웹 크롤링을 할 건데, Python 의 동시성 프로그래밍을 이용해 크롤링 속도를 높여볼 거다.
동시성 프로그래밍을 사용해 성능을 높여볼 수 있는 다양하고 멋진 서비스들이 많지만, 내 실력에 속도를 제일 확연히 느끼며 측정해볼 수 있으며, 무엇보다 내가 유일하게 만들 수 있는 간단한 프로그램이 크롤링이니까...
게다가 이번에 속도가 nodejs 급으로 빠르다는 Fastapi 를 배웠기 때문에(인프런 파이썬 동시성 프로그래밍) 한 번 사용해보려고 한다.
Django에 비해 매우 쉽게 배울 수 있는 편이라고 한다.
나도 어제 이거 하루만에 만들었다.
크롤링이??? 크롤러가 하루면 오래걸린거아니냐? 라고 하는 사람들은 내 실력을 모르는 거다.
나는 정말 댕청이기 때문에 하루만에 만든 건 정말 빨리 만든거다.
사실 DRF 로 하루만에 만든 api 도 있지만 아무튼 빠른 거임
아무튼 빠름.
시작해볼까
시작

일단 가상환경
python -m venv <가상환경이름> 으로 가상환경을 만들어준다.
환경을 만들었으면 본격적으로 시작하기 전에 fastapi 를 비롯해서 몇가지 설치를 해야할 라이브러리들이 있는데,
fastapi: 우리가 사용할 프레임워크 - fastapi 설치 및 설명
pip install fastapi✅uvicorn: 서버와 연결 시켜주는 라이브러리 - uvicorn 설치 및 사용 설명
pip install uvicorn[standard]✅
여기서pip install uvicorn이라고 하게되면(standard 로 설치하지 않으면) uvloop 가 설치되지 않아, 성능이 조금 떨어지게 된단다. FastAPI 톺아보기pandas: 우리가 데이터를 가져와 정렬한 뒤에 excel 로 내보내기 위해서 필요하다.
그리고openpyxl도 필요하다.pandas에서to_excel로 내보내려면openpyxl이 있어야한다.
pip install pandas✅
pip install openpyxl✅
일단 우리가 네이버 검색 api 를 사용할 거기 때문에,
아 물론 BeautifulSoup 을 사용해서 데이터를 가져와도 된다.
데이터 가져오는 건 내가 손 볼 부분이 아니다.
네이버 쓰기 싫으면 뭐 다른 방법으로 쓸만한 데이터 긁어옵시다.
일단 우리는 네이버 검색 api 를 사용할 거기 때문에,
secrets.json 을 만들고 main.py 도 만들어야할 거고, secrets.json 을 가져올 config.py 도 만들어야하고, 데이터 모델을 만들어야하니까 item.py 라고 할까? 아무튼 모델도 만들어야한다.
우선 fastapi 를 설치하면(pip install fastapi) jinja2 가 있어서
templates 를 사용할 수 있다.
우린 대단한 서비스를 만드는 게 아니기 때문에 vue 같은 건 없다.
index.html 로 만들어버릴 거다.
