

JDBC ?
JDBC는 Java DataBase Connectivity 의 약자로, 직역하자면 자바-데이터베이스-연결, 자바 애플리케이션과 데이터베이스 사이의 통신을 가능하게 해주는 API입니다. JDBC는 저보다 일찍 태어났을(?) 정도로 오래된 기술로 현재까지 자바의 데이터베이스 작업을 위한 표준 방법으로 자리 잡고 있을 정도로 안정되고 중요한 기술입니다.
그렇다면 JDBC를 왜 사용해야 할까 ?

(이미지 출처: https://stock.adobe.com/kr/search?k=why)
오늘날 데이터의 중요성은 입으로 말하기도 아플 정도로 중요합니다. 이미 저는 어릴 적부터 '정보화 시대' 라는 말을 들으면서 자라왔는데 현재는 과거보다 더욱 데이터가 중요해졌으며, 이제는 AI・빅데이터・데이터 분석 등 새로운 기술들로 인해 데이터의 중요성이 나날이 커지는 것을 우리가 모두 알고 있죠 ﹗
그럼 왜 자바(Java) ?
우리 대한민국에서 가장 많이 사용되는 언어는 자바이며, 자바를 사용하는 애플리케이션이 매우 많고 앞으로도 많아질 것이며, 우리나라뿐만 아니라 자바는 전세계적으로 인정받을 정도로 많이 사용되는 언어입니다.

(이미지 출처: https://www.pinterest.co.kr/pin/953637289828229042/)
즉, 자바를 통한 애플리케이션으로부터 우리는 과거부터 현재 그리고 앞으로의 미래에도 많은 데이터들이 생겨날 예정이므로, 데이터가 지배하는 현대 사회에서 데이터베이스와의 상호 작용은 엄청 중요하다는 것을 쉽게 생각해 낼 수 있습니다.
JDBC 를 사용하는 이유 1
JDBC를 사용함으로써 자바 개발자는 데이터베이스 연결, SQL 문 실행, 결과 처리 등의 작업을 효율적으로 수행할 수 있습니다. 또한, JDBC는 데이터베이스 종류에 상관없이 일관된 인터페이스를 제공하므로, 애플리케이션의 데이터베이스를 변경하더라도 코드의 대대적인 수정 없이 유연하게 대응할 수 있습니다 👍🏻👍🏻👍🏻
JDBC 를 사용하는 이유 2

(이미지 출처: https://stock.adobe.com/kr/search?k=1997)
JDBC 가 오래된 기술인 만큼 처음 출시되었을 때부터 현재까지 지속해서 많은 발전이 이루어졌습니다. 초기의 JDBC는 단순히 SQL 문 실행에만 초점을 맞추었지만, 시간이 지남에 따라 트랜잭션 관리, 풀링 기술, 메타 데이터 접근 등 많은 기술이 추가되었습니다.
무엇보다 SQL Mapper 기술인 MyBatis 나 최근에는 JPA와 같은 ORM 기술이 인기가 많아지면서 JDBC 위에 추상화된 레이어를 제공하여 더욱 간결하면서 객체 지향적인 데이터베이스 작업이 가능하게 되었습니다.
그럼 더더욱 JDBC를 사용해야 하는 이유가 명확해졌습니다. 이는 JDBC가 여전히 자바 애플리케이션에서 데이터베이스 작업의 핵심적인 기반이라는 것을 의미합니다.
JDBC를 사용해야 하는 이유: 결론
멋진 기술들을 잘 사용하려면 그 내부적인 원리를 잘 이해해야 한다는 건데 자바를 통해서 데이터베이스 작업을 잘 다루기 위해서는 근본적인 JDBC부터 잘 알아야 한다는 것입니다. 앞으로도 데이터베이스 기술이 발전하고 새로운 요구사항이 생겨날 때마다, JDBC는 계속해서 진화하며 자바 개발자에게 필수적인 도구로 남을 것입니다.
(물론 먼 훗날 한국에서 자바를 대체하는 새로운 대세 언어가 생겨난다면 우리의 JDBC는 쓸모가 없어질지도 모릅니다ㅠㅠ)
JDBC 를 알기 위해 알고 넘어가야 할 것 !
