MongoDB 의 유래, 특징, 배포 방식과 차이점 및 전략에 대해서 알 수 있습니다.
유래
- 빅 데이터가 등장하면서 데이터의 양이 급격히 증가했고 기존의 SQL 데이터베이스 시스템은 대규모 데이터 처리에 한계
- 분산 처리의 필요성
- 기존 SQL 데이터베이스 시스템의 정해진 데이터 스키마를 따라야 제약이 유연성과 확장성을 제한하였고, 이에 유연성과 확장성의 필요성이 대두
따라서, 이러한 이유로 MongoDB는 대규모 데이터 처리와 분산 처리에 특화되어 있으며, 유연성과 확장성이 높은 NoSQL 데이터베이스 시스템으로 개발되었습니다.
특징
스키마 자유도
MongoDB는 스키마 자유도가 높습니다. 즉, 데이터베이스에 저장되는 문서의 구조나 필드를 미리 정의할 필요가 없습니다. 이는 데이터베이스의 유연성을 높여주며, 데이터베이스 설계와 관리를 단순화합니다.
샤딩(Sharding) 지원
MongoDB는 대규모 데이터 처리를 위해 샤딩(Sharding)이라는 기능을 제공합니다. 이를 통해 데이터를 분산하여 저장하고 처리할 수 있으며, 이를 통해 데이터베이스의 처리 속도와 확장성을 높일 수 있습니다.
다양한 인덱싱(Indexing) 기능
MongoDB는 다양한 인덱싱(Indexing) 기능을 제공합니다. 이를 통해 데이터베이스의 검색 속도를 높일 수 있으며, 데이터베이스의 성능을 개선할 수 있습니다.
복제(Replication) 기능
MongoDB는 데이터베이스의 가용성을 높이기 위한 복제(Replication) 기능을 제공합니다. 이를 통해 데이터베이스 서버가 다운되었을 때에도 다른 서버에서 데이터베이스를 계속 사용할 수 있습니다.
풍부한 쿼리(Query) 기능
MongoDB는 SQL과 비슷한 쿼리(Query) 언어를 사용하여 데이터베이스를 쉽게 조작할 수 있습니다. 이를 통해 데이터베이스의 검색과 조작이 용이해지며, 데이터베이스의 활용성을 높일 수 있습니다.
유연한 저장소(Storage) 엔진
MongoDB는 유연한 저장소(Storage) 엔진을 사용합니다. 이를 통해 데이터베이스의 처리 속도와 확장성을 높일 수 있습니다.
오픈소스
MongoDB는 오픈소스 데이터베이스 시스템으로, 누구나 무료로 사용할 수 있으며, 커뮤니티에서 지속적으로 업데이트 및 개선 작업이 이루어지고 있습니다.
배포 방식
Replica-set, sharded cluster 2가지 방식이 존재합니다.
Replica-set
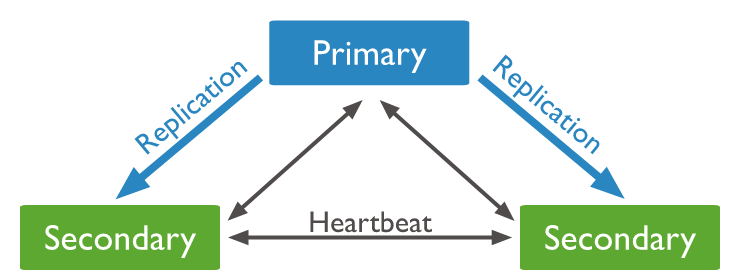
MongoDB에서 Replica Set은 데이터베이스의 가용성과 안정성을 높이기 위한 분산 시스템입니다. Replica Set은 데이터베이스의 복제 기능을 이용하여 여러 대의 서버에 데이터를 저장하고, 서버 중 한 대에 문제가 생길 경우에도 다른 서버에서 데이터를 제공할 수 있도록 구성됩니다.
Replica-set 의 구성 요소
- Primary Node(주 서버)
Replica Set 중 한 대의 서버로, 쓰기 작업을 처리하는 역할(configuration 설정이 필요)을 합니다.
데이터베이스의 변경 작업은 Primary Node에서만 처리됩니다. - Secondary Node(보조 서버)
Replica Set에 속한 서버 중 Primary Node 이외의 모든 서버를 말합니다.
Secondary Node는 Primary Node에서 데이터를 복제하여 데이터베이스의 읽기 작업을 처리합니다.
Secondary Node 중 한 대에 문제가 생겨도 다른 Secondary Node에서 데이터를 읽어올 수 있습니다. - Arbiter Node(판정 서버)
Replica Set에 속한 서버 중 한 대로, 데이터를 저장하지 않고 단지 Primary Node의 선출을 판정하는 역할을 합니다.
Arbiter Node는 Replica Set의 안정성을 높이기 위해 사용됩니다.
