개요
이번 포스팅은 JS의 비동기 프로그래밍의 중요한 요소들을 간단하게 짚고 넘어간 뒤, 비동기를 처리하는 방식 3가지인 Callback, Promise, Async Await의 내부를 살펴볼 것입니다.
JS는 싱글 쓰레드다?
자바스크립트는 흔히 싱글 쓰레드기반 언어라고 불립니다. 하지만 싱글 쓰레드만을 사용하지 않습니다.
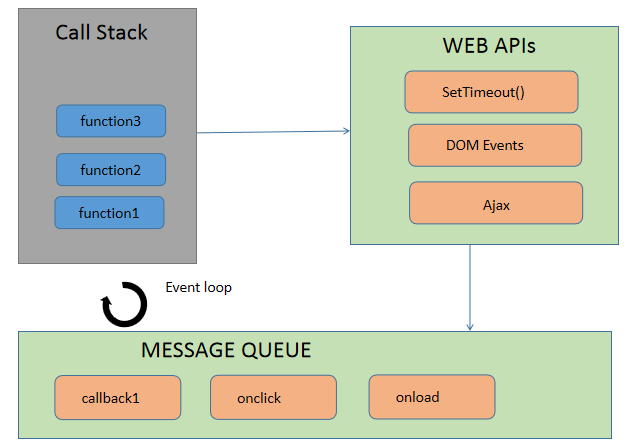
싱글 쓰레드 언어라고 불리는 이유는 Call Stack이 하나이기 때문입니다. 그래서 전역 Main 함수를 포함해, 함수의 실행을 하나의 쓰레드가 순회하면서 실행합니다. 하지만 하나의 스레드로만 연산을 모두 처리하면 자바스크립트는 지금까지 살아남는 언어가 되지 않았을 것입니다.
JS의 비동기 프로그래밍 특징
JS는 하나가 모든 일을 담당하는 싱글 쓰레드의 단점을 회피하기 위해 비동기 프로그래밍을 사용합니다. Source를 순회하는 쓰레드는 하나이지만 Network IO나 DB를 조회하는 등, 시간 비용이 큰 로직은 다른 쓰레드로 위임을 하고 다른 로직으로 이동해 할 것들을 합니다.
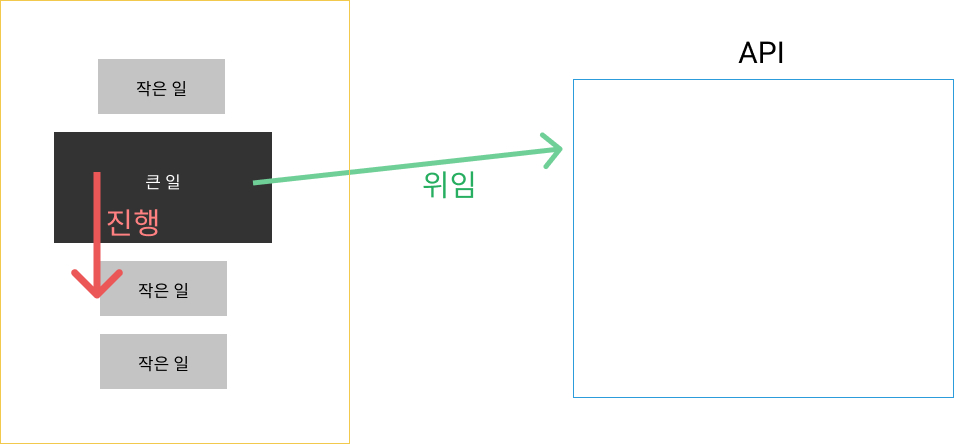
이렇게 큰 일들은 다른 쓰레드로 던져서 위임하는 것은 비동기 특징입니다. 위임시키는 대상은 API라는 곳인데, 브라우저에선 WebAPI, NodeJS에선 Node API 라고 부르는 별개의 쓰레드 영역입니다. 큰 일을 던져준 쓰레드는 쉬느냐? 쉬지 않습니다. 던져준 일을 기다리지 않고 다른 일로 진행하는 것을 논 블로킹이라고 합니다.
