소프트웨어 아키텍처
1.소프트웨어 아키텍처
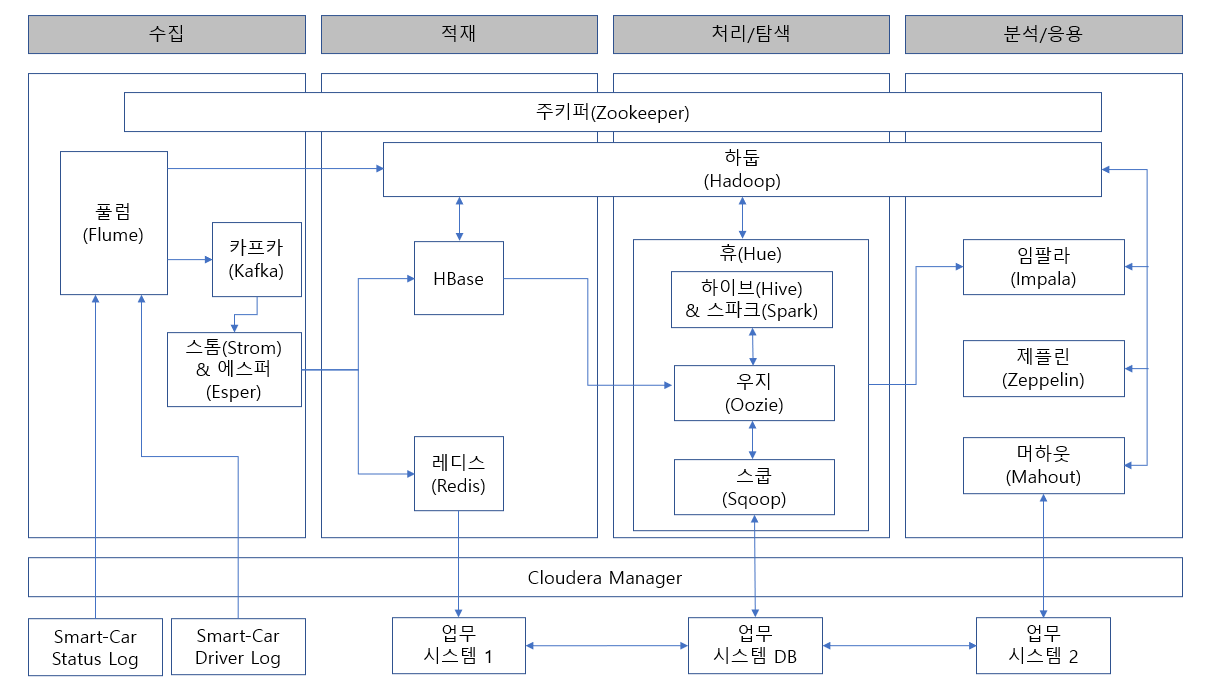
데이터 수집, 적재, 처리, 분석 과정의 소프트웨어 아키텍처위 그림에 있는 모듈 및 기술들을 공부하고 정리하는 공간
2.하둡(Hadoop)

하둡은 빅데이터의 핵심 소프트웨어다. 빅데이터의 에코시스템들은 대부분 하둡을 위해 존재하고 하둡에 의존해서 발전해 가고 있다 해도 과언이 아니다. 하둡은 크게 두 가지 기능이 있다. 첫 번째가 대용량 데이터를 분산 저장하는 것이고, 두 번째는 분산 저장된 데이터를 가공
3.주키퍼(Zookeeper)
