1. 데이터 마트
- 데이터 웨어하우스
- 많은 양의 데이터를 오랫동안 보관하는 것에 최적화되어있다.
- 업무적으로 중요한 데이터가 저장되고, 전사적인 관점에서 통합하여 관리
- 데이터 마트
- DW와 사용자 사이의 중간층
- 대부분의 데이터는 DW로부터 복제되지만, 자체적으로 수직될수 있음
- 관계형 데이터 베이스나 다차원 데이터 베이스를 이용하여 구축
- 필요한 데이터를 추출하여 데이터 마트를 따로 구축
- 데이터 레이크
- 미가공된 원시 데이터를 그대로 저장한다
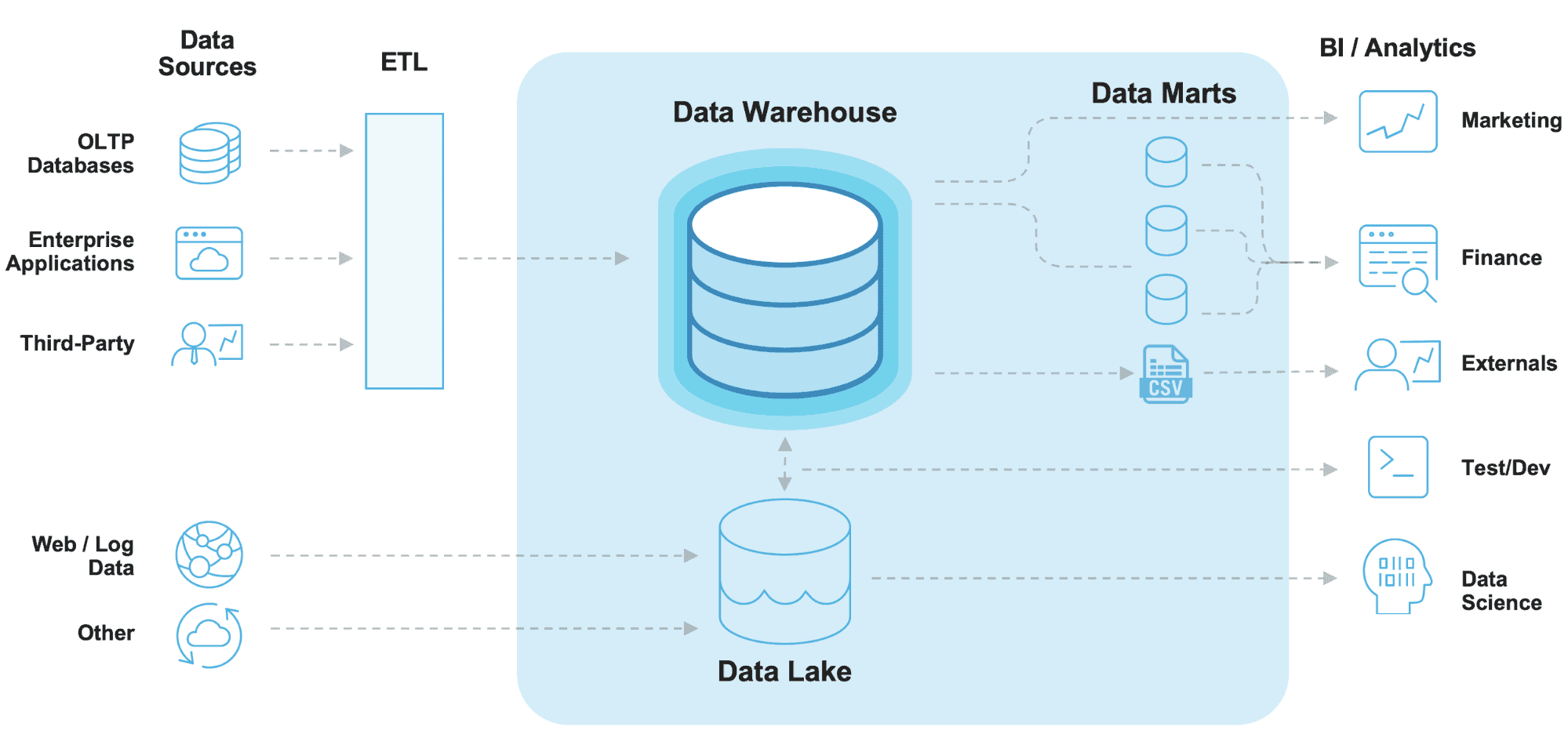
- 미가공된 원시 데이터를 그대로 저장한다
1) 데이터 전처리
-
결측값, 이상값 제거
-
변수선택, 차원축소, 파생변수 생성등
-
reshape패키지 :melt(),cast()ordcast()melt(): 원데이터 형태로 만드는 함수cast(): 요약 형태로 만드는 함수
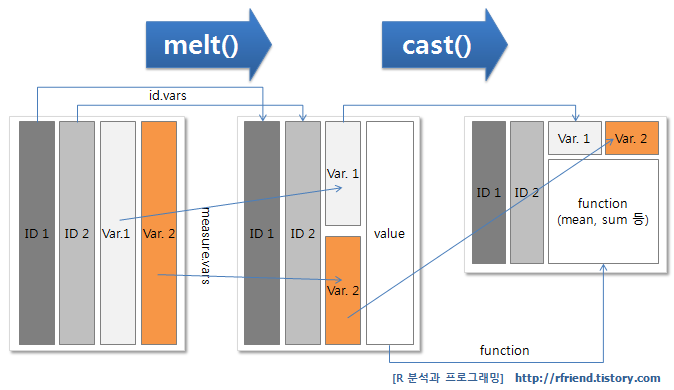
