정규화가 무엇인가요?
데이터 중복을 없애고 한 곳에 데이터를 관리하는 작업입니다. 한 곳에서 관리하게 되면 부정합이 발생하지 않습니다. 하지만, 데이터를 조회할 때 원본 데이터를 참조해야 한다는 단점이 있습니다.
테이블 설계 과정은 조회와 쓰기 사이 트레이드 오프하는 행위이기 때문에 정규화할지, 비정규화할지 고민할 필요가 있습니다. 쓰기가 많은 경우 중복 데이터를 줄일 수 있는 정규화가 효과적이고, 읽기가 많은 경우 결합 연산을 줄이는 비정규화가 효과적이다.
제 1 정규화란?
attribute의 value는 반드시 나눠질 수 없는 단일 값이어야 한다.
한 칸에 하나의 데이터만 넣습니다. 이 조건을 만족하지 않으면 데이터를 찾기 어렵고, 수정하기도 어렵습니다.

제 2 정규화란?
모든 non-prime atrribute는 모든 key에 fully functionally dependent 해야 한다.
현재 테이블의 주제와 관련없는 attribute를 분리합니다. (partial dependency를 제거한 테이블을 의미합니다.) 이 조건을 만족하지 않으면 하나의 데이터를 수정할 때, 다른 컬럼의 데이터도 같이 수정해야 하기 때문에 관리가 어려워집니다.

의존되는 attribute 단위로 관리하면 데이터 수정 범위를 줄일 수 있습니다.
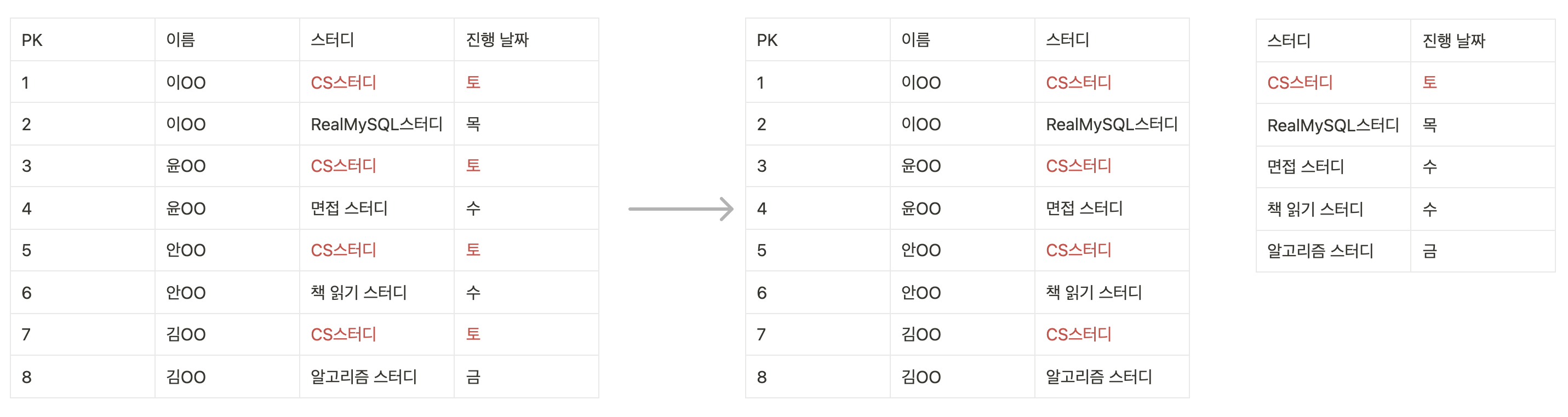
제 3 정규화란?
모든 non-prime attribute는 어떤 key에도 transitively dependent하면 안된다.
일반 attribute 에만 종속된 컬럼을 다른 테이블로 빼는 방법입니다. 제 3 정규형을 만족하면 데이터 수정 범위를 줄일 수 있습니다.

이미 정규화된 DB의 조회 성능을 어떻게 높을 수 있을까요?
CQRS 패턴을 만족하거나 캐싱하는 방식이 있습니다.CQRS는 데이터 저장소에 대한 읽기 및 업데이트 작업을 구분하는 패턴인 명령과 쿼리의 역할 분리를 의미합니다.
CQRS는 데이터 저장소에 대한 읽기 및 업데이트 작업을 구분하는 패턴인 명령과 쿼리의 역할 분리를 의미합니다.
