SwiftData를 공부하게 된 이유
iOS에서 영구 데이터(Persistent Data) 관리는 DayBlock 프로젝트에서 CoreData를 사용해본 경험이 전부였다. 그리고 이번 아카데미 프로젝트에서 다시 한번 영구 데이터 관리가 필요한 기능 구현을 위해 대표적으로 사용되는 CoreData, Realm, SwiftData 3가지 방법을 모두 사용해보기로 했다. 추후 있을 프로젝트에서 어떤 방식을 사용할지 선택의 기준 근거가 필요했기 때문에 이런 방향성을 설정하게 됐다! 그렇게 평소 가장 관심이 컸던 SwiftData 부터 이해하며 조금씩 적용해보려 한다.
이 글에서 이해하고자 하는 목표!
- SwiftData 기본 컨셉(Schema, Container, Context) 이해하기
- CRUD 기능 구현해보기
- 어떤 상황에서 선택할 수 있는지 기준 잡기
😼 애플 공식 문서, WWDC 2023 내용을 기반으로 작성했습니당
이번에도 내가 이해한 방식대로 쉽고! 재밌게! 풀어서! 설명 하는 것을 목표로 작성해본다.
SwiftData 한 문장으로 살펴보기

이름부터가 정말 직관적이다. Swift / Data → 누가봐도 데이터 저장에 관련되어 있을 것 같다. 예상과 마찬가지로 SwiftData는 애플이 제공하는 영구 데이터(Persistent Data) Framework다.
애플 공식 문서에서 발췌한 내용으로 SwiftData를 가장 잘 표현할 수 있음과 동시에 나오게 된 배경을 이해할 수 있는 한 문장(주인장 픽)은 다음과 같다.
SwiftData - Apple Documentation
Write your model code declaratively to add managed persistence and automatic iCloud sync.
Model 코드를 선언적(declaratively)으로 작성해 영속성(persistence)을 관리 및 iCloud 자동 동기화를 추가합니다.
SwiftData로 iCloud 기능도 사용 가능해 보이긴 하나, 이번 주제에서는 다루지 않을 내용이니 슬그머니 빼주고 다시 풀어서 적어보면,
Model 코드를 선언적(Swift 언어로) 작성해 영속성(로컬에 영구 저장)을 관리할 수 있습니다.
CoreData를 사용해보지 않았다면 이 문장이 와닿지 않을 수 있다. (아니 그럼 Swift 언어로 적지 뭘로 적는다는 말이야!) CoreData는 .xcdatamodeld 이라는 파일을 Xcode에서 생성해줘야 데이터 스키마를 작성할 수 있었기에 매우 귀찮고, 직관적이지도 않을 뿐더러, 문제도 많았다!(내가 느끼기엔)
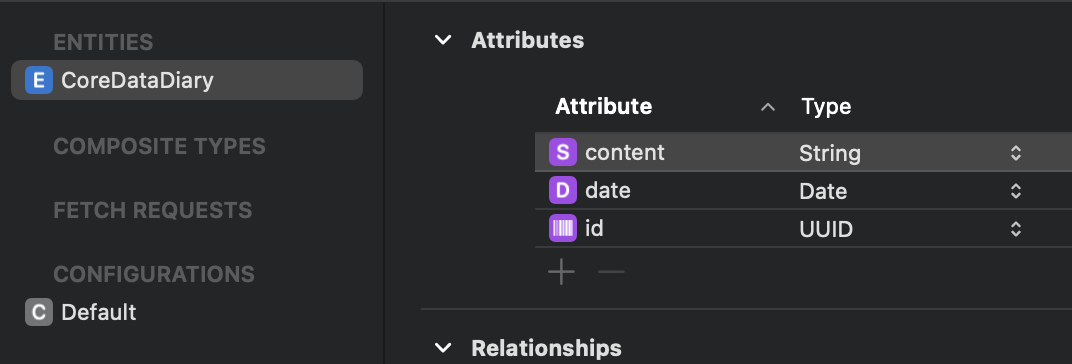
위 그림과 같이 CoreDataDiary 라는 영구 데이터 사용을 위해선 외부 파일에 각종 설정을 해줘야하는 식인 것이다.
가장 열받는 포인트는 Attribute의 사용할 수 있는 Type은 매우 제한적이라는 점이다,,
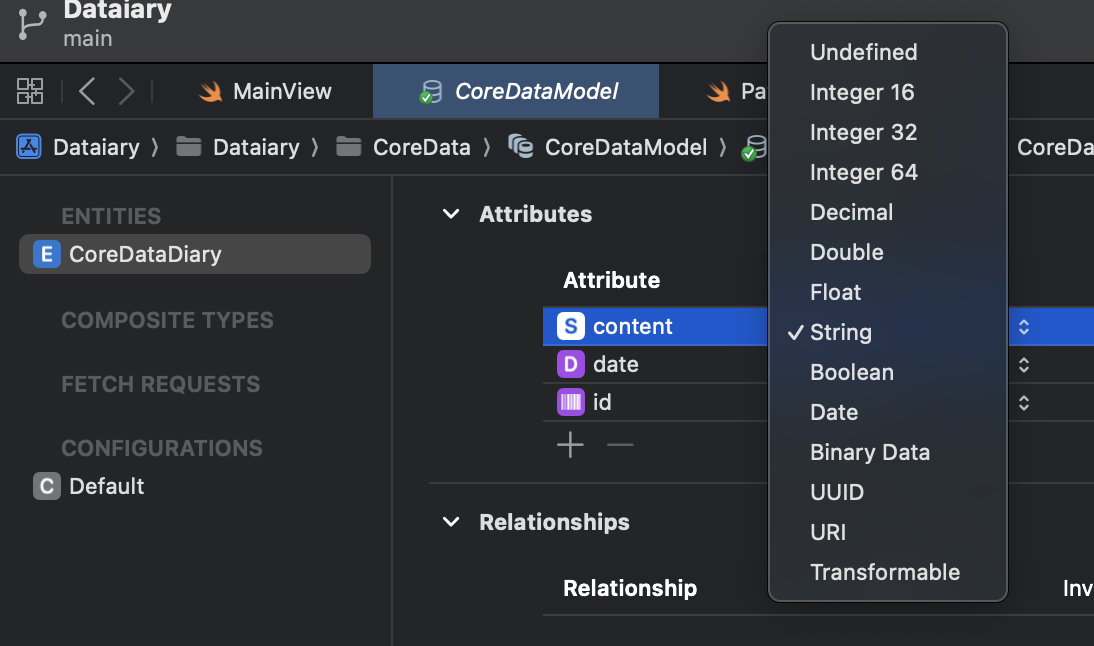
물론 기본 타입을 제공하기 때문에 많은 상황에서 문제없이 사용할 수도 있겠지만, CustomType을 사용해야하는 입장에선 난감하기 그지없다. (방법이 없는 것은 아니지만, 쉽지 않다)
물론 이밖의 Relationships 지정이라던가, 구현 자체의 어려움 등 다양한 요인들이 기존 구현 방식에 존재했다는 것을 인지하며 다시 SwiftData로 돌아와 생각해보자.
