
'정석준님 (https://github.com/sjjeong)'께서 주관하는 Kotlin Coroutine 스터디 진행 과정
코틀린 코루틴의 정석 책을 읽고 이해한 내용을 바탕으로 정리하여 글을 작성하였습니다. 부족한 부분이나, 틀린 부분이 있다면 반영할 수 있도록 하겠습니다.
11장 - 코루틴 심화
11-1. 공유 상태를 사용하는 코루틴의 문제와 데이터 동기화
1. 가변 변수를 사용할 때의 문제점
멀티 스레드 환경에서 가변 변수에 동시에 접근해 값을 변경하면 데이터의 손실이나 불일치로 인해 심각한 버그가 발생할 수 있습니다.
코루틴은 주로 멀티 스레드 환경에서 실행되기 때문에 코루틴을 사용할 때도 동일한 문제가 발생할 수 있습니다.
fun main() = runBlocking<Unit> {
var count = 0
withContext(Dispatchers.Default) {
repeat(10_000) {
launch {
count += 1
}
}
}
println("count = $count")
}
/** 결과:
count = 9665
*/위 코드에서는 실제로 var count = 0 가변 변수를 10,000개의 launch 코루틴을 생성하여, 1씩 증감시키는 동작을 하고 있습니다. 여기에서 기대하는 결과 값은 10000 이지만 9965가 나온것을 확인할 수 있습니다. 실제로 실행할 때 마다 다른 결괏값이 나오는 것을 확인할 수 있습니다 (9965, 9032, 8934 등)
왜 이런 문제가 발생할까요? 원인은 크게 두가지로 요약될 수 있습니다.
첫 번째 원인
메모리 가시성 문제 입니다. 메모리 가시성 문제란 스레드가 변수를 읽는 메모리 공간에 관한 문제로 CPU 캐시와 메인 메모리 등으로 이뤄지는 하드웨어의 메모리 구조와 연관 되어있습니다. 스레드가 변수를 변경시킬때 메인 메모리가 아닌 CPU 캐시를 사용할 경우 CPU 캐시의 값이 메인 메모리에 전파되는 데 약간의 시간이 걸려 CPU 캐시와 메인 메모리 간에 데이터 불일치 문제가 생깁니다. 따라서 다른 스레드에서 count 변수의 값을 1000 -> 1001로 변경 시켰는데 변경이 CPU 캐시에만 반영되고 메인 메모리로 전파되지 않았다면 다른 스레드가 count 변수에 접근했을 때 count 변수의 이전 값인 1000을 읽게 됩니다.
두 번째 원인
경쟁 상대 문제 입니다. 2개의 스레드가 동시에 값을 읽고 업데이트 시키면 같은 연산이 두 번 일어납니다. 예를 들어 count 변수에 저장된 값이 1000일때 2개의 스레드가 동시에 count 변수를 읽고 업데이트한다면 count 변수가 1000 -> 1001 되는 연산이 두 번 일어나게 됩니다. 즉, 2개의 코루틴이 값을 1만큼만 증가시키므로 하나의 연산은 손실됩니다.
이 두가지 문제는 멀티 스레드 환경에서 공유 상태를 사용할 때 데이터 동기화 문제를 일으키는 주범입니다.
2. JVM의 메모리 공간이 하드웨어 메모리 구조와 연결되는 방식
멀티 스레드에서 공유 상태를 사용할 때의 데이터 동기화 문제를 이해하기 위해서는 하드웨어상에서 동작하는 가상 머신인 JVM의 메모리 공간이 하드웨어의 메모리 공간과 어떻게 연결되는지 알아야 합니다.
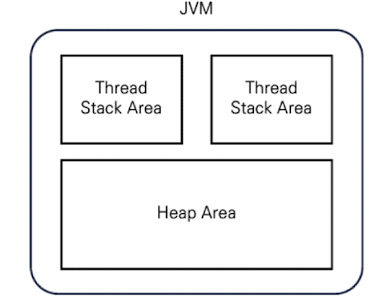
JVM은 위 그림과 같이 스레드마다 스택 영역이라고 불리는 메모리 공간을 갖고 있고, 이 스택 영역에는 원시 타입의 데이터가 저장되거나 힙영역에 저장된 객체에 대한 참조가 저장됩니다. 힙 영역은 JVM 스레드에서 공통으로 사용되는 메모리 공간으로 객체나 배열 같은 크고 복잡한 데이터가 저장됩니다.
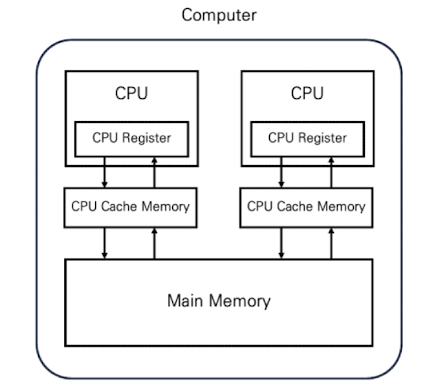
이번에는 JVM이 실행되는 컴퓨터의 메모리 구조에 대해 알아보겠습니다. 컴퓨터는 위 그림과 같이 CPU 레지스터, CPU 캐시 메모리, 메인 메모리 영역으로 구성 됩니다. 각 CPU는 CPU 캐시 메모리를 두며, 데이터 조회 시 공통 영역인 메인 메모리까지 가지 않고 CPU 캐시 메모리에서 데이터를 조회할 수 있도록 만들어 메모리 엑세스 속도를 향상 시킵니다.