주키퍼의 필요성 주키퍼는 개발자들이 동기화를 비롯한 부수적인 요소 대신, 서비스가 제공하는 기능과 그 구현 방법에 더 집중하도록 도와준다. 개발자가 주키퍼에 저장해야하는 정보는 제어 또는 조율을 위한 데이터이다. (서버들의 설정 정보, 클러스터의 마스터 서버, 각각 작
4.아파치 플럼(Apache Flume)
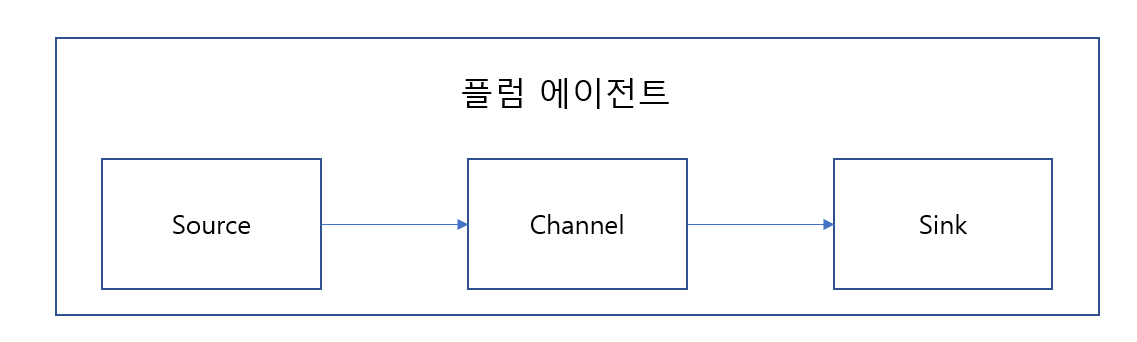
Flume은 빅데이터를 수집할 때 다양한 수집 요구사항들을 해결하기 위한 기능으로 구성된 소프트웨어다. 플럼은 대량의 로그 데이터를 효율적으로 수집, 집계, 이동하기 위한 신뢰성있는 분산형 소프트웨어다. steaming data 기반으로 유연하고 간단한 아키텍처를 갖추