-
JDBC 드라이버
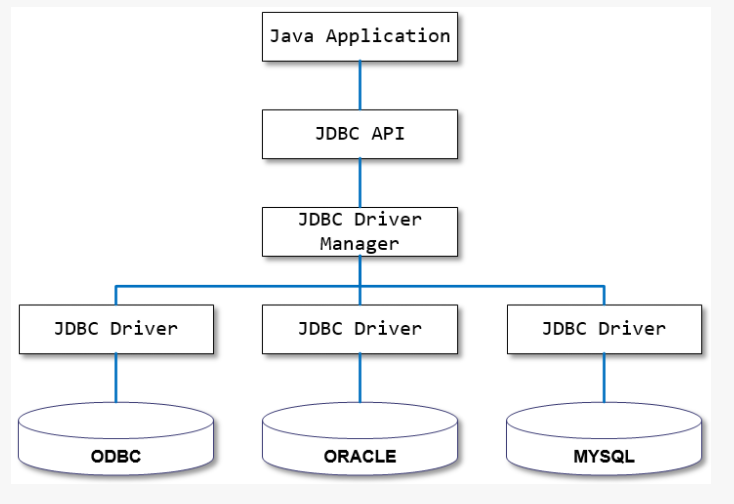
JDBC API를 구현하는 컴포넌트로, 자바 애플리케이션과 데이터베이스 사이의 통신을 담당합니다. JDBC도 결국 데이터베이스 작업을 사용하기 위한 표준화된 인터페이스이기 때문에 실제 데이터베이스와의 연결을 위해서는 매개체가 필요합니다. 따라서, 데이터베이스와의 연동을 위한 드라이버가 필요한데, 각 데이터베이스 벤더는 자신의 데이터베이스 시스템을 위한 JDBC 드라이버를 제공합니다.
-
데이터베이스 URL
: 데이터베이스에 연결하기 위한 특정 포맷의 주소입니다. 이 URL은 사용할 데이터베이스의 종류, 데이터베이스가 호스팅되는 서버의 주소 및 포트 번호, 데이터베이스 이름 등의 정보를 포함합니다.jdbc:mysql://localhost:3036/mydatabase?serverTimezone=UTC
- SQL

(이미지 출처: https://logowik.com/azure-sql-database-logo-vector-svg-pdf-ai-eps-cdr-free-download-16374.html)
: 데이터베이스와 상호작용하기 위한 표준 언어입니다. JDBC는 자바 애플리케이션에서 데이터베이스의 작업을 할 수 있게 해주는 도구이기 때문에 결국 JDBC를 사용하는 애플리케이션에서도 데이터 조작 및 관리를 위해 SQL 문을 작성합니다.
데이터베이스와의 연결하는 가장 기초적인 방법
-
JDBC 드라이버 로드: 애플리케이션에서 사용할 데이터베이스의 JDBC 드라이버를 로드합니다. 이는 대부분
Class.forName()메소드를 사용하여 진행됩니다. -
연결 생성: 데이터베이스 URL, 사용자 이름, 비밀번호를 사용하여
DriverManager.getConnection()메소드를 통해 데이터베이스 연결을 생성합니다. -
SQL 문 실행:
Statement객체를 생성하여 SQL 쿼리를 실행합니다. 데이터를 조회하는 경우ResultSet객체를 통해 결과를 받아올 수 있습니다. -
연결 종료: 모든 작업이 끝난 후에는
close()메소드를 호출하여ResultSet,Statement, 그리고Connection까지 차례로 데이터베이스 연결을 종료해야 합니다.
JDBC 맛보기 코드
간단한 예시로 Gradle 에 필요한 의존성을 추가하고, JDBC를 사용하여 H2 데이터베이스에 Board 테이블을 생성하고 CRUD 작업을 예시 코드를 통해 연습해 보도록 하겠습니다.
