12세 이하인 여자 환자 목록 출력하기
https://school.programmers.co.kr/learn/courses/30/lessons/132201?language=oracle

SELECT PT_NAME, PT_NO, GEND_CD, AGE, NVL(TLNO, 'NONE')
FROM PATIENT
WHERE AGE < 13 AND GEND_CD = 'W'
ORDER BY AGE DESC, PT_NAME ASC;- NVL함수: null을 대상으로 어떤 값을 출력할지 처리하는 함수
- 나이를 기준으로 내림차순 정렬하고, 나이가 같으면 환자이름을 기준으로 오름차순 정렬하라
-> ORDER BY 문에서 여러 개의 열을 지정하면, 첫 번째 열로 정렬한 후, 첫 번째 열의 값이 같은 행들에 대해 두 번째 열로 정렬한다. 이를 '다중 정렬'이라고 한다.
따라서 ORDER BY AGE DESC, PT_NAME ASC; 구문은 "나이(AGE)를 기준으로 내림차순 정렬하고, 나이가 같은 경우에는 환자 이름(PT_NAME)을 기준으로 오름차순 정렬하라"는 의미다.
즉, 이 구문이 실행되면 먼저 나이가 가장 많은 환자부터 가장 적은 환자 순으로 데이터가 정렬되며, 만약 나이가 같은 환자가 있다면 그 환자들 사이에서는 이름 순으로 정렬된다.
NVL 함수 관련 글) https://cheershennah.tistory.com/211
3월에 태어난 여성 회원 목록 출력하기
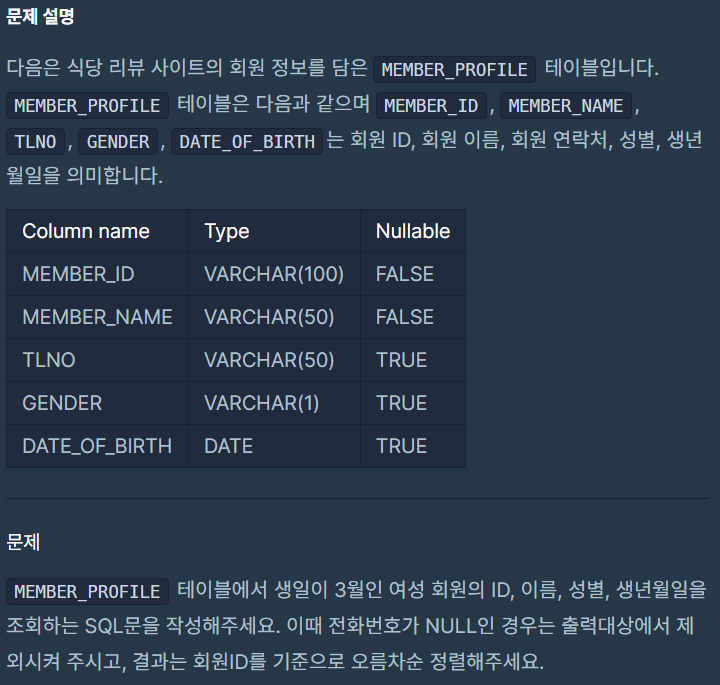
SELECT MEMBER_ID, MEMBER_NAME, GENDER, TO_CHAR(DATE_OF_BIRTH, 'YYYY-MM-DD') AS DATE_OF_BIRTH
FROM MEMBER_PROFILE
WHERE TO_CHAR(DATE_OF_BIRTH, 'MM') = '03'
AND TLNO IS NOT NULL
AND GENDER ='W'
ORDER BY MEMBER_ID ASC;-
생일이 3월인 함수 출력: TO_CHAR(DATE_OF_BIRTH, 'YYYY-MM-DD') AS DATE_OF_BIRTH -> TO_CHAR(DATE_OF_BIRTH, 'YYYY-MM-DD')는 SQL에서 지정된 형식의 문자열로 변환하는 함수다. DATE_OF_BIRTH 열의 값을 'YYYY-MM-DD' 형식의 문자열로 변환하였고, DATE_OF_BIRTH 라는 별칭으로 출력하였다.
-
전화번호가 NULL이면 출력하지 않는다: WHERE TLNO IS NOT NULL
-> SELECT ~ WHERE IS NOT 조건1 이면, 조건1인 값은 출력하지 않는다.
Show the name and the population for 'Sweden', 'Norway' and 'Denmark'

- 제출코드 (오답)
SELECT name, population FROM world
WHERE name = 'Sweden' AND 'Norway' AND 'Denmark';- 정답
SELECT name, population FROM world
WHERE name IN ('Brazil', 'Russia', 'India', 'China');
-- 또는 WHERE name = 'Sweden' OR name = 'Norway' OR name = 'Denmark';- 배운점
a조건,b조건,c조건에 모두 해당하는 값을 가져올 때는 IN을 사용하자.