Model 코드를 선언적(Swift 언어로) 작성해 영속성(로컬에 영구 저장)을 관리할 수 있습니다.
선언적(Swift 언어)으로 작성해 영속성을 관리할 수 있는 Framework라니! 벌써 많은 것들이 쉬워진 기분이다. 실제로도 그런지 뜯어보자!
SwiftData 기본 컨셉 이해하기
SwiftData는 3가지 핵심 포인트가 존재한다. 요 3가지만 이해하면 기본 컨셉은 끝났다고 할 수 있다.
A. Schema 스키마
B. ModelContainer 컨테이너
C. ModelContext 컨텍스트
항상 이런 이름들이 어떻게, 왜 지어졌을까 유추하다보면 그 쓰임새를 더 명확히 이해할 수 있게 된다. 아카데미 러너 데이터를 만들어보며 하나씩 파헤쳐보자.
A. Schema 스키마: 데이터 설계하기
schema가 무엇인가? 정확히는 데이터 schema란 무엇일까? 위키디피아에서 참조한 schema의 뜻은 다음과 같다.
Schema(스키마)는 계획이나 도식을 가리키는 영어 낱말이다.
즉 데이터 schema란 '데이터에 대한 계획이나 도식' 을 뜻한다.
벌써 답이 나왔다!(자문자답) Schema는 우리가 보통 Model을 만들 때 사용하던 다음과 같은 코드를 뜻한다!
import Foundation
class Learner {
var studentID: UUID // 러너코드
var name: String // 이름
init(studentID: UUID, name: String) {
self.studentID = studentID
self.name = name
}
}Learner라는 class는 러너 정보 데이터에 대한 계획, 즉 데이터 Schema라고 할 수 있는 것이다. 남은 일은 SwiftData에서 어떻게 데이터 Schema를 사용 하는지 알아보는 것 뿐이다.
import Foundation
import SwiftData // 1. SwiftData 받아오기
@Model // 2. 매크로 추가
class Learner {
var studentID: UUID
var name: String
init(studentID: UUID, name: String) {
self.studentID = studentID
self.name = name
}
}이게 끝이다. 단순히 SwiftData를 import 하고, @Model 매크로를 작성해주는 것만으로 우린 SwiftData의 Schema 설계를 마쳤다. CoreData는 스키마 구현을 위해 추가적인 파일을 생성해 관리해줘야 했지만, 앞서 봤듯 SwiftData는 데이터를 선언적으로 작성이 가능하다는 것이다!
이밖의 Unique Key 지정, Relationship 모두 정말 쉽게 선언적으로(코드로) 작성 가능하다. 매크로(@) 기능을 통해 모두 구현이 가능한데, 핵심적으로 사용되는 매크로는 다음과 같다. 요것도 하나씩 뜯어보자.
- @Model
- @Attribute
- @Relationship
- @Transient
1. @Model
Model()
Converts a Swift class into a stored model that’s managed by SwiftData.
Swift Class를 SwiftData에서 관리하는 stored model로 변환합니다.
공식 문서 설명과 같이, @Model 매크로는 Swift의 class에 적용 가능하다. 아래 코드와 같이 @Model 매크로를 적용시켜주기만 하면 '이 class는 SwiftData에서 관리하려고 하는 영구 데이터이구나!' 라고 인식할 수 있게 된다.
@Model // 요거!
class Learner {
var studentID: UUID
var name: String
init() { ... }
}@Model 매크로가 적용된 class는 빌드 시 확장되어 PersistentModel 프로토콜을 준수하게 되는데, 이 프로토콜을 살펴보면 왜 매크로가 class에만 적용 가능한지 알 수 있다.
protocol PersistentModel : AnyObject, Observable, Hashable, Identifiable우선 class에서만 채택 가능한 AnyObject가 가장 먼저 눈에 띄고, 변화를 감지할 수 있는 Observable과 Identifiable도 준수하고 있음을 알 수 있다.
여기서 SwiftUI의 데이터 플로우 설계 경험이 많은 사람은 Observable 프로토콜을 보고 무엇인가 알아챘을 수도 있다! 이는 뒤에 나올 개념(View 업데이트!)과 연결지어 설명할테니 우선은 있다는 것만 알고 넘어가자.
2. @Attribute
Attribute(_:originalName:hashModifier:)
Specifies the custom behavior that SwiftData applies to the annotated property when managing the owning class.