1. Gradle을 통한 JDBC 의존성 추가
Gradle 빌드 도구를 사용하여 JDBC를 위한 필요한 의존성을 build.gradle 파일에 추가합니다.
dependencies {
implementation 'com.h2database:h2:1.4.200'
implementation 'org.springframework.boot:spring-boot-starter-jdbc'
}2. H2 Database에서 Board 테이블 생성
H2 Database 콘솔을 사용하여 Board 테이블을 생성합니다.
CREATE TABLE Board (
BoardId INT AUTO_INCREMENT PRIMARY KEY,
title VARCHAR(100),
content TEXT
);3. JDBC 연결 유틸리티 코드
JDBC와 H2 DB 연결을 관리하는 유틸리티 클래스를 작성합니다. 이 클래스는 데이터베이스 연결을 생성하고 반환하는 역할을 합니다.
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
public class DBUtil {
private static final String URL = "jdbc:h2:mem:testdb;DB_CLOSE_DELAY=-1";
private static final String USERNAME = "sa";
private static final String PASSWORD = "";
public static Connection getConnection() throws SQLException {
return DriverManager.getConnection(URL, USERNAME, PASSWORD);
}
}JDBC 드라이버 로드가 생략된 이유는 Java SE 6부터 도입된 자동 드라이버 로딩 기능 때문입니다. 이 기능을 통해 Class.forName()을 명시적으로 호출하여 JDBC 드라이버를 로드하는 과거의 방식이 더 이상 필요하지 않게 되었습니다. Java SE 6 이상에서는 JDBC 4.0 API가 도입되었고, 이 API는 ServiceLoader 메커니즘을 사용하여 드라이버를 자동으로 탐지하고 로드합니다. DriverManager.getConnection() 메서드를 호출할 때, Java는 classpath에 있는 모든 JDBC 드라이버를 검사하고, 데이터베이스 URL에 해당하는 드라이버를 자동으로 찾아 로드합니다.
4. Board 엔티티 생성
다음은 Board 엔티티를 데이터베이스에 추가하는 예제입니다.
public class BoardDao {
public void createBoard(Board board) throws SQLException {
String sql = "INSERT INTO Board (title, content) VALUES (?, ?)";
try (Connection conn = DBUtil.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, board.getTitle());
pstmt.setString(2, board.getContent());
pstmt.executeUpdate();
}
}
}각 단계별 설명은 다음과 같습니다:
-
PreparedStatement객체 생성
: 이 객체는 SQL 쿼리를 사전에 컴파일하고, 실행 전에 매개변수를 설정할 수 있습니다. 이 방식은 SQL 쿼리 실행을 보다 효율적으로 만들고, SQL 인젝션 공격과 같은 보안 취약점을 예방할 수 있습니다.
(SQL 인젝션이란? : https://velog.io/@jjjjj/DB%EC%9D%B8%EC%A0%9D%EC%85%98-SQL-%EC%9D%B8%EC%A0%9D%EC%85%98) -
매개변수 설정:
pstmt.setString(1, board.getTitle())
: 첫 번째 물음표(?) 위치에board객체의title필드 값을 문자열(String) 형태로 설정합니다.pstmt.setString(2, board.getContent())
: 두 번째 물음표(?) 위치에board객체의content필드 값을 문자열로 설정합니다.물음표는 SQL 쿼리 내에서 동적으로 값을 설정할 위치를 표시합니다 !
-
쿼리 실행:
pstmt.executeUpdate()
: 쿼리를 실행합니다.executeUpdate메서드는 INSERT, UPDATE, DELETE와 같이 데이터베이스의 내용을 변경할 경우 사용됩니다. 이 메서드는 실행 후 생성 혹은 수정/삭제가 진행된 행의 수를 정수(INT)로 반환합니다.
5. Board 엔티티 조회
Board 엔티티를 조회하는 코드와 테스트 코드를 작성합니다. 다음은 특정 BoardId를 가진 Board 엔티티를 조회하는 예제입니다.