IN 대신 OR로도 구할 수 있지만, IN을 사용하는 것이 효율적이다.
Just the right size
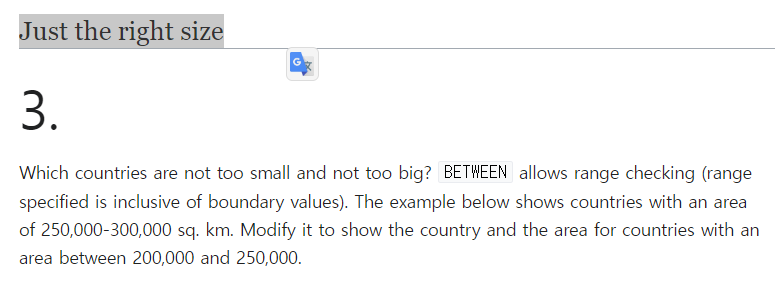
- 제출코드
SELECT name, area FROM world WHERE area BETWEEN 200000 AND 250000; - 배운점
BETWEEN을 사용할 때는 괄호가 필수는 아니다.
countries that end in A or L
- 제출 코드
SELECT name FROM world
WHERE name LIKE '%a' OR name LIKE '%l'- 배운점
LIKE는 보통 쿼리문 WHERE절에 주로 사용되며 부분적으로 일치하는 칼럼을 찾을때 사용된다.
: 글자숫자를 정해줌(EX 컬럼명 LIKE '홍동')
% : 글자숫자를 정해주지않음(EX 컬럼명 LIKE '홍%')
--A로 시작하는 문자를 찾기--
SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE 'A%'
--A로 끝나는 문자 찾기--
SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE '%A'
--A를 포함하는 문자 찾기--
SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE '%A%'
--A로 시작하는 두글자 문자 찾기--
SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE 'A_'
--첫번째 문자가 'A''가 아닌 모든 문자열 찾기--
SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE'[^A]'
--첫번째 문자가 'A'또는'B'또는'C'인 문자열 찾기--
SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE '[ABC]'
SELECT 컬럼명 FROM 테이블 WHERE 컬럼명 LIKE '[A-C]'Per capita GDP
- 제출코드
SELECT name, GDP/population AS "per capita GDP" FROM world
WHERE population > 200000000;- 배운점
-
Oracle에서는 대소문자를 구분한다.
ex) Table 과 table은 서로 다른 테이블로 인식한다. -
Oracle에서 AS 사용시 쌍따옴표("")를 사용하는 경우는 다음과 같다.
1) 대소문자를 구분하여 출력할 때
2) 공백문자를 출력할 때
3) 특수문자를 출력할 때
United

- 제출코드
SELECT name
FROM world
WHERE name LIKE '%United%';- 배운점
LIKE를 쓸 때는 작은따옴표로 문자열을 묶어야 한다.
흉부외과 또는 일반외과 의사 목록 출력하기
- 제출코드
SELECT DR_NAME, DR_ID, MCDP_CD, TO_CHAR(HIRE_YMD, 'YYYY-MM-DD') AS HIRE_YMD
FROM DOCTOR
WHERE MCDP_CD IN ('CS', 'GS')
ORDER BY HIRE_YMD DESC, DR_NAME ASC;- 배운점
1) TO_CHAR() 사용 후 AS를 붙여 출력할 문자열을 지정해야한다.
2) IN 을 사용할 때는 괄호 안 문자열들에 작은 따옴표를 붙여야된다.
강원도에 위치한 생산공장 목록 출력하기
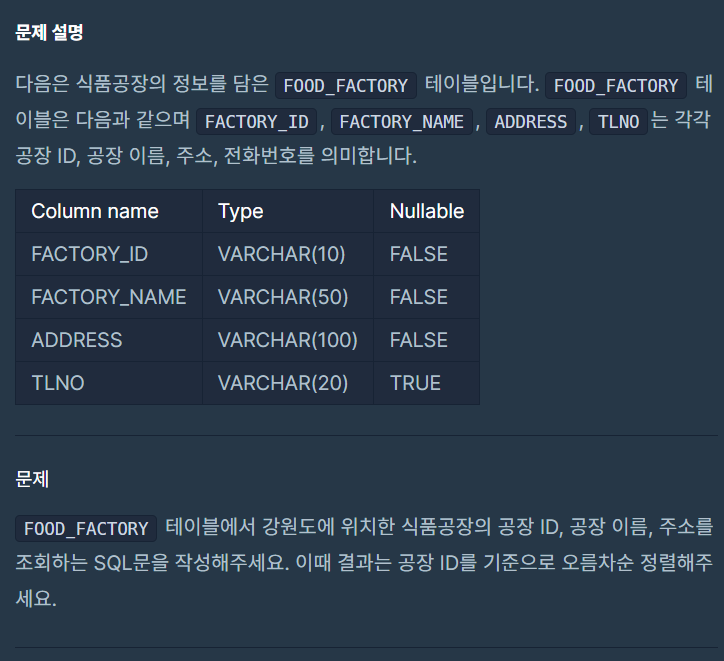
- 제출코드
SELECT FACTORY_ID, FACTORY_NAME, ADDRESS
FROM FOOD_FACTORY
WHERE ADDRESS LIKE ('강원도%')
ORDER BY FACTORY_ID; - 배운점
강원도에 위치한 식품공장을 찾으려면 LIKE ('강원도%') <- 이렇게 작성하면 된다.
