미로찾기 알고리즘
미로찾기 알고리즘의 풀이는 DFS, BFS 둘 중 하나를 사용하면 된다.
어떤 경우에 사용하면 좋을지 알아보자.
DFS
DFS 는 모든 노드를 방문하는 경우에 사용한다.
주로 스택과 재귀 함수를 활용한다.
재귀 함수를 사용하는 경우에는 종료 조건을 명확하게 명시해야 하며,
그렇지 않으면 무한 반복에 빠진다.
- DFS와 함께 사용하는 알고리즘: 백트래킹
- 백트래킹이란 해를 찾아가는 도중, 지금 가는 경로가 해가 아니라면 더 이상 경로를 가지 않고 되돌아가는 것이다. 백트래킹의 목적은 불필요한 탐색을 줄이고, 최대한 올바른 쪽으로 가고자 하는 것이다. 즉, 모든 가능한 경우의 수 중에서 특정한 조건을 만족하는 경우만 살펴보는 것이다.
풀이 순서
-
초기화: 미로의 시작 지점, 방문 여부를 체크할 배열, 미로의 구조(벽이 있는지, 열린 공간인지를 표시하는 배열)를 초기화한다.
-
DFS 함수 정의: 현재 위치에서 할 수 있는 모든 이동(상, 하, 좌, 우 등)을 시도하며, 각 위치에서 재귀적으로 DFS 함수를 호출한다.
-
경계 및 방문 체크: 이동할 위치가 미로의 경계를 벗어나지 않고, 아직 방문하지 않은 곳인지 확인한다.
-
목적지 확인: 현재 위치가 목적지인지 확인한다. 목적지에 도달하면 경로를 찾은 것으로 간주하고 탐색을 종료한다.
-
방문 기록 및 백트래킹: 현재 위치를 방문했다고 표시하고, 재귀적으로 다음 위치를 탐색한다. 탐색이 끝나면, 방문 표시를 되돌려 놓는다(백트래킹).
스켈레톤 코드
public class Main {
private static int[][] maze = {
{0, 1, 0, 0, 0},
{0, 1, 0, 1, 0},
{0, 0, 0, 0, 0},
{0, 1, 1, 1, 0},
{0, 0, 0, 0, 0}
};
private static boolean[][] visited;
private static int n; // 미로의 행의 수
private static int m; // 미로의 열의 수
// 이동할 네 방향 정의 (상, 하, 좌, 우)
private static int[] dx = {-1, 1, 0, 0};
private static int[] dy = {0, 0, -1, 1};
public static void main(String[] args) {
n = maze.length;
m = maze[0].length;
visited = new boolean[n][m];
// 미로 탐색 시작 (0, 0)에서 시작
boolean result = dfs(0, 0);
System.out.println("경로 찾기 성공: " + result);
}
public static boolean dfs(int x, int y) {
// 경계 조건 체크
if(x < 0 || x >= n || y < 0 || y >= m) return false;
// 벽이거나 이미 방문한 경우
if(maze[x][y] == 1 || visited[x][y]) return false;
// 목적지 도달 (예제에서는 (n-1, m-1)을 목적지로 설정)
if(x == n-1 && y == m-1) return true;
// 현재 위치 방문 처리
visited[x][y] = true;
System.out.println("방문한 좌표: (" + x + ", " + y + ")"); // 방문한 좌표 출력
// 상, 하, 좌, 우 탐색
for(int i = 0; i < 4; i++) {
if(dfs(x + dx[i], y + dy[i])) {
return true; // 경로 찾음
}
}
// 경로를 찾지 못한 경우, 현재 위치의 방문 여부를 되돌림 (백트래킹)
visited[x][y] = false;
return false;
}
}
방문한 좌표: (0, 0)
방문한 좌표: (1, 0)
방문한 좌표: (2, 0)
방문한 좌표: (3, 0)
방문한 좌표: (4, 0)
방문한 좌표: (4, 1)
방문한 좌표: (4, 2)
방문한 좌표: (4, 3)
경로 찾기 성공: true
- 시간복잡도: 전체 노드의 수가 (n X m)일 때 (여기서 (n)은 행의 수, (m)은 열의 수), 모든 노드를 방문하는 데 걸리는 시간은 (O(n X m))이다.
