
컴퓨터 비전
- 컴퓨터 비전(Computer Vision)은 디지털 이미지(또는 비디오)를 처리하여 기계가 시각적 세계를 이해할 수 있도록 하는 기술이다.
- 컴퓨터 비전의 하위 분야는 여러개가 있다. 예를 들어
- 객체 인식(Object recognition)
- 객체 탐지(Object detection)
- 비디오 추적(segmentation)
- 동작 인식(action recognition)
- 비디오 추적(video tracking)


참고 논문 : A comprehensive study of deep video action recognition
이미지 전처리(Image Preprocessing)
- 이미지 전처리는 raw 이미지를 딥러닝에 적합한 형식으로 변화하는 과정이다.
- 일반적인 전처리 기법에는 크기 조정(resizing), 정규화(normalization), 데이터 증강(data augmentation)이 포함된다.
- 정규화는 보통 픽셀 값을 표준 범위(예 0~1, -1~1)로 스케일링하는 과정을 의미한다.

AlexNet
- ImageNet 대회에서 우승한 최초의 CNN으로 컴퓨터 비전 분야에서 딥러닝의 돌파구를 마련했다.
- 5개의 합성곱(convolutional) 층과 3개의 완전 연결(fully connected)층으로 구성되었다.
- ReLU 활성화 함수와 드롭아웃(dropout)을 사용하여 정규화를 수행했다.
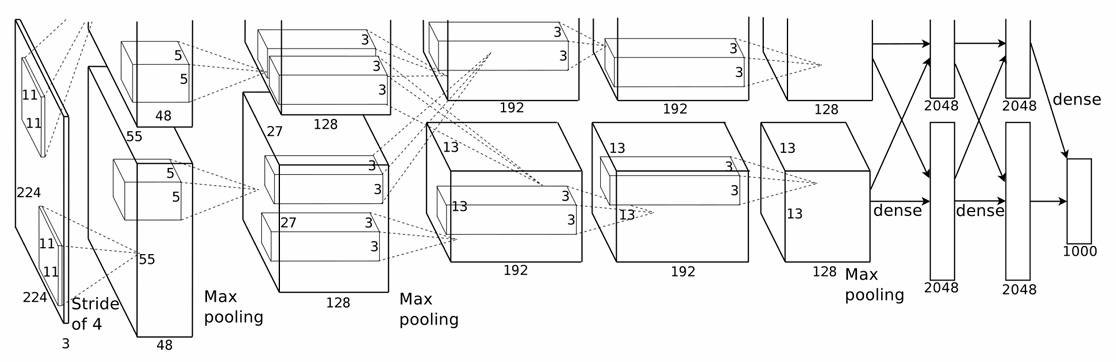
참고 논문 : Imagenet classification with deep convolutional neural networks
VGG-Net
- 네트워크 깊이가 성능 향상에 있어 중요하다는 것을 시사함.
- 네트워크 전체에 걸쳐 작은 3x3 합성곱 필터를 일관되게 사용했다.
- 더 작은 필터를 여러 개 쌓으면 더 큰 필터와 동일한 수용 영역(receptive field)을 더 적은 파라미터로 달성할 수 있음을 보여줬다.
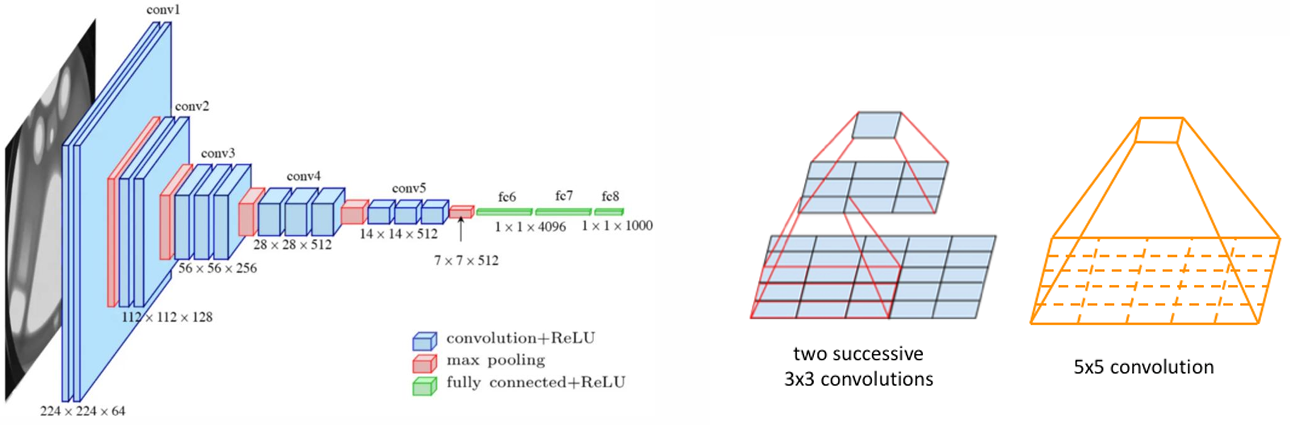
참고 논문 : Very deep convolutional networks for large-scale image recognition
Inception (GoogLeNet)
- 병렬로 여러 크기의 필터를 사용하는 인셉션 모듈(inception modules) 개념을 도입했다.
