특정 데이터가 변하면 참조되는 데이터도 변해야 한다.- 도메인 무결성
필드의 타입, null 값 허용 등에 대한 사항을 정의하고, 각 row에 올바른 값이 입력되어야 한다. (올바른 초기 설정이 필요함)
외래키(FK)와 참조 무결성
- 한 테이블의 키 중 다른 테이블의 row를 유일하게 식별할 수 있는 키를 외래키(FK)라고 한다.
- 중복된 값 혹은 null을 가질 수 있다.
- 반드시 참조되는 테이블의 PK 혹은 유일한 값을 가지는 column을 참조해야 한다.
- 참조되는 테이블에 존재하는 값을 가져야 한다. (단, null은 예외)
FK는 PK와 같이 유일한 값을 가지는 Column을 참조한다. (그래야 참조하는 의미가 있겠지 ?!)
이 부분을 몰랐다가 초반에 쿼리 짤 일 있을 때 머리 좀 아팠던 기억이 있다 ㅎㅁㅎ 기억할 것..!
무결성에 관련된 쿼리 명령어도 알 수 있었다.
RESTRICTED // 레코드를 변경 또는 삭제하고자 할 때, 해당 레코드를 참조하고 있다면 연산 취소
CASCADE // 레코드를 변경 또는 삭제하면, 해당 레코드를 참조하는 개체도 변경 or 삭제
SET NULL // 레코드를 변경 또는 삭제하면, 해당 레코드를 참조하는 개체의 값은 null로🌱 DataGrip & MySQL
초반에 설치한 친구들이다 >.< 이제 사용법을 알아봅세다 ~.~
🛠 DataGrip에서 새로운 테이블 생성하기
DataGrip에 접속해서, @localhost 클릭 > Schema 생성 > 생성한 스키마 클릭 > Table 생성을 누르면 아래와 같은 화면이 뜰 것이다.
 적당한 속성과 타입을 지정하고 필요한 칼럼들을 추가해준다.
적당한 속성과 타입을 지정하고 필요한 칼럼들을 추가해준다.
여기서는 id 속성은 PK이므로 자동 증가 기능, 주요키 속성 추가를 해주었다. (주요키 기본 속성에 not null, unique 포함되어 있음) product 속성은 고유한 이름을 갖고, null 값일 수 없는 속성이므로 Not null과 Unique으로 지정해주었다.
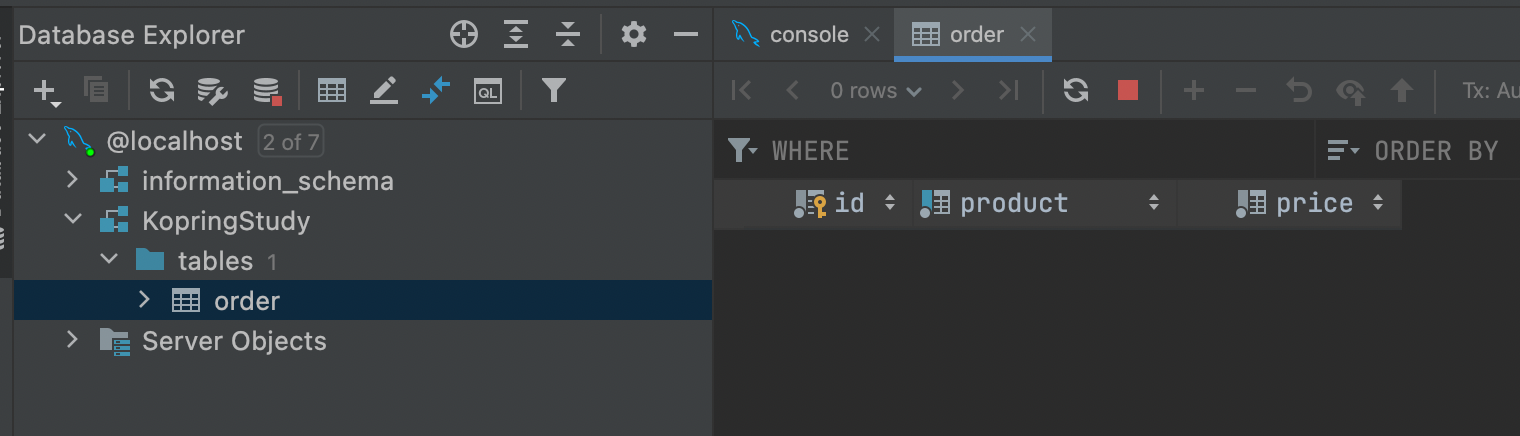 짜잔~ 잘 생성되었습니다 ~!~!