Owning Class(소유한 클래스)를 관리할 때 SwiftData가 주석(매크로)이 달린 속성(property)에 적용할 커스텀 동작을 지정합니다.
조금 더 쉽게 풀어보자면, SwiftData Class가 가진 속성에 매크로를 추가해 커스텀 동작을 지정할 수 있다는 것이다. 어떤 커스텀 동작을 만들어줄 수 있는지 앞서 사용하던 Learner 클래스를 이용해 살을 붙여보자.
Learner 클래스는 studentID 라는 UUID 타입의 속성을 가지고 있다. 그리고 해당 속성은 유일(Unique) 해야할 것이다. (같은 러너 코드를 가진 사람이 두명이게 되면 문제가 생길테니 말이다.) 이를 @Attribute 매크로를 이용해 표현할 수 있다!
@Model
class Learner {
@Attribute(.unique) var studentID: UUID // Unique 동작 지정
var name: String
init() { ... }
}이제 studentID 속성은 유일함(Unique)이 보장되며, 같은 러너 코드를 두고 싸우는 일도 막을 수 있을 것이다. 이밖에도 다양한 옵션을 지정해 나만의 속성을 만들어줄 수 있다.
- allowsCloudEncryption: 속성 값을 암호화한 형태로 저장
- externalStorage: 속성 값을 Model Storage에 인접한 이진 데이터로 저장
- preserveValueOnDeletion: 속성 값이 삭제될 때 해당 값을 영구 기록에 보존
- spotlight: 속성 값이 Spotlight 검색 결과에 나타날 수 있도록 색인화
originalName 인수 자리에 이전 속성 이름을 넣어 가볍게 마이그레이션 할 수도 있다.
// Before
@Model
class Learner {
@Attribute(.unique) var studentID: UUID
var name: String
init() { ... }
}
// After
@Model
class Learner {
@Attribute(.unique) var studentID: UUID
// 기존 name 에서 → nickName 으로 속성 이름 변경!
// name 속성에 저장되었던 데이터들을 안전하게 nickName으로 사용이 가능함.
@Attribute(originalName: "name") var nickName: String
init() { ... }
}3. @Relationship
Relationship(_:deleteRule:minimumModelCount:maximumModelCount:originalName:inverse:hashModifier:)
Specifies the options that SwiftData needs to manage the annotated property as a relationship between two models.
SwiftData가 주석(매크로)이 달린 속성을 두 모델 간의 관계(relationship)로 관리하는데 필요한 옵션을 지정합니다.
나름 복잡한 데이터를 설계하다 보면 필연적으로 관계(Relationship)를 가진 경우를 맞이하게 된다. 우선 간단한 예제를 위해 애플 제품을 표현할 수 있는 AppleDevice class를 만들어보자.
@Model
class AppleDevice {
var deviceName: String
init() { ... }
}그리고 애플 제품을 너무나 사랑한 러너들은 '내가 어떤 애플 제품들을 가지고 있는지' 뽐내고 싶었고, 이를 데이터 스키마에 표현하길 원했다고 해보자.(실제로도 그럴 것 같다) 어떻게 표현할 수 있을까? 기존 데이터 설계 방식 그대로 생각해보면 다음과 같이 표현할 수 있다.
@Model
class Learner {
@Attribute(.unique) var studentID: UUID
@Attribute(originalName: "name") var nickName: String
var appleDevices: [AppleDevice] // 요렇게 추가
init() { ... }
}이렇게만 만들어주면 되겠지? 라고 생각할 수 있지만 이는 문제를 발생시킬 수 있다! 만약 러너 한명이 중도 퇴소를 해 Learner 데이터 하나를 지웠을 때의 상황을 가정해보자.
분명 관리자는 Learner 데이터를 삭제하는 로직을 실행했겠지만, 러너가 가지고 있는 appleDevices 데이터에 대한 처리가 없기 때문에 누가 가지고 있는지는 모를 AppleDevice 데이터가 남게되는 것이다. (왜 러너가 퇴소했는데 애플 제품이 회수가 안되지? 같은 상황이 발생할 수 있는 것이다.)
그래서 SwiftData는 관계를 설정함과 동시에, 삭제 규칙을 정할 수 있도록 @Relationship 매크로를 제공한다.
@Model
class Learner {
@Attribute(.unique) var studentID: UUID
@Attribute(originalName: "name") var nickName: String
// AppleDevice와의 relationship 설정 + 삭제 규칙 설정(모든 데이터 삭제)
// 애플 디바이스를 가지고 있을 수도, 없을 수도 있기에 옵셔널 타입으로 선언했다.
@Relationship(deleteRule: .cascade) var appleDevices: [AppleDevice]?
init() { ... }
}💡 그럼 그냥 @Relationship만 작성하면 어떤 효과가 있나요?
영구 데이터로의 '접근'을 제공한다. appleDevices 속성을 이용해 실제 영구 저장 데이터 [AppleDevice] 에 접근해 데이터 컨트롤이 가능하다는 것! (ex: learner.appleDevices?.first)
이제 Learner 데이터가 삭제되면, 관련되어 있는 appleDevices의 데이터도 함께 삭제될 것이다. @Relationship의 deleteRule 인수 자리에 사용할 수 있는 삭제 규칙의 목록은 다음과 같다.
- cascade: 관련 모델을 삭제하는 규칙
- deny: 다른 모델과 하나 이상 참조되어있으므로 삭제를 방지하는 규칙
- noAction: 관련 모델을 변경하지 않는 규칙(아무 효과 없음)
- nullify: 삭제된 모델에 대한 관련 모델의 참조를 무효화하는 규칙
관계 설정 까지 끝났으니 뭐가 더 남았겠어! 라고 생각했을 수 있지만 또 한가지 러너들의 부탁이 생겼다고 해보자. 애플 기기마다 어떤 러너가 사용 중인지 파악할 수 있는 로직을 추가를 요청 받았다.