상위 n개 레코드
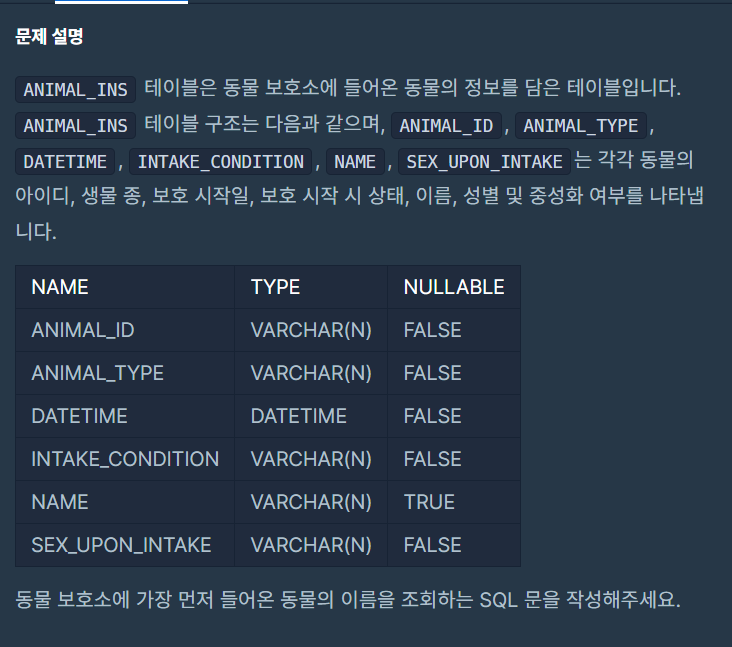
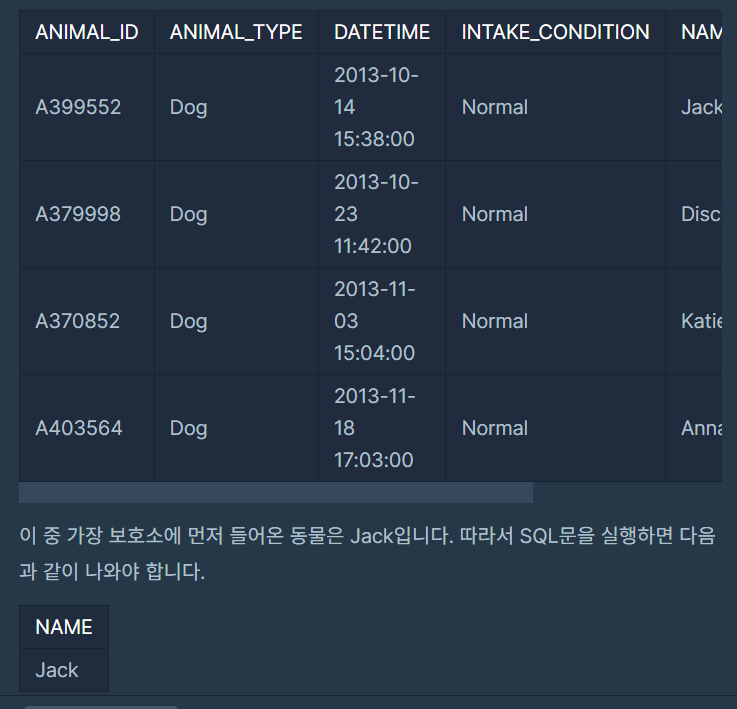
- 제출코드
SELECT NAME
FROM (
SELECT *
FROM ANIMAL_INS
ORDER BY DATETIME ASC
)
WHERE ROWNUM = 1;- 배운점
- 상위 n개의 데이터를 뽑으려면 서브쿼리와 ROWNUM이 필요하다.- 서브쿼리로 데이터를 정렬한뒤, ROWNUM으로 n개를 지정하면 된다.
