앞으로 배울 내용
- 강화학습이란 무엇인가?
- 미로찾기를 위한 강화학습 구현
- 역진자 문제를 위한 강화학습 구현
- 파이토치를 이용한 딥러닝 구현
- 딥러닝을 적용한 강화학습 - DQN 구현
- 딥러닝을 적용한 강화학습 - 심화과정
- AWS GPU 환경에서 벽돌깨기 구현
오늘은 2. 미로찾기를 위한 강화학습 구현
2.1 주피터 노트북 체험 페이지 사용법
2.2 미로와 에이전트 구현
2.2.2 에이전트 구현
이제 녹색 동그라미로 나타낸 에이전트가 미로 안을 무작위로 이동하여 목표 지점을 찾아가도록 구현하고, 그 과정을 동영상으로 출력해 보겠다.
강화학습에서 포스팅 1. 강화학습이란 무엇인가? 파트에서 말했듯이 강화학습에서 에이전트가 어떻게 행동할지를 결정하는 규치기을 정책(policy)이라고 한다. 정책 policy의 p에 해당하는 그리스 문자인
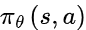 로 표기한다.
로 표기한다.
이것이 무엇인지 쉽게 설명하자면 "상태가 s일 때 행동 a를 취할 확률은 파라미터 𝛳가 결정하는 𝝅를 따른다"는 의미다.
행동 a는 어떤 상태에 있을 때 에이전트가 취할 수 있는 행동을 나타낸다. 미로탐색이라면 상, 하, 좌, 우로 이동하는 4가지 행동을 취할 수 있을 것이다. 다만 붉은 벽이 있는 방향으로는 이동할 수 없다. 미로가 아니고 로봇이라면 각 관절에 연결된 모터를 각각 어느 정도 회전시킬지가 될 것이고, 바둑이나 장기라면 다음 수로 어떤 말을 어디로 옮길지에 해당한다.
정책 𝝅는 다양한 방법으로 나타낼 수 있다. 정책을 함수로 나타낼 수도 있고 5장에서 보듯 심층강화학습에서는 신경망을 사용하기도 한다. 이번자으이 태스크인 미로에서는 정책을 나타내는 가장 간단한 방법인 표현식 표현(tabular representation)을 사용할 것이다. 표형식 표현은 행이 s인, 열이 행동 a를 나타낸다. 표의 각 값은 해당 상태에서 각 행동을 취할 확률을 의미한다.
먼저 파라미터 𝛳의 초기값 𝛳_0을 구현해 보자. 이동 가능한 방향에는 1, 벽이 있어 이동할 수 없는 방향에는 np.nan을 대입했다. np.nan은 아무 값도 없는 누락된 값을 의미한다. 표의 행은 상태를 의미하며, 열은 행동을 나타내며, 순서대로 상, 우, 하, 좌를 의미한다.
# 정책을 결정하는 파라미터의 초깃값 theta_0을 설정
# 줄은 상태 0~7, 열은 행동 방향(상, 우, 하, 좌)을 나타낸다.
theta_0 = np.array([[np.nan, 1, 1, np.nan], # s0
[np.nan, 1, np.nan, 1], # s1
[np.nan, np.nan, 1, 1], # s2
[1, 1, 1, np.nan], # s3
[np.nan, np.nan, 1, 1], # s4
[1, np.nan, np.nan, np.nan], # s5
[1, np.nan, np.nan, np.nan], # s6
[1, 1, np.nan, np.nan], # s7, s8은 목표 지점이므로 정책이 없다
])이어서 파라미터 𝛳_0을 변환해서 정책 을 구한다. 여기서 단순한 변환 방법을 택해서 이동 방향에 대한 𝛳값의 비율을 계산해서 확률로 삼는다. 이 변환을 맡을 함수를 simple_convert_into_pi_from_theta라는 이름으로 정의한다.
# 정책 파라미터 theta를 행동 정책 pi로 변환하는 함수
def simple_convert_into_pi_from_theta(theta):
'''단순히 값의 비율을 계산'''
[m, n] = theta.shape # theta의 행렬 크기를 구함
pi = np.zeros((m, n))
for i in range(0, m):
pi[i, :] = theta[i, :] / np.nansum(theta[i, :]) # 비율 계산
pi = np.nan_to_num(pi) # nan을 0으로 변환
return pi
이제는 지금 정의한 변환 함수인 simple_convert_into_pi_from_theta를 실행해 𝛳_0으로부터 초기 정책 을 구한다.
