
주제별로 문제를 하나 골라보고, 그 과정에서 어려움을 느꼈던 부분이 있으면 같은 주제의 문제를 다시 풀어보는 중이다. 대신 그 문제의 어떤 부분에서 어려움을 느꼈는지 확실히 해두고 넘어가려고 노력하는 중.
이번에는 2580 스도쿠를 풀고 정보를 갱신하는 데에 있어서 막힘을 느껴서 7682 틱택토를 풀었다.
백트래킹(Backtracking)
백트래킹은 주어진 모든 조건에 대해 로직을 수행하고, 중간에 더 이상 볼 필요가 없는(확실히 정답이 아닌) 경우가 발생할 경우 해당 조건을 배제하고 다음 조건에 대해 다시 로직을 반복한다. 유효하지 않은 조건을 명확히 찾는 것이 중요.
순차적인 값들을 선택해야하고 해당 선택들을 Node로 나타내면 트리로 표현할 수 있다. 따라서 BFS혹은 DFS를 사용해 탐색한다. BFS의 경우 대체로 Queue에 동시에 저장되는 값이 DFS보다 많기 때문에, 메모리 사용에 주의해야하며, 그런 이유로 DFS를 사용하는 것이 더 효율적인 경우가 많은 것 같다. 대신 트리의 깊이가 무한대가 될 수 있는 경우 BFS를 사용해야한다.
개인적으로 생각하기에(윗 문단과 거의 같은 말이지만), DFS는 선택하고 있는 데이터의 배열을 매번 재귀때마다 복사해서 전해주지 않아도 된다는 장점이 있다.
예시
Q. 1, 2, 3, … , 10의 수를 5칸에 배치한다. 단, 배열의 모든 수가 서로 근접하는 수여서는 안된다.
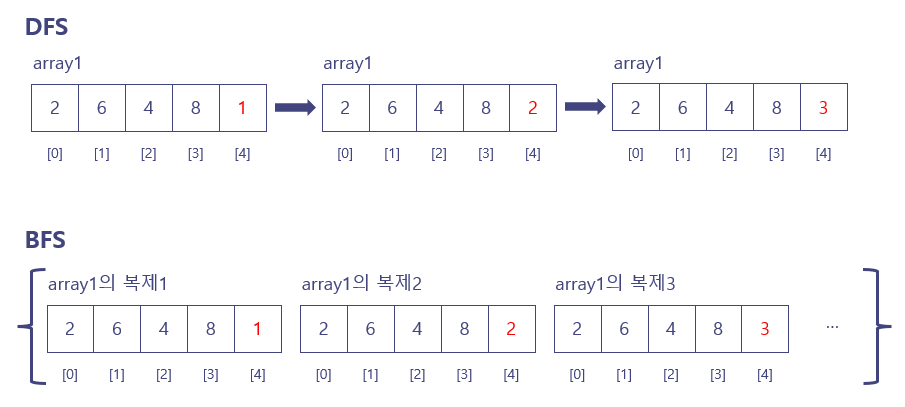
위와 같은 배열이 앞의 단계를 거쳐서 나왔고, 인덱스 4의 값을 구한다 했을 때, DFS의 경우 현재 조건을 위해 배열의 값 자체를 바꾸어도 다음 조건을 검사하는 데에 있어 영향을 미치지 않는다. 하지만 BFS의 경우 각 조건에 대한 배열의 상태를 함께 저장해두어야한다. 배열을 하나만 사용해 해당 배열의 값을 바꾸면 다른 조건에 대해 검사할 때 영향을 미치기 때문.
즉, DFS는 배열 1개를 이용해 데이터 관리가 가능하지만 BFS는 그렇지 않다는 것. 메모리 관리 측면에 있어서 DFS가 훨씬 효율적임을 알 수 있다.
2580 스도쿠
위에서 굳이 배열을 복사하지 않아도 된다는 점을 굳이 강조한 이유가, 이 문제에서 해당 요소로 인해 많이 헤맸기 때문. 아마 경험이 부족해서 그랬던 것 같다. 원본 배열만 가지고 매번 해당 값을 직접 수정하여도 다른 조건을 검사하는 데에 영향을 미치지 않는다.
문제를 요약하자면 스도쿠 판이 주어졌을 때, 빈칸에 들어갈 적절한 값을 선택하는 것이었다. 각 단계에 대해 현재까지 선택한 데이터를 어떻게 넘겨줄까에 대해 많은 고민을 했다. 9*9짜리 필드를 매번 재귀 단계마다 복사하는 것은 분명 메모리에 문제가 생길 것이라고 판단하였다.
시도 1 : 빈칸에 대한 배열만 전달, 시간초과
board = [[] for i in range(9)]
blank = []
for i in range(9) :
board[i] = list(map(int, input().split(" ")))
for j in range(9) :
if board[i][j] == 0 :
blank.append((i, j))
value = [0 for i in range(len(blank))]
findPerfectBoard(0, value)blank 배열을 만들어 입력을 받을 때 빈칸의 x, y좌표를 tuple의 형태로 저장하였다.
value의 경우 각 blank에 어떤 값이 들어가는지를 저장할 list로, blank와 인덱스를 공유한다.
blank[i]의 좌표에 들어갈 값이 value[i]에 저장되는 방식. dictionary로 저장하면 더 직관적이었겠으나... 메모리가 더 들어갈 것 같아서 value를 별개의 list로 저장했다. 그리고 부질없었다
# row
for i in range(9) :
if board[cur_y][i] != 0 :
if board[cur_y][i] in valid :
valid.remove(board[cur_y][i])
else :
comparator = newValue[blank.index((cur_y, i))]
if comparator != 0 and comparator in valid :
valid.remove(comparator)
if len(valid) == 0 :
return현재 좌표에 대해 이 스도쿠 판이 유효한지 검사하려면 해당 row, column, 그리고 속해있는 3x3짜리 구역(이하 area)를 검사해야한다. 과정은 전부 비슷해서 row에 해당하는 코드만 가져왔다.
