PyTorch 스터디
교재 : Dive Into Deep Learning
- 진행 방식
- 해당 주차의 스터디 범위 학습
- 정해진 순번대로 발표 (개인적 목표: 매회 발표 자원하기!)
- 스터디 과정에서 학습 내용을 정리하였다.
Ch 3.1
3.1. 선형 회귀(Linear Regression) — Dive into Deep Learning documentation (d2l.ai)
d2l-ko/linear-regression.md at master · d2l-ai/d2l-ko (github.com)
딥러닝에서 가중치(W), 편향(Bias)의 역할 (tistory.com)
편향 (Bias)
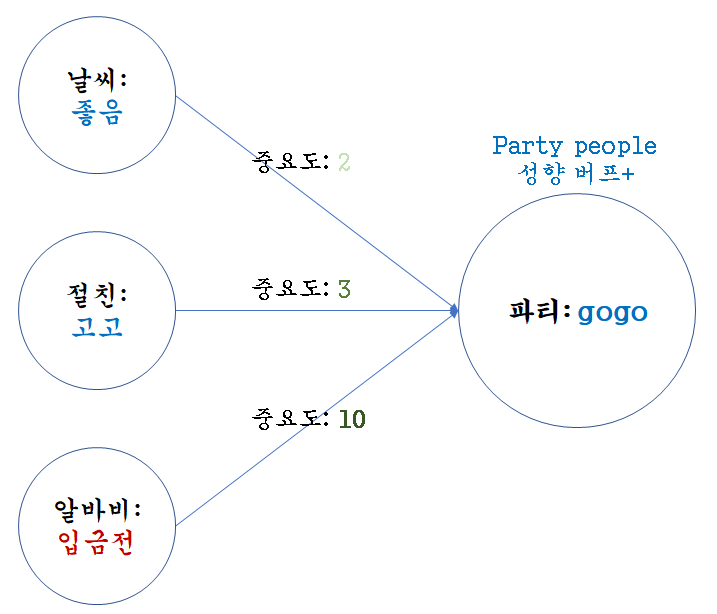
분류 문제 : 사람 A가 파티를 갈까?
sum(가중치*x) + b
하나의 뉴런으로 입력된 모든 값을 다 더한 다음에(가중합이라고 합니다) 이 값에 더 해주는 상수
비오고, 돈 없고, 시간 맞는 친구가 없어도
무조건 파티에 가는 사람이 있음
딥러닝에서 가중치(W), 편향(Bias)의 역할 (tistory.com)
활성화 함수 (Activation function)
A. (현실의)
임계점을 구현
- 자격증 평균 60점 넘으면 합격
- 59.9999999999 점 =
불합격- 50년 무사고 → 1분 뒤 사고 → ....
현실에서 임계점을 경계로 출력값에 큰 변화가 있음
- 뉴런에서도 동일 딥러닝은 뉴런(인간의 뇌)을 모방함
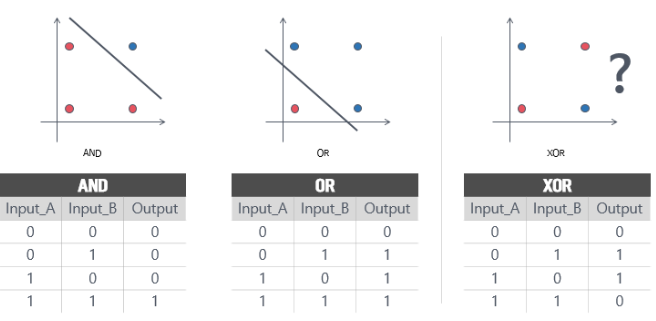
B. (이미지에서)
곡선특징(non-linear feature)를 인식
- 전제
딥러닝의 input → layer → output의 구조 = 선형
딥러닝에서 가중치(W), 편향(Bias)의 역할 (tistory.com)
딥러닝 - 활성화 함수(Activation) 종류 및 비교 : 네이버 블로그 (naver.com)
예시 : 선형 층(linear layer) 집합 = 선형
원인 : 이전층의 ouput(상수) = 다음층의 input
선형그래프로는 곡선을 표현할 수 없다.
예시에서 보인 것처럼 linear한 연산을 갖는 layer의 집합 하나의 linear으로 표현된다.