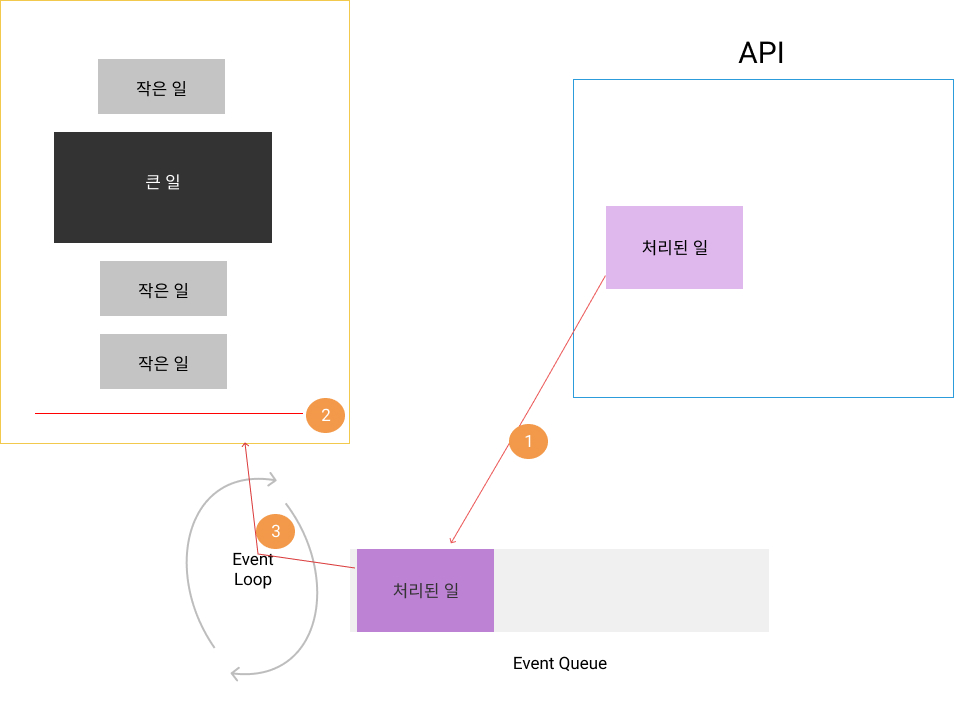
그리고 다른 쓰레드에게 던진 일이 끝나면, 그 큰 일이 마저 해야할 것을 처리할 수 있게 Source를 순회하는 쓰레드가 알 수 있게 이벤트로 알려주는 시스템을 이벤트 기반 아키텍처 라고 부릅니다. 그 과정은
(1) 처리된 일은 Event Queue에 들어가고 대기를 합니다.
(2) 제어 쓰레드가 일을 마쳐서 CallStack에서 실행할 게 없어지면
(3) Event Loop는 Event Queue에 있는 일을 하나 꺼내서 CallStack에 집어 넣어 실행합니다.
비동기 처리 방식 3가지
이제 비동기로 발생한 결과물을 처리하는 시스템 3가지를 알아보겠습니다.
Callback
Callback은 ES6에서 Promise가 표준화될 때까지 비동기를 처리하는 공식 방법이였습니다.
비동기를 호출하는 함수를 호출하면서 콜백 함수라는 인자를 넣어 함수의 결과물을 필요로 하는 뒤의 로직을 구성할 수 있게 됩니다.