만약, (n)과 (m)이 비슷한 크기라면, 이를 대략적으로 (O(n^2))으로 간주할 수도 있다.
인상적인 점은, 위 코드가 대표적인 미로문제 dfs 풀이임에도 불구하고, dfs라는 특성 때문에 높은 시간복잡도가 나온다는 점이다.
주의점
- 연산 횟수의 기하급수적인 증가
DFS 는 모든 가능한 경우의 수를 탐색하기 때문에 미로의 크기가 커질 경우, 연산이 기하급수적으로 늘어나기 때문에 실행 시간도 같이 증가하는 문제점이 있다.
따라서 탐색 횟수가 많은데 최단경로를 찾아야 하는 문제라면,
BFS로 푸는것이 이득이다.
BFS
실행 순서
실행 순서는 아래와 같다.
- 초기화:
- 미로의 각 칸을 노드로 간주하고, 노드 간 연결(이동 가능한 경로)을 간선으로 간주한다.
- 각 노드(칸)의 방문 여부를 나타내는 visited 배열을 초기화합니다. 모든 노드는 초기에 방문하지 않은 상태(false)다.
- 탐색을 시작할 노드(미로의 시작 위치)를 큐에 추가하고, 해당 노드를 방문한 것으로 표시한다(visited 배열을 true로 업데이트).
- BFS 탐색:
큐가 빌 때까지 다음 과정을 반복한다.
- 노드 꺼내기: 큐에서 노드(현재 위치)를 하나 꺼내 (curr) 현재 노드로 설정한다.
- 목표 확인: 만약 현재 노드가 목표 위치(미로의 출구)라면, 탐색을 종료한다.
- 인접 노드 탐색: 현재 노드에 인접한 모든 노드(상하좌우로 이동 가능한 칸)를 순회한다. 이 때, 각 인접 노드가 미로 내부에 위치하며 벽이 아닌지(이동 가능한 칸인지), 그리고 아직 방문하지 않았는지를 확인한다.
- 노드 방문: 인접 노드 중 조건에 맞는 노드(이동 가능하고, 아직 방문하지 않은 노드)가 있으면, 그 노드를 큐에 추가하고 방문한 것으로 표시한다.
- 경로 재구성(선택적):
목표에 도달한 경우, 방문한 노드들을 역추적하여 시작점부터 목표점까지의 경로를 재구성할 수 있다. 이를 위해 각 노드에 대해 어느 노드에서 왔는지를 나타내는 정보를 추가로 저장할 수 있다.
한계점
-
DFS에 비해 큰 저장공간 필요
DFS 와 달리 다음 탐색할 노드를 동시에 여러 개 저장하기 때문에 갈림길이 많을 수록 유망하지 않은 노드까지 저장해야 한다. -
규모가 클 경우 비효율적
DFS 는 규모가 크더라도 최선의 경우에는 어떤 경로 하나에서만 도착하기만 하면 종료한다. 하지만, BFS 는 동시에 여러 경로를 탐색해야 하기 때문에 프로그램 실행 시간이 오래 걸린다는 단점이 있다.
