1. 성능평가
- Loss : 모델 학습시 학습데이터(train data) 를 바탕으로 계산되어, 모델의 파라미터 업데이트에 활용되는 함수
- Metric : 모델 학습 종료 후 테스트데이터(test data) 를 바탕으로 계산되어, 학습된 모델의 성능을 평가하는데 활용되는 함수
https://kharshit.github.io/blog/2018/12/07/loss-vs-accuracy
https://scikit-learn.org/stable/modules/model_evaluation.html#multilabel-ranking-metrics
Task에 따라 Loss 또는 Metric을 활용할지 판단이 필요하다
2. Confusion Matrix
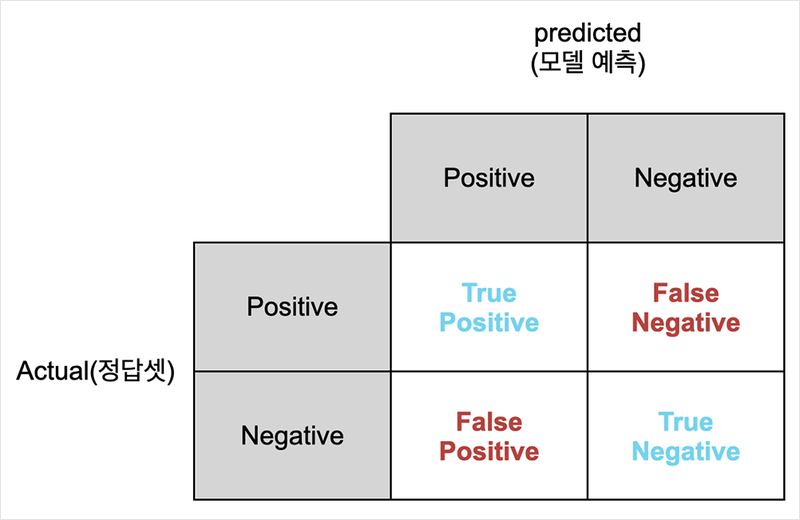
- True Positive (TP) - 모델이 양성(Positive)을 양성으로 맞혔을 때
- True Negative (TN) - 모델이 음성(Negative)을 음성으로 맞혔을 때
- False Positive (FP) - 모델이 음성(Negative)을 양성(Positive)으로 잘못 예측했을 때
- False Negative (FN) - 모델이 양성(Positive)을 음성(Negative)으로 잘못 예측했을 때

- Accuracy 정확도 = (TP+TN) / (TP+TN+FN+FP)
- Precision 정밀도 = (TP) / (TP+FP)
- 모델이 양성으로 잘못 규정한 것이 적을수록 정밀도는 올라감
- Recall 재현율 = (TP) / (TP+FN)
- 모델이 실제 양성을 분류해 내지 못한 경우가 적을 수록 재현율은 올라감
- F1-score : F score에서 일때를 말함
- Recall을 중요시하고 싶다면 beta 값을 1보다 크게 하는 것이 좋음
- Recall을 중요시하고 싶다면 beta 값을 1보다 크게 하는 것이 좋음
3. Threshold의 변화에 따른 모델 성능
1) PR 커브
2) ROC(Receiver Operating Characteristic Curve)
- Confusion Matrix 수치를 활용해, 분류기의 분류 능력을 그래프로 표현하는 방법
- Threshold 값의 변화에 따라 Confusion Matrix에 생기는 변화로 인해 그려지는 것
- TP Rate(Sensitivity) =
- FP Rate(1-Sensitivity) =
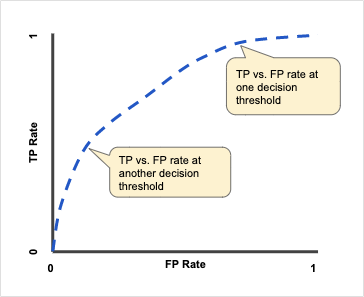
- ROC AUC(Area Under the ROC Curve)
- 영역의 넓이가 넓은 모델일수록, 상대적으로 좋은 성능을 보여줌
4. 다양한 머신러닝 모델 평가척도
1) 회귀 모델
- MSE, RMSE
- 특징 : 오차의 제곱에 비례하여 수치가 늘어나므로, 특이값에 민감하게 반응
- 단점Outlier가 많은 데이터에 대해 모델이 강건(robust)하지 못함
- MAE, MAPE
- 오차의 절대값에 비례해서 수치가 늘어나는데 상대적으로 특이값에 민감하지 않음
- Outlier가 많은 데이터에 대해 강건함
https://partrita.github.io/posts/regression-error/
2) 랭킹 모델
https://lamttic.github.io/2020/03/20/01.html
3) 이미지 생성 모델
- MSE, PSNR
- 특징 : 픽셀 단위로 비교해서 거리를 측정
- 단점 : 이미지가 약간 평행이동해 있어도 두 차이를 크게 측정하는 단점
- SSIM은 이와 달리 픽셀 단위 비교보다는 이미지 내의 구조적 차이에 집중하는 방식