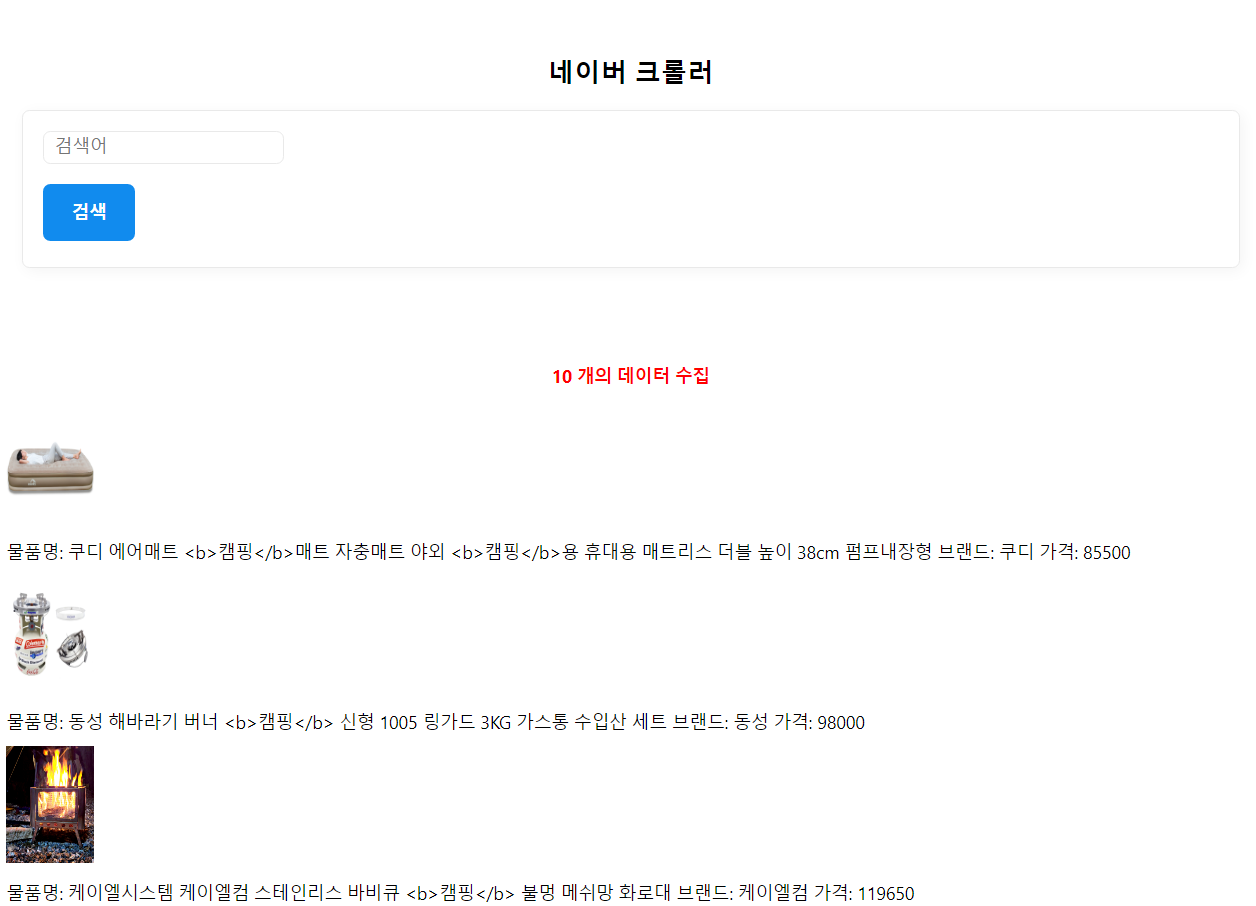
너무 대충인가.(아쉬운점1)
모 어때여~
중요한 건 페이지에 노출이 아니라 excel 로 받을 수 있도록 정리된 파일! 그게 중요한 겨!