- 동일한 층(layer)에서 다양한 스케일의 특징을 효율적으로 포착할 수 있도록 했다.
- 이전 모델에 비해 파라미터 수를 크게 줄였다.

참고 논문 : Going deeper with convolutions
ResNet
- 일반적인 합성곱 신경망에 층을 계속 깊게 쌓으면 모델이 오히려 성능이 저하가 된다. 이는 과적합 때문이 아닌 기울기 소실(vanishing gradient) 문제가 발생한다.
- 깊은 네트워크에서 발생하는 기울기 소실(vanishing gradient) 문제를 해결하기 위해 skip connection(잔차 연결, residual connection)을 도입했다.
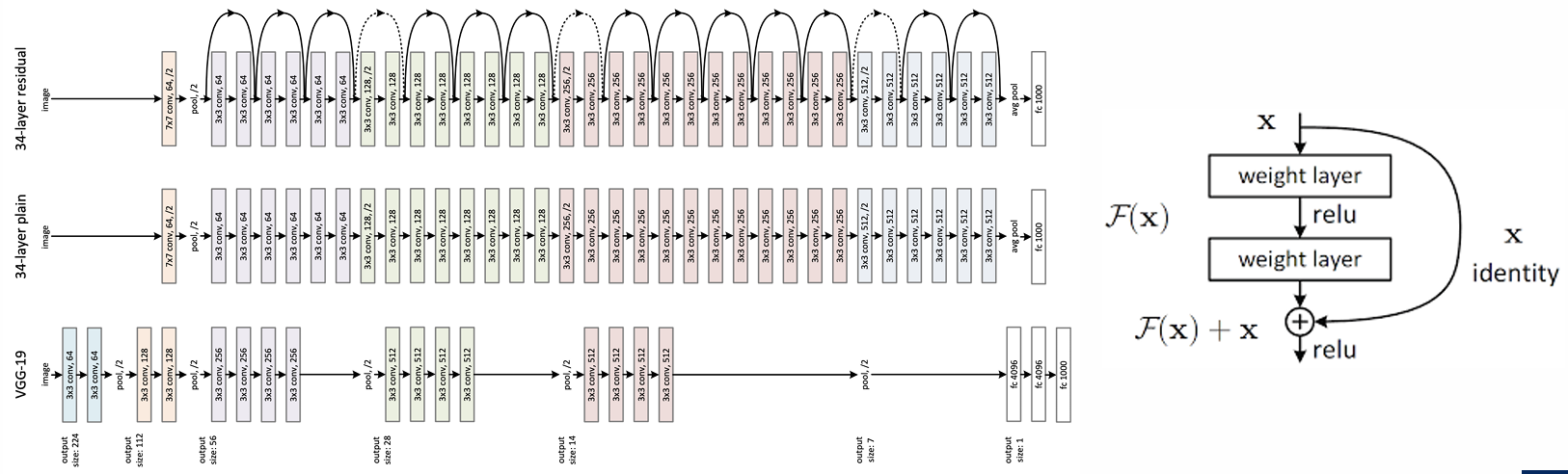
DenseNet
- 각 층이 feed-forward 방식으로 모든 다른 층과 연결되는 Dense Connectivity를 도입했다.
- 특징(feature)의 재사용을 촉진하고 파라미터 수를 줄인다.
