제출 코드
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.StringTokenizer;
class Main {
private static int aLen;
private static int bLen;
private static int[] A;
private static int[] B;
private static int[] C;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
// 1. aLen, bLen 입력
aLen = Integer.parseInt(st.nextToken());
bLen = Integer.parseInt(st.nextToken());
A = new int[aLen];
B = new int[bLen];
// 2. 배열 A 입력
st = new StringTokenizer(br.readLine());
for (int i = 0; i < aLen; i++) {
A[i] = Integer.parseInt(st.nextToken());
}
// 3. 배열 B 입력
st = new StringTokenizer(br.readLine());
for (int i = 0; i < bLen; i++) {
B[i] = Integer.parseInt(st.nextToken());
}
// 4. 배열 합치기
C = new int[aLen + bLen];
int idx = 0;
for (int num : A) {
C[idx++] = num;
}
for (int num : B) {
C[idx++] = num;
}
// 5. 오름차순 정렬
Arrays.sort(C);
// 6. 출력
StringBuilder sb = new StringBuilder();
for (int i = 0; i < C.length; i++) {
sb.append(C[i]);
if (i != C.length - 1) {
sb.append(" ");
}
}
System.out.println(sb.toString());
}
}모범답안
package baekjoon.array;
import java.io.*;
import java.util.Arrays;
import java.util.StringTokenizer;
public class Main {
private static int aLen;
private static int bLen;
private static int[] A;
private static int[] B;
private static int[] C;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(System.out));
StringTokenizer st = new StringTokenizer(br.readLine());
// 1. aLen, bLen 입력
aLen = Integer.parseInt(st.nextToken());
bLen = Integer.parseInt(st.nextToken());
A = new int[aLen];
B = new int[bLen];
// 2. 배열 A 입력
st = new StringTokenizer(br.readLine());
for (int i = 0; i < aLen; i++) {
A[i] = Integer.parseInt(st.nextToken());
}
// 3. 배열 B 입력
st = new StringTokenizer(br.readLine());
for (int i = 0; i < bLen; i++) {
B[i] = Integer.parseInt(st.nextToken());
}
// 4. 배열 합치기
C = new int[aLen + bLen];
int idx = 0;
for (int num : A) {
C[idx++] = num;
}
for (int num : B) {
C[idx++] = num;
}
// 5. 오름차순 정렬
Arrays.sort(C);
// 6. 출력
StringBuilder sb = new StringBuilder();
for (int i = 0; i < C.length; i++) {
sb.append(C[i]);
if (i != C.length - 1) {
sb.append(" ");
}
}
bw.write(sb.toString());
// 남아있는 데이터를 모두 출력시킴
bw.flush();
bw.close();
br.close();
}
}
-
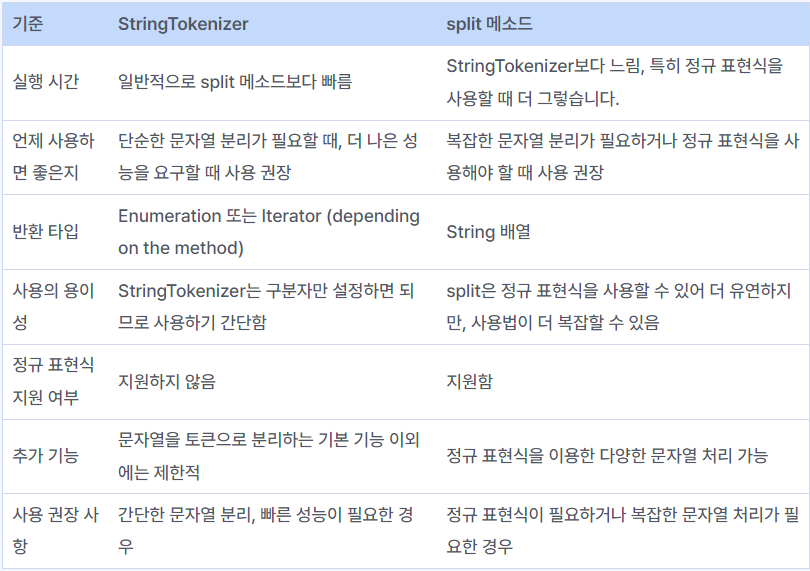
일반적으로 StringTokenizer의 nextToken() 메서드가 String.split() 메서드보다 약간 더 빠르다.
이는 String.split() 메서드가 정규 표현식을 사용하여 문자열을 분할하기 때문이다. 정규 표현식 처리는 일반적인 문자열 처리보다 더 많은 리소스를 소모한다. -
System.out.println() 보다 BufferedWriter()를 사용하는 것이 속도가 더 빠르다. 만약 BufferedWriter()를 사용하면 마지막에 flush(), close()를 작성해야 한다.
Stringtokenizer vs split()
import java.util.StringTokenizer;
public class TokenizerExample {
// StringTokenizer 예시
String str = "apple,banana,orange";
StringTokenizer tokenizer = new StringTokenizer(str, ",");
while (tokenizer.hasMoreTokens()) {
String token = tokenizer.nextToken();
System.out.println(token);
}
// String.split() 예시
String[] tokens = str.split(",");
for (String token : tokens) {
System.out.println(token);
}
}
BufferedReader, BufferedWriter를 활용한 빠른 입출력
https://coding-factory.tistory.com/251
깃허브 링크

화려한 외면이 아닌 단단한 내면