이럴 때는 데이터의 inverse(역) 관계를 설정해주면 된다.
@Model
class Learner {
@Attribute(.unique) var studentID: UUID
@Attribute(originalName: "name") var nickName: String
// inverse를 KeyPath로 접근해 연결해줬다.
@Relationship(deleteRule: .cascade, inverse: \.AppleDevice.learner) var appleDevices: [AppleDevice]?
init() { ... }
}
@Model
class AppleDevice {
var deviceName: String
// AppleDevice에서 접근 가능한 learner
// 생성 당시 어떤 러너에게 소유될지 알 수 없기에 옵셔널로 선언했다.
var learner: Learner?
init() { ... }
}이젠 AppleDevice에서도 Learner 데이터에 접근 가능해졌다. 이렇게 삭제 규칙과 inverse 설정을 통해 영구 저장 데이터 간의 Relationship 설정까지 알아봤다.
4. @Transient
Transient()
Tells SwiftData not to persist the annotated property when managing the owning class.
Class를 관리할 때 주석(매크로)이 달린 속성을 유지하지 말라고 SwiftData에 말합니다.
말 그대로 영구 저장할 필요가 없는 데이터에 추가할 수 있는 매크로다. 예를 들어 AppleDevice가 켜져있는지 꺼져있는를 표시할 수 있는 속성 값 isActive는 영구 저장할 필요가 없을 수 있다. 그럴 때 다음과 같이 매크로를 이용할 수 있다.
@Model
class AppleDevice {
var deviceName: String
var learner: Learner?
// Transient 매크로를 이용해 영구 저장이 필요없는 속성 값을 선언해줬다.
@Transient var isActive = false
init() { ... }
}여기서 중요한 점은 Transient 매크로를 이용한 속성값엔 항상 기본값이 있어야 한다! 생각해보면 당연한게 영구 저장되어 있지 않으면 불러올 수 있는 값도 없기에 기본값이 항상 있어야 성립할 수 있을 것이다.
추가로, Computed properties(계산 속성)을 사용한다면 기본적으로 Transient(일시적인) 데이터로 간주하기 때문에, 매크로를 따로 구현해 줄 필요가 없다고 한다.
B. ModelContainer 컨테이너 : 패키징과 중개
Schema 구현에 관한 이야기만 벌써 잔뜩 나와버렸다. (도대체 언제 CRUD 알려줄건데!!!) 다음은 ModelContainer에 관한 설명이다. 이번에도 이름이 왜? ModelContainer로 지어졌는지 생각해보자.
컨테이너는 무엇인가? 일반적으로 화물 운송에 주로 사용하는 큰 상자 같은 것으로 내용물을 안전히(특정 목적을 위해) 패키징 해 이동시키는 역할을 수행한다. 개발 분야에서 사용하는 Container 도 현실 세계의 멘탈 모델과 유사한 정의를 내린다.
애플이 정의하는 ModelContainer는 다음과 같다.
ModelContainer- Apple Documentaion
An object that manages an app’s schema and model storage configuration.
앱의 Schema 및 Model 저장소 Configuration(구성)을 관리하는 개체입니다.
위 내용은 어떤 것(Schema, Configuration)을 Container 안에 패키징 하느냐에 대한 정의로 볼 수 있다. 그리고 현실 세계의 컨테이너처럼 패키징한 내용을 '이동' 시키는 역할도 수행하게 되는데, 다음 내용이 이에 해당한다.
A model container mediates between its associated model contexts and your app’s underlying persistent storage.
Model Container는 관련 Model Context와 App의 기본 영구 저장소 사이에 위치합니다.
즉, ModelContainer는 패키징한 내용(Schema, Configuration)을 ModelContext와 영구 저장소 사이에 위치하며 중개자 역할을 하고 있는 것이다. 내가 이해한 내용을 바탕으로 간단한 그림을 그려봤다. (ModelContext에 대한 설명은 컨테이너 설명이 끝나고 진행하니 일단은 저런게 있다는 것만 알고 넘어가보자!)

그럼 이제 직접 ModelContainer를 만들어보자. 앞서 설명했듯 ModelContainer는 Schema와 Configuration를 패키징해야 한다.
Schema는 앞서 사용한 Learner와 AppleDevice 클래스를 사용하면 될 것 같고,,, Configuration은 무엇이고 또 어떻게 만들어줄 수 있을까? 아래 예시 코드를 통해 기본적인 개념과 방법을 알아보자.
import SwiftData
var modelContainer: ModelContainer = {
// 1. Schema 생성
let schema = Schema([Learner.self, AppleDevice.self])
// 2. Model 관리 규칙을 위한 ModelConfiguration 생성
let configuration = ModelConfiguration(schema: schema, isStoredInMemoryOnly: false)
// 3. ModelContainer 생성
do {
let container = try ModelContainer(for: schema, configurations: [configuration])
return container
} catch {
fatalError("ModelContainer 생성 실패!!!: \(error)")
}
}()주석에 표시한 단계별로 하나씩 풀어서 살펴보자.
1. Schema 생성
이전에 생성해둔 Learner와 AppleDevice 클래스 타입을 컬렉션으로 넣어줌으로써 어떤 데이터 스키마를 사용할 것인지 지정해 준다.
let schema = Schema([Learner.self, AppleDevice.self])💡 사실 배열 안에
Learner.self만 추가해줘도 원하는 동작으로 구현이 가능하다!
SwiftData가 컴파일 단계에서AppleDevice클래스와Relationship이 설정되어있음을 추론할 수 있기 때문에, 자동으로 스키마에 추가되는 것! 위 코드는 여러 예시 상황을 보여주기 위해 작성해봤다.