-
sqldf패키지 : R에서 SQL 명령어 사용 가능하게 해주는 패키지 -
plyr패키지 : Data 분할, 재결합 처리하는 패키지ddply(): 데이터 프레임 내에 그룹 별로 특정한 함수를 적용한 데이터 분석을 하는 함수
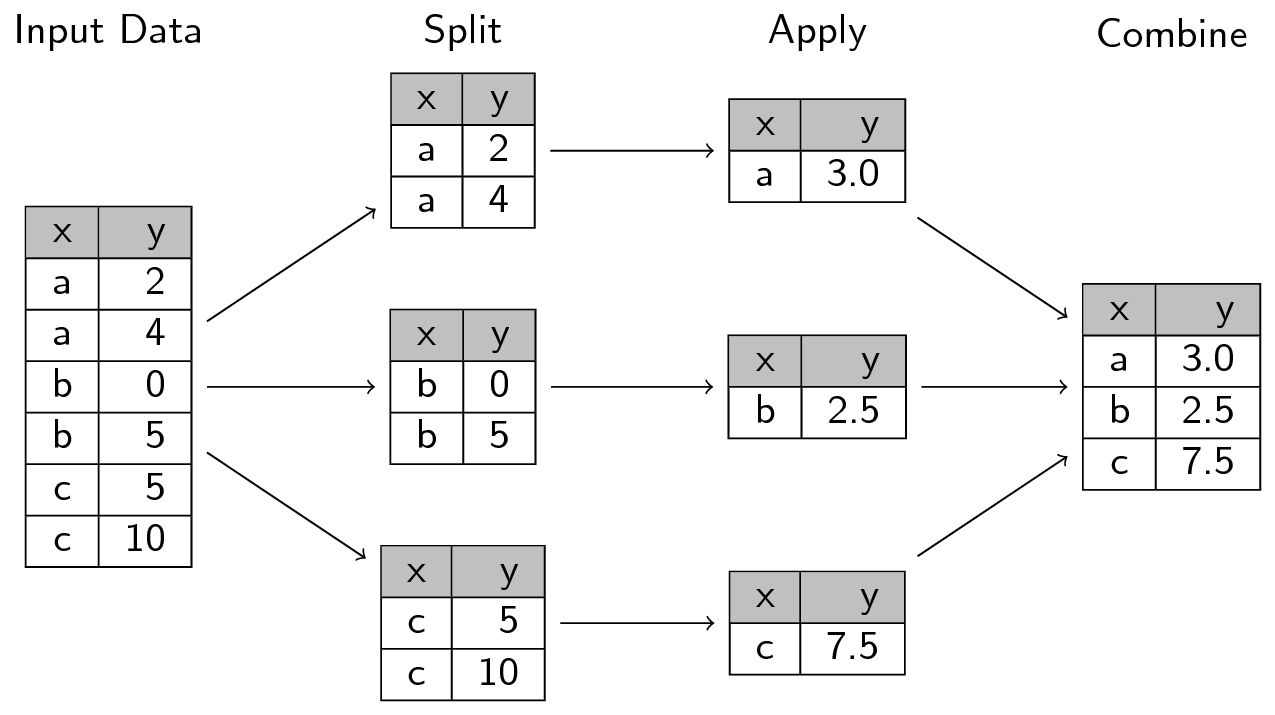
-
data.table패키지 :data.frame과 달리 인덱스를 지정하여 속도가 월등히 빠르다
2) EDA
- Exploration Data Analytics 탐색적 자료 분석
- 통계값과 시각화
(1) 결측값
- 처리 방법 : 단순 대치법, 평균 대치법, 단순확률 대치법, 다중 대치법
- 단순 대치법 : 결측값 삭제
- 평균 대치법
- 비조건부 : 관측 데이터의 평균
- 조건부 : 회귀분석을 활용
- 단순확률 대치법 : 평균 대치법의 단점(과소 추정)을 보완
- K-NN(Nearest Neighbor)