파일만
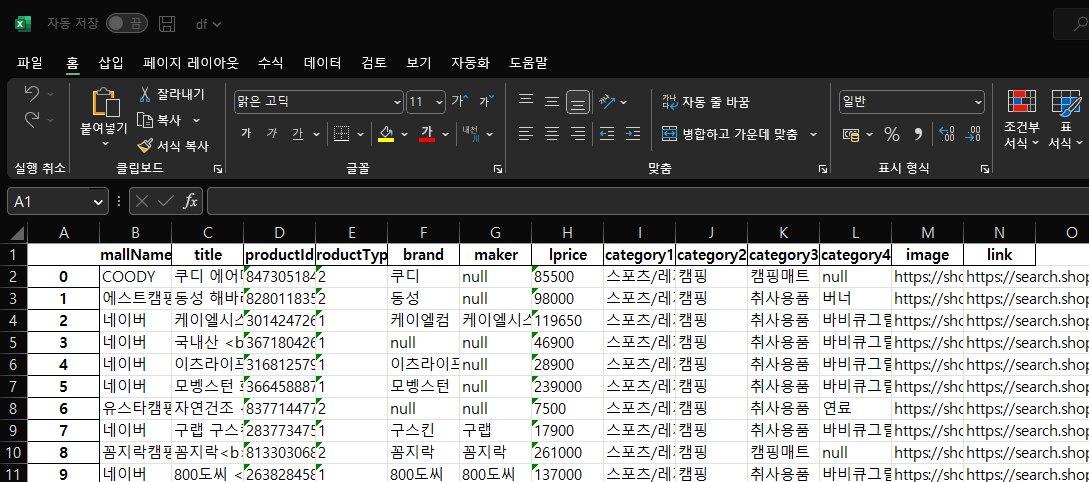
이렇게 잘 나오면 된 겨!
사실 아쉬운 부분이 많지만 차차 개선해 나갈 수 있는 부분들이다.(아쉬운점2)
아무튼 검색어를 입력해서 검색하면 검색된 네이버 api 의 응답이 페이지에 표시되는 동시에, excel 파일로 저장되게 만들 거다.
아쉬운 부분은 뒤에서 한 번에 얘기하고 앞으로 리팩토링을 통해서 차차 개선해나가도록 하자.
일단 된 다는 게 중요한 거 아니겠어요?
일단 가상환경 만들었으니
진짜 시작
root 폴더에 server.py를 만들고 root-app 폴더에 main.py 를 만들어서
페이지를 띄워보자.
# server.py
import uvicorn
if __name__ == "__main__":
uvicorn.run("app.main:app", host="localhost", port=8000, reload=True)app 폴더에 있는 main 파일을 열어서(app.main:app) 8000번 포트로 열고 코드가 새로 저장되면 새로고침 하자.(reload=True)
# app/main.py
from fastapi import FastAPI, Request
from fastapi.responses import HTMLResponse
from fastapi.templating import Jinja2Templates
# 절대 경로 지정을 위한 path 지정 Base_dir
from pathlib import Path
BASE_DIR = Path(__file__).resolve().parent
app = FastAPI()
templates = Jinja2Templates(directory=BASE_DIR / "templates")
@app.get("/", response_class=HTMLResponse)
async def root(request: Request):
return templates.TemplateResponse(
"./index.html", {"request":request}
)라고 하면 이제 index.html 파일이 필요하다. 보통 index.html 을 만들어주자.
jinja로 template 를 만들어주고 보내주는 건 뭐 어려운 건 아니니까.
<!-- app/templates/index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>네이버 크롤러</title>
<link href="https://unpkg.com/mvp.css" rel="stylesheet"/>
</head>
<style>
section {
display: block;
flex-wrap: wrap;
gap: 15px;
}
</style>
<body>
<header>
<h1>네이버 크롤러</h1>
<center>
<form id="search_form" action="/search">
<input
type="search"
placeholder="검색어"
id="search_input"
name="query"
/>
<button type="submit">검색</button>
</form>
</center>
</header>
<main>
{% if items %}
<center>
<h3 style="color:red">{{items|length}} 개의 데이터 수집</h3>
</center>
<section>
{% for item in items %}
<div>
<img src="{{item.image}}" width="60px" height="80"/>
<p>
물품명: {{ item.title }}
브랜드: {{ item.brand }}
가격: {{ item.lprice }}
</p>
</div>
{% endfor %}
</section>
{% else %}
<center>
<h3 style="color: red;">검색해주세요</h3>
</center>
{% endif %}
</main>
</body>
</html>이렇게 하면 이제 /search 메서드가 필요하지. item 은 없으면 검색해주세요 가 나타나니 천천히 만들어 주자.