짜잔~ 잘 생성되었습니다 ~!~!
DataGrip으로 테이블까지 잘 생성했다. 이제 우리는 이 테이블을 Spring Boot에서! JPA를 통해 테이블에 접근하고 데이터를 transaction 할 것이다 ㅎㅎㅎㅎ 스터디를 통해서 JPA를 처음 써볼 수 있었다. JPA가 무엇인지부터 살짝 알아보자.
🌱 Spring Data JPA (Java Persistence API)
현재 Java 진영의 ORM 기술 표준으로, 인터페이스의 모음
쉽게 말해서 자바에서 쉽게 DB를 사용하게 해주는 기술이라고 생각하면 되겠다.
그럼 쿼리를 놔두고 굳이 왜 쓸까 ..? 단지 쉬우려고 ..?
쿼리를 쓰려면 코드에 SQL도 포함된다. 그렇게 되면 Kotlin 코드보다 SQL 부분이 더 많아지게 될텐데, 그렇게 되면
가독성이 떨어진다.
패러다임(객체지향/관계형)의 불일치 문제가 발생한다.
RDBMS 스타일은 DAO 파일에서 각자 객체를 받아와야해서 객체지향 스타일과 멀어진다. 그런 SQL이 많아진다면! 당연히 가독성도 후두두 떨어질 것이다 😢
이 문제를 완화(중재)하기 위해 나온 수단을 JPA로 이해하면 되겠다.
개발자가 객체지향 프로그래밍하면 JPA가 대신 DB에 맞게 SQL을 수행해준다.
장점
CRUD 쿼리 직접 짜지 않아도 된다
Data Layer에서도 객체지향 프로그래밍 활용 가능단점
SQL을 사용할 때마다 성능 이슈 발생 가능 (특히 대용량 트래픽에서)
높은 러닝커브
정리하면 코드 설계를 살리는 것이 장점이고, 대용량에서는 성능 문제가 발생하는 것이 단점이다. 그래서 대용량을 사용하는 부분에서는 SQL을 많이 사용한다는 썰도 들었다-!
아직 JPA를 제대로 써보지 못해서 왜 SQL보다 러닝커브가 높은 지는 이해를 못했다 흐음ㅁ..
🌱 실습! CRUD API에 JPA 연동하기
라이브 코딩 시간에는 이전에 만든 CRUD에 JPA를 얹어보는 것을 배웠다.
지난 시간 복습도 할 겸 수업을 들으면서, User 대신 Order이란 새로운 주제를 두고 CRUD API 부터 다시 코드를 만들어보았다.
먼저 jpa를 사용하기 위한 의존성 추가해주자.
> build.gradle.kts
dependencies {
...
implementation("org.springframework.boot:spring-boot-starter-data-jpa")
runtimeOnly("mysql:mysql-connector-java")
}이제 DB 연동을 위한 세팅을 해주자.
src > main > resource > application.properties
spring.jpa.database=mysql
# DB Source URL
spring.datasource.url=jdbc:mysql://localhost:<port_num>/<DB_name>?allowPublicKeyRetrieval=true&useSSL=false&userUnicode=true&serverTimezone=Asia/Seoul
# DB username
spring.datasource.username=<user_name>
spring.datasource.password=<_password>
spring.jpa.show-sql=true<port_num> 보통 3306
<DB_name> 데이터베이스(스키마) 이름
<user_name> mysql 계정을 생성할 때 만든 유저 이름, 보통 root
<_password> mysql 생성한 계정 비밀번호
🏜⛏ 여기서 잠깐..