2. ModelConfiguration 생성
먼저 ModelConfiguration 이 무엇인지 알 필요가 있다. Configuration 의 뜻은 구성으로, 애플 공식 문서에서 이야기하는 정의는 다음과 같다.
ModelConfiguration - Apple Documentation
A type that describes the configuration of an app’s schema or specific group of models.
App의 Schema 또는 특정 Model 그룹의 구성(Configuration)을 설명하는 타입입니다.
쉽게 풀어보자면, 영구 저장 데이터 관리를 위한 설정이라고 생각할 수 있다. ModelConfiguration은 이와 같은 설정을 위해 여러 속성값을 제공하고 있다.
- url: Schema의 영구 저장소의 디스크상 위치
- name: ModelConfiguration의 이름
- allowsSave: 영구 저장소의 쓰기(Writable) 가능 여부를 결정하는 Bool 값
- isStoredInMemoryOnly: 메모리에만 일시적으로 저장할지를 결정하는 Bool 값
다시 돌아와 위 코드에서는 ModelConfiguration 생성을 위한 schema와, isStoredInMemoryOnly 매개 변수를 설정해줬다. 러너 데이터가 영구적으로 저장되길 바라기 때문에 false로 설정해 준 것! (반대로 MockData를 만들 때는 true로 설정해주면 불필요한 저장을 막을 수 있다.)
let configuration = ModelConfiguration(schema: schema, isStoredInMemoryOnly: false)3. ModelContainer 생성
이제 ModelContainer 생성을 위한 모든 준비가 끝났다! Schema와 Configuration을 ModelContainer 생성자에 넣어 주면 끝!
let container = try ModelContainer(for: schema, configurations: [configuration])4. 아직 안.끝.났.다!
이렇게 만들어준 ModelContainer를 사용하려면 어떻게 해야할까? Container는 중개해주는 역할을 할 뿐 그 자체로 쓰임새를 가지진 않는다. 결국 위 그림에서 봤던 것처럼 ModelContext에 연결해주는 역할을 수행해야 하는데, 이는 view modifier를 이용해 설정이 가능하다.
modelContainer(for:inMemory:isAutosaveEnabled:isUndoEnabled:onSetup:) view Modifier를 이용해 Modelcontainer를 주입하게 되면, 해당 View에서 Model Container를 설정하고(필요하다면 새로 생성) 해당 컨테이너에 대한 ModelContext Environment도 설정해 준다.
전역적으로 어디에서든 방금 만든 ModelContainer를 이용해 ModelContext에 접근이 가능해진다는 말이다!
ModelContainer를 생성하고, 주입하는 전체 코드를 보며 마무리해보자.
import SwiftUI
import SwiftData
@main
struct AcademyApp: App {
var modelContainer: ModelContainer = {
let schema = Schema([Learner.self])
let configuration = ModelConfiguration(schema: schema, isStoredInMemoryOnly: false)
do {
return try ModelContainer(for: schema, configurations: [configuration])
} catch {
fatalError("ModelContainer 생성 실패!!!: \(error)")
}
}()
var body: some Scene {
WindowGroup {
ContentView()
}
// 전역적으로 사용할 영구 데이터이기 때문에, WindowGroup에 주입!
.modelContainer(modelContainer)
}
}C. ModelContext 컨텍스트 : 데이터 실제로 만지기
꽤나 긴 여정이었다. 우리는 이제 SwiftData가 거시적으로 어떻게 동작하는지에 대해 약간의 감을 잡게 되었다!(아마도,,, Maybe,,,) 마지막 개념 정리는 우리가 가장 많이 사용하게 될 ModelContext에 대한 이야기다. 바로 고고싱!
Context는 맥락, 문맥이라는 뜻을 가지고 있다. 나는 '맥락'이라는 단어 자체의 느낌, 맥락이라는 단어의 맥락(?)은 대충 알고 있지만 정의에 대해서는 역시 공식 문서(Oxford)를 참조해보기로 했다.
context?
The situation in which something happens and that helps you to understand it.
어떤 일이 일어나고 그것을 이해하는 데 도움이 되는 '상황'
음~ 그럼 ModelContext는 Model에 어떤 일이 일어났고, 그것을 이해하는데 도움이 되는 객체인건가? 이번엔 애플 공식 문서를 뜯어보도록 하자.
ModelContext - AppleDocumentation
An object that enables you to fetch, insert, and delete models, and save any changes to disk.
Model을 fetch하거나 insert 및 delete하고, 디스크에 변경사항을 save 할 수 있는 객체입니다.
결국 영구 저장소에는 fetch, insert, delete, update 등 다양한 '어떤 일'이 일어날 수 있고, 이를 컨트롤 할 수 있는 것이 ModelContext라는 객체인 것이구나! 라고 이해해볼 수 있다.
공식 문서에서도 ModelContext는 영구 데이터 모델의 전체 LifeCycle을 관리하는 역할이기 때문에 SwiftData의 핵심이라 이야기 하고 있다.
실제로 ModelContext는 Model에 대한 변경사항을 추적하고 유지한다.
그리고 가장 중요한 컨셉은, 영구 저장소에 암묵적으로(implicit) 쓰거나(writes) 수동으로 저장(save())하기 전까지 변경 사항은 메모리에만 존재하게 된다!!!
이 말이 무슨 뜻일까? 변경 사항이 메모리에만 존재한다니,,? 아래 WWDC 2023 - Dive deeper into SwiftData에서 가져온 예시를 통해 이해해보자.
우선 위 그림은 ModelContext가 리스트에서 사용 중인 데이터를 fetch 해왔을 때 상태다. View가 List에 데이터를 로드할 때 각 데이터 객체를 ModelContext에 불러오는 것!