코드
package baekjoon;
import java.io.*;
import java.util.*;
import java.util.*;
public class Main {
private static int[][] maze = {
{0, 1, 0, 0, 0},
{0, 1, 0, 1, 0},
{0, 0, 0, 0, 0},
{0, 1, 1, 1, 0},
{0, 0, 0, 0, 0}
};
private static boolean[][] visited;
private static int n; // 미로의 행의 수
private static int m; // 미로의 열의 수
// 이동할 네 방향 정의 (상, 하, 좌, 우)
private static int[] dx = {-1, 1, 0, 0};
private static int[] dy = {0, 0, -1, 1};
public static void main(String[] args) {
n = maze.length;
m = maze[0].length;
visited = new boolean[n][m];
// 미로 탐색 시작 (0, 0)에서 시작
boolean result = bfs(0, 0);
System.out.println("경로 찾기 성공: " + result);
}
public static boolean bfs(int startX, int startY) {
Queue<int[]> queue = new LinkedList<>();
queue.add(new int[]{startX, startY});
visited[startX][startY] = true;
System.out.println("방문한 좌표: (" + startX + ", " + startY + ")"); // 방문한 좌표 출력
while (!queue.isEmpty()) {
int[] current = queue.poll();
int x = current[0];
int y = current[1];
// 목적지 도달 (예제에서는 (n-1, m-1)을 목적지로 설정)
if (x == n - 1 && y == m - 1) {
return true;
}
// 상, 하, 좌, 우 탐색
for (int i = 0; i < 4; i++) {
int nextX = x + dx[i];
int nextY = y + dy[i];
// 경계 조건 체크 및 방문 여부 확인
if (nextX >= 0 && nextX < n && nextY >= 0 && nextY < m &&
maze[nextX][nextY] == 0 && !visited[nextX][nextY]) {
queue.add(new int[]{nextX, nextY});
visited[nextX][nextY] = true;
System.out.println("방문한 좌표: (" + nextX + ", " + nextY + ")"); // 방문한 좌표 출력
}
}
}
return false; // 경로를 찾지 못한 경우
}
}
출력)
방문한 좌표: (0, 0)
방문한 좌표: (1, 0)
방문한 좌표: (2, 0)
방문한 좌표: (3, 0)
방문한 좌표: (2, 1)
방문한 좌표: (4, 0)
방문한 좌표: (2, 2)
방문한 좌표: (4, 1)
방문한 좌표: (1, 2)
방문한 좌표: (2, 3)
방문한 좌표: (4, 2)
방문한 좌표: (0, 2)
방문한 좌표: (2, 4)
방문한 좌표: (4, 3)
방문한 좌표: (0, 3)
방문한 좌표: (1, 4)
방문한 좌표: (3, 4)
방문한 좌표: (4, 4)
방문한 좌표: (0, 4)
경로 찾기 성공: true
cf. (2,0)에서 벌어지는 일
- 큐에서 (2, 0)을 꺼낸다.
- (2, 0)의 인접한 좌표들(상하좌우)을 탐색한다.
상: (1, 0)은 이미 방문한 좌표이므로 큐에 추가하지 않는다.
하: (3, 0)은 아직 방문하지 않은 좌표이므로 큐에 추가한다.
좌: (2, 1)은 아직 방문하지 않은 좌표이므로 큐에 추가한다.
우: (1, 1)은 벽(1)이므로 큐에 추가할 수 없다.
- (3, 0)과 (2, 1)을 큐에 넣고, 방문 처리한다.
큐: [..., (3, 0), (2, 1)]
방문 처리: visited[3][0] = true, visited[2][1] = true
이렇게 (2, 0)에서는 인접한 좌표 중 (3, 0)과 (2, 1)이 큐에 추가된다.
이후에는 큐에서 다음 좌표를 꺼내서 위와 같은 과정을 반복하며 BFS 탐색을 진행한다.