평균 일일 대여 요금 구하기
https://school.programmers.co.kr/learn/courses/30/lessons/151136
- 정답
SELECT ROUND(AVG(DAILY_FEE)) AS AVERAGE_FEE
FROM CAR_RENTAL_COMPANY_CAR
WHERE CAR_TYPE = 'SUV';- 배운점
1) 소수점 첫번째 자리에서 반올림 하려면 ROUND()를 사용하면 된다.
만약 두번째 자리에서 하려면 SELECT ROUND(3.14159, 2); 로 작성하면 된다.
조건에 맞는 회원수 구하기
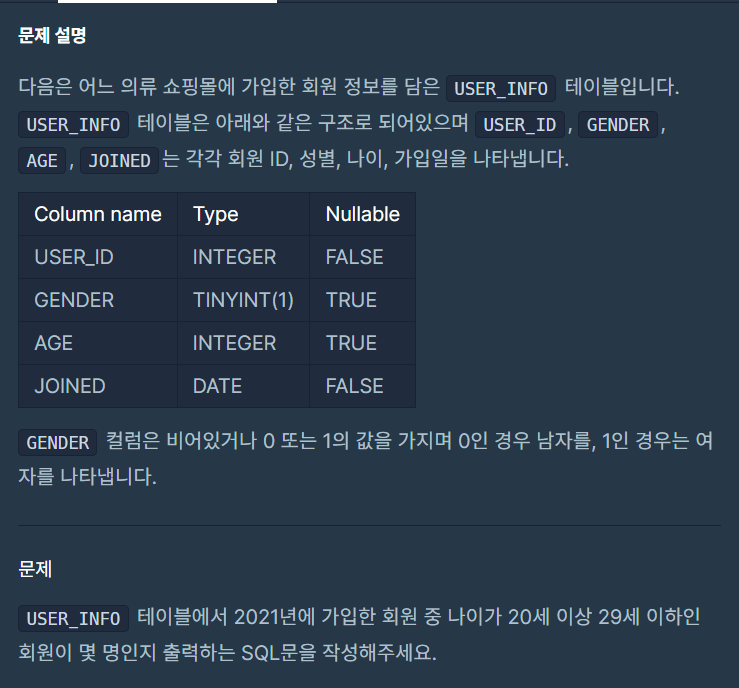
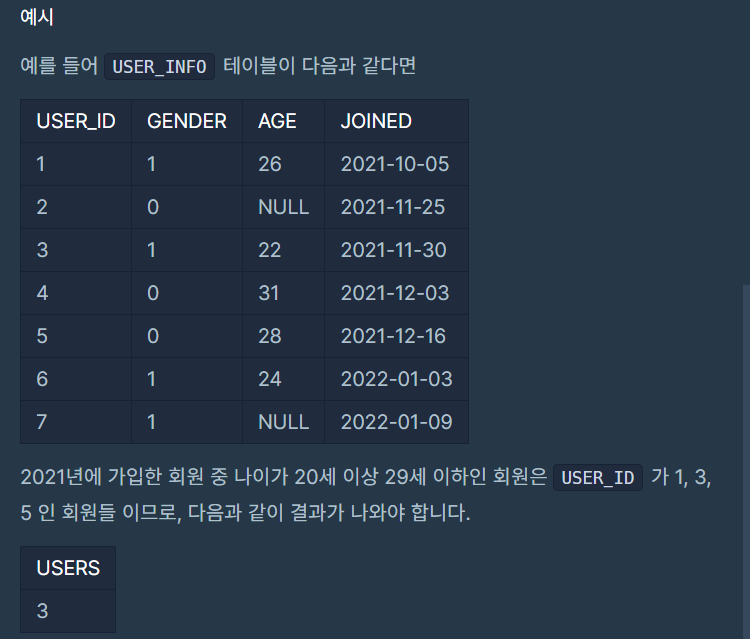
- 정답
SELECT COUNT(*) AS "USERS"
FROM USER_INFO
WHERE EXTRACT(YEAR FROM JOINED) = 2021
AND AGE BETWEEN 20 AND 29;- 정답2
SELECT COUNT(*) AS "USERS"
FROM USER_INFO
WHERE TO_CHAR(JOINED, 'YYYY') LIKE '2021%';
AND AGE BETWEEN 20 AND 29;- 배운점
1) EXTRACT 함수는 날짜나 시간 값에서 특정 요소를 추출할 때 사용한다.
2) LIKE 함수를 사용하려면 무조건 대상이 문자열이어야 한다.
그래서 자료형이 문자열이 아니면 LIKE는 TO_CHAR과 함께 사용해야 한다.
