[신경망을 수식으로 표현]
신경망이 어떻게 학습을 알아보기 위해 우선 신경망을 수식으로 표현해보자.
n개의 입력 데이터를 받는 단층 신경망이 d개의 뉴런을 가지고 있고 p개의 출력을 내보낸다면 다음과 같은 행렬들의 식으로 나타낼 수 있다.
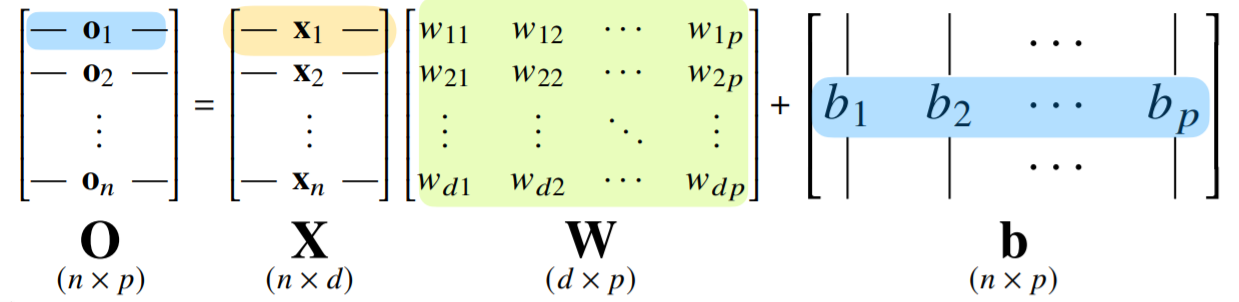
O는 출력, X는 입력 데이터, W는 가중치, b는 편향의 행렬이다.
이때 우항의 결과로 나오는 행렬의 성분 하나하나가 우리가 신경망 그림에서 자주 보는 화살표 하나하나라 볼 수 있다.
또한 다음 층의 뉴런(결과?) 하나하나는 O행렬의 행 성분의 합으로 정해진다.
이 출력에 e^On/Σe^O인 소프트맥스 함수를 적용해주면 분류 문제에서 자주 사용하는 각 출력이 확률의 형태로 되는 것이다.
(모델을 사용할 때에는 확률이 가장 높은 것 하나만 1로 출력해주는 원 핫 인코딩을 사용하고 학습 시에만 확률 값을 사용한다.)
활성화 함수
입력에 편향과 가중치를 곱해준 후 활성화 함수를 거치게 된다.
활성화 함수는 일종의 비선형 함수로 되어있는데 활성화 함수가 없다면 인공 신경망은 그냥 선형결합 모델이 된다.(복잡한 비선형 문제를 풀 수 없다.)
대표적인 활성화 함수에는 전통의 sigmoid, tanh(하이퍼볼릭 탄젠트)와 최근에 자주 사용되는 ReLU가 있다.
sigmoid와 tanh는 딱봐도 비선형 모양이지만 ReLU는 0보다 작을 때에는 0을, 0보다 클 때에는 입력값을 그대로 출력하는 언뜻 보기엔 선형같은 모양이다.
하지만 사람들이 실제 생물의 방식과 비슷하다고 생각한 앞의 두 개는 그래디언트 소실 문제로 깊은 신경망 학습에 적합하지 않다고 밝혀졌고 지금은 이 문제를 해결한 ReLU를 거의 쓴다.
순전파와 역전파
값이 입력층에서 출력층 방향으로 기울기와 편향 그리고 활성화함수를 거치며 나아가는 것을 순전파라고 한다.
역전파는 순전파로 얻어진 결과와 예측하고자 하는 원래의 값과 손실함수를 이용하여 파라미터들로 미분하여 출력층에서부터 입력층 방향으로 경사하강법 등으로 파라미터를 수정해나가는 과정이다.
어느 층의 파라미터로 미분한 값을 구하기 위해선 뒷층의 미분 결과를 알아야 하기 때문에(합성함수의 미분) 뒤에서부터 앞 방향 순으로 미분하는 것이다.

자료 출처:
Mathematics for Machine Learning
[AI Tech Pre-course] 인공지능(AI) 기초 다지기