비교
DFS: 깊이 우선 탐색으로, 막히면 백트래킹하여 다른 경로를 탐색
BFS: 너비 우선 탐색으로, 모든 경로를 동시에 확장하여 최단 경로를 보장
유기농배추
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.StringTokenizer;
public class Main {
static int[][] ground; // 배추밭을 나타내는 2차원 배열
static boolean[][] check; // 방문 여부를 확인하는 2차원 배열
static int weight; // 배추밭의 가로 길이
static int height; // 배추밭의 세로 길이
public static void main(String[] args) {
try {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int T = Integer.parseInt(br.readLine()); // 테스트 케이스의 수
StringTokenizer st;
for (int i=0; i < T; i++) {
st = new StringTokenizer(br.readLine(), " ");
weight = Integer.parseInt(st.nextToken());
height = Integer.parseInt(st.nextToken());
ground = new int[weight][height];
check = new boolean[weight][height];
int K = Integer.parseInt(st.nextToken()); // 배추가 심어진 위치의 수
for (int j=0; j < K; j++) {
st = new StringTokenizer(br.readLine(), " ");
int x = Integer.parseInt(st.nextToken());
int y = Integer.parseInt(st.nextToken());
ground[x][y] = 1; // 배추가 심어진 위치에 1을 표시
}
int count = 0; // 필요한 지렁이의 개수
for (int j=0; j < weight; j++) {
for (int k =0; k < height; k++) {