코드로 보는 Callback
위의 상황을 코드로 작성하겠습니다.
console.log('작은 일');
bigTask((result) => {
console.log(result);
});
console.log('작은 일');
console.log('작은 일');Node API, Web API 둘 다 있는 setTimeout를 사용해 간단히 비동기 상황을 구현하겠습니다.
function bigTask(callback) {
setTimeout(() => {
const result = '큰 일';
callback(result);
}, 1000);
}여기서 bigTask의 호출 방식은 아래와 같은 실용적인 DB 접근 함수와 비슷합니다.
bigTask((result) => {
console.log(result);
});
userModel.findById(id, (user) => {
console.log(user);
});DB 접근 메서드에 id라는 인자가 하나 더 있지만 필요 인자 개수의 차이지, Callback System은 같습니다.
callback을 사용하는 비동기 함수 내부에선 대부분 bigTask 함수처럼 함수가 만들어낸 결과물을 사용자가 정의한 callback이란 함수에 인자로 넣어 호출하는 시스템입니다.
하지만 Callback은 뒤에 나올 Promise, Async await이 표준화 되면서, 로직 구현 시에 대체로 선호하지 않는 방식입니다.
Callback Hell
만약 NodeJS Express에서 한 유저가 팔로윙한 사용자들이 작성한 게시글의 댓글들을 가져오는 라우터를 처리해야 한다고 생각해봅니다.
app.get('/...', function (req, res) {
const result = [];
const id = req.params.id;
FollowingModel.find({ followerId: id }, function(users) {
for(let i=0; i<users.length; i++) {
const user = users[i];
PostModel.find({ writer: user.id }, function(posts) {
for(let j=0; j<posts.length; j++) {
const post = posts[j];
CommentModel.find({ postId: post.id }, function(comments) {
result.push(...comments);
});
}
});
}
});
});
res.send(result);
});릴레이션 고려 안하기도 하고 더러운 DB 접근 로직이지만 구지 DB 접근 로직이 아니더라도 연속으로 비동기 함수를 호출해야 하는 상황이라고 생각하면 됩니다.
어려운 비동기 제어
function (req, res) 함수 내에선 FollowingModel.find 를 호출하고 결과를 가져오기 전에 res.send가 호출됩니다.
그런데도 왜 잘 동작하는 코드일까요? 그 이유는 res.send 가 express 내부에서 비동기 함수이기 때문입니다.
우선 express의 라우팅 시스템을 보면 아래와 같은 순서로 동작합니다.
미들웨어 -> app.get('/..')가 실행되어 request, response 인자 생성
-> function(req, res) 호출 -> function(req, res) 내부에서 response 메서드 호출
-> function(req, res)가 끝난 뒤, response 메서드 로직 동작이 때, result라는 배열 변수는 레퍼런스가 하나로 고정된 상태로, 변수 호출 시와 function(req, res)가 끝나 res.send 로직안에서 같은 레퍼런스를 가지고 있습니다.
그래서 res.send에서 킵한 result와 콜백 지옥에서 사용되는 result 클로저 변수는 같은 것이기 때문에 댓글 정보가 추가됩니다.
이는 Express가 제공해주는 시스템이라 문제가 없이 돌아가지만 보통의 경우 중첩된 콜백안의 결과물들로 예측 가능한 결과를 만들기 어렵습니다.
코드 가시성 하락
코드 자체도 들여 쓰기로 인해 코드 가시성이 떨어져 개발 생산성이 떨어집니다.
그렇다고 callback 함수들을 각각 함수로 정의해 코드 가시성을 증대시킬 수 있겠지만 코드의 리딩이 계속 함수를 건너 다른 함수로 건너는 방식으로 되기 때문에 사람에게 익숙한 명령형 사고방식과 거리가 멀어져 여전히 개발 생산성이 떨어지게 됩니다.
Promise
이렇게 Callback Hell이 부르는 단점을 극복하기 위해 ES6부턴 Promise를 표준으로 채택했습니다.
비동기를 값으로 표현
Promise의 가장 큰 특징은 비동기 상황을 하나의 객체(값)로 표현한 것입니다. 그 상황은 pending, fulfilled, rejected가 있습니다.