- 기울기 손실(vanishing gradient)을 완화하고 특징 전달(feature propagation)을 강화한다.
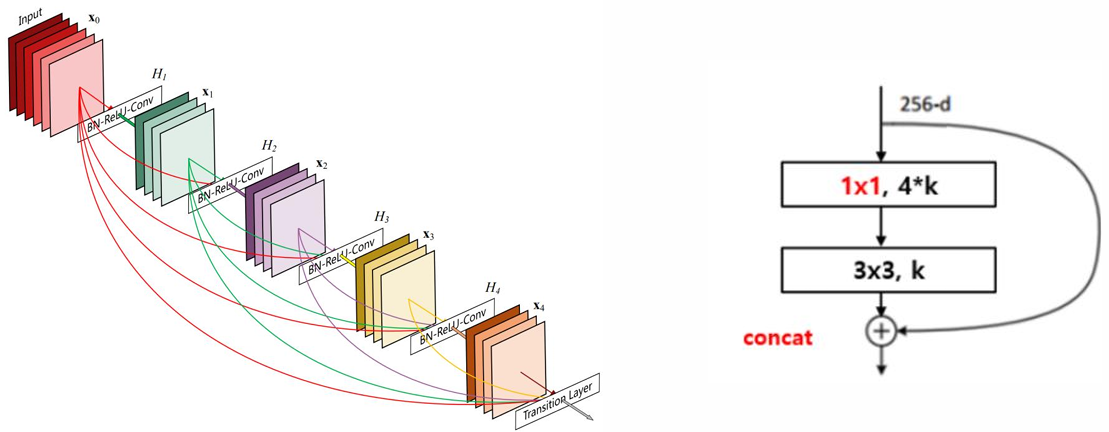
MobileNet
- 모바일 및 임베디드 장치에서 효율적인 추론(inference)을 수행하도록 설계되었다.
- 연산량과 모델 크기를 줄이기 위해 depthwise separable convolution을 도입했다.
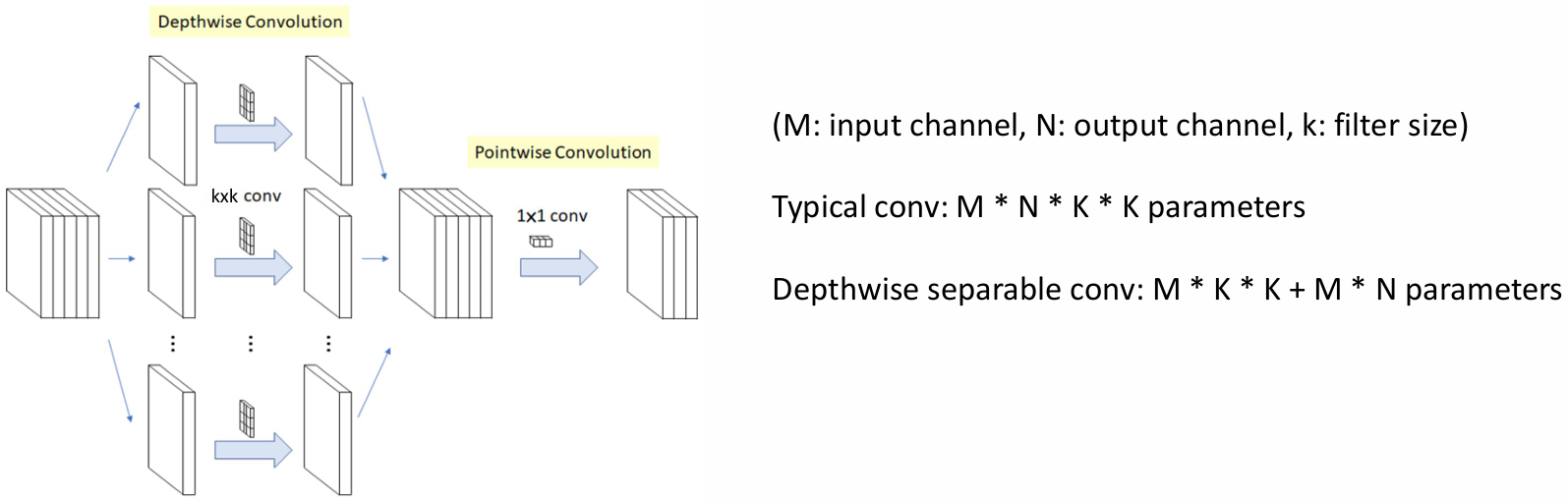
참고 논문 : Mobilenets: Efficient convolutional neural networks for mobile vision applications
EfficientNet
- 네트워크의 깊이(depth), 너비(width), 해상도(resolution)를 균형 있게 조절하기 위해 복합 스케일링(compound scaling) 방법을 도입했다.