- 다중 대치법 : 단순 대치법을 1번이 아닌 m번 대치를 통해 m개의 가상적 완전 자료를 만듦
(2) 이상값
- 극단적으로 크고 작은 값
- ESD(Extreme Studentized Deviation)
- 3-sigma 방법
- 평균으로 부터 표준편차의 3배가 넘는 범위의 데이터
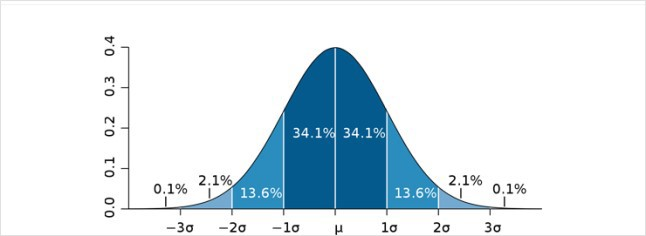
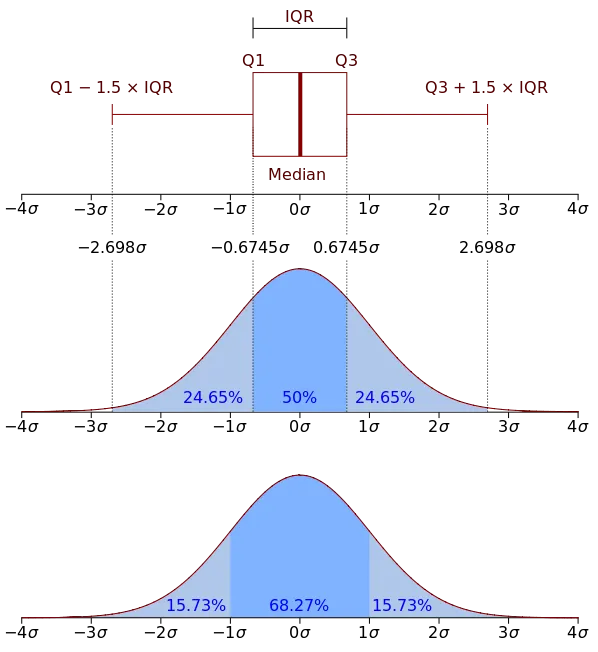
- 사분위수
- Q1 - 1.5 IQR < < Q3 + 1.5 IQR (IQR = Q3 - Q1)을 벗어난 값
2. 통계 분석
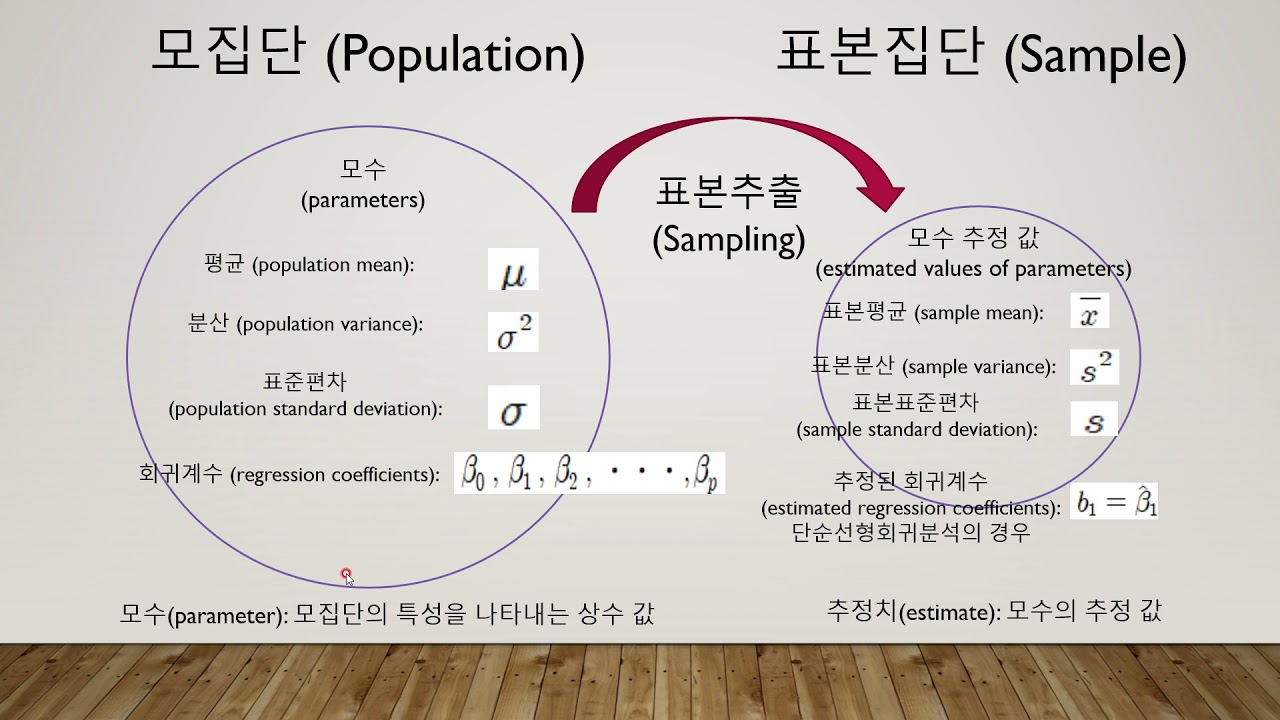
- 통계란, 특정 집단을 대상으로 수행한 조사/실험을 통해 나온 요약된 형태의 표현
⇒ 효과적인 의사전달 - 전수조사 : 인구주택총조사 등과 같이 대상집단 모두를 조사
- 비용과 시간이 많이 소요
- 표본조사 : 모집단에서 샘풀을 추출하여 진행하는 조사