- pending
resolve나 reject를 하지 않아 여전히 Promise 생성자 로직이 실행되는 상태 - fulfilled
resolve가 호출되어 값을 넘길 수 있는 상태, then 사용 가능 상태 - rejected
reject가 호출되어 값을 넘길 수 있는 상태, catch 사용 가능 상태
보통 fulfilled 상태에서 전달하는 값은 then 메서드로 받고, rejected 상태에서 전달하는 값은 catch 메서드로 받습니다.
병렬 처리
비동기를 값으로 다루는 것의 좋은 점은 비동기 제어를 쉽게할 수 있다는 것입니다. 병렬 처리도 Promise.all 메서드로 손쉽게 사용할 수 있습니다.
const p1 = new Promise(resolve => {
setTimeout(() => resolve('resolve: p1'), 3000);
})
const p2 = new Promise(resolve => {
setTimeout(() => resolve('resolve: p2'), 5000);
});
console.time('test');
Promise.all([p1, p2]).then(([r1, r2]) => {
console.log(r1, r2);
console.timeEnd('test');
}); // test: 5002.0849609375ms 그래서 무거운 비동기 함수들이 서로 연관이 없을 경우 병렬 처리 후에 then 안에 로직을 구성합니다.
Then Chaining
서로 연관 있는 것들은 로직들은 then의 체이닝으로 로직을 이어갑니다.
then의 첫번째 인자 함수인 fulfilled 함수에서 return 값으로 일반 객체나 Promise를 설정하면 체이닝된 다음 then에서 값을 이어 받습니다.
이 때 Promise를 반환해주면 fulfilled되어 resolve 값을 전달해줍니다.
const p1 = new Promise(resolve => {
setTimeout(() => resolve('resolve: p1'), 3000);
})
const p2 = (param) => new Promise(resolve => {
setTimeout(() => resolve(`${param}, resolve: p2`), 5000);
});
p1.then(r1 => {
console.log('after p1 resolve');
return p2(r1);
}).then(r2 => {
console.log('after p2 resolve');
console.log(r2);
});위 코드는 3초후에 after p1 resolve가 8초후에 after p2 resolve와 resolve: p1, resolve: p2가 콘솔에 출력됩니다.
Reject 처리
reject는 보통 예외, 에러 상황에서 발생합니다.
reject 처리 방법은 then의 두번째 인자 함수(rejected 함수)와 catch로 처리할 수 있습니다. 하지만 보통 catch를 사용하는 것을 권해드립니다. 그 이유는 곧 설명드리겠습니다.
Rejected 함수
먼저 then의 rejected 함수의 예시입니다.
const p1 = new Promise((resolve, reject) => {
setTimeout(() => reject('reject: p1'), 3000);
})
const p2 = (param) => new Promise(resolve => {
setTimeout(() => resolve(`${param}, resolve: p2`), 5000);
});
p1.then(r1 => {
console.log('after p1 resolve');
return p2(r1);
}, e1 => {
console.log('after p1 reject');
console.log(e1);
}).then(r2 => {
console.log('after p2 resolve');
console.log(r2);
}, e2 => {
console.log('after p2 reject');
});콘솔 출력 결과는 아래와 같이 나옵니다.
after p1 reject -> reject: p1 -> after p2 resolve -> undefined보통 reject 상황은 에러, 예외 상황에 발생합니다. 그래서 보통 아래와 같은 출력을 기대할 것입니다.
after p1 reject -> reject: p1
혹은
after p1 reject -> reject: p1 -> after p2 reject -> ...e1 출력인 reject: p1까지 출력 하거나 다음 rejected 함수를 원하는 상황이 많을텐데요. 실제론 reject 함수 -> fulfilled 함수로 chaining 됩니다.
return을 하지 않아도 JS의 함수는 암묵적으로 undefined를 return 하기 때문에 undefined가 인자인 fulfilled 함수가 자동으로 실행되어 예측 불가능한 결과를 만듭니다.