- 효율성과 정확도 사이의 다양한 균형점을 제공하는 모델 계열(family of models)을 제안했다.
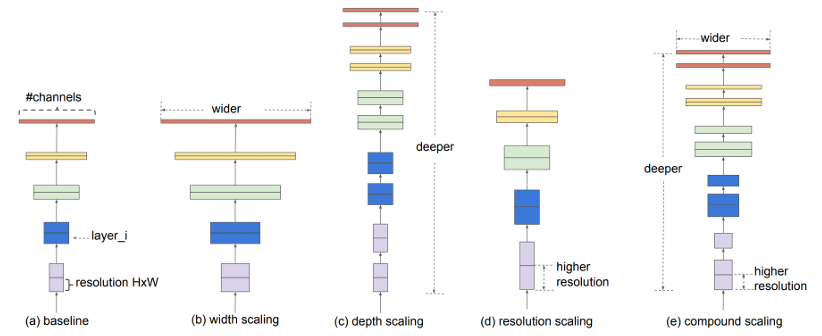
참고 논문 : Efficientnet: Rethinking model scaling for convolutional neural networks
Vision Transformer (ViT)
- 트랜스포머 아키텍처를 이미지 처리에 맞게 변형했다.
- 이미지를 문장에서 단어를 다루는 방식처럼 패치(patch)들의 시퀀스로 취급했다.
- 셀프 어텐션(self-attention) 메커니즘을 사용하여 이러한 이미지 패치들을 처리했다.
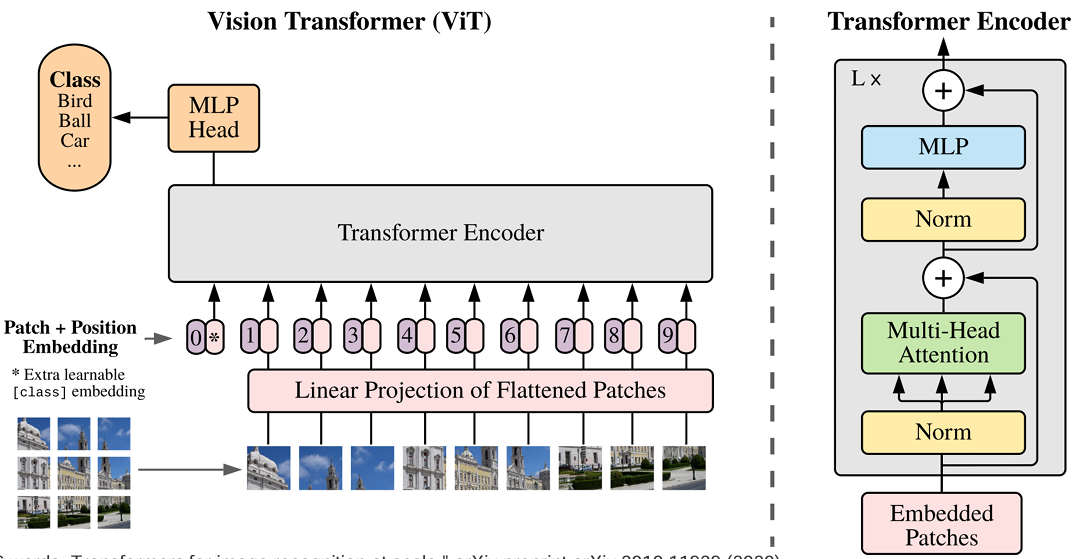
참고 논문 : An image is worth 16x16 words: Transformers for image recognition at scale
Swin Transformer
- 연산 복잡도를 줄이기 위해 국소 영역(local regions) 내에서만 self-attention을 수행했다.
- 윈도우를 번갈아 이동(shift)시킴으로써 이미지의 서로 다른 영역 간 정보 교환을 가능하게 했다.