가격이 제일 비싼 식품의 정보 출력하기
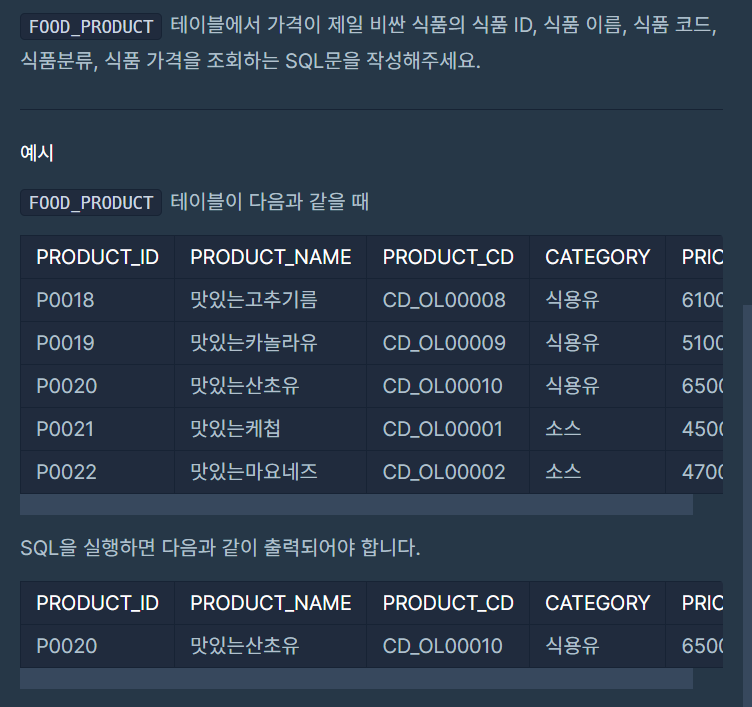
- 오답
SELECT *
FROM FOOD_PRODUCT
WHERE MAX(PRICE); MAX()나 MIN()과 같은 집계 함수는 단독으로 사용할 수 없다.
이러한 집계 함수들은 주로 서브쿼리, GROUP BY, ORDER BY와 함께 사용한다.
집계 함수들은 데이터 집합을 그룹화하고, 각 그룹에 대한 계산을 수행하기 때문에, 단독으로 사용할 경우 어떤 그룹을 기준으로 계산할지 명확하지 않기 때문에 오류가 발생한다.
- 정답
// 서브쿼리를 사용한 풀이
SELECT *
FROM(SELECT *
FROM FOOD_PRODUCT
ORDER BY PRICE DESC)
WHERE ROWNUM = 1;
// FETCH를 사용한 풀이
SELECT *
FROM FOOD_PRODUCT
ORDER BY PRICE DESC
FETCH FIRST ROW ONLY;고양이와 개는 몇 마리 있을까
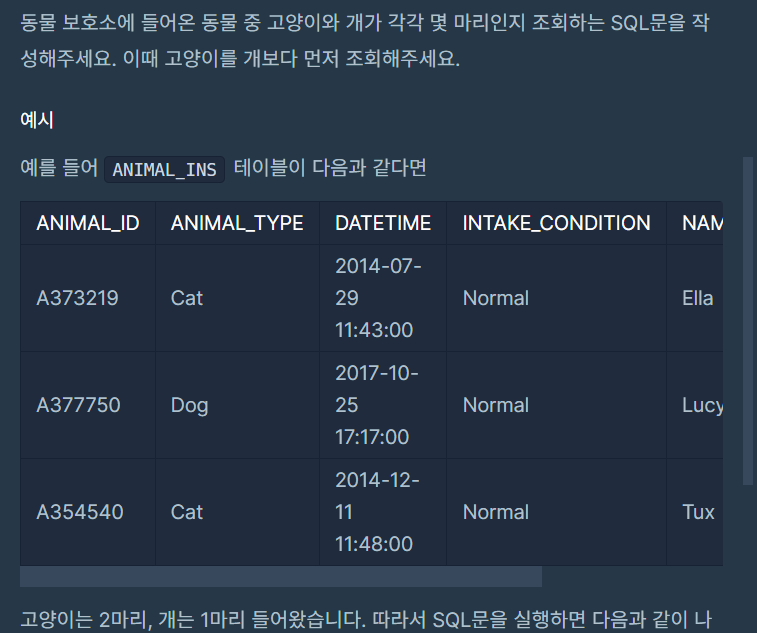
- 정답
SELECT ANIMAL_TYPE, COUNT(*) AS count
FROM ANIMAL_INS
GROUP BY ANIMAL_TYPE
ORDER BY CASE WHEN ANIMAL_TYPE = 'cat' THEN 0 ELSE 1 END;- 배운점
핵심은 고양이를 개보다 먼저 조회한다는 것이다.
ORDER BY CASE WHEN 을 사용하면 된다.