그리고 가장 심각한 단점이 있습니다.
임의의 then fulfilled 함수내의 에러를 해당 then rejected 함수에서 핸들링할 수 없다는 것입니다.
const p1 = new Promise((resolve, reject) => {
setTimeout(() => resolve('reject: p1'), 3000);
})
const p2 = param => new Promise(resolve => {
setTimeout(() => resolve(`${param}, resolve: p2`), 5000);
});
p1.then(r1 => {
console.log('after p1 resolve');
throw new Error('error');
return p2(r1);
}, e1 => {
console.log('after p1 reject');
console.log(e1);
}).then(r2 => {
console.log('after p2 resolve');
console.log(r2);
}, e2 => {
console.log('after p2 reject');
console.log(e2);
});
// after p1 resolve -> after p2 reject -> error여기서 throw new Error('error'); 를 두번째 then의 fulfilled 함수에 이동시켜봅니다.
then(r2 => {
console.log('after p2 resolve');
throw new Error('error');
console.log(r2);
})이렇게 되면 다음 then의 rejected 함수가 없기 때문에 error가 핸들링되지 않습니다.
catch 메서드
const p1 = new Promise((resolve, reject) => {
setTimeout(() => reject('reject: p1'), 3000);
})
const p2 = new Promise(resolve => {
setTimeout(() => resolve("resolve: p2"), 5000);
});
p1.then(r1 => {
console.log('after p1 resolve');
return p2(r1);
})
.then(r2 => {
console.log('after p2 resolve');
console.log(r2);
})
.catch(e => {
console.log('after reject');
console.log(e);
})콘솔 출력 결과
after reject -> reject p1앞에서 rejected 함수말고 catch를 사용하라는 이유는 다음과 같습니다.
- 예외 처리 같은 reject 로직을 뒤에서 작성할 수 있습니다.
- 그래서 중간에 섞인 rejected 함수 사용 로직보다 역할이 명확하게 보입니다.
- reject 상황을를 뒤에 배치하여 then chaining으로 이어서 로직을 작성할 수 있습니다.
- 무엇보다 then의 fulfilled 로직에서 발생하는 에러를 잡아줄 수 있습니다.
4번 장점에 대한 예시는 다음과 같습니다.
const p1 = new Promise((resolve, reject) => {
setTimeout(() => resolve('resolve: p1'), 3000);
})
const p2 = new Promise(resolve => {
setTimeout(() => resolve("resolve: p2"), 5000);
});
p1.then(r1 => {
console.log('after p1 resolve');
return p2;
})
.then(r2 => {
console.log('after p2 resolve');
throw new Error('error');
console.log(r2);
})
.catch(e => {
console.log('after reject');
console.log(e, 'r2 fixed');
return e;
})
.then(e => {
console.log(e, 'r1 fixed');
});콘솔 출력 결과
after p1 resolve -> after p2 resolve ->after reject
-> error, r2 fixed -> error r1 fixed코드로 보는 Promise
표준 Promise의 구현과 다를 수 있겠지만 최소한의 기능을 탑재한 Promise 코드입니다.
class Promise {
constructor(fn) {
const resolve = (...args) => {
setTimeout(() => {
if(typeof this.onDone === 'function') {
this.onDone(...args);
}
if(typeof this.onComplete === 'function') {
this.onComplete();
}
},0)
}
const reject = (...args) => {
setTimeout(() => {
if(typeof this.onError === 'function') {
this.onError(...args);
}
if(typeof this.onComplete === 'function') {
this.onComplete();
}
},0)
}
fn(resolve, reject);
}
then(onDone, onError) {
this.onDone = onDone;
this.onError = onError;
return this;
}
catch(onError) {
this.onError = onError;
return this;
}
finally(onComplete) {
this.onComplete = onComplete;
return this;
}
}이 코드로 new Promise 생성자를 사용해 보통의 비동기 처리를 할 수 있습니다.
const resolve = (...args) =>{...}
const reject = (...args) => {...}resolve와 reject는 pending 상태를 끝낼 때 호출되는데, 들어가는 매개변수를 예측할 수 없기 때문에 rest spread를 사용한 클로저 함수로 정의를 해둡니다.