- 모집단(Population) : 대상 집단 전체
- 모수(Parameter) : 모집단에 대한 정보(, )
- 원소(Element) : 모집단을 구성하는 개체
- 표본집단(Sample) : 모집단에서 추출한 표본
1) 표본 추출 방법
-
단순 랜덤 추출(Simple Random Sampling) : 임의의 n개 추출하는 방법
-
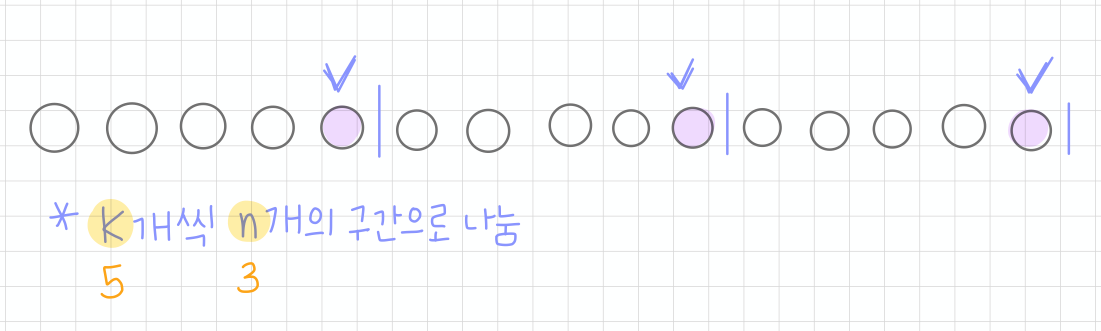
계통추출법(Systematic Sampling) : K개씩 n개의 구간으로 나누는 방법
-
집락추출법(Cluster Random Sampling)
- 군집내 이질적/군집외 동질적
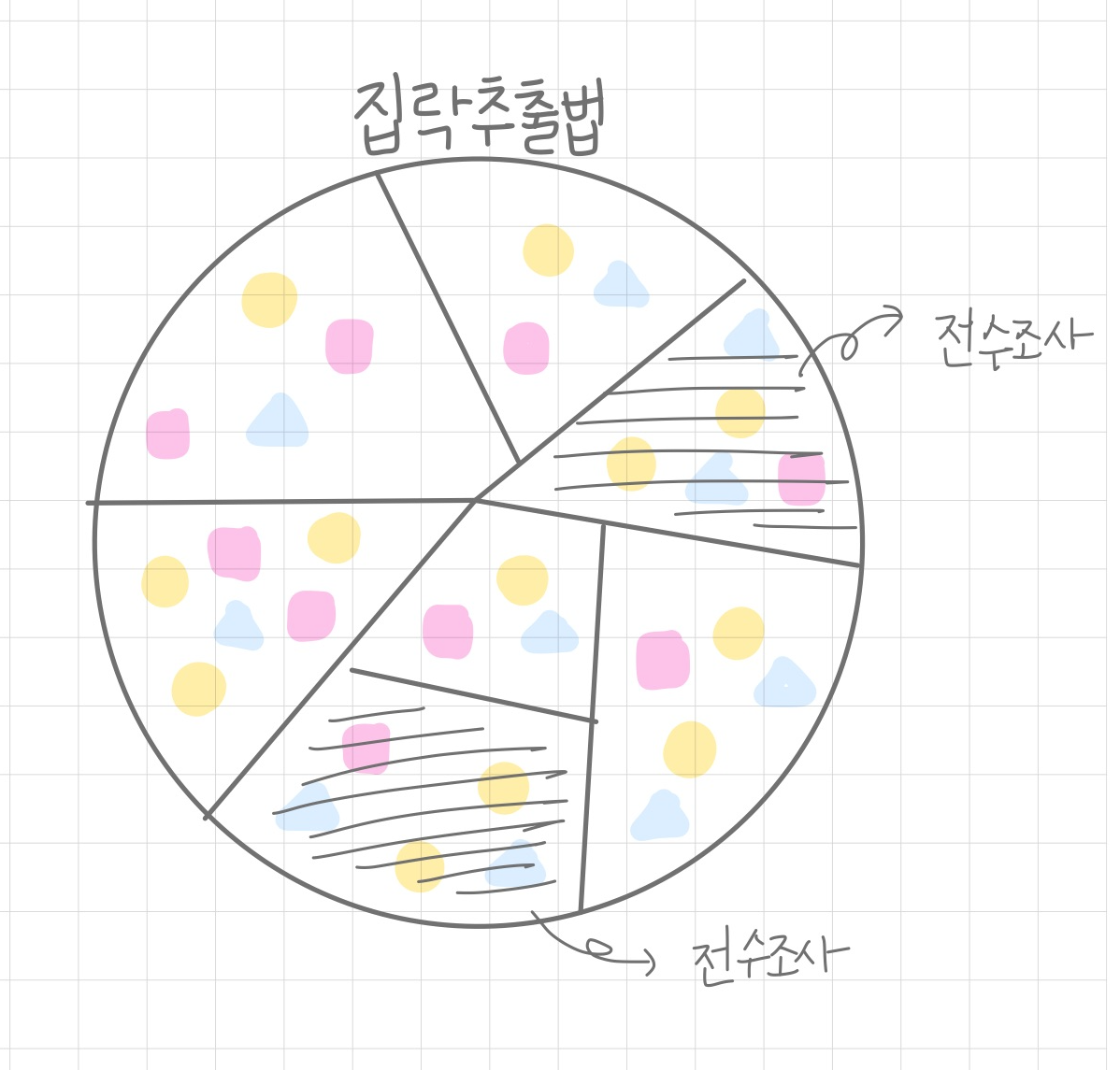
- 군집내 이질적/군집외 동질적
-
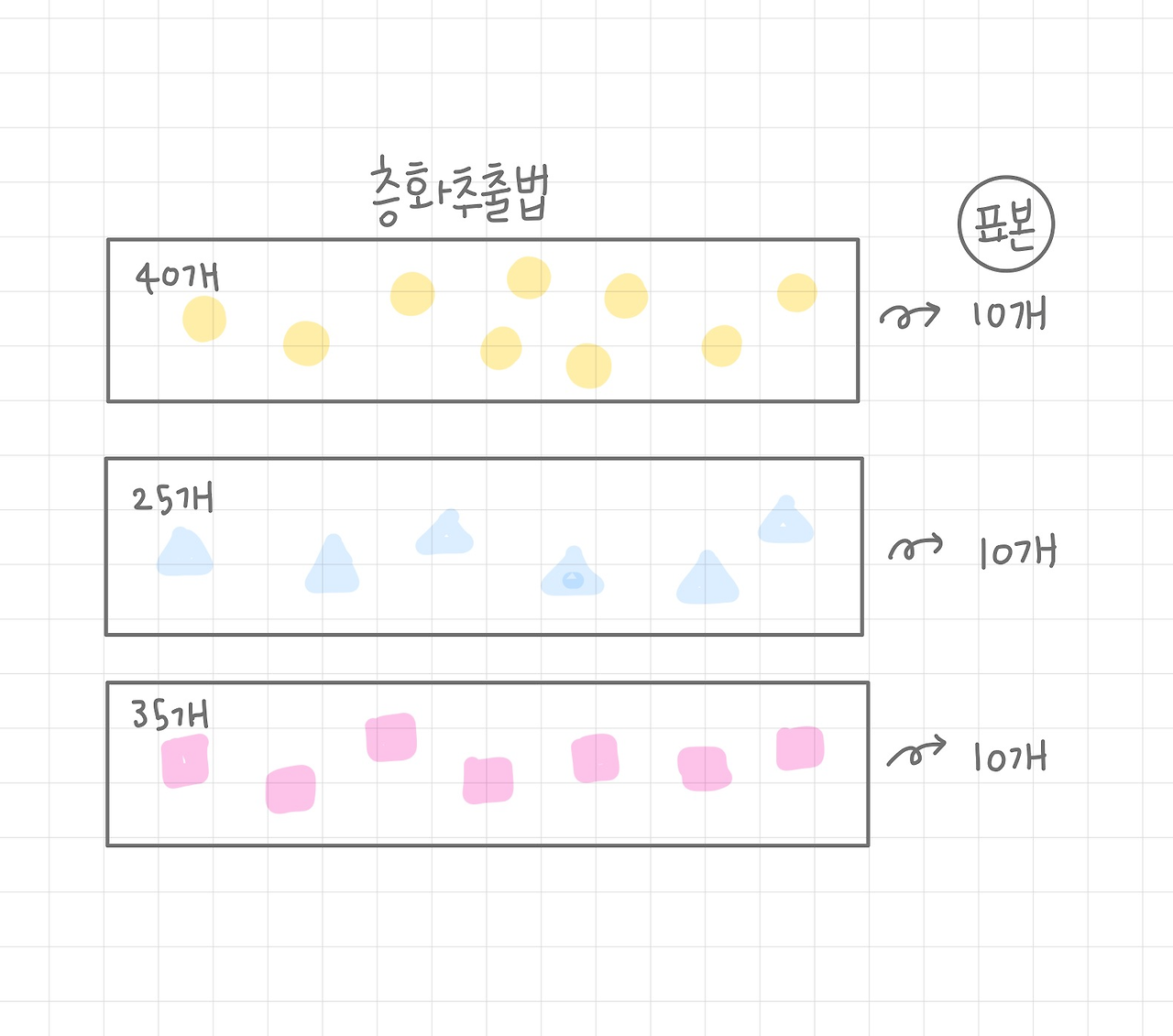
층화추출법
- 군집내 동질적/군집외 이질적
- 비례층화추출법 : 소집단의 크기에 비례하도록 표본의 수를 할당하여 추출