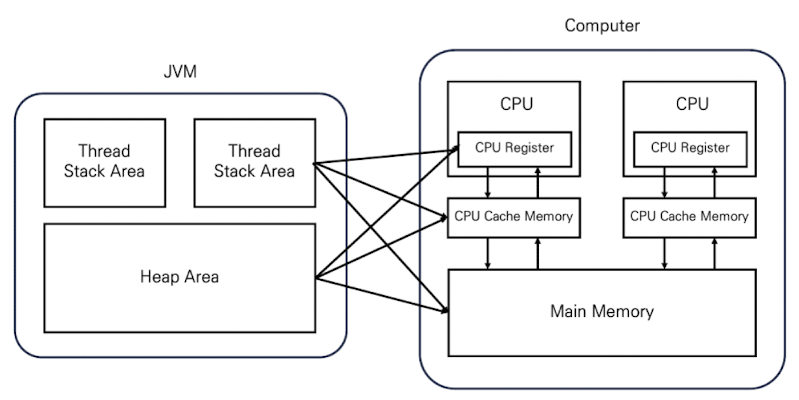
이제 JVM의 메모리 공간인 스택 영역과 힙 영역을 하드웨어 메모리 구조와 연결해보면 위와 같은 그림으로 표현할 수 있습니다. 하드웨어 메모리 구조는 JVM의 스택 영역과 힙 영역을 구분하지 않습니다. 따라서 JVM의 스택 영역에 저장된 데이터들은 CPU 레지스터, CPU 캐시 메모리, 메인 메모리 모두에 나타날 수 있으며, 힙 영역도 마찬가지입니다. 이런 구조로 인해 멀티 스레드 환경에서 공유 상태를 사용할 때 두 가지 문제가 발생합니다.
- 공유 상태에 대한 메모리 가기성 문제
- 공유 상태에 대한 경쟁 상태 문제
3. 공유 상태에 대한 메모리 가시성 문제와 해결 방법
1) 공유 상태에 대한 메모리 가시성 문제
공유 상태에 대한 메모리 가시성 문제란 하나의 스레드가 다른 스레드의 변경된 상태를 확인하지 못하는 것으로 서로 다른 CPU에서 실행되는 스레드들에서 공유 상태를 조회하고 업데이트할 때 생기는 문제 입니다.
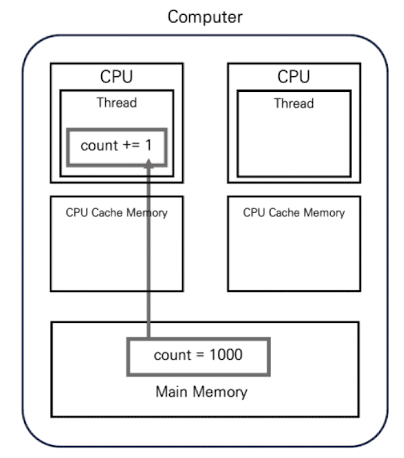
공유 상태는 처음에는 메인 메모리상에 저장돼 있습니다. 이때 하나의 스레드가 이 공유 상태를 읽어오면 해당 스레드를 실행 중인 CPU는 공유 상태를 CPU 캐시 메모리에 저장합니다.
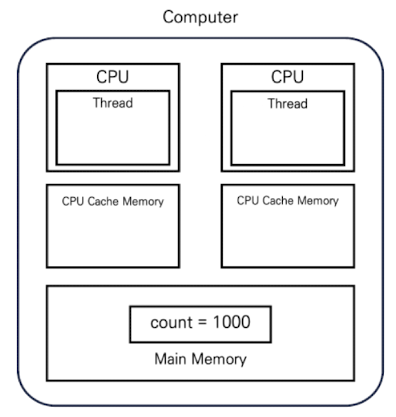
예를 들어 위 그림과 같이 메인 메모리에 count = 1000이라는 상태가 있다고 하고, 스레드가 count 값을 증가시키는 연산을 실행하려고 합니다.
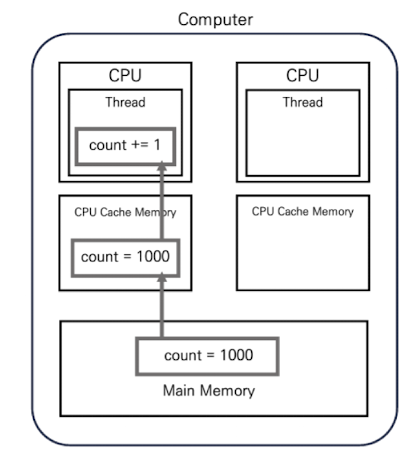
위 그림과 같이 메인 메모리에서 count 값을 읽어오면 CPU 캐시 메모리에는 count = 1000 이라는 정보가 저장되며, 스레드는 이 값을 사용해 count 값을 증가 시키는 연산을 실행합니다.
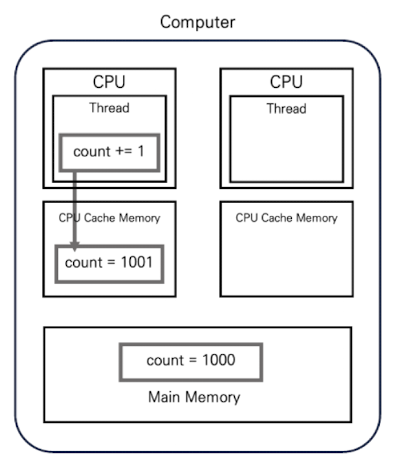