이 함수들은 클로저로써 Promise 생성자 인자로 넘겨주는 함수에 전달해주기만 합니다.
그런데 resolve, reject 내에서 setTimeout을 왜 사용했을까요?
왜냐하면 setTimeout을 사용하지 않으면, 생성자 함수 내에서 비동기 호출 없이 동기적으로 사용되면 then의 사용이 안되기 때문입니다. 그래서 resolve, reject 내부 로직을 처음부터 비동기로 만들었습니다.
그래서 onDone이나 onError를 실행하는 로직은Event Queue에 들어가서 callStack이 비워질때까지 실행되지 않습니다. 원래는 MicroTask Queue에 들어가는게 맞지만, Promise를 구현한다는 것은 ES5이하라는 상황을 가정하는데 MicroTask Queue는 ES5에는 존재하지 않아 setTimeout을 사용했습니다.
그리고 아쉬운 것은 then과 catch 메서드 경우, 그저 인스턴스의 속성을 할당해줄 뿐이지 아무것도 하지 않습니다. 그래서 Then Chaining이 적용되지 않습니다. 이 문제는 추후에 고쳐볼 생각입니다.
Async Await
async await 구문은 ES8부터 적용된 비동기 처리 방식입니다. 그래서 Front에서 사용하는 경우 호환성을 위해 babel의 사용이 필요합니다.
Promise는 비동기 처리하기 좋은 방식이지만 then chaining이 무수히 많아지면 가독성이 떨어지는 단점이 존재합니다.
그래서 이런 단점을 보완하기도 하며, 좀 더 비동기 처리를 명령형 프로그래밍에 익숙하게 만들어 코드를 보기 좋게 만들 수 있습니다.
Async function
Async Await 구문을 사용하기 첫 시작은 async function을 선언하는 것입니다. await 구문은 async function내에서만 사용할 수 있습니다.
우선 async function은 반환 값이 Promise라는 것을 알아야 합니다.
async function func(a) {
return a;
}
console.log(func(2)); // 2를 resolve할 PromiseAsync Await 사용 예제
app.get('/...', function (req, res) {
const result = [];
const id = req.params.id;
FollowingModel.find({ followerId: id }, function(users) {
for(let i=0; i<users.length; i++) {
const user = users[i];
PostModel.find({ writer: user.id }, function(posts) {
for(let j=0; j<posts.length; j++) {
const post = posts[j];
CommentModel.find({ postId: post.id }, function(comments) {
result.push(...comments);
});
}
});
}
});
res.send(result);
});위에서 Callback을 설명하면서 작성한 Express 예시를 async await을 사용할 수 있게 변환하겠습니다. 여기서 Model들의 메서드는 callback만을 지원한다고 전제하겠습니다.
우선 기존 모델들을 Promise로 사용할 수 있게 만드는 Model 객체를 만들겠습니다.
const Model = {};그리고 첫번째 인자를 기존 모델, 두번째 인자를 where 객체로 사용하고 Promise를 반환하는 find 메서드를 만들 것입니다.
Model.find = (model, where) => new Promise((resolve, reject) => {
if(!model || !model.find) return reject('find 메서드가 없습니다.');
model.find(where, (err, result) => { err ? reject(err) : resolve(result); });
});위에서 정의한 Model의 메서드를 사용해 async await을 사용해보겠습니다.
app.get('/...', async function (req, res) {
const result = [];
const id = req.params.id;
try {
const users= await Model.find(FollowingModel, { followerId: id });
const posts = (await Promise.all(
Array.from(users)
.map(user => user.id)
.map(userId => Model.find(PostModel, {writer: userId}))
)).flat();
const comments = (await Promise.all(
Array.from(posts)
.map(post => post.id)
.map(postId => Model.find(CommentModel, { postId }))
)).flat();
res.send(comments);
} catch (e) {
res.status(500).send(e);
}
});심플함을 위해서 각 db 처리 로직마다의 에러 처리는 하지 않았습니다.