- 불비례층화추출법 : 비례하지 않음(아래 사진)
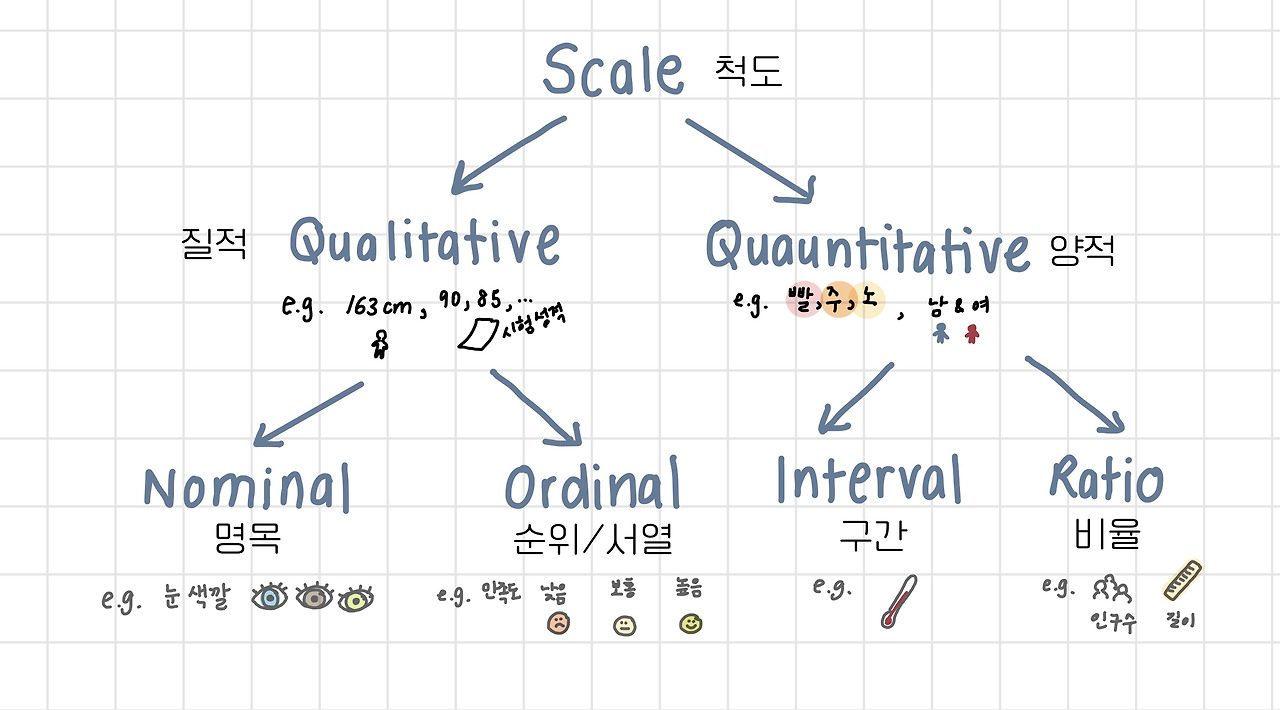
2) 척도
- 명목척도 : 대상을 속성에 따라 구분
- 순서척도 : 순위관계 有
- 등간(구간)척도 : 사칙연산 불가능
- 비율척도 : 절대적 기준인 0이 존재, 사칙연산 가능
3) 확률
-
확률 :
-
확률변수 : 인 함수
-
조건부 확률 :
-
독립사건 :
-
배반사건 :
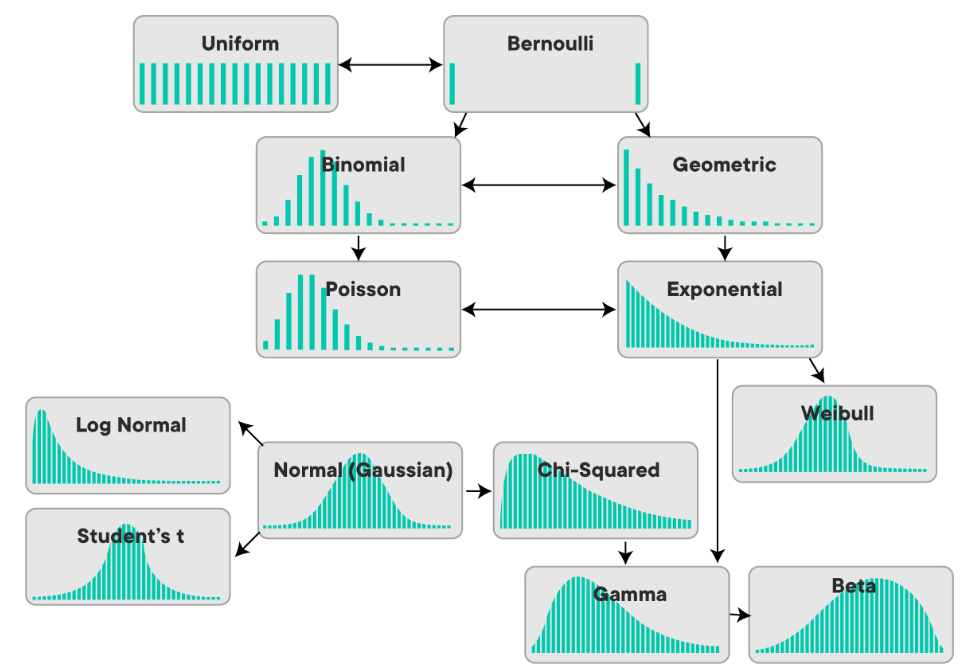
4) 확률분포(Probability Distribution)
(1) 이산형 확률 변수
- 베르누이 확률분포 (Bernoulli distribution)
- 이항분포 (Binomial distribution)
- 기하분포 (Geometric distribution)
- 다항분포 (Multinomial Distribution)
- 포아송분포 (Poisson distribution)
(2) 연속형 확률 변수