# 초기 정책 pi_0을 계산
pi_0 = simple_convert_into_pi_from_theta(theta_0)
# 초기 정책 pi_0을 출력
pi_0

이번에는 에이전트가 정책 을 따라 행동하게끔 해보겠다. 1단계 이동 후 에이전트의 상태를 구하는 함수를 get_next_s라는 이름으로 정의한다. 미로의 위치는 0부터 8까지의 숫자로 정의돼 있다. 에이전트가 이동하는 경우, 예를 들어 위로 이동한다면 상태의 값이 3 감소하게 하면 될 것이므로 현재 위치 값에서 3을 빼면 된다
# 1단계 이동 후의 상태 s를 계산하는 함수
def gen_next_s(pi, s):
direction = ["up", "right", "down", "left"]
next_direction = np.random.choice(direction, p = pi[s, :])
# pi[s, :]의 확률에 따라, direction 값이 선택된다.
if next_direction == "up":
s_next = s - 3 # 위로 이동하면 상태값이 3만큼 줄어든다.
elif next_direction == "right":
s_next = s + 1 # 오른쪽으로 이동하면 상태값이 1만큼 늘어난다
elif next_direction == "down":
s_next = s + 3 # 아래로 이동하면 상태값이 3만큼 늘어난다
elif next_direction == "left":
s_next = s - 1 # 왼쪽으로 이동하면 상태값이 1만큼 줄어든다
return s_next
마지막으로 에이전트가 목표에 도달할 때까지  에 따라 gen_next_s 함수로 에이전트를 이동시키며 계속 진행한다. 이렇게 목표 지점에 도달할 때까지 에이전트를 계속 이동시크는 역할을 맡을 함수 goal_maze를 정의하겠다. goal_maze 함수는 목표에 도달할 때까지 while문을 반복 수행하며 상태 이력을 staten_history 리스트에 계속 저장한다. 그리고 마지막에 state_history를 반환한다.
에 따라 gen_next_s 함수로 에이전트를 이동시키며 계속 진행한다. 이렇게 목표 지점에 도달할 때까지 에이전트를 계속 이동시크는 역할을 맡을 함수 goal_maze를 정의하겠다. goal_maze 함수는 목표에 도달할 때까지 while문을 반복 수행하며 상태 이력을 staten_history 리스트에 계속 저장한다. 그리고 마지막에 state_history를 반환한다.
# 목표 지점에 이를 때까지 에이전트를 이동시키는 함수
def goal_maze(pi):
s = 0 # 시작 지점
state_history = [0] # 에이전트의 경로를 기록하는 리스트
while (1): # 목표 지점에 이를 때까지 반복
next_s = gen_next_s(pi, s)
state_history.append(next_s) # 경로 리스트에 다음 상태(위치)를 추가
if next_s == 8: # 목표 지점에 이르면 종료
break
else:
s = next_s
return state_history
그리고 이 goal_maze 함수를 사용해 정책  를 에이전트를 이동시키고 그 과정에서 취한 행동 이력을 state_history에 저장한다.
를 에이전트를 이동시키고 그 과정에서 취한 행동 이력을 state_history에 저장한다.
# 목표 지점에 이를 때까지 미로 안을 이동
state_history = goal_maze(pi_0)print(state_history)
print("목표 지점에 이르기까지 걸린 수는 " + str(len(state_history) - 1) + "단계입니다")
행동 이력을 따라 화면 상의 미로에서 에이전트를 구현하는 것으로 이번 절의 내용을 마치려고 한다.
# 에이전트의 이동 과정을 시각화
# 참고 URL http://louistiao.me/posts/notebooks/embedding-matplotlib-animations-in-jupyter-notebooks/
from matplotlib import animation
from IPython.display import HTML
def init():
'''배경 이미지 초기화'''
line.set_data([], [])
return (line,)
def animate(i):
'''프레임 단위로 이미지 생성'''
state = state_history[i] # 현재 위치
x = (state % 3) + 0.5 # 상태의 x좌표 : 3으로 나눈 나머지 + 0.5
y = 2.5 - int(state / 3) # y좌표 : 2.5에서 3으로 나눈 몫을 뺌
line.set_data(x, y)
return (line,)
# 초기화 함수와 프레임 단위 이미지 생성함수를 사용하여 애니메이션 생성
anim = animation.FuncAnimation(fig, animate, init_func=init, frames=len(
state_history), interval=200, repeat=False)
HTML(anim.to_jshtml())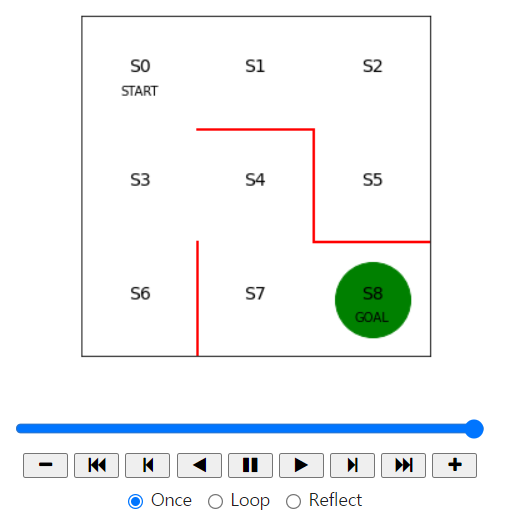
"
"
"
"
"
"
"
"
"
"
"
"
"
Reference