성능을 증가시키고자 비동기 처리 로직들을 한번에 병렬처리 하고 싶었으나 함수형 라이브러리를 사용하지 않으면 코드가 더 복잡해질 것 같아 각 Model을 접근할 때마다 병렬처리를 했습니다.
딱보아도 이전 callback 로직과 비교해 코드 리딩이 깔끔해진 것을 알 수 있습니다.
Async 대신 Promise 사용 예제
만약 async await을 사용하지 않으면 아래 같은 코드가 될 것입니다.
app.get('/...', function (req, res) {
const result = [];
const id = req.params.id;
Model.find(FollowingModel, { followerId: id })
.then(users => {
const postPromises =
Array.from(users)
.map(user => user.id)
.map(userId => Model.find(PostModel, {writer: userId}));
return Promise.all(postPromises);
})
.then(posts => {
const commentPromises =
Array.from(posts)
.flat()
.map(post => post.id)
.map(postId => Model.find(CommentModel, { postId }));
return Promise.all(commentPromises);
})
.then(comments => Array.from(comments).flat())
.then(res.send)
.catch(res.status(500).send);async await을 사용하는 것보다 then을 사용하면서 depth가 늘어나고 좀 더 신경써주어야할 것들 때문에 몇가지 코드가 늘어났습니다.
하지만 저는 함수형 프로그래밍을 좋아하기 때문에 Promise를 모나드로써, then chaining하는 방식을 사용합니다. 그래서 이런 형태의 코드에서 함수들을 모듈화 시키고 Model의 Service 로직도 단순화 시켜 조립하는 형태를 더 선호합니다.
코드로 보는 Async Await
키워드는 코드로 추가할 영역이 아니기 때문에 Async function은 함수를 감싸는 wrapper 함수로 만들어야 합니다.
Async function은 우선 generator function으로 이루어져있습니다. async wrapper의 인자는 generator function이 들어갑니다.
function _async(generator) {
return function(...args) {
const iter = generator.apply(this, args);
return new Promise(function(resolve, reject) {
function step(key, arg) { // key: 'next' | 'throw'
try {
const next = iter[key](arg);
const value = next.value;
if (next.done) resolve(value);
else {
return Promise.resolve(value)
.then(resolvedValue => step("next", resolvedValue))
.catch(err => step("throw", err))
}
} catch (err) {
reject(err);
return;
}
}
step("next");
});
};
}async화 시킨 function을 호출하면 기존 async function과 마찬가지로 Promise를 반환합니다.
const iter = generator.apply(this, args);그전에 generator function을 iterator로 만든 변수를 클로저 변수로 할당합니다. apply를 사용한 이유는 _async를 호출할 때와 _async로 감쌌던 함수를 실행할 때의 this가 다르기 때문에 바인딩 시키는 것입니다.
이제 Promise의 생성자 함수 내부를 볼까요? 결과적으로 말하면, Promise가 resolve하는 것은 generator function 내부가 모두 끝나 next.done을 가질 때입니다. 그전까진 묵묵히 generator function을 돌기만 합니다.
step("next");우선 첫 시작은 step 함수를 실행시키면서 iterator 로직을 실행시킵니다.
const next = iter[key](arg) // iter.next(); ===> yield에 걸리는 Promise를 가진 iterable
const value = next.value; // iterable돌면서 yield를 만나면 yield에 해당되는 문을 가져와 아래 코드처럼 resolve 시킵니다. 만약 yield를 만나지 못하면 next 변수는 undefined를 가진 Iterable이 됩니다.