만약 새로운 데이터를 insert(추가) 하면 어떻게 될까?
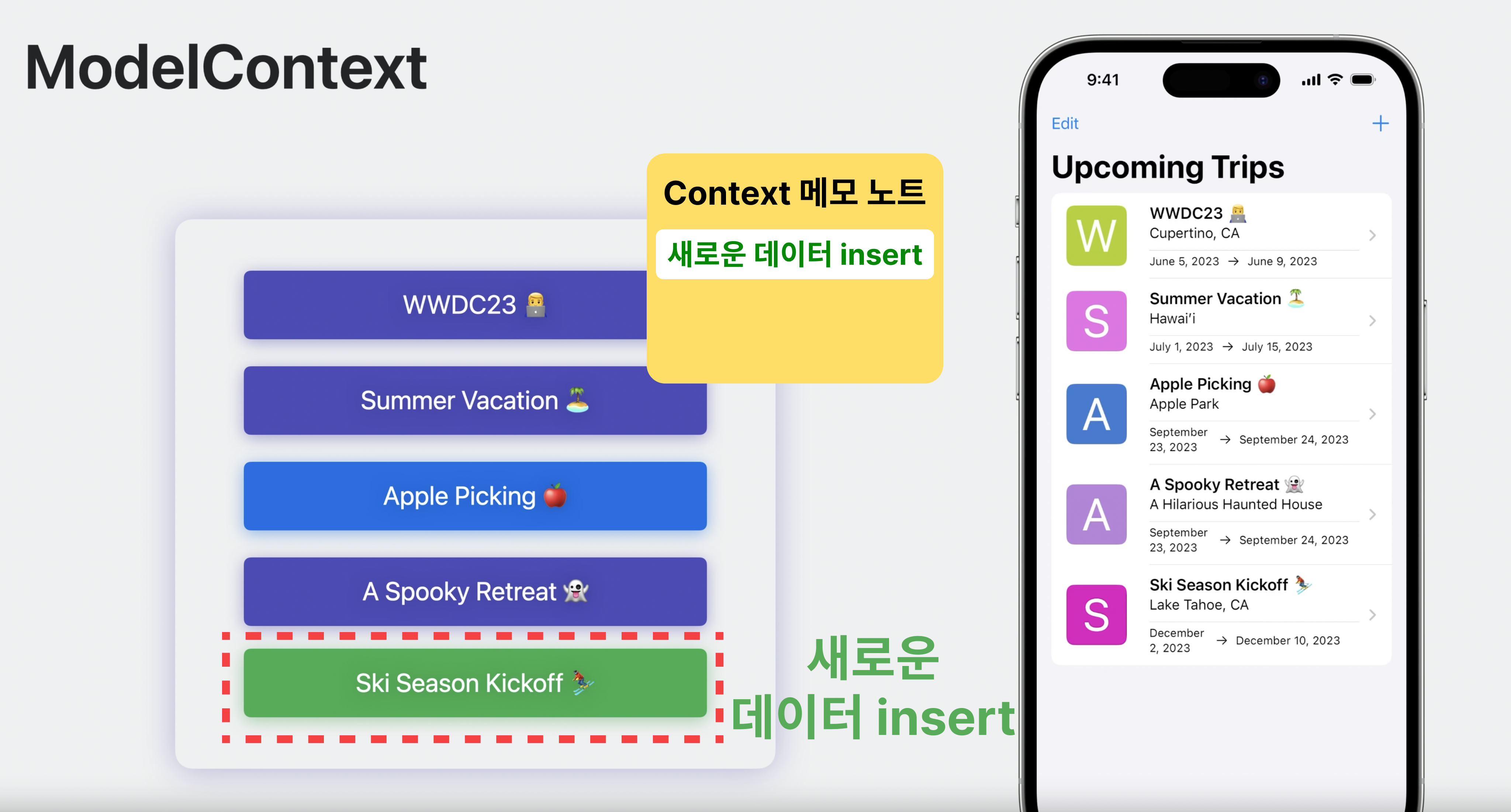
ModelContext는 새로운 데이터가 추가되었다는 사실을 기록해놓는다!(위 그림에서는 색상 변경으로 insert 되었다는 정보를 표현하고 있다)
여기서 짚고 넘어가야할 포인트는 아직 영구 저장소에 새로운 데이터가 추가 된 것이 아니라는 것이다. ModelContext에만 새로운 데이터 추가에 대한 정보가 들어온 것(메모리에만 존재!)으로, 실제 영구 저장소에 저장하려면 암묵적(implicit)으로 쓰거나(writes), 수동으로 저장(save()) 해야한다는 것이다.
그렇다면 암묵적으로 쓴다는 의미가 어떤 것인지 궁금해진다. 답은 ModelContext의 자동 저장 여부를 결정하는 autosaveEnabled 프로퍼티에서 찾을 수 있었다.
자동 저장이 허용된 경우, 즉 암묵적 쓰기에 대한 정의는 데이터가 삽입(insert)되거나 등록(register)된 Model을 변경하면 ModelContext에서 save()를 호출한다고 한다. 또한 windows, scenes, views, sheet의 LifeCycle 등의 다양한 시간 동안에도 save()를 호출한다고 한다.
거의 웬만한 경우에 자동으로 save()를 호출해주는 것이라 생각해볼 수도 있는데 이 때문에 애플은 WWDC에서 자신만만하게 저장을 굳이 하지 않아도 되는 것이라 이야기했던 것 같다.(자신감 대박)
결국 SwiftData가 얼마나 자주 save()를 호출해주는 것인지 정확히 알 수는 없지만, 우리가 크게 신경 쓰지 않아도(ModelContext를 이용해 데이터 조작만 해도) 영구 데이터 관리에 문제가 없을 것으로 예상된다.