일단 이렇게 만들고 터미널에 python server.py 라고 서버를 실행시킨 뒤에
localhost:8080 에 접속하면 몬가 페이지가 나타나겠지?
그러나 검색을 하면 /search 페이지는 안 만들어졌으니 에러가 나겠징.
이제 search 를 만들어주자.
본격적인 크롤링 메서드 만들기
이제 본격적으로 만들텐데 일단 main.py 에다가 search 메서드를 만들어주자.
# main.py
...
@app.get("/search", response_class=HTMLResponse)
async def search(request: Request, query: Union[str, None]):
keyword = query
navershopscraper = NaverShopScraper()
# 데이터 가져오는 메서드
items = await navershopscraper.search(keyword, 1)
item_models = []
for item in items:
item_model = ItemModel(
keyword=keyword,
title=item["title"],
brand=item["brand"],
price=item["lprice"],
image=item["image"],
link=item["link"],
mallName=item["mallName"],
productId=item["productId"],
productType=item["productType"],
maker=item["maker"],
category1=item["category1"],
category2=item["category2"],
category3=item["category3"],
category4=item["category4"],
)
item_models.append(item_model)
return templates.TemplateResponse(
"./index.html", {"request": request, "items": items}
)이렇게 만든 뒤에 실제로 크롤링을 실행하는 NaverShopScraper() 메서드를 만들어야겠지?
그리고 아래쪽에 ItemModel 이라는 우리 상품들의 모델을 만들어주자.
사실 없어도 되는 거긴 한데, 저렇게 차곡차곡 넣어놓으면 나중에 자료 만들 때도 좋겠지?
검색되어 들어온
items데이터가item_models를 거치지 않고 바로return templates로 보내지는 걸 알 수 있다. 순전히 데이터를 정돈해서 파일로 내보내기 위함임.
물론item_model을 거쳐 사용할 수도 있다.
여기서 또 아쉬운 점이 생기긴 하는데 나중에 이야기하도록 하고,(아쉬운점3)
아무튼 Model 을 만들어서 넣어준다면 그냥 메서드 내에서 딕셔너리를 만드는 것 보다 이로운 점이 생긴다.
model 을 만들어주면 좋은 점
예를 들어 ItemModel 이
# item.py
from odmantic import Model
class ItemModel(Model):
keyword: str
production: str
price: int라고 했을 때
우리가, 혹은 사용자가 혹은 데이터가 잘못 들어간다면(이것도 결국 우리 짓이지)
예를 들어
# main.py
...
item_models = []
for item in items:
item_model = ItemModel(
keyword=keyword,
production=item["production"],
brand=item["brand"], # Model 엔 없는 항목😞😞😞😞😞😞😞
price=item["lprice"]
)
item_models.append(item_model)
...이렇게 실수로 없는 항목을 집어넣는 메서드가 되거나 ( 여기서 또 아쉬운 부분이 생긴다. 아쉬운점4)
자동으로 저 항목은 걸러서 넣어준다.
그래서 item_model 에 들어갈 때 keyword, production, price 는 있지만, brand 는 없는 채로 들어가게 된다. 에러는 나지 않는다.(이게 좋으면서도 아쉬운 부분임)
아무튼! (아무튼무새)
model 이 있으면 좋다!
일단 만들지 않은 Navershopscraper 라는 메서드를 만들어야겠지?
결국 이 메서드는
scraper 가 데이터를 가져오면
그걸 jinja 가 (index.html 에서) for 문으로 하나씩 출력시켜주는 거다.
이제
엄밀히 말해 scraper 라고 할 수는 없는
Naver Shop API 를 이용해보자.(feat. aiohttp)
준비물: Naver api id, Naver api SecretKey 꼭 챙겨오자.
일단 우리는 동시성 프로그래밍을 위해서 비동기 http 요청을 날리는 aiohttp 를 사용해볼 거다.
사실 api 를 사용하지 않고 진짜 긁어오는 거라면 뭐 필요없는 거 아닌가?
bs4 를 사용할 때 http 요청을 하기도 하나?