- CNN과 유사한 계층적(feature hierarchy) 특성 맵을 도입하여 다양한 해상도에서 시각적 특징을 효과적으로 추출했다.
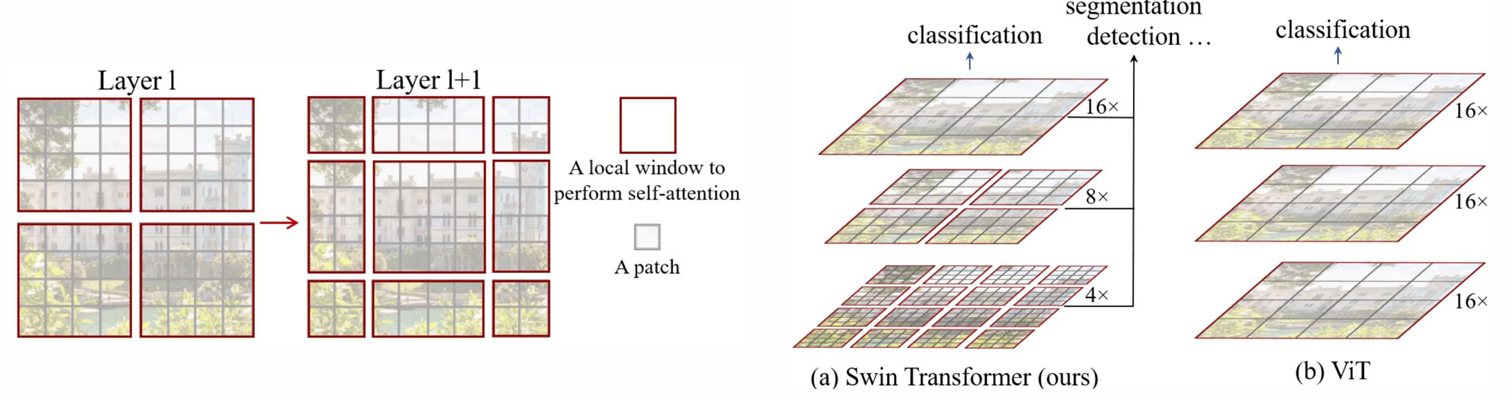
참고 논문 : Swin transformer: Hierarchical vision transformer using shifted windows
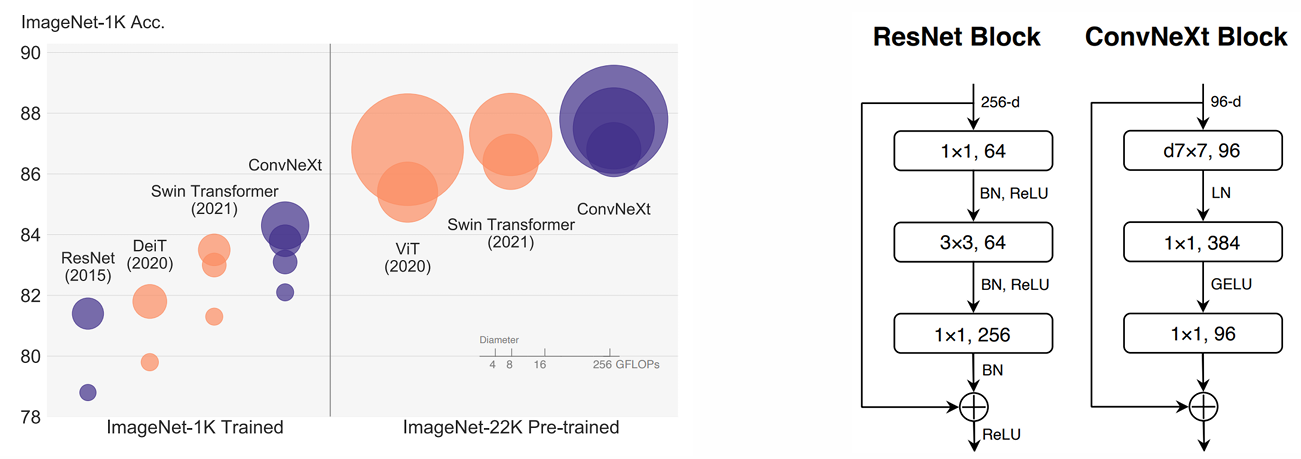
ConvNeXt
- 트랜스포머의 성능에 맞추기 위해 설계된 순수 CNN 구조다.