5.카프카(Kafka)
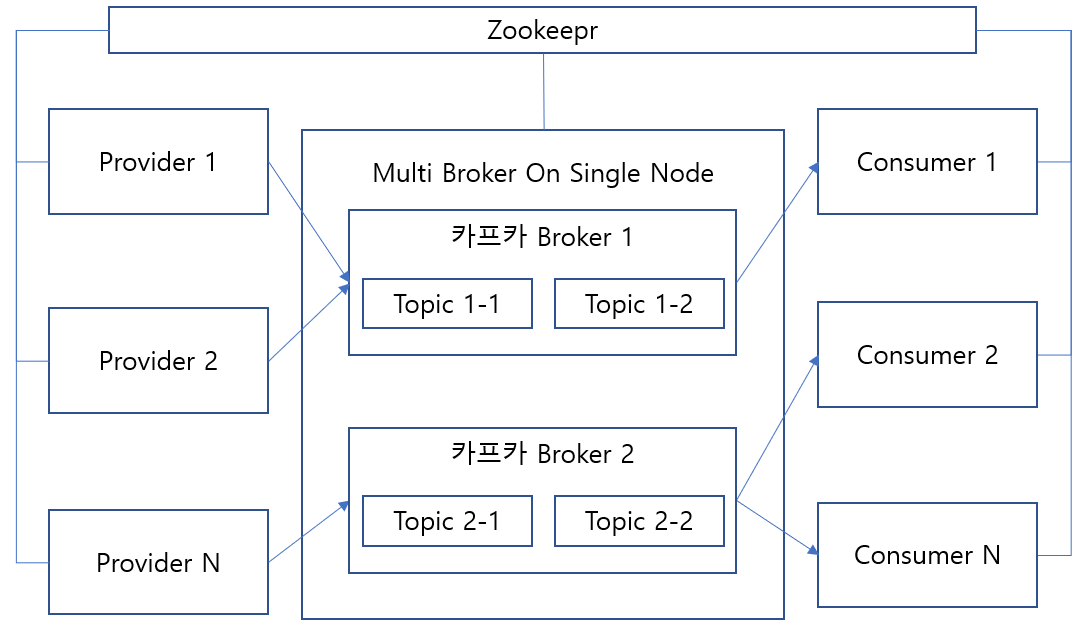
Apache Kafka는 링크드인(LinkedIn)에서 개발한 분산 스트리밍 플랫폼이다. 시스템 또는 애플리케이션간에 데이터를 안정적으로 가져오는 실시간 데이터 파이프 라인을 만들 때 주로 사용되는 오픈소스 솔루션이다. 카프카는 대용량의 실시간 로그처리에 특화되어 있는
6.스톰(Storm)
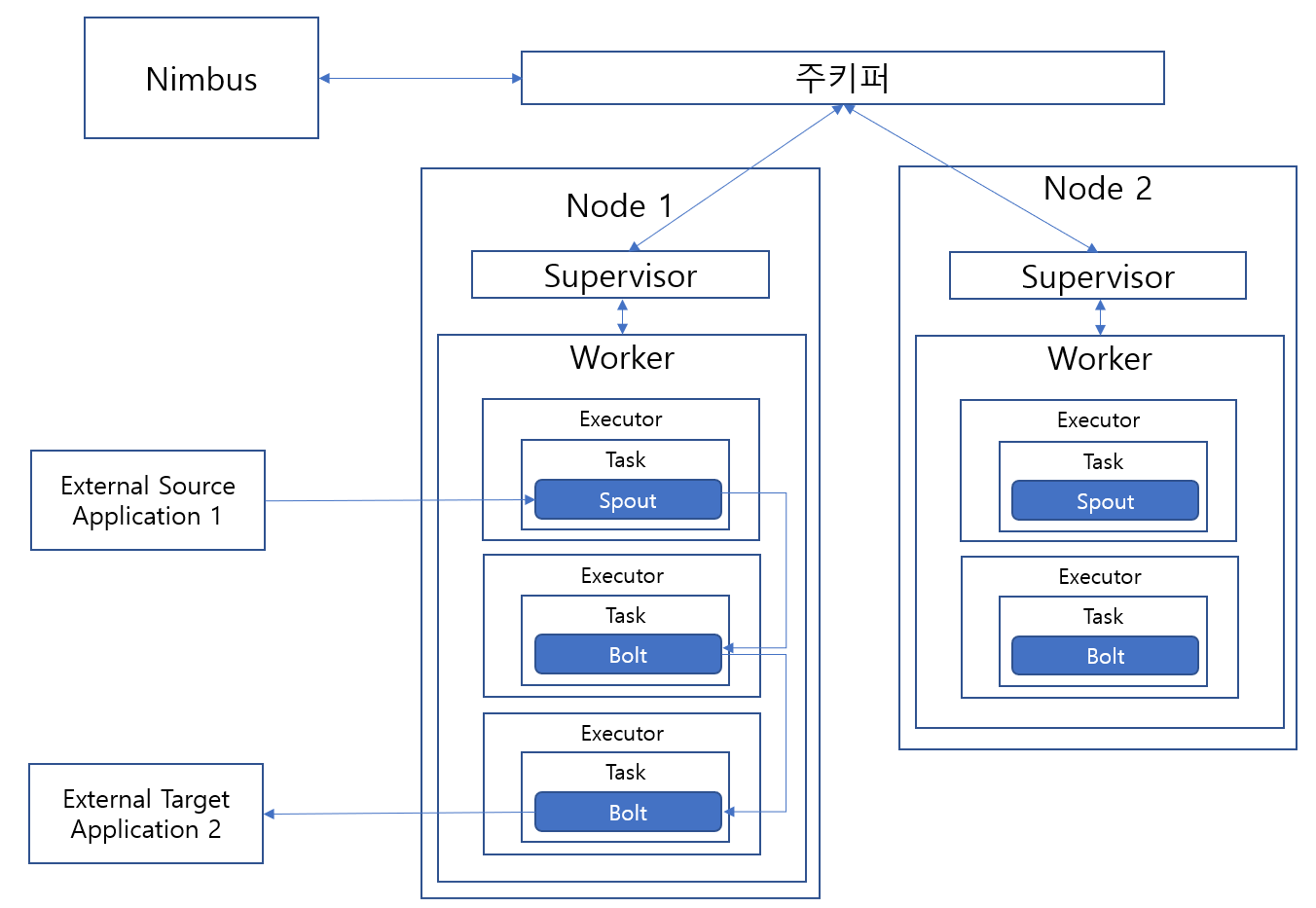
스톰은 스피드 데이터를 인메모리 상에서 병렬 처리하기 위한 소프트웨어다. 스피드 데이터는 원천 시스템의 수많은 이벤트(클릭/터치, 위치, IoT 등)가 만들어 내며, 작지만 대규모의 동시다발적이라는 특성이 있다. 