뭐 아무튼 aiohttp 를 사용해볼 건데, 그 전에!
Requests vs aiohttp 🤜💥🤛
먼저 requests 요청 메서드를 만들어보자.
앗 그전에 url 을 만들어주는 메서드 를 만들어보자.
def unit_url(self, keyword, start):
return {
"url": f"{self.NAVER_API_SHOP}?query={keyword}&display=10&start={start}",
"headers": {
"X-Naver-Client-Id": self.NAVER_SEARCH_API_ID,
"X-Naver-Client-Secret": self.NAVER_SEARCH_API_SECRETKEY,
},
}start 는 첫 시작 위치를 적는거다. 그래서 start 에 10이 들어오면 10 번째부터 display에 들어온 수만큼 보여준다.
예를 들어,
display=10, start=1 이라면
1번째 부터 10개의 항목을 보여주고 [1~10] 이 되겠지
start 가 2 로 넘어가면
2번째 부터 10개의 항목을 보여준다. [2~11] 이 될거다.
start 없이 한번에 display 에 1000 을 넣지 왜 굳이 start 를 넣어 잘라 넣냐고?
조금씩 잘라서 비동기로 처리할 때를 위해서.
그래서 unit_url 에 props 를 넘겨줄때 항목이 겹치지 않게 계산해서 값을 보내주자.
진짜 requests 요청 메서드를 만들어보자
# shop_scraper.py
def searchRequests(self, keyword, total_page):
start = time.time()
apis = [self.unit_url(keyword, 1 + i * 10) for i in range(total_page)]
all_data = []
for api in apis:
res = requests.get(api["url"], headers=api["headers"])
if res.status_code == 200:
result = res.json()["items"]
all_data.append(result)
result = []
for data in all_data:
if data is not None:
for item in data:
result.append(item)
end = time.time()
print(end - start)
return resulttotal_page 가 많아질 수록 apis 길이가 길어지고, 그럼 뒤에 있는 api 는 줄을 오래 기다려야겠지?
이번엔
aiohttp 로 비동기 요청 메서드를 만들어보자.
async def fetch(session, url, headers):
async with session.get(url, headers=headers) as response:
if response.status == 200:
result = await response.json()
print("성공")
return result["items"]
else:
print("fetch 실패")
async def searchAiohttp(self, keyword, total_page):
start = time.time()
apis = [self.unit_url(keyword, 1 + i * 10) for i in range(total_page)]
# aiohttp 를 이용한 비동기 http 요청
async with aiohttp.ClientSession() as session:
all_data = await asyncio.gather(
*[
NaverShopScraper.fetch(session, api["url"], api["headers"])
for api in apis
]
)
result = []
for data in all_data:
if data is not None:
for item in data:
result.append(item)
end = time.time()
print(end - start) # 0.21107125282287598
return result요청에 걸린 시간을 측정해보자
requests 요청했을 때 소요 시간

aiohttp


🙂ㅎㅎ?
왜 더 오래걸리지 ㅎㅎㅎㅎ...
1개를 해서 그럴 수도 있다.
total_page 를 4개로 바꿔보자. 그럼 조금 더 동시성이 빛을 발하겠지.
requests

4개로 바꾼 aiohttp
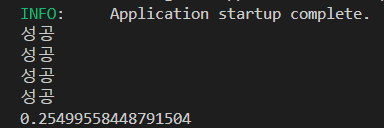
오 좋아 시간이 확실히 적게 걸린다.
10개로 늘려보자.
10개의 requests

10개의 aiohttp
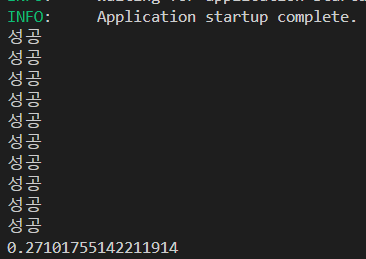

와 확실히 차이가 있다!