💡 그럼 언제 명시적으로
save()를 호출해줘야 할까?
애플은 Model 전체를 전달해야하거나 등의 작업이 필요할 때 save()를 호출하라고 이야기했다!
다시 돌아와 ModelContext는 데이터를 삭제할 때도 아래 그림과 같이 삭제 되었는다는 '정보'만 가지고 있을 것이다.

이와 같이ModelContext 는 데이터에 어떤 일(삽입, 업데이트, 삭제 등)이 일어나는지 기록하고 있다. 데이터의 맥락(context)을 자유롭게 사용할 수 있게 하는 객체로써, 이러한 기록을 바탕으로 Undo, Redo 기능 구현도 자연스레 적용이 가능하다.
그리고 이전에 우리는 ModelContainer를 전역적으로 주입해줬었다.(기억 나시죠?) 이를 이용해 ModelContext를 View에서 사용 가능하다!
struct LearnerView: View {
// 바로 요렇게 말이다!
@Environment(\.modelContext) private var modelContext
}이제 남은 것은 요놈을 가지고 어떻게 실제 데이터를 가지고 놀지 아는 것이다.
CRUD 기능 구현해보기
내가 느낀 SwiftData의 CRUD 기능 구현은 정말 쉬웠다! 그도 그럴 것이 Swift 코드로 만들어진 스키마(class)와 동일한 이름과 타입으로 모든 것을 작성할 수 있다보니 표현식 자체도 매우 직관적이고, 따로 설정해줘야 할 것들도 SwiftData가 알아서 해준다는 느낌,, 이었다.
아마도 가장 많은 분들이 궁금해할, 그래서 어떻게 쓰는건데?에 대한 부분을 코드와 함께 뽀개보자.
- Insert(Create)
- Fetch(Read)
- Update(Update )
- Delete(Delete)
1. Insert(Create)
modelContext.insert() 메서드를 통해 배열에 데이터를 넣는 것만큼이나 간단하게 데이터 추가가 가능하다. 위에서 말했듯이 save()를 명시적으로 호출해주지 않아도 잘 저장이 된다.
func createLearner() {
// 새로운 Learner 생성
let newLearner = Learner(nickName: "한톨")
// ModelContext에 새로운 데이터 추가 알림
modelContext.insert(newLearner)
}2. Fetch(Read)
Fetch 또한 modelContext.fetch()를 이용해 수행 가능하다.
func readLearner() -> [Learner] {
do {
// Learner 모든 데이터 반환
let learners = try modelContext.fetch(FetchDescriptor<Learner>())
return learners
} catch {
print("Learner 데이터를 찾을 수 없습니다.")
return []
}
}여기서 눈여겨 봐야할 것은 fetch 함수의 매개 변수로 들어가는 FetchDescriptor 객체다. FetchDescriptor는 fetch를 수행할 때 사용할 기준, 정렬 순서 및 추가 설정을 지정할 수 있는 타입으로, 위 코드에선 따로 지정해주지 않고 전체 [Learner] 데이터를 받아올 수 있게 구현해줬다.
그럼 닉네임에 '톨'이 포함되는 러너를 나이순으로 받아오는 이상한 요구사항을 위해선 어떻게 코드를 작성해줄 수 있을까? (원래 Learner 스키마에 나이 속성은 없었지만 예제를 위해 급하게 추가했다)
func readLearnerWithTolTol() -> [Learner] {
do {
// 1. 필터링 기준 : nickName에 '톨' 이 들어가는가?
let predicate = #Predicate<Learner> { $0.nickName.contains("톨") }
// 2. 정렬 기준 + 순서 : 나이 + 오름차순으로 정렬해줘!
let sort = SortDescriptor(\Learner.age, order: .forward)
// 3. FetchDescriptor 생성 후 Fetch!
let descriptor = FetchDescriptor(predicate: predicate, sortBy: [sort])
return try modelContext.fetch(descriptor)
} catch {
print("이름에 톨이 들어가는 러너는 없는걸요")
}
}Predicate를 이용해 필터 기준을 지정하고, SortDescriptor를 이용해 정렬 기준 및 순서를 지정해줬다. 이 두개를 적절히 활용할 수 있다면 대부분의 요구사항에서 데이터를 받아오는데 전혀 문제가 없을 것이다!
하지만 사실 애플은 우리에게 더 편한 방법을 제공하고 있다.(????????? 아니 왜 지금 말한는건데???!) 전체 데이터 조작을 모두 ModelContext 로 가능하다는 사실을 알고 넘어가는게 학습에 더욱 효과적이라 생각했기 때문이다.(주인장 맴)
그 마법과 같은 방법이 바로 @Query 매크로다!
@Query는 SwiftData가 제공하는 매크로로, 이를 이용해 코드는 훨씬 간결하게 유지하면서도, 위에서 살펴본 Fetch 요구사항을 모두 만족시킬 수 있다!
바로 요렇게 말이다!
struct LearnerView: View {
// 전체 Learner 데이터 반환
@Query var learners: [Learner]
// nickName에 '톨'이 포함되고, 나이 오름차순으로 정렬된 Learner 데이터 반환
@Query(filter: #Predicate<Learner> {
$0.nickName.contains("톨")
}, sort: \Learner.age, order: .forward) var learners: [Learner]
}@Query 매크로를 사용하면 ModelContext에 접근하지 않고도 Learner 데이터를 모두 동일하게 받아올 수 있다. 이게 가능한 이유는, @Query 매크로 내부적으로 저장소 데이터와 동기화된 상태를 유지하는 로직이 들어가 있기 때문이라고 한다. (애플이 강추하는 방법이기도 하다)
추가로 위에서 설명했던 @Model 매크로가 기억나는가? @Model 매크로를 class에 적용하면 자연스레 PersistentModel 프로토콜을 준수하게 되고, 그 안에는 Observable 프로토콜도 포함 되어 있었다!!!
protocol PersistentModel : AnyObject, Observable, Hashable, Identifiable이 말인 즉슨, 데이터의 변화를 감지 할 수 있다는 뜻이고 이를 이용해 View를 업데이트 할 수도 있다는 것이다!
