!pip3 install WordCloud
!pip3 install konlpyfrom wordcloud import WordCloud
from collections import Counter
from konlpy.tag import Okt
from konlpy.tag import Komoran
from PIL import Image
import matplotlib.pyplot as plt
import numpy as npwith open('C:\\Users\\dd\\Desktop\\Virtual_Hadoop\\04.WordCount\\대한민국헌법.txt', 'r', encoding='utf-8') as f:
text = f.read()okt = Okt()
# 명사만 추출
nouns = okt.nouns(text) words = [n for n in nouns if len(n) > 1] # 단어의 길이가 1개인 것은 제외
# 위에서 얻은 words를 처리하여 단어별 빈도수 형태의 딕셔너리 데이터를 구함
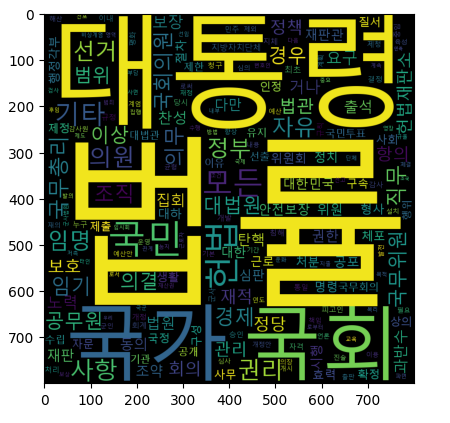
wcnt = Counter(words) wc = WordCloud(font_path='malgun', width=400, height=400, scale=2.0, max_font_size=250)
gen = wc.generate_from_frequencies(wcnt)
plt.figure()
plt.imshow(gen)

열심히 공부합시다! The best is yet to come! 💜