// 배추가 있고 방문하지 않은 위치라면
if (ground[j][k] == 1 && !check[j][k]) {
dfs(j,k); // 해당 위치에서 DFS 수행
count++; // DFS를 수행하면 연결된 모든 배추가 방문 처리되므로 지렁이 한 마리 추가
}
}
}
System.out.println(count); // 필요한 지렁이의 개수 출력
}
} catch (IOException e) {
e.printStackTrace();
}
}
static void dfs(int startX, int startY) {
check[startX][startY] = true; // 현재 위치 방문 처리
// 상, 하, 좌, 우 이동을 위한 배열
int[] X = {0,0,-1,+1};
int[] Y = {-1, +1, 0, 0};
for (int i =0 ; i < 4; i++) {
int x = startX + X[i];
int y = startY + Y[i];
// 배추밭을 벗어나는 경우 건너뛰기
if ( x < 0 || x >= weight || y < 0 || y >= height) {
continue;
}
// 인접한 위치에 배추가 있고 아직 방문하지 않았다면
if (ground[x][y] == 1 && !check[x][y]) {
dfs(x,y); // 재귀적으로 DFS 수행
}
}
}
}
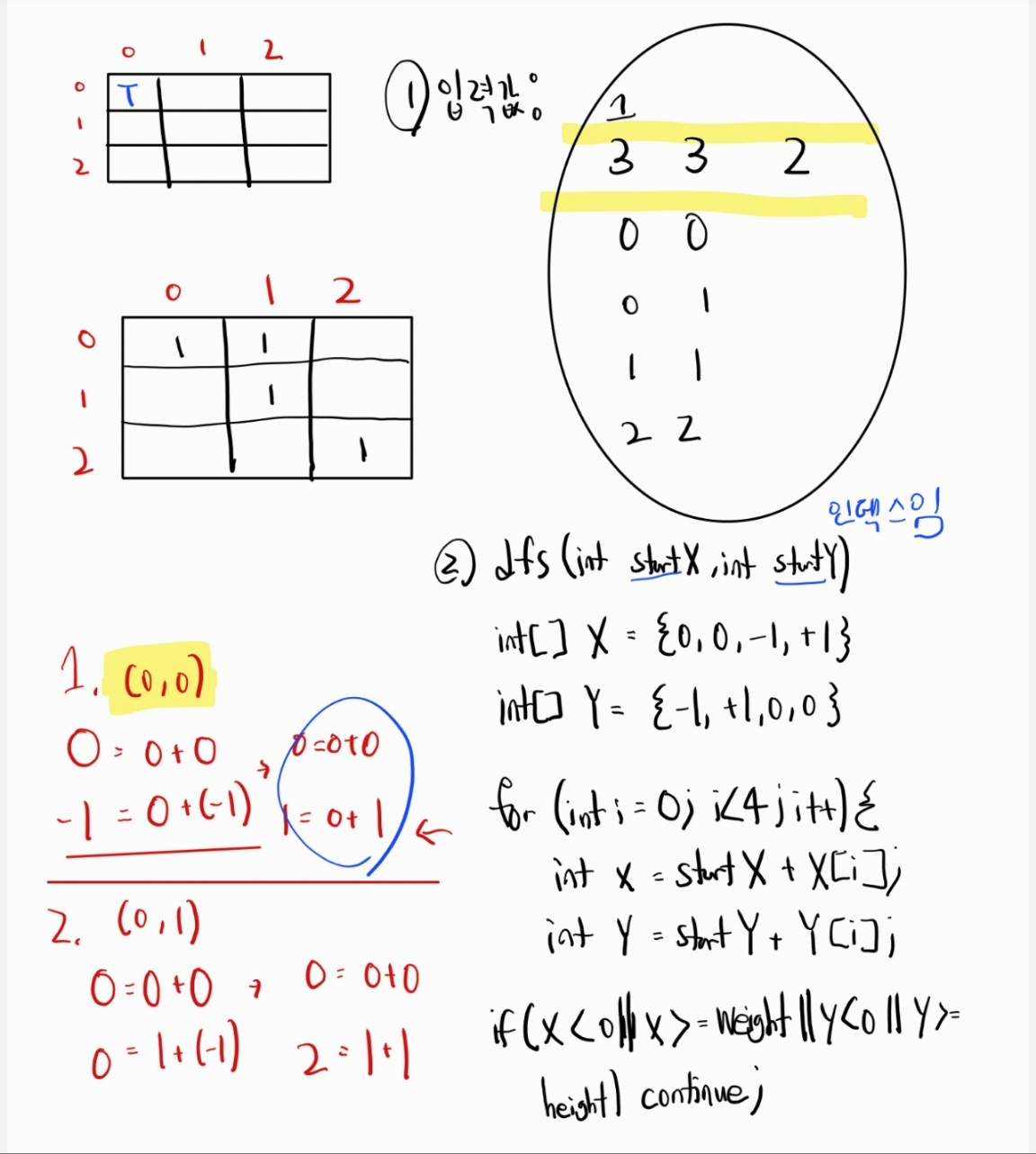
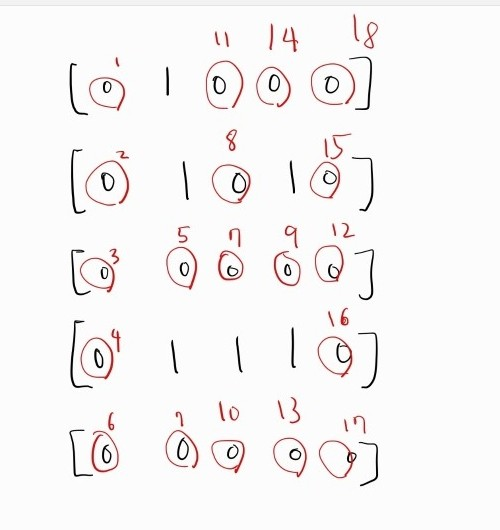
-
이중반복문을 통해 [j][k] 중에 1이고, 방문하지 않은 위치라면 해당 인덱스에서 dfs를 수행한다.
-
dfs()
a. 현재 위치를 방문처리 한다.
b. 인접한 위치에 배추가 있다면 재귀적으로 dfs를 수행한다. ([0,0][1,0][1,1]와 [2,2])
c. 상하좌우 좌표를 이용해서 만약 startX, startY와 X[i], Y[i] 를 더한 값이 가로세로 크기보다 크거나 0보다 작으면 범위를 이탈한 것으로 보고, 다음 반복을 진행한다.
d. 총 2개의 사이클이 존재하므로, 하나의 사이클 당 count가 1이 증가한다. -
반복문 종료 후, count는 총 2이므로 결과는 2다.