- 비전 트랜스포머에서 영감을 받은 설계 선택을 통해 기존 ResNet 아키텍처를 현대화했다.
- 주요 변경 사항으로는 더 큰 커널 크기, depthwise convolution, layer normalization, 깊이 증가 등이 있다.
Object Detection

Object Detection - RCNN
- 객체 탐지를 위해 CNN을 처음으로 활용한 모델이다.
- 영역 제안을 생성하기 위해 수작업 방식인 selective search를 사용했다.
- 각 영역에서 독립적으로 CNN 특징을 추출했다.

참고 논문 : Rich feature hierarchies for accurate object detection and semantic segmentation
Object Detection - Fast RCNN
- 전체 이미지를 한 번만 CNN에 통과시켜 처리함으로써 R-CNN을 개선했다.
- RoI(Region of Interest) 풀링 레이어를 도입했다.
- 분류(classification)와 경계 상자 회귀(bounding box regression)를 결합한 다중 작업 손실 함수(multi-task loss function)를 사용했다.
- 여전히 외부 영역 제안 방법에 의존했다.

- 영역 제안을 생성하기 위해 Region Proposal Network(RPN)를 도입했다.
- RPN을 Fast R-CNN과 통합하여 하나의 통합된(end-to-end trainable) 학습 가능한 네트워크를 구성했다.
- 이후의 많은 객체 탐지 모델들의 기반이 되는 구조를 형성했다.
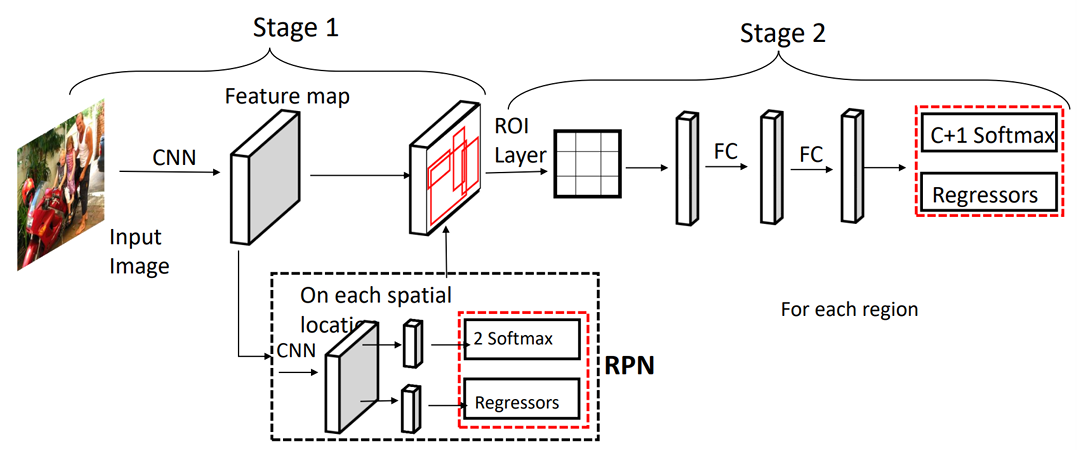
참고 논문 : RFaster R-CNN: Towards real-time object detection with region proposal networks
Semantic Segmentation
- 겹치는 패치들 사이에서 공유된 특징을 재사용하지 않아 비효율적이다.