예상처럼 @Model 매크로가 적용된 SwiftData 클래스에 업데이트가 발생하면, SwiftUI는 이를 감지하고 View를 새로 그려주게 된다.(ModelContext를 이용하거나 @Query를 이용하거나 똑같이 업데이트 해준다!)
마치 @State 프로퍼티 래퍼를 사용하듯 데이터에 어떤 변화를 주면 되는지에 대해 더 신경쓰면 되는 것이다.
🤔
ModelContext.fetch()와@Query가 정확히 똑같은 로직으로, 똑같은 횟수 업데이트해주는 건지는 불확실하다. 단지 데이터에 변화가 생기면 업데이트 해준 다는 것이 확실할 뿐이다!
++ 이에 대해서는 추가적인 공부가 필요할 듯 하다. (알고 계신 분은 댓글로 알려주세요~!)
3. Update(Update)
어떤 데이터를 update() 할지 잘 지정해줄 수 있으면 다른 어떤 동작보다 구현이 쉽다!
ModelContext를 이용해 업데이트 하지 않고 데이터 자체만 업데이트 해주면 자동으로 ModelContext에 기록됨과 동시에 View도 업데이트 된다.
마찬가지로 save()를 명시적으로 호출해주지 않아도 된다.
/// index: 업데이트 할 Learner index
func updateLearner(to index: Int) {
// 업데이트 할 Learner 데이터
// 위에서 만든 @Query를 이용해 fetch해옴.
let learner = learners[index]
// 업데이트
learner.nickName = "두톨"
}4. Delete(Delete)
드디어 마지막이다!(힘내힘내) update와 마찬가지로 어떤 데이터를 delete() 할지 잘 지정해주면 문제 없다.
ModelContext를 이용해 삭제해줄 수 있으며, 얘 또한 save()를 명시적으로 호출해주지 않아도 되니 걱정말자.
/// index: 삭제 할 Learner index
func deleteLearner(to index: Int) {
// 삭제 할 Learner 데이터
// 위에서 만든 @Query를 이용해 fetch해옴.
let learner = learners[index]
// ModelContext를 이용한 삭제
modelContext.delete(learner)
}어떤 상황에서 선택할 수 있는지 기준 잡기
WWDC 2023에서 발표된 따끈따끈한(이젠 2024년이니 조금은 식었으려나) 애플의 최신 영구 데이터 저장 Framework를 얕게나마 공부해봤다.
직접 사용해보며 경험한 내용과 공식적인 내용을 섞어 나름대로 정리를 해보자면,
✅ SwiftData 사용을 추천해요!
- SwiftUI로 개발을 진행할 때 - UIKit과도 사용이 가능하지만, SwiftUI의 View 업데이트 로직과 매우 잘맞는다고 느꼈다.
- 최소 지원 Target이 17.0 이상일 때 - 아쉽게도 17.0 아래의 버전은 SwiftData를 지원하지 않는다.
- 외부 라이브러리(종속성) 추가가 망설여 질 때 - 대표적으로
Realm과 같은 외부 라이브러리에 대한 리스크를 줄이고자 할 때. - 오로지 선언적(Swift)으로 영구 데이터 스키마 정의하고자 할 때 -
CoreData의 경우 추가적인 파일 생성을 부른다. - 마이그레이션이 자주 필요할 때
CoreData에 비해 마이그레이션의 난이도가 훨씬 쉽다!(요건 나중에 다뤄보도록 하겠슴당)
❌ SwiftData 사용을 한번 더 고민해봐요,,,
- 최소 지원 Target이 17.0 미만일 때 - 위에서 이야기한 것처럼 사용이 불가하다.
- 데이터를 시각적으로 보기 원할 때 -
Realm라이브러리의 경우 추가적인 tool을 제공해 테이블을 시각화할 수도 있다! - 최신 프레임워크에 대한 불확실성을 줄이고자 할 때 - 아직 세상에 나온지 1년 밖에 안됐기 때문에 안정성의 문제가 있을 수도 있다.(실제로도 문제를 제기하는 목소리가 꽤나 있다)
SwiftData를 찍먹해보며,,,
SwiftData를 사용하면 확실히 CoreData를 사용하는 것보다 생산성이 훨씬 올라감을 느꼈다. 물론 작은 프로젝트에서의 얕은 활용이었기 때문에 그럴 수도 있겠지만, 애플이 추구하는 슈퍼 이지함이 무엇인지는 체감할 수 있었다.
공식 문서에 Deep 한 동작 방식 까지 기술되어 있지 않아 아쉬운 부분이 있었지만, 블로그 포스팅을 위해 찬찬히 들여다보며 전체 맥락에 대한 이해는 처음과 비교했을 때 꽤나 높아짐을 느낀다.
다음에 다시 SwiftData에 대해 다룰 수 있다면, 마이그레이션과 @Query 호출 방식에 대한 포스팅을 해보고 싶다.
애플 디벨로퍼 아카데미 @POSTECH에서 진행한 프로젝트에서 SwiftData를 활용한 간단한 프로젝트 - Dataiary가 있어 슬쩍 포스팅에 끼워넣으며 이번 포스팅도 마쳐보도록 하겠다!!!
😆 작은 관심과 피드백은 제게 블로그 포스팅을 위한 원동력이 됩니다! 감사합니다 :)