그래서
활성화 함수사용
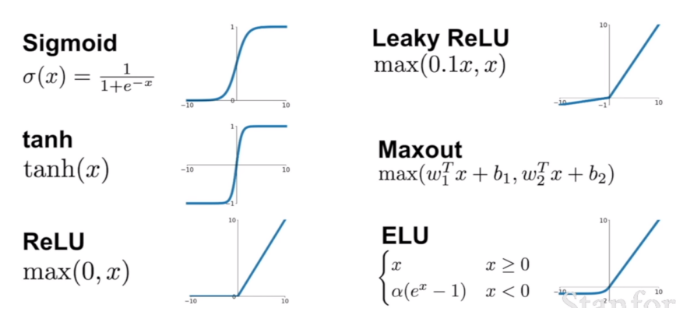
- 참고
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=handuelly&logNo=221824080339
활성화 함수(activation function)을 사용하는 이유 :: 프라이데이 (tistory.com)
최적화 (optimizer)
학습 성능 / 모델 성능 올리기
💡 데이터 반영 비율(학습률, learning rate) 설정하기딥러닝 학습중에 흔히 등장하는 loss의 형태, 어떻게 극복할까?
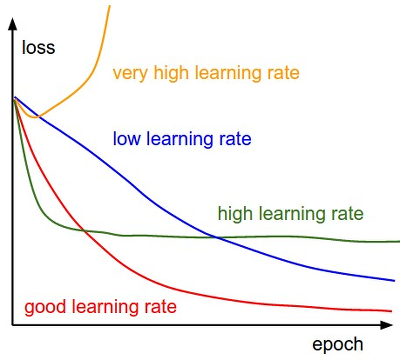
optimizer의 선택과 튜닝으로!!
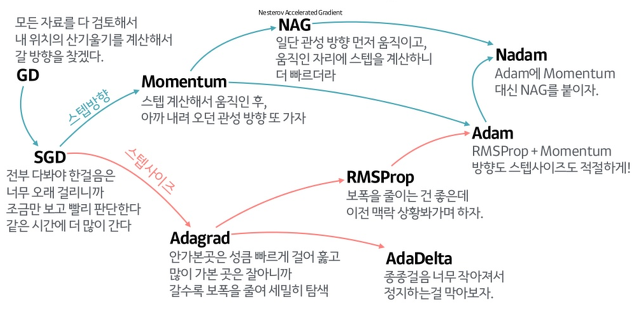
딥러닝(Deep learning) 살펴보기 2탄 (tistory.com)
옵티마이저(Optimizer) · Data Science (yngie-c.github.io)
확률적 경사 하강법(Stochastic Gradient Descent, SGD)
- 미니 배치에서 적용하고 가중치를 업데이트한다.
- 조금씩 자주 업데이트 하는 게 더 빠르다.


GD
정확하게
💡 느려....
- 모든 데이터를 계산한다 => 소요시간 1시간
- 최적의 한스텝을 나아간다.
- 6 스텝 * 1시간 = 6시간
- 확실한데 너무 느리다.
SGD
빠르게!!
💡 정확도는 더 많이 반복해서 올림
- 일부 데이터만 계산한다 => 소요시간 5분
- 빠르게 전진한다.
- 10 스텝 * 5분 => 50분
- 조금 헤메지만 그래도 빠르게 간다!
학습
💡 학습 : 데이터 셋으로 forward → backward데이터의 처리 사용 과정
- 데이터 → 모델 → 예측
가중치 업데이트
오차 줄이기 for 성능
학습 (training) vs 추론(inference)
💡 weight 갱신 O / X- 학습 : forward → backward
- 추론 : forward
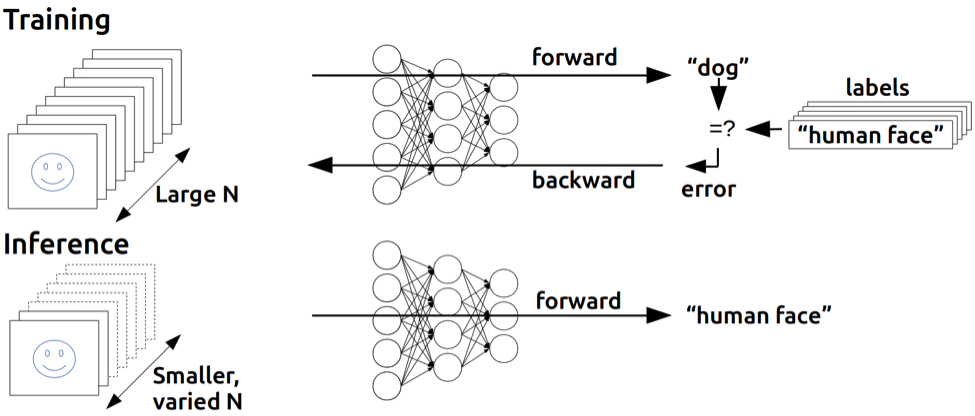
딥러닝 학습/추론과 이에 따른 하드웨어 차이 비교 (tistory.com)
epoch & batch size & iteration
배치(batch)와 에포크(epoch)란? by bskyvision

출처 : 텐서플로우로 배우는 딥러닝 (slideshare.net) , 머신 러닝 - epoch, batch size, iteration의 의미 : 네이버 블로그 (naver.com)
epoch
- 학습(
forward → backward)을 거친 것 - 전체 데이터를 n 번 사용해서 학습
배치 사이즈 batch size
💡 1 `batch` = n of data- batch 한번에 데이터를 몇개를 사용할 것인가.