ORDER BY CASE WHEN ANIMAL_TYPE = 'cat' THEN 0 ELSE 1 END;
동명 동물 수 찾기


- 오답
SELECT *
FROM ANIMAL_INS
WHERE COUNT(*) > 1
GROUP BY NAME;
SELECT NAME, COUNT(*) AS COUNT
FROM ANIMAL_INS
GROUP BY NAME
HAVING COUNT(*) >= 2
ORDER BY COUNT DESC;- 정답
SELECT NAME, COUNT(NAME) AS COUNT
FROM ANIMAL_INS
GROUP BY NAME HAVING COUNT(NAME) > 1
ORDER BY NAME;- 배운점
- COUNT(): 이 함수는 선택한 결과 집합의 전체 행 수를 세는 데 사용된다. 는 모든 열을 의미하므로, COUNT()는 결과 집합에 포함된 모든 행을 카운트한다. 따라서 COUNT()는 결과 집합의 행 수를 반환한다.
COUNT(NAME): 이 함수는 선택한 열의 값이 NULL이 아닌 행의 수를 세는 데 사용된다. 특정 열을 지정하면 해당 열의 값이 NULL이 아닌 행의 수를 세게 된다. 즉, COUNT(NAME)은 'NAME' 열이 NULL이 아닌 행의 수를 반환한다.
따라서 이 두 함수는 결과가 다를 수 있다. COUNT(*)는 결과 집합에 있는 모든 행을 세고, COUNT(NAME)은 'NAME' 열이 NULL이 아닌 행의 수를 세기 때문에 서로 다른 결과를 반환할 수 있다.
- COUNT(*)은 집계 함수이며 WHERE 절에서 집계 함수를 사용할 수 없다. 따라서 COUNT를 WHERE과 함께 쓰면 안되고, HAVINGR과 사용한다.
가격대 별 상품 개수 구하기
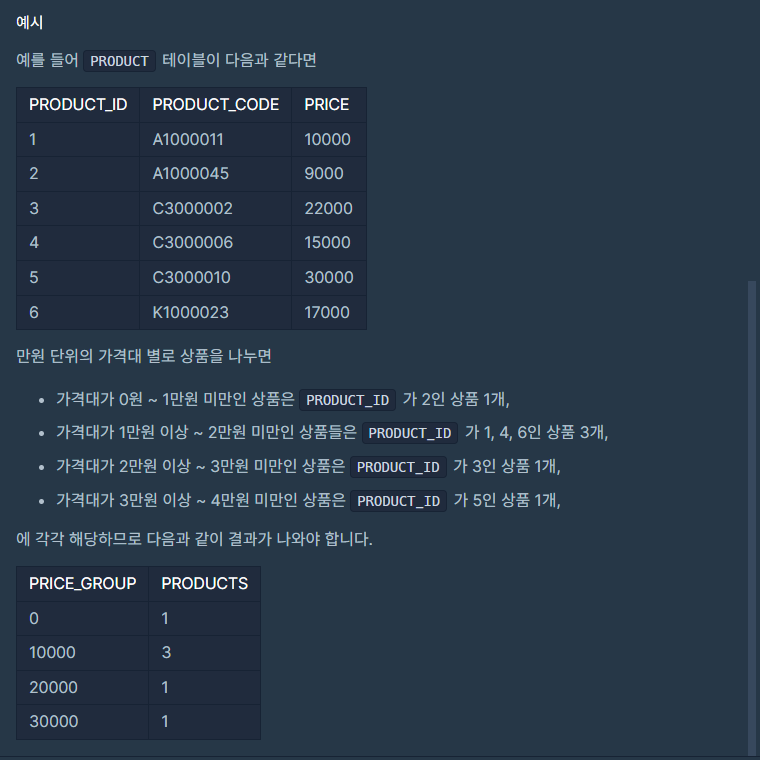
SELECT FLOOR(PRICE/10000)*10000 AS PRICE_GROUP, COUNT(*) AS PRODUCTS
FROM PRODUCT
GROUP BY FLOOR(PRICE/10000)*10000
ORDER BY PRICE_GROUP- 배운점
PRICE_GROUP을 10000 단위로 지정하려면 FLOOR함수와 (PRICE/10000)*10000을 활용하면 됨
진료과별 총 예약 횟수 출력하기


SELECT MCDP_CD AS "진료과코드", COUNT(*) AS "5월예약건수"
FROM
(SELECT * FROM APPOINTMENT WHERE EXTRACT(month from APNT_YMD) = 5)
GROUP BY MCDP_CD
ORDER BY "5월예약건수" ASC, "진료과코드" ASC;- 배운점
- AS 뒤에 알파벳이면 따옴표 생략 가능하지만, 별칭이나 열의 이름에 공백이나 특수 문자가 포함되어 있거나 대소문자가 혼합되어 있을 때는 따옴표를 사용해야 한다.
- ORDER BY에 두 개의 조건을 넣고 싶으면 그냥 뒤에 바로 써라.