테이블 이름을 order로 지정해주면 안된다 ㅇㅁㅇ.. (이걸로 DB 연동이 안되서 삽질 엄청 했다 엉엉) order로 테이블 이름을 지정하면 이미 있는 이름이거나 그런 건 모르겠지만 get이고 post고 에러난다 안돼ㅠㅠ 그래서 orders로 이름을 바꿔주고 재시도 하니까 연동에 성공했다!
JPA와 가장 직접적으로 맞닿는 레포지토리를 생성해주자.
> src/main/kotlin/com/sohyeon/kopring/repository/order/OrderRepository.kt
interface OrderRepository : JpaRepository<OrderEntity, Long> {
fun findOrderEntityByProduct(product: String): OrderEntity?
fun findOrderEntityByProductAndPrice(product: String, price: Int): OrderEntity?
fun findOrderEntityById(Id: Long): OrderEntity?
fun deleteOrderEntityById(Id: Long)
}find<Entity이름>By<파라미터> : 파라미터로 엔티티 값을 찾는다
find<Entity이름>By<파라미터1>And<파라미터2> : 파라미터 2개로 찾기
delete<Entity이름>By<파라미터> : 파라미터를 가지는 엔티티 값 삭제
정말 쿼리 없이 위의 함수들만 정의해주면 get과 delete가 가능하다. (신기해~)
엔티티는 어노테이션과 함께 다음과 같이 생성해주자.
> src/main/kotlin/com/sohyeon/kopring/entity/order/OrderEntity.kt
@Entity
@Table(name="orders")
class OrderEntity (
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
val id: Long = 0,
@Column(name="product") var product: String = "",
@Column(name = "price") var price: Int = 0
) {
// 빈 생성자
constructor(): this(product="", price=0)
}@Entity : 엔티티로 명시해주는 annotation 정도로 이해하자
@Table(name= .. ) : 해당 테이블명을 지정해주는 annotation 이다 (order 하지 말 것 ^^..)
constructor() : 정확히는 모르겠지만 JPA에서는 빈 생성자를 생성해주어야 한다.
Dto 파일은 2주차에서 생성한 것과 같은 방식으로 OrderDto로 생성해주자.
Service 파일도 2주차랑 마찬가지로 함수 지정해주기!~!
ServiceImpl 파일에서 JPA를 활용해보자 !!
private val repository: OrderRepository먼저 Argument 부분에 해당 repository를 불러와준다. 이제 이 레포지토리를 활용하여 데이터를 활용하게 API를 조금씩 변경했다.
repository.findAll()findAll() (기본 함수)로 테이블의 모든 데이터 값을 불러올 수 있다.
repository.findOrderEntityByProduct(product)
repository.findOrderEntityByProductAndPrice(product, price)파라미터로 데이터를 불러오는 Get API는 레포지토리 파일에서 정의해준 함수를 활용할 수 있다.
repository.save(order)데이터를 추가하는 함수에는 기본 함수인 save() 함수를 활용한다.
val orderResult = repository.findOrderEntityById(id)
..
orderResult.product = orderDto.product
orderResult.price = orderDto.price수정하는 함수에서는 id 값으로 데이터를 찾아와서, request body로 들어 온 값들을 위와 같이 해당 데이터에 넣어준다.
repository.deleteOrderEntityById(id)삭제하는 함수에서는 레포지토리에서 정의해준 함수를 사용하면 된다.
🔥 잠깐 !!
POST, PUT, DELETE와 같이 데이터가 변하는 method 에서는 트랜잭션이 동시에 실행되어서는 안된다. 따라서 각 함수에 @Transactional 어노테이션을 붙여서 이를 방지해주자.
Feeling
슬슬 DB 관련도 실습해면서 더 재밌어졌다! 스프링에서 쿼리 없이 사용해본 적이 없었는데..! JPA처럼 쿼리 없이 쓰는 것도 어색하지만 훨씬 수월하고 신기하다. 대용량을 요구하는 쪽에서는 아직 SQL도 많이 쓰고 있지만 점차 NoSQL도 많이 도입되는 추세라고 하니 열심히 공부하고 배워야겠다! 화이팅~~
