
DB에서 특정 조건의 데이터 조회 성능을 향상시키기 위해서는 인덱스를 사용한다. 인덱스를 사용하면 왜?, 어떻게? 조회 속도가 빨라지는 걸까? 한 번 알아본다.
보통 테이블은 데이터들이 산발적으로 저장되어 있기 때문에 특정 조건의 데이터를 찾기위해서는 풀 테이블 스캔 즉, 테이블을 처음부터 끝까지 훑어야 한다.
특징
- 테이블은 오브젝트라고도 한다. 인덱스도 오브젝트다. 인덱스를 생성하면 테이블에 매핑되는 새로운 테이블이 생성되는 것과 같다.
- 인덱스는 인덱스 컬럼을 기준으로 정렬이 되어 생성된다.
B-tree 인덱스
- 인덱스의 종류는 여러 가지있다. 그중 B-tree 인덱스를 가장 많이 사용한다.
B-Tree
균형 있는 이진탐색트리다.
- 트리의 높이가 같다.
- 자식 노드를 2개 이상 가질 수 있다.
- O(log n)

형태
여기서는 개념을 잡는 것이 목적이기에 구조를 간단하게 설명했습니다.
예시로 살펴본다.
회원테이블이 있고 a 컬럼을 가지고 인덱스를 생성한다.
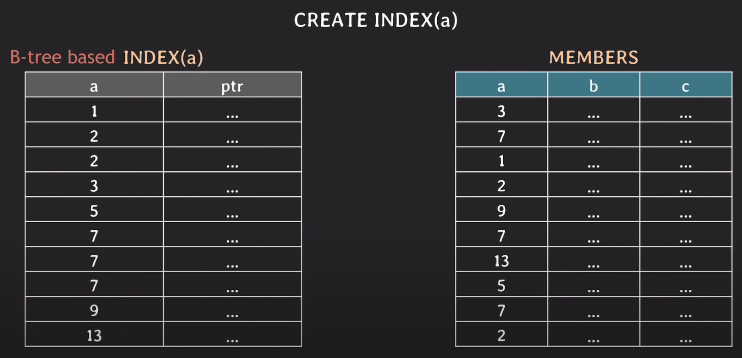
인덱스 역시 테이블이기 때문에 새로운 테이블이 생성된다. 인덱스의 컬럼은 2개로 정렬된 a와 포인터를 갖고 있다. 포인터는 a컬럼에 해당하는 실제 회원 테이블의 로우를 참조하고 있다.
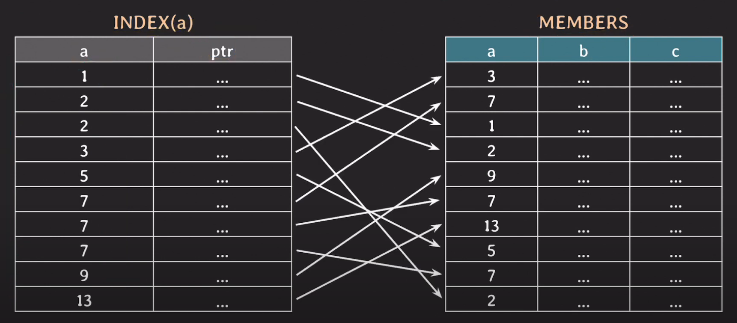
조회 - 단일 조건
이제 데이터를 조회해본다. where a = 9 라는 조건으로 조회한다.
인덱스를 기반으로 조회하게 된다. 인덱스는 정렬되어 있기 때문에 이진탐색을 이용해서 효율적으로 조회할 수 있다. 절반 씩 줄여나가면서 원하는 조건을 발견하고 같은 조건의 데이터가 더 있을 수 있기 때문에 앞,뒤의 데이터도 확인한다.
만약 9를 발견했고 1개 밖에 없다면 이제 포인터를 이용해서 실제 테이블의 행에 접근해서 데이터를 반환한다.
조회 - 복합 조건
이번에는 인덱스는 그대로 사용하는데 where a = 7 and b = 95로 조회 조건이 달라진다. 차이를 알아본다.
이번에도 역시 이진 탐색을 이용해서 먼저 a = 7을 찾는다. 찾았다면 b = 95인지도 확인해야 하기 때문에 포인터를 타고 실제 테이블로 가서 확인한다. 만약 a = 7 이 여러 개라면 모든 행마다 일일이 b = 95를 확인하기 위해서 포인터를 타고 가서 확인해야 한다.
여기서 알 수 있는 점은 여러 컬럼을 AND 조건으로 조회시 인덱스는 하나만 걸려있다면 인덱스가 걸린 컬럼에 대해서는 빠르게 조회할 수 있지만 다른 컬럼은 일일이 확인해야하기 때문에 효율이 떨어진다.
그럼 어떻게 하면 더 효율적으로 조회할 수 있을까?
복합 인덱스를 걸어주면 된다. a만 인덱스를 걸지 않고 (a,b) 묶어서 인덱스를 걸 수 있다.