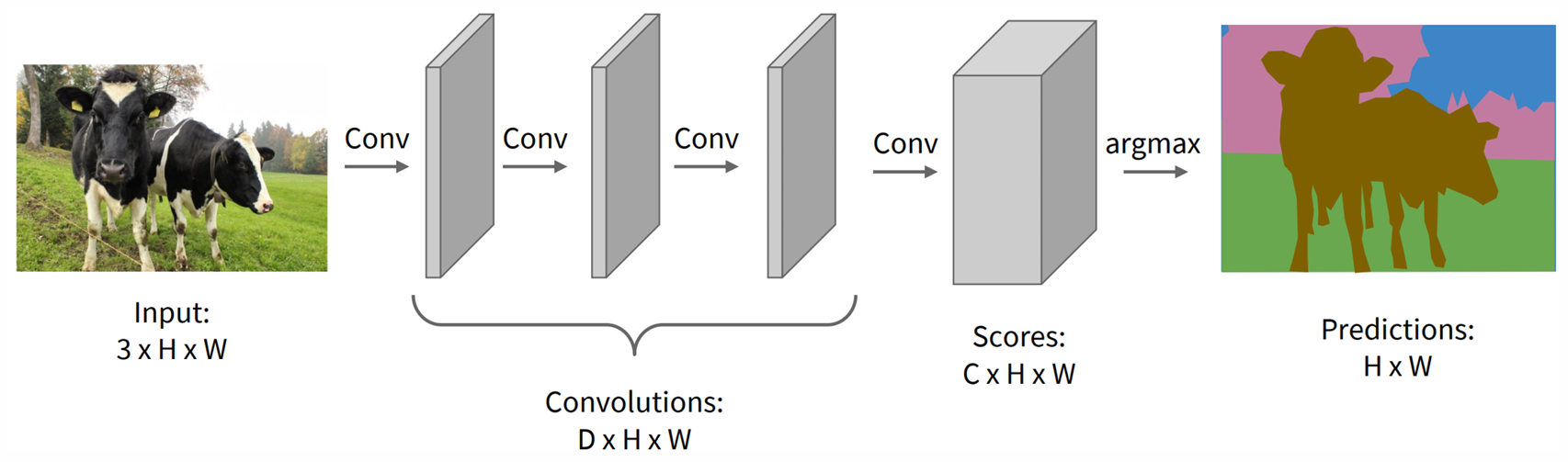
- 원본 이미지 해상도에서 convolution 연산을 수행하면 계산 비용이 매우 크다.
Semantic Segmentation - SegNet
- 네트워크 내부에 다운샘플링과 업샘플링을 포함한 합성곱 계층을 사용했다.
- Max-Pooling은 각 풀링 윈도우에서 가장 큰 값을 선택하고, 해당 값의 위치(인덱스)를 기록했다.
- 풀링 인덱스를 활용하여 풀링된 특징 맵을 원래 크기로 복원했다.
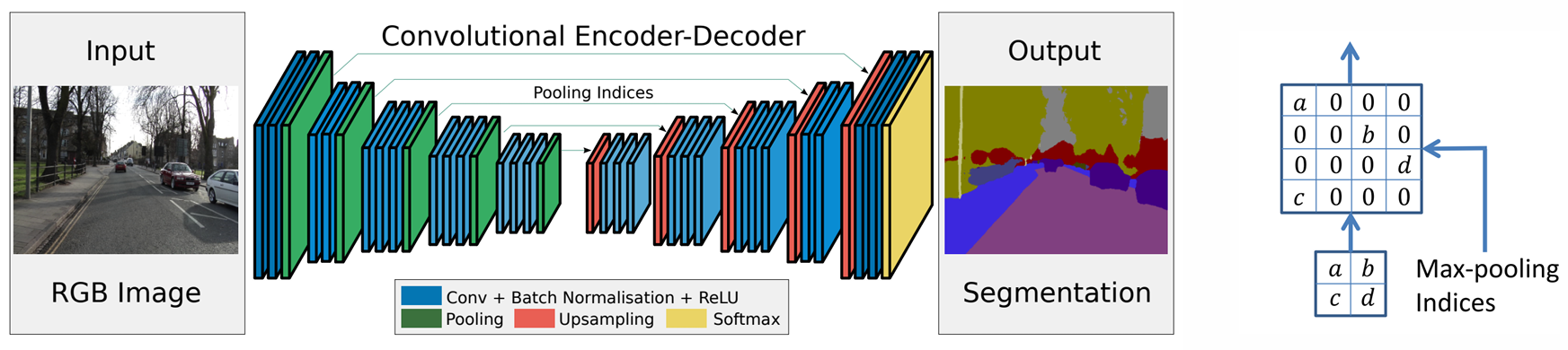
참고 논문 : Segnet: A deep convolutional encoder-decoder architecture for image segmentation
Detection + Segmentation - Mask RCNN
- Faster R-CNN을 확장하여 픽셀 수준의 이미지 분할을 가능하게 했다.
- 각 Region of Interest(관심 영역)에 대해 분할 마스크를 예측하는 분기(branch)를 추가했다.
- 객체 탐지와 분할을 공동으로 수행함으로써 성능 향상을 달성했다.
참고 논문 : Mask r-cnn
