핵심단어
CNN, 사전훈련, 전이학습
학습목표
- CNN의 기본구조 숙지하기
- Convolution & Pooling Layer 의 동작 방식과 조정할 수 있는 값(Stride, Padding 등)에 대해 이해하기
- 전이 학습(Transfer Learning)을 설명할 수 있으며 이미지 처리를 위한 대표적인 사전 학습 모델 설명하기
- CNN모델을 구축하거나, 사전 학습 모델을 사용해 이미지 분류하는 코드 작성하기..(과연)
1. CNN
- 이미지는 위치에 맞는 공간적 특성을 가지고 있음
- But, MLP는 모든 입력값을 Flatten으로 펴준 뒤에 연산, 공간적 특성을 살리지 못함
- 합성곱신경망(CNN)은 학습과정에서 이런 공간적 특성을 보존하며 학습 가능
CNN 구조
- 합성곱 층(특징추출 부분) - 풀링층(분류를 위한 신경망) 이렇게 두가지 층으로 나뉘어져 있음
합성곱과 풀링
합성곱(Convolution)
- 합성곱 층에서는 합성곱 필터(Convolution Filter)가 슬라이딩(Sliding)하며 이미지 부분부분의 특징을 읽어나감 (warm-up영상 참고)
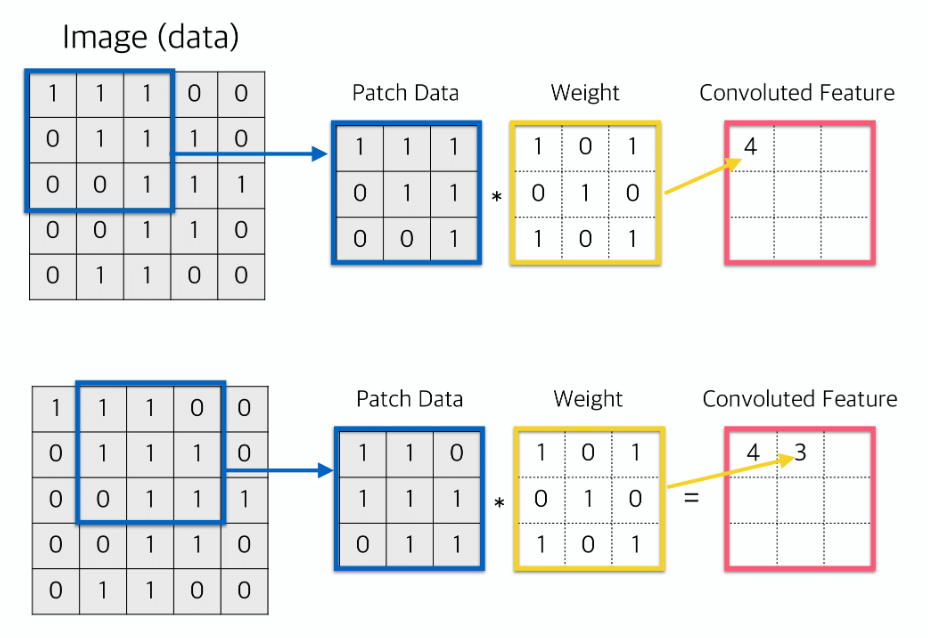
- 위의 그림이 찰떡이다
패딩
- 패딩은 이미지의 외부를 특정한 값으로 둘러싸서 처리해주는 방식
- 보통 제로-패딩이 가장 많이 사용됨
- 연산되어 나오는 OUTPUT의 크기를 조절하고, 실제 이미지 값을 충분히 활용하기 위해 사용한다
스트라이드
- 스트라이드는 보폭이라는 뜻!
- 스트라이드 조정을 통해 슬라이딩 할 때 몇 칸 씩 건너뛸지를 정함

풀링
- 가로 세로 방향을 줄이기 위한 방식
- 최대풀링과 평균 풀링이 있음
- 일반적으로 이미지 처리 시에는 각 부분의 특징 보존을 위해 최대 풀링 사용
- 풀링층은 가중치가 없으며, 채널수가 변하지 않음
완전 연결 신경망(fully connected layer)
- 합성곱층 - 풀링층에서 충분히 특징을 추출
- 다음은 분류를 위한 완전 연결 신경망 구축
- 완전 연결 신경망은 다층 퍼셉트론 신경망으로 구성되어 있음
- 문제에 따라 출력층만 잘 구성해줘도 좋은 결과를 도출할 수 있다
3개의 convolution층 사이에 pooling층 끼워넣어 특징 추출 구성
model = Sequential()
model.add(Conv2D(32, (3,3), padding='same', activation='relu'))
#32 : 필터의 개수 3,3 : 필터의 크기, 'same'= 출력값 같게
model.add(MaxPooling2D(2,2)) #풀링 2x2행렬
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(MaxPooling2D(2,2))
model.add(Conv2D(64, (3,3), padding='same', activation='relu'))
model.add(Flatten()) #층펴주기
model.add(Dense(128, activation='relu')) #은닉층
model.add(Dense(10, activation='softmax')) #출력층
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])model.fit(X_train, y_train,
batch_size=128, #권장사이즈는 아님