Promise.resolve(value)
.then(resolvedValue => step("next", resolvedValue))
.catch(err => step("throw", err);그래서 만약 yield로 걸렸던 문이 Promise를 반환했다면 fulfilled 시킨 값을 가진 Promise로 만든 뒤, then chaining으로 iterator에게 인자로 전달해 next 시킵니다.
또한, 로직을 수행하는 중간에 오류나 예외가 생겨, Promise가 중간에 reject를 하면 catch문으로 인자를 받아 generator 내부에서 catch를 수행할 수 있게 만듭니다.
이 과정을 Generator Function이 다 돌때까지 진행되는 것이죠
정리하면,
- generator function을 _async로 wrapping
- wrapping 시킨 함수를 실행하면 generator function으로 iterator로 만들고 Promise 반환
- step("next")로 iterator 시작
- iterator 내부에서 yield를 만나면 yield에 걸린 문을 구현 문의 Promise로 가져와 resolve화
- resolve 시킨 값을 유명 재귀 함수 step에 전달하면서 호출
- 그렇게 되면 전달한 값이 yield에 걸린 문을 대체시키며 iterator를 재개
- iterator가 끝날 때까지 4~6 과정이 반복
그래서 구현한 async await polyfill를 사용하면 아래 코드와 같이 잘 작동합니다.
const after1s = p => new Promise(resolve => setTimeout(() => resolve(p), 1000));
const after2s = p => new Promise(resolve => setTimeout(() => resolve(p), 2000));
const aFunc = _async(function* (a) {
console.log("start");
console.log(yield after2s(a), "after 2 second");
console.log(yield after1s(a), "after 1 second");
console.log("end");
});
aFunc(2);콘솔 출력 결과
start
2, after 2 second (2초 후)
2, after 1 second (3초 후)
end정리
- JS는 비동기 프로그래밍이란 특징이 가장 중요하다고 생각합니다.
- 그래서 JS를 잘 다룰려면 CallStack, EventLoop, EventQueue, API 간의 흐름을 알고 써야 된다고 생각합니다.
- 그리고 그 흐름속에서 비동기성, 논 블로킹, 이벤트 기반 아키텍처 특징을 알아야 하구요.
- Callback, Promise, Async Await의 원리를 알면 비동기를 제어하는데 도움이 되는 것 같습니다. 그 중에서도 비동기를 동기처럼 다루기 위해 재귀함수를 사용하는 전략은 예측 가능한 프로그래밍을 하는데 많은 영감을 주는 것 같습니다.
- Promise든, Async Await이든 자신만의 클린 코드 작성법을 터득하는게 좋다고 생각합니다.. 개인적으로 함수형 프로그래밍으로 Promise를 Chaining한 것들을 await 해서 모은 것들로 메인 로직을 구성하는 것이 맞는 것 같습니다.
- 그래도 콜백 함수는 아닌 것 같습니다.

14개의 댓글

유익한 글 감사합니다 ;D
Diagram 그리는 도구를 추천드리고 싶어요!
물론, 취향에 따라 마음에 들지 않을수도 있겠지만..
혹시 사용해보신적 없으시면 다음번에 한번 사용해보시길 추천드립니다!
위 도구를 사용하면 더욱 프로답게 (?) Diagram을 만들 수 있어요.


재밌게 잘 읽었습니다 ㅎㅎ 자바스크립트에서 비동기를 사용해야 하는 당위성을 너무 잘 풀어써 주셔서 막연하게 그런가보다 하던 부분을 채워넣었네요 :) 주로 프론트엔드 개발을 하다 보니 HTTP method의 반환을 기다리거나 컴포넌트의 라이프사이클과 연관되어 사용하다 보니 기술적 한계 때문에 사용하는게 아닐까 하고 있었는데 좀 더 언어적인 단계부터의 고민이 담긴 구문이었군요 ㅎㅎ



좋은 글 잘보고 갑니다!