인덱스를 거는 순서가 중요하다. a,b 순으로 인덱스를 지정했다면 a컬럼이 먼저 정렬되고 그 다음 b 컬럼이 정렬된다. 이렇게 인덱스를 걸어두고 다시 복합 조건으로 조회해본다.
이전과 동일하게 먼저 a = 7을 찾는다. 이제 b = 95를 찾는다. 이전과 다르게 인덱스에 b컬럼도 존재하기 때문에 포인터를 타지 않고 바로 b컬럼을 확인할 수 있다. 그리고 여기서 중요한 차이점을 알 수 있다. b 컬럼 역시 정렬되어 있기 때문에 만약 b = 95를 발견했다면 인접한 위,아래 행만 확인하면 된다. 훨씬 효율적이다.
한 가지 더 살펴보자.
복합 인덱스를 그대로 두고 조건이 달라진다. b = 95이다. 이 경우 어떻게 될까? 인덱스가 아무런 이점이 없다. a를 기준으로 정렬되어 있기 때문에 b만 보면 정렬되지 않은 것과 같다. 이런 경우 b로 인덱스를 따로 만들어야 한다.

예제를 살펴본다.
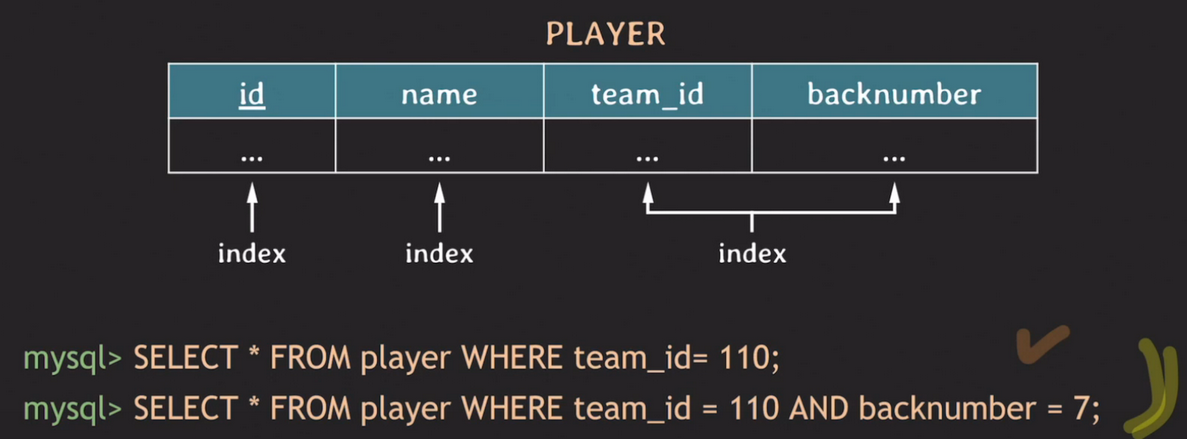
team_id와 backnumber를 묶어서 인덱스를 지정했다. 위와 같은 조건인 경우 두 조건 모두 하나의 인덱스를 이용할 수 있다. 굳이 team_id 를 따로 인덱스로 지정할 필요가 없다.

그럼 이 조건은 어떨까? 먼저 backnumber 조건의 경우 인덱스는 team_id를 기준으로 먼저 정렬되어 있기 때문에 어차피 Fulltable 스캔을 해야 한다. or로 묶인 2번째 조건의 경우 team_id는 인덱스를 타지만 backnumber는 인덱스를 못타기 때문에 시간이 오래걸린다. 이 조건들을 성능을 향상시키기 위해서는 backnumber를 인덱스로 지정해주면 된다.
이렇기 때문에 사용되는 쿼리의 조건을 잘 파악하고 조건을 잘 커버할 수 있는 인덱스를 생성하는 것이 중요하다.
쿼리가 어떤 인덱스를 타는지 확인하는 법
mysql의 경우 select 쿼리 앞에
explain키워드를 넣어주면 해당 쿼리가 어떤 인덱스를 타는지 확인할 수 있다.
인덱스를 직접 지정하는 방법
db의 optimizer가 쿼리를 보고 어떤 인덱스를 사용할지 판단한다.
내가 직접 인덱스를 지정하고 싶다면use index (인덱스명)나force index (인덱스명)을 사용하면 된다.