스톰은 이러한 스피드 데이터를 실시간으로 다루기 위해 모
7.에스퍼(Esper)
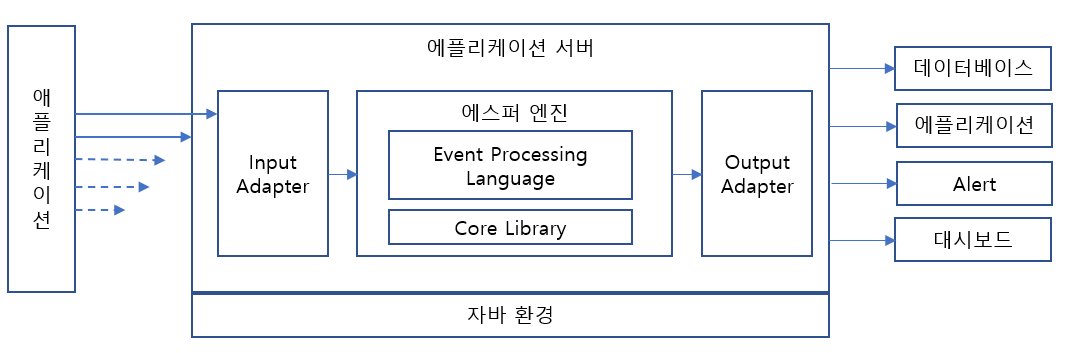
에스퍼의 경우 실시간 스트리밍 데이터의 복잡한 이벤트 처리가 필요할 때 사용하는 룰 엔진이다. 실시간으로 발생하는 데이터 간의 관계를 복합적으로 판단 및 처리하는 것을 CEP(Complex Event Processing)라고 하는데, 에스퍼가 바로 CEP 기능을 제공한
8.HBase
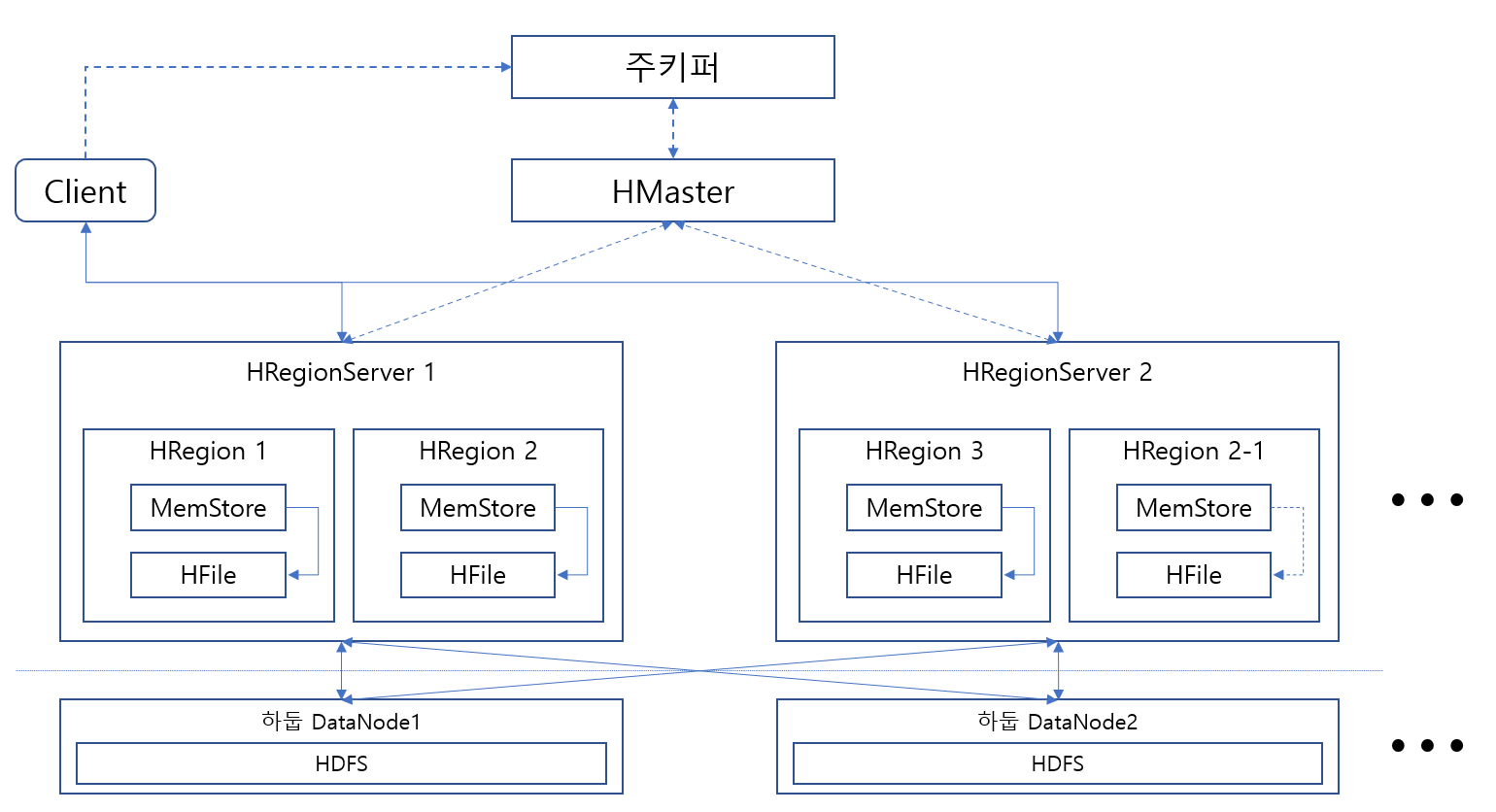