validation_data=(X_val, y_val),
epochs=10)2. 전이학습
- 전이학습은 대량의 데이터를 학습한 사전 학습 모델(Pre-trained Model)의 가중치를 그대로 가져온 뒤 분류기, 즉 완전 연결 신경망 부분만 추가로 설계하여 사용
- 사전학습 모델의 가중치는 대량의 데이터를 학습하여 얻어지고, 여러 데이터의 특징을 많이 학습하여 어떠한 데이터가 입력 되더라도 대체적으로 준수한 성능을 보임
- 결론 : 잘 만들어진 거 가져다가 약간 수정해서 써보렴
이미지 분류를 위한 사전 학습 모델 VGG, Inception, ResNet
VGG
- 모든 합성곱 층에서 3×3 크기의 필터 사용
- 대신 층을 깊게 쌓음으로써 기존 7×7, 11×11 크기의 필터 이상의 표현력을 가질 수 있도록 함
- 활성화 함수로 ReLU를 사용하고 가중치 초깃값으로는 He 초기화을 사용
- 층을 깊게 쌓았음에도 기울기 소실(Gradient vanishing)문제기 발생하지 않음
- 마지막으로 완전 연결 층에 드롭아웃(Dropout)을 사용하여 과적합 방지 및 옵티마이저는 아담(Adam) 사용
GoogLeNet(Inception)
- 기본적인 합성곱 신경망이 결합된 형태
- 가로 방향으로 넓은 신경망 층을 가지고 있음 : 인셉션 구조
ResNet
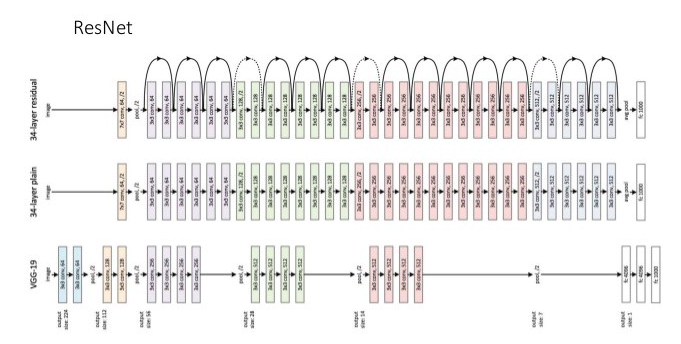
- 층을 넘어 이어지는 화살표 구조
- 이 화살표는 ResNet의 특징인 Residual Connection(=Skipped Connection)
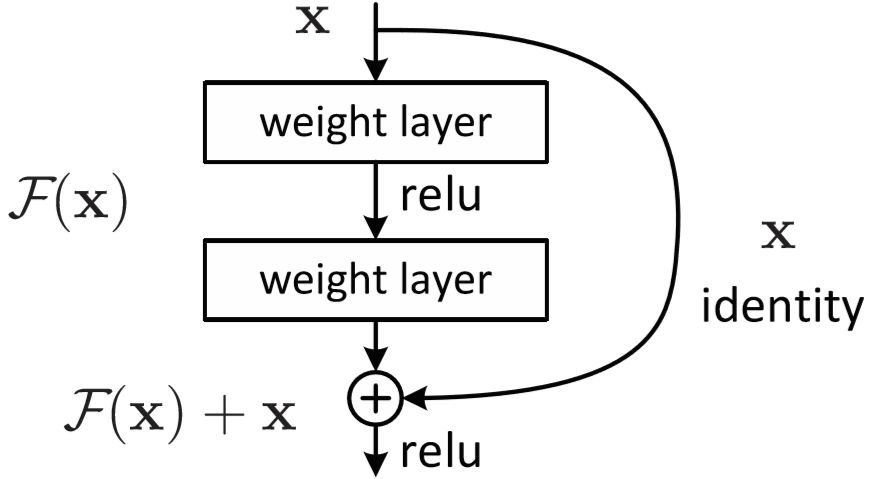
- 층을 거친 데이터의 출력에 거치지 않은 출력을 더해주는 구조
- 이 방법을 사용하면 역전파 과정에서 미분을 적용하더라도 1 이상의 값으로 보존됨
- 층이 깊어짐에 따라 발생하는 기울기 소실(Vanishing Gradient) 문제를 어느정도 해결할 수 있음
pretrained_model = VGG16(weights='imagenet', include_top=False)
model = Sequential()
model.add(pretrained_model)
model.add(GlobalAveragePooling2D()) #데이터 shaqpe를 (n,n,n,512) -> (n,512)
model.add(Dense(128,activation='relu'))
model.add(Dense(10,activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(X_train, y_train,
batch_size=128,
validation_data=(X_val, y_val),
epochs=10)
model.evaluate(X_test, y_test, verbose=2)3.이미지 증강(Image Augmentation)
- 일반화(Generalization)가 잘 되는 모델을 만들기 위해서 학습 데이터셋에 있는 이미지를 일부러 회전하거나 기울여서 나타냄
- 이러한 방법을 이미지 데이터 증강(Image Data Augmentation) 이라고 합니다.
학습후기
첫 부분이라 그런 지 엄청 어렵지는 않았는데 토론가니깐 머리가 핑글핑글 돌고!
그치만 토론 한 문제 정도는 완벽하게 숙지하고 넘어가서 뿌듯했다!
내일도 화이팅! 딥러닝 어렵더라도... 킵고잉하기!

기록기록