데이터 묶음의개수정해주기
연필 한다스 / 계란 한판
반복 iteration
- epoch = 전체 데이터셋 사용
전체 데이터가 너무 크니까 나눠서 실행하자
- 전체 데이터 셋을 n등분
- 메모리 (램) 25 GB
- 데이터 100 GB
25 GB 씩 몇번 사용해야 전체 데이터셋 돌릴 수 있지?
- 전체 용량 / 1회 학습량
- 100 GB / 25 GB = 4회
- 4번 반복
과정을 반복
input → model → output → w update
forward → backward
가중치 4번 업데이트됨
전체 데이터셋을 모두 학습에 사용하는 동안 몇번 가중치를 업데이트 할 것인가
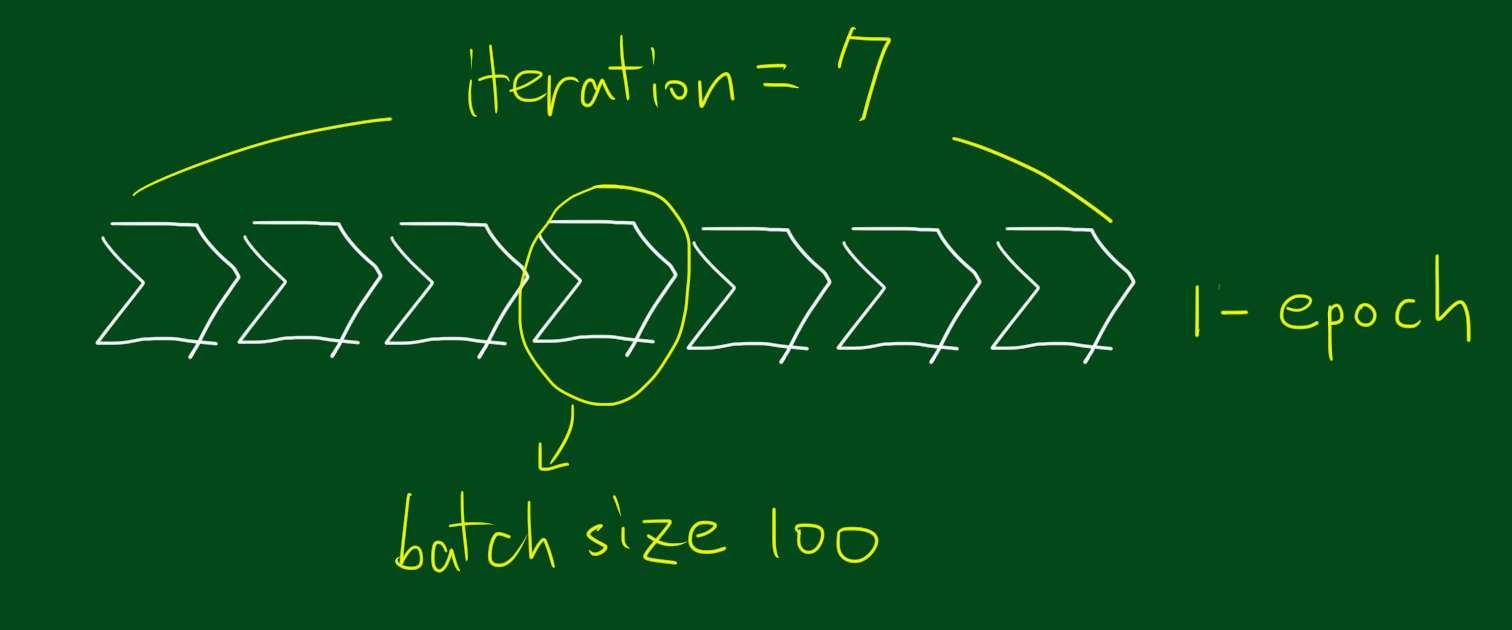
[딥러닝] 에폭(epoch) & 배치 사이즈(batch size) & 반복(iteration) 개념 정리 (tistory.com)
https://losskatsu.github.io/machine-learning/epoch-batch/#4-iteration%EC%9D%98-%EC%9D%98%EB%AF%B8