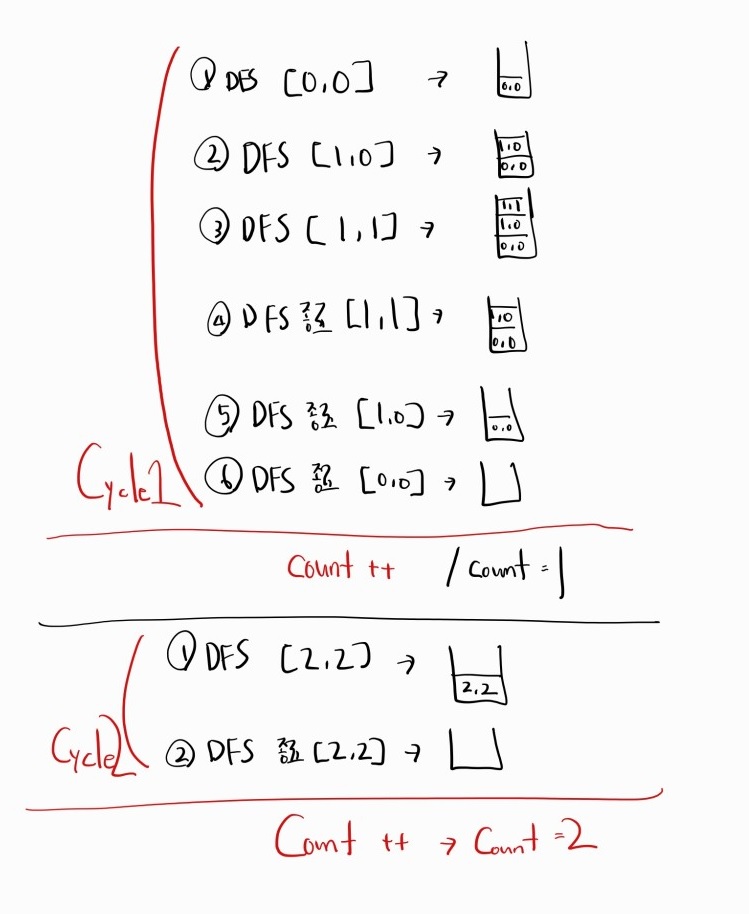
이 코드에서 사용된 재귀함수의 작동방식이다.
총 2개의 사이클이 존재하며, 1사이클 당 count가 1 증가하므로 최종 count는 2다.
시간복잡도
- 각 테스트마다 배추밭을 초기화 : O(K)
- 테스트 케이스 갯수 : O(N)
- DFS를 통해 배추밭을 탐색한다 : O(weight * height)
O(T (K + weight height))
상하좌우 좌표계
그림을 다시 보자.
현재 위치가 (1,0)이라면, 다음 움직일 위치는 바로 아래인 (1,1)이다.
오른쪽은 배추가 없기 떄문에 이동할 수 없다.
int[] X = {0,0,-1,+1};
int[] Y = {-1, +1, 0, 0};
for (int i =0 ; i < 4; i++) {
int x = startX + X[i];
int y = startY + Y[i];
// 배추밭을 벗어나는 경우 건너뛰기
if ( x < 0 || x >= weight || y < 0 || y >= height) {
continue;
}
// 인접한 위치에 배추가 있고 아직 방문하지 않았다면
if (ground[x][y] == 1 && !check[x][y]) {
dfs(x,y); // 재귀적으로 DFS 수행
}
} 이는 미로문제에서 자주 사용되는 방법인데, X,Y 배열의 1,2,3,4번째의 값의 세트가 차례대로 상,하,좌,우를 뜻한다.
상: (0,-1)
하: (0,1)
좌: (-1,0)
우: (1,0)
특이하게도 수학에선 상이 y = +1, 하는 y = -1이지만, 컴퓨터공학에선 그 반대다.
좌우는 동일하다.
대상: (0,1)
0번째 반복) 위로 갈 수 있는지 확인해보자.
int x = 1 + 0 -> 1
int y = 0 + (-1) -> -1
y가 -1이라서 다음 반복을 실행한다.
1번째 반복) 아래로 갈 수 있는지 계산하자.
int x = 1 + 0 -> 1
int y = 0 + 1 -> 1
둘 다 조건이 걸리지 않으므로 아래로 갈 수 있다.
2번째 반복)
int x = 1 + -1 = 0
int y = 0 + 0 = 0
둘 다 0이여서 문제는 없지만, 아래 조건문에서 걸려서 다음 i번째 반복으로 넘어가게 된다.
왜냐하면 이미 시작점인 (0,0)은 방문했기 때문이다. (check[x][y] = true이므로)
if (ground[x][y] == 1 && !check[x][y]) {
dfs(x,y); // 해당 좌표로 dfs 실행
}3번째 반복)
int x = 1 + 1 = 2
int y = 0 + 0 = 0
이 역시 범위 관련해서는 문제가 없지만, 위 if문에서 탈락된다.
왜냐하면 오른쪽 좌표는 (2,0)인데 ground[2][0]은 1이 아니기 때문이다.
참고: https://80000coding.oopy.io/51503941-ff71-4cd4-a4cc-ec8a68eddbb7