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
public class BoardDao {
public Board findBoardById(int boardId) throws SQLException {
String sql = "SELECT * FROM Board WHERE BoardId = ?";
try (Connection conn = DBUtil.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, boardId);
try (ResultSet rs = pstmt.executeQuery()) {
if (rs.next()) {
return new Board(rs.getInt("BoardId"), rs.getString("title"), rs.getString("content"));
}
}
}
return null;
}
}각 단계별 설명은 다음과 같습니다:
-
SQL 쿼리 준비
:"SELECT * FROM Board WHERE BoardId = ?"이 쿼리는Board테이블에서BoardId컬럼의 값이 메서드에 전달된boardId와 일치하는 행만 데이터를 조회합니다. -
쿼리 매개변수 설정
:pstmt.setInt(1, boardId)를 호출하여 쿼리의 첫 번째 물음표 위치에boardId값을 정수로 설정합니다. -
쿼리 실행 및 결과 처리:
pstmt.executeQuery()
: 준비된 쿼리를 실행하고,ResultSet객체로 결과를 반환받습니다.ResultSet은 쿼리 결과를 나타내는 객체입니다. 현재는 where 문을 통해서 조회하였기 때문에 최대 1개의 행이 담겨져 있습니다.if (rs.next())
:ResultSet에 다음 행이 있는지 확인합니다. 결과가 존재하면true를 반환하고, 결과 포인터를 해당 행으로 이동시킵니다.new Board(rs.getInt("BoardId"), rs.getString("title"), rs.getString("content"))
:ResultSet에서 현재 행의BoardId,title,content컬럼 값을 추출하여 새로운Board객체를 생성합니다.
-
결과 반환: 메서드는 찾은
Board객체를 반환하거나, 결과 행이 없는 경우null을 반환합니다.
6. Board 엔티티 수정
다음은 Board 엔티티의 title과 content를 업데이트하는 예제입니다.
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class BoardDao {
public void updateBoard(Board board) throws SQLException {
String sql = "UPDATE Board SET title = ?, content = ? WHERE BoardId = ?";
try (Connection conn = DBUtil.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setString(1, board.getTitle());
pstmt.setString(2, board.getContent());
pstmt.setInt(3, board.getBoardId());
pstmt.executeUpdate();
}
}
}7. Board 엔티티 삭제
다음은 특정 BoardId를 가진 Board 엔티티를 삭제하는 예제입니다.
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class BoardDao {
public void deleteBoard(int boardId) throws SQLException {
String sql = "DELETE FROM Board WHERE BoardId = ?";
try (Connection conn = DBUtil.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql)) {
pstmt.setInt(1, boardId);
pstmt.executeUpdate();
}
}
}JDBC 사용 시 기본적인 예외 처리 방법
JDBC를 사용할 때 발생할 수 있는 SQLException을 처리하기 위한 기본적인 방법은 try-catch 블록을 사용하는 것입니다. 각 JDBC 작업을 수행하는 동안 try-with-resources 구문을 사용하여 자원을 자동으로 관리할 수 있습니다.
이 방법을 통해 Connection, PreparedStatement, ResultSet 객체 등을 자동으로 닫을 수 있으며, 이는 메모리 누수를 방지할 수 있습니다.
try (Connection conn = DBUtil.getConnection();
PreparedStatement pstmt = conn.prepareStatement(sql);
ResultSet rs = pstmt.executeQuery()) {
// 데이터베이스 작업 수행
// ...
} catch (SQLException e) {
e.printStackTrace();
}저는 처음부터 자바 애플리케이션에서 DB 연결은 JPA 만을 사용하다가 SSAFY 에 입과 하여 처음으로 SQL 매퍼인 MyBatis 를 사용해 보고 이후에 프로젝트에서는 다시 JPA와 Querydsl 을 사용하고 있습니다. 물론, SSAFY 교육 과정에서도 JDBC를 배우긴 하였지만, 생각보다 오래되기도 하여서 다시 한번 복습 겸 정리를 해보고 싶어서 포스트를 작성하게 되었습니다 !
혹시나 문제 되는 부분이 있으면 댓글을 통해서 알려주시면 빠르게 수정하도록 하겠습니다🙇🏻
[참고]
https://velog.io/@alstjdwo1601/JDBC%EB%9E%80
https://velog.io/@rktdngud/JDBC-JDBC
https://velog.io/@bingbong-party/JDBC-JDBC
https://velog.io/@dondonee/JDBC-%EC%9D%B4%ED%95%B4