- 균일분포 (Uniform distribution)
- 정규분포 (Normal distribution)
- 지수분포 (Exponential distribution)
- t-분포 (T distribution)
- 두 집단의 평균이 동일한지 여부
- 카이제곱() 분포 (Chi-square distribution)
- 두 집단 간의 동질성 검정에 활용
- F-분포(F distribution)
- 두 집단 간 분산의 동일성 검정
- 두 집단 간 분산의 동일성 검정
5) 추정과 가설검정
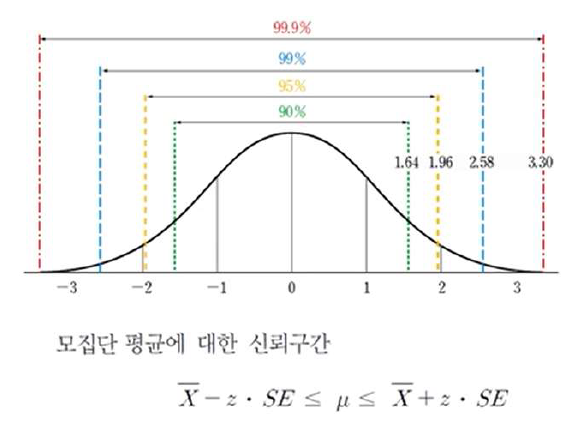
(1) 추정
- 점추정
- 모수를 특정한 하나의 수치로 표현하는 것
- 구간추정
- 모수가 특정한 구간에 있을 것이라고 표현하는 것
- 신뢰구간
(2) 가설검정
-
귀무가설(Null Hypothesis, )
- 일반적으로 연구에서 검정하는 가설
-
대립가설(Alternative Hypothesis, )