Replica Set은 Primary Node와 Secondary Node 간의 데이터 복제 기능을 이용하여 데이터베이스를 복제하고, 동기화합니다. Primary Node에서 발생한 쓰기 작업은 Secondary Node로 전달되어 복제되며, Secondary Node에서 발생한 데이터 변경 작업은 Primary Node로 전달되지 않습니다.
Replica-set 의 장점과 단점
장점
- 데이터베이스의 가용성을 높일 수 있습니다.
- 데이터베이스의 안정성을 높일 수 있습니다.
- 데이터 복제 기능을 이용하여 데이터를 백업할 수 있습니다.
- 데이터베이스의 확장성을 높일 수 있습니다.
단점
- write 분산 처리가 불가능합니다.
Shared Cluster
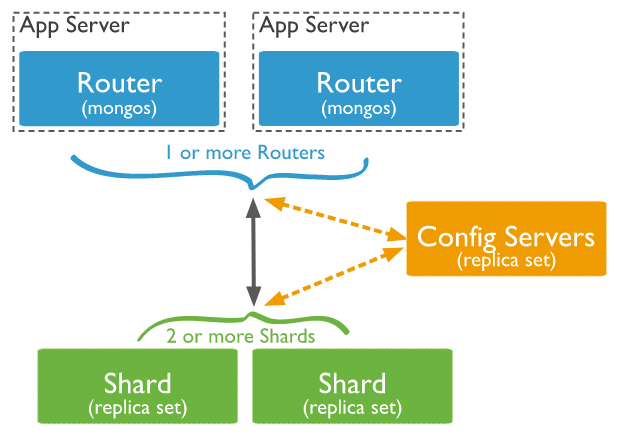
MongoDB의 Sharded Cluster는 대규모 데이터 처리를 위한 분산 데이터베이스 시스템입니다. Sharded Cluster는 데이터베이스의 샤딩(Sharding)과 Replica Set 기능을 사용하여 여러 대의 서버에 데이터를 분산하여 저장하고, 필요에 따라서 데이터베이스를 확장할 수 있습니다.
Sharded Cluster의 구성요소
- Config Server
Sharded Cluster의 구성 정보를 저장하는 서버입니다.
Config Server는 Replica Set으로 구성되어 있습니다. - Shard Server
Sharded Cluster에 속한 서버 중 데이터를 저장하는 서버입니다.
각각의 Shard Server는 Replica Set으로 구성되어 있습니다. - Query Router
Sharded Cluster와 클라이언트 간의 데이터 통신을 담당하는 서버입니다.
Query Router는 클라이언트의 쿼리(Query)를 분석하여 적절한 Shard Server에 전달합니다.
Sharded Cluster는 데이터베이스의 샤딩(Sharding)을 사용하여 데이터를 분산 저장합니다. 샤딩을 사용하면 데이터베이스의 처리 속도를 높일 수 있습니다. 각각의 Shard Server는 Replica Set으로 구성되어 있으며, Replica Set 간의 데이터 복제는 MongoDB의 쓰기 작업과 동기화됩니다. 이를 통해 데이터베이스의 안정성과 가용성을 높일 수 있습니다.
Sharded Cluster는 다음과 같은 장점을 가지고 있습니다.
Shared Cluster 의 장점과 단점
장점
- 데이터베이스의 확장성을 높입니다. Shard Server를 추가하면 데이터베이스의 처리 속도를 높일 수 있습니다.
- 데이터베이스의 가용성을 높입니다. 각각의 Shard Server는 여러 개의 서버로 구성되어 있기 때문에, 한 대의 서버에 문제가 생겨도 다른 서버에서 데이터를 제공할 수 있습니다.
- 데이터베이스의 안정성을 높입니다. Replica Set을 사용하여 데이터베이스의 복제 기능을 이용하면 데이터베이스의 안정성이 높아집니다.
단점
- 성능 하락
replica-set 배포 방식에 비해 성능이 떨어집니다. 데이터가 분산되어 있어, 특히 Range Query 에서 큰 성능 하락을 경험할 수 있습니다.
- 장애 복구 비용 증가
데이터가 분산되어 있는 만큼 장애에 복구하는데 들어가는 리소스가 상승합니다.
- 운영 비용 증가
Sharded Cluster는 여러 대의 Shard Server와 Config Server, Query Router 등으로 구성되어 있으므로, 단일 서버에 비해 더욱 복잡한 구성을 가지고 있습니다. 따라서, Sharded Cluster의 관리는 단일 서버에 비해 더욱 복잡합니다.
배포 전략
배포 전략을 고려할때 데이터의 증가나 요구 사항들을 면밀하게 검토해야 합니다. 하지만 가장 최우선적으로 Replica-set 을 사용하여 운영하는 방식을 고려해야 합니다.
데이터의 증가가 크고, Write 가 압도적으로 많아서 꼭!! 꼭!! Sharded Cluster 방식을 고려해야 할때, 도입하는게 좋습니다.