use: 권장force: 강제ex)
select * from member USE INDEX (age_idx) where age = 20;
커버링 인덱스
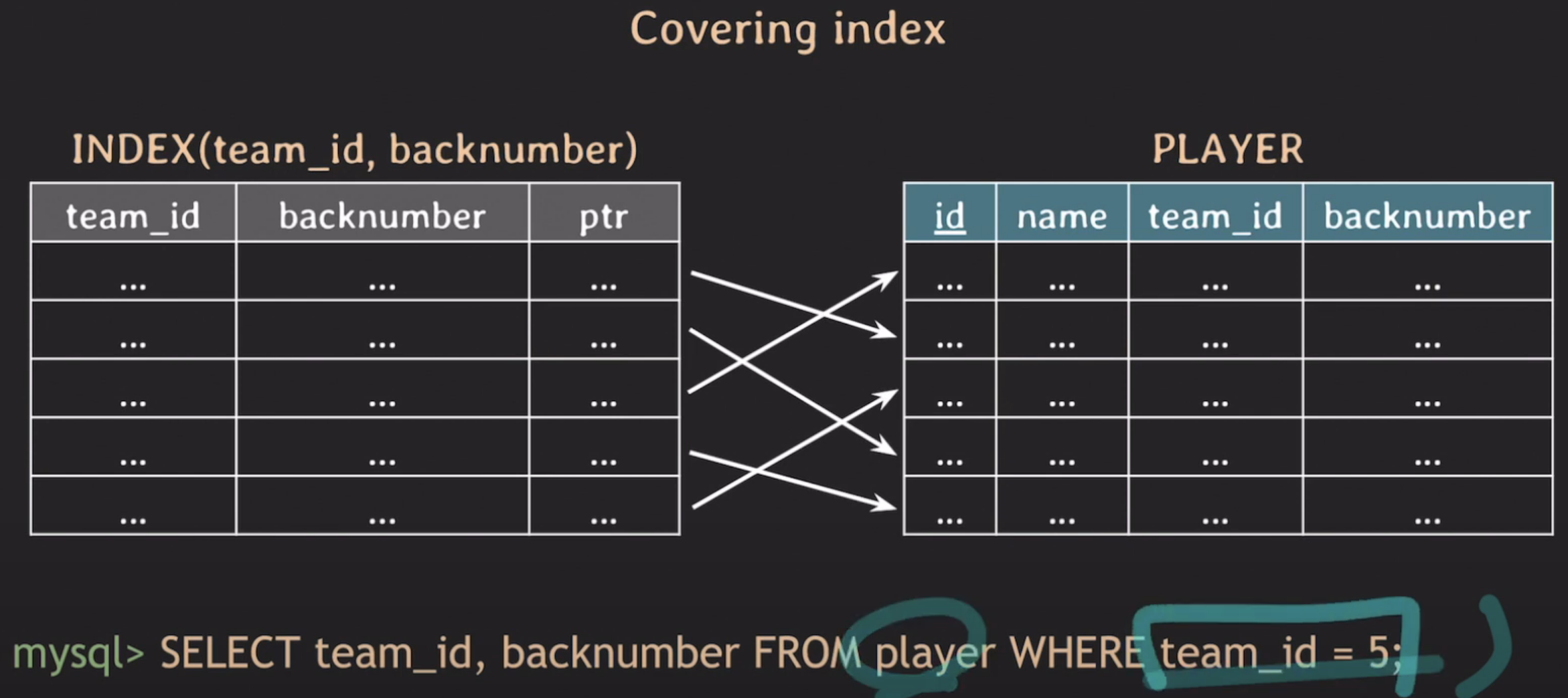
예시처럼 team_id와 backnumber만 조회하는 경우를 살펴본다. 인덱스는 team_id & backnumber로 걸려있는데 이 얘기는 인덱스안에 이미 team_id & backnumber 가 들어있다는 뜻이다. 그래서 인덱스에서 team_id로 조건이 맞는 데이터를 찾기만 하면 실제 테이블에 가지 않아도 필요한 데이터를 조회할 수 있기 때문에 성능이 높아진다. 이런 경우를 커버링 인덱스라고 한다.
단점
인덱스를 남발하면 안된다. 인덱스도 오브젝트이기 때문에 데이터를 추가하는 경우 인덱스에도 데이터를 저장해야 한다.
- insert 성능이 떨어진다.
- 데이터를 write 할 때 인덱스에 데이터를 추가하면 인덱스 구조가 변경되기 때문에 시간이 걸린다.
- 저장공간의 낭비된다.
인덱스를 걸 때 중복여부를 잘 판단해서 불필요한 인덱스를 생성하지 않는다. 그리고 트레이드 오프를 잘 고민해서 실보다 득이 더 클 때 적용하는 것이 좋다. 예 ) 데이터 write 는 거의 안하고 조건을 단 조회 쿼리가 많은 경우.
Hash 인덱스
Hash table을 사용하기 때문에 다음과 같은 특징이 있다.
- 조회 성능이
O(1)이다. - rehashing에 대한 부담이 있다. hash table은 배열로 만들어져있기 때문에 데이터가 늘어나면 배열의 크기를 늘려줘야 한다.
- hash 테이블은 hash 값을 넣어서 해당 하는 값이 튀어나오게 작동하기 때문에
=조건만 사용할 수 있다. 값의 크기를 비교하는 연산은 불가능하다. - 같은 맥락으로 (a,b) 복합 인덱스의 경우 B-tree는 a 컬럼만 조건을 걸어도 해당 인덱스를 탈 수 있었지만 hash 인덱스는 두 값을 합쳐서 해시를 생성하기 때문에 a조건 만으로는 인덱스를 탈 수 없다.
참고