동시성으로 프로그래밍 했을 때는 연산 해야할 것들이 많아져도 속도가 많이 느려지지 않는다.
마지막으로 total_page 를 100 으로 잡아 1000개의 데이터를 가져오는 시간을 측정 해봐야지.
했으나, 데이터 100개가 넘어가면 429 error 를 뱉는다 429 error 는 요청이 너무 많아 스팸처리 되는 거라고 stackoverflow 가 설명해줬다...
아쉽지만... requests 로 해보자.
requests 로 보낸 데이터는 잘 나온다. 1000개의 데이터임

requests 는 되고 aiohttp 는 안되는 걸 보니, 동시성 프로그래밍을 이용한 요청은 너무 빠르게 많이 들어와서 스팸처리가 되나보다.
아무튼! (아무튼무새)
이렇게 속도 차이가 많이 난다~
요청량이 적다면 오히려 requests 가 더 빠를 수도 있다~
그래서 이렇게 데이터를 가져오면 return result 로 결과들을 돌려주고,
main 에서 jinja templates 로 item 값을 넣어주면 검색된 항목들이 페이지에 표현된다.
그럼 이제 밖으로 데이터를 내보내기
받은 데이터 excel 로 내보내기
힘드니까 다음 글로 적고 싶지만
대충 적어보자면
item 들을 pandas 를 이용해 dataframe 으로 만든다.
표로 만든다는 얘기임.
그 표를 pandas 내부 메서드 to_excel 을 이용하면 바로 밖으로 내보내진다.
import pandas
itemdf = pandas.DataFrame(item)
itemdf.to_excel("itemlist.xlsx")하면 된다.
하지만 여기서 바로 pandas 만 사용하면 'openpyxl' modulenotfound error 가 생긴다.
하지만 우리는 해결법을 알지
ModuleNotFoundError: No module named 'openpyxl'
to_excel 을 이용하면 excel 로 내보내는 거고 csv 파일로 내보낸다던가 다른 방법도 많다 pandas 에는.
다양한 파일로 쉽게 내보낼 수 있다.
끝
아쉬운 점이 많다.
하나씩 다음 글을 쓰면서 개선해나가보자.

어찌됐든
동시성 프로그래밍의 빠른 속도를 느꼈다.
최대한 순수함수형태로 코드를 짜보려고 했는데, 모... 잘 안 된 거 같다.
이렇게 해서 함수형 프로그래밍을 배우고 있으니 조금 더 다듬으면
한 페이지에서 다양한 naver 검색 api 를 사용할 수 있고, excel 파일로 받을 수 있는 페이지가 나오지 않을까 생각한다.
모.. 사실 아무짝에 쓸모는 없음 ;
사실상 함수형 프로그래밍과 동시성 프로그래밍의 연습이지만
그래도 괜찮게 만들면 모... 나중에 excel 필요할 때 좋겠지 모...
아쉬운 점
- 페이지에 대한 아쉬움
1-1. 노출 항목 수를 페이지에서 조절하고 싶다.
1-2. 검색을 했을 때 바로 excel 파일을 저장하지말고, 버튼을 눌렀을 때 저장이 되게 하고싶다.
1-3. 저장이 될 때 저장루트를 지정된 곳으로 정하거나, 사용자가 선택하는 폴더로 저장되게 하고싶다. - excel 파일에서 productType 을 숫자가 아니라 해당 항목에 대한 설명? 으로 저장하고 싶다.
- 자료를 만들 때 넣어야 하는 모델의 항목들을 크롤링해서 일일이 알아내지 말고 알아서 가져오게 할 순 없을까.
- 실수로 model 에는 없는 항목을 집어넣는 메서드를 작성했을 때 필터가 되긴 하지만 에러가 나타나지는 않는다. 그래서 실수로 넣는 메서드를 만들었다해도, 에러가 나지 않으니 알 수 없다.
개선해보면 매우 좋을 듯.
심심하니까 해보자.