아파치 HBase는 Hadoop을 위한 공개 NoSQL 분산 데이터 베이스이다. 아파치 소프트웨어 재단에서 아파치 하둡 프로젝트 일부로서 개발되었으며 하둡의 분산 파일 시스템인 HDFS위에서 동작한다. 대량의 흩어져 있는 데이터 저장을 위해 falut-tolerent
9.레디스(Redis)
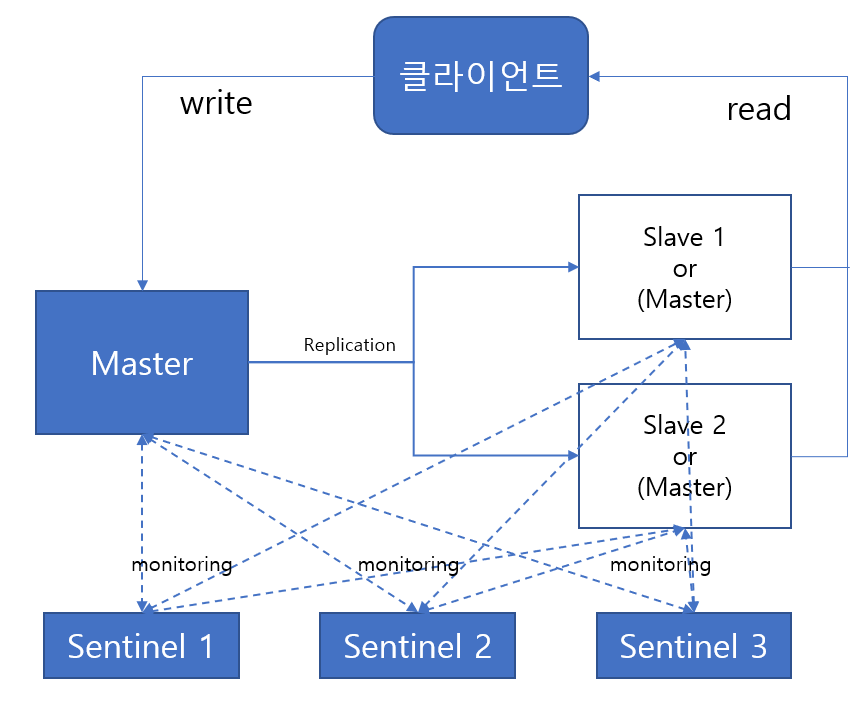
레디스는 분산 캐시 시스템이면서 NoSQL 데이터베이스처럼 대규모 데이터 관리 능력도 갖춘 IMDG(In-Memory Data Grid) 소프트웨어다. 레디스는 키/값 형식의 데이터 구조를 분산 서버상의 메모리에 저장하면서 고성능의 응답 속도를 보장한다. 인메모리 데이