카테고리 별 도서 판매량 집계하기
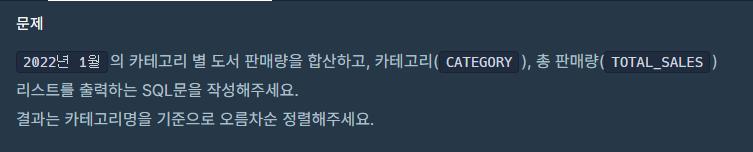
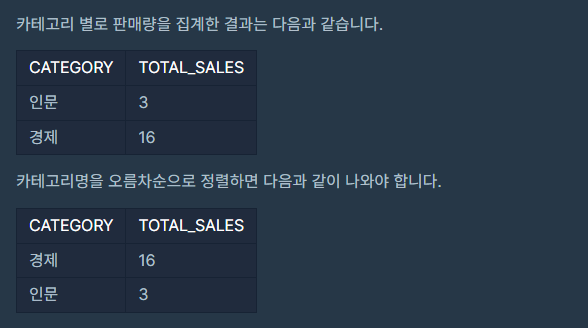
- 정답
SELECT b.CATEGORY, SUM(bs.SALES) AS TOTAL_SALES
FROM BOOK b
JOIN BOOK_SALES bs
ON b.BOOK_ID = bs.BOOK_ID
WHERE EXTRACT(YEAR FROM bs.SALES_DATE) = 2022 AND EXTRACT(MONTH FROM bs.SALES_DATE) = 1
GROUP BY b.CATEGORY
ORDER BY b.CATEGORY;- 배운점
- EXTRACT의 괄호가 문장 끝까지 이어지지 않고, = 앞에서 끊겨야 함
- 날짜를 비교할 때, 예를 들어 2022년 1월 일 때, LIKE('2022-01%')를 사용할 수 없다.
이는 문자열을 비교하는 것이기 때문에 날짜 그대로를 비교하려면 EXTRACT()를 쓰는것이 좋다.
자동차 종류 별 특정 옵션이 포함된 자동차 수 구하기
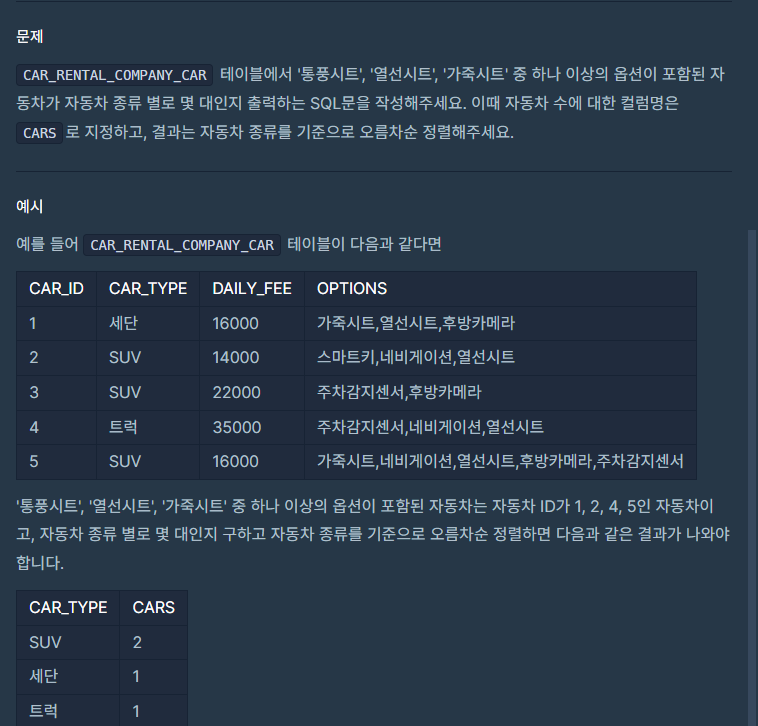
- 제출코드
SELECT CAR_TYPE, COUNT(*) AS CARS
FROM CAR_RENTAL_COMPANY_CAR
WHERE OPTIONS IN ('통풍시트', '열선시트', '가죽시트')
GROUP BY CAR_TYPE
ORDER BY CAR_TYPE;- 정답
SELECT CAR_TYPE, COUNT(*) AS CARS
FROM CAR_RENTAL_COMPANY_CAR
WHERE OPTIONS LIKE '%통풍시트%' OR OPTIONS LIKE '%열선시트%' OR OPTIONS LIKE '%가죽시트%'
GROUP BY CAR_TYPE
ORDER BY CAR_TYPE;- 배운점 (중요)
WHERE OPTIONS IN ('통풍시트', '열선시트', '가죽시트')
는 안되는 이유가 뭘까?
WHERE OPTIONS IN ('통풍시트', '열선시트', '가죽시트') 구문이 작동하지 않는 이유는 IN 연산자가 정확한 일치를 검색하기 때문이다. 즉, OPTIONS 필드의 값이 '통풍시트', '열선시트', '가죽시트' 중 하나와 정확히 일치하는 행만 반환한다.
그러나, OPTIONS 필드가 여러 옵션을 포함하는 문자열이라면, 이 구문은 원하는 결과를 반환하지 않는다. 예를 들어, '통풍시트,열선시트'와 같이 여러 옵션이 하나의 문자열로 저장된 경우, IN 연산자는 이 값을 '통풍시트' 또는 '열선시트'와 같은 개별 옵션과 정확히 일치시키지 못한다.
이런 경우, LIKE 연산자 또는 REGEXP_LIKE 함수와 같은 패턴 매칭을 사용해야 한다.
LIKE나 REGEXP_LIKE는 부분 문자열이나 패턴을 사용하여 문자열 내에서 일치하는 값을 찾을 수 있다.
따라서, OPTIONS 필드가 여러 옵션을 포함하는 문자열인 경우, 이들 함수를 사용하여 각 옵션이 문자열에 포함되어 있는지 검사해야 한다.
그럼 이제 in()을 사용하기 적합한 경우를 살펴보자.
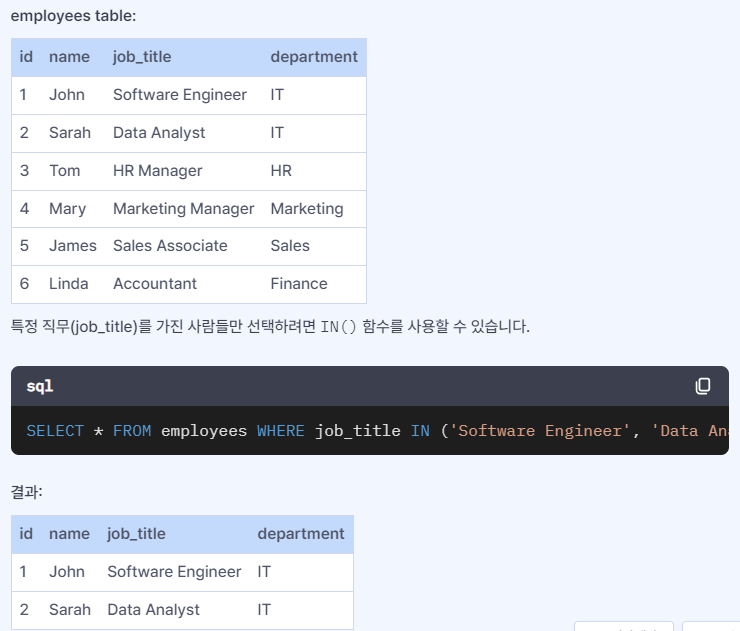
상품 별 오프라인 매출 구하기
https://school.programmers.co.kr/learn/courses/30/lessons/131533

- 제출코드(오답)
SELECT p.PRODUCT_CODE, p.PRICE * o.SALES_AMOUNT AS SALES
FROM PRODUCT p
JOIN OFFLINE_SALE o
ON p.PRODUCT_ID = o.PRODUCT_ID
GROUP BY p.PRODUCT_CODE
ORDER BY SALES DESC, PRODUCT_CODE ASC;- 정답
SELECT p.PRODUCT_CODE, SUM(p.PRICE * o.SALES_AMOUNT) AS SALES
FROM PRODUCT p
JOIN OFFLINE_SALE o
ON p.PRODUCT_ID = o.PRODUCT_ID
GROUP BY p.PRODUCT_CODE
ORDER BY SALES DESC, PRODUCT_CODE ASC;- 배운점
-
GROUP BY 절은 데이터를 특정 기준에 따라 그룹화합니다. 예를 들어, 직원들의 정보가 담긴 테이블에서 부서별로 데이터를 그룹화하려면 'GROUP BY department'라고 쿼리를 작성하면 됩니다.
-
SELECT 절에서는 GROUP BY 절에 사용된 컬럼 뿐만 아니라, 집계 함수를 사용한 컬럼을 포함할 수 있습니다. 집계 함수에는 COUNT(), SUM(), AVG(), MAX(), MIN() 등이 있습니다. 이 함수들은 그룹화된 데이터에 대한 계산을 수행합니다.
-
SELECT 절에서 GROUP BY 절에 사용되지 않은 컬럼을 사용하려면, 해당 컬럼은 집계 함수 내에 있어야 합니다. 이렇게 하지 않으면, 그룹화된 데이터에서 해당 컬럼의 값을 어떻게 선택해야 할지 모호해져서 오류가 발생합니다.