- 연구자가 연구를 통해 입증되기를 기대하는 예상이나 주장하는 내용
-
검정통계량(Test Statistic)
- 관찰된 표본으로부터 구하는 통계량
- 채택여부를 판단
-
유의수준(Significance level)
- 귀무가설을 기각하게 되는 확률의 크기
귀무가설이 옳은데도 이를 기각하는 확률의 크기
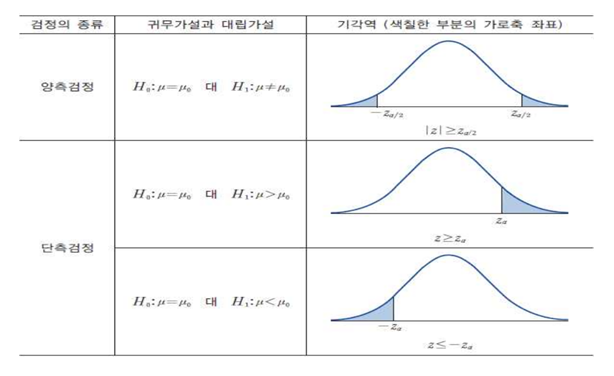
- 귀무가설을 기각하게 되는 확률의 크기
-
유의확률(Significance Probability, p-value)
- 귀무가설이 맞다고 가정할 대 얻을 수 있는 결과보다 실제값이 더 극단에 위치할 확률
-
기각역(Critical region)
- 귀무가설을 기각하는 구간
- 귀무가설이 옳다는 전제 하에서 구한 검정통계량의 분포에서 확률이 유의수준 인 부분
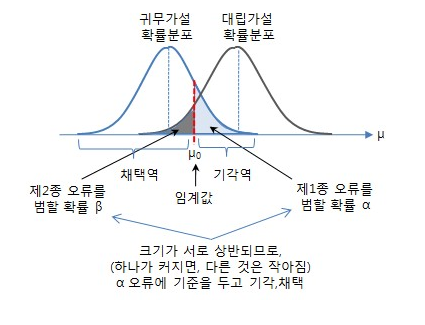
1종오류,2종오류
6) 기술통계
- 평균
- 중앙값
- 최빈값
- 분산
- 표준편차
- 표본평균의 표본오차
- 왜도
- 첨도
- 공분산
- 상관 정도
-상관계수
- 상관 정도
3. 회귀분석
출처
- Beyond “Modern” Data Architecture
- R 데이터 재구조화 reshape 패키지 melt(), cast() 함수, reshape2의 acast(), dcast() 함수, tidyverse의 spread() 함수
- Splitting and Combining Data Frames with plyr
- [정보TALK] 이상치 판단 기준이 실무에서도 같을까요?
- [통계모형] - 1. 모집단과 표본집단
- 통계 표본추출방법 (단순랜덤, 계통추출법, 집락추출법, 층화추출법 차이점)
- [통계] 척도 (Scale)의 4가지 종류
- [확률/통계] 확률분포 총 정리 (이산확률분포, 연속확률분포)
- Statistics : 10-3 : 통계적 추정 : 가설검증 (검정통계량, 기각역의 결정, 유의확률)