스도쿠 판이 저장되어있는 board(변하지 않는 부분)와 blank(매 선택마다 변하는 부분)에 들어갈 값을 별개로 저장하였기 때문에, board를 검색하다가 blank에 해당하는 부분이 있을 경우(값이 0인 경우) value list에서 해당 값을 가져오는 식으로 검사하였다.
메모리 초과는 발생하지 않았으나, 시간초과가 발생했다. 아마 blank인 조건을 매번 검사하고, 현재 검사중인 조건을 저장한 newValue 배열에서 매번 값을 삭제하고 추가하는 과정을 반복했기 때문으로 추정.
하지만 나는 이 과정이 문제일 것이라고 추측하지 못하고, 매번 row, column, area 검사를 반복하는 시간으로 인해 시간초과가 발생했을 것이라고 착각했다. 그래서 검사하는 시간을 줄이기 위해 방식을 변경했다.
시도 2 : 각 row, column, area에서 부족한 값을 별개의 배열에 저장, 시간초과
만일 첫번째 row가 1 2 0 4 5 6 0 8 9 였다고 생각해보자. 그러면 이 row에는 3, 7이 빠져있다. 그래서 모든 row와 column, area에 대하여 새로운 배열을 만들어 이 빠진 숫자들을 별도로 저장하고, 해당 배열에서 값들을 뽑아내어 빈칸에 대치해보면 되지 않을까?
def findCompleteBoard(idx, value) :
isEnd = False
if idx == len(value) :
printBoard(board, value)
return True
y, x = blank[idx]
areaIdx = int(y/3)*3+int(x/3)
candidate = [a for a in missingNumRow[y] if a in missingNumCol[x] and a in missingNumArea[areaIdx]]
if len(candidate) == 0 :
return False
for i in candidate :
value[idx] = i
missingNumRow[y].remove(i)
missingNumCol[x].remove(i)
missingNumArea[areaIdx].remove(i)
isEnd = findCompleteBoard(idx + 1, value)
if isEnd :
return True
missingNumRow[y].append(i)
missingNumCol[x].append(i)
missingNumArea[areaIdx].append(i)
return False해당하는 각각의 2차원 list를 missingNumRow, missingNumCol, missingNumArea로 명명하고, missingNumRow[0]에는 0번째 row에 빠진 숫자들을 저장하였다.
특정 빈칸에 들어갈 수 있는 숫자는 missingNumRow, missingNumCol, missingNumArea의 교집합이다. 교집합이 존재하지 않을 경우 들어갈 수 있는 유효한 값이 없다는 것이고, 이 조건은 더이상 진행하지 않고 즉시 종료한다.
교집합이 존재할 경우 해당 교집합의 숫자를 blank에 넣고, missingNumRow, missingNumCol, missingNumArea배열에서 해당 숫자를 제거하고 재귀를 수행하고, 재귀가 끝나면 missingNumRow, missingNumCol, missingNumArea 배열에 해당 숫자를 다시 넣어주었다.
스스로 생각하기에 신박한 방법이었으나 역시 시간초과.
시도 3: board 배열 자체에 현재 검사중인 값을 저장. 성공
시도 2를 해보며 생각해보니, missingNumRow, missingNumCol, missingNumArea 배열을 모든 조건들에 대해 공유했던 것처럼, 이전의 수정이 다음 조건의 검사에 영향을 미치지 않는다는 것을 깨달았다. 그렇다면 value 배열을 매번 deep copy해 전달할 필요가 없고, 그러면 매번 이 칸이 빈칸인지 검사하고 value에서 빈칸에 해당하는 값을 찾는 과정도 필요가 없다.
또한, 매번 빈칸에 대해 row, column, area를 검사하는 것도 각 경우당 27번의 검사만이 필요하다. 빈칸의 개수가 N일 경우 결국 시간복잡도는 O(N)인 것. 생각보다 많은 시간이 걸리지 않는 것 같았다.
- board의 빈칸에 현재 검사중인 값을 직접 넣는다. 1~9의 수를 집어넣고 매번 수를 집어 넣을 때마다 재귀 함수를 호출한다.
- 이전 단계에서 넣은 수에 대해 27번의 검사를 수행.
- 만일 현재 넣은 값이 27개 중에 이미 존재할 경우 그 경우는 유효하지 않은 경우이므로 더 이상 진행하지 않고 종료.
- 종료하면 재귀함수 호출 직전으로 돌아간다.
돌이켜보니 정말 어이없는 부분에서 헤맸던 것 같다. 앞서 말한것처럼 굳이 배열을 복사하지 않아도 된다는 점을 깨닫지 못했던 것이 화근. 해당 부분을 확실히 습득하고 싶어서 7682번 틱택토를 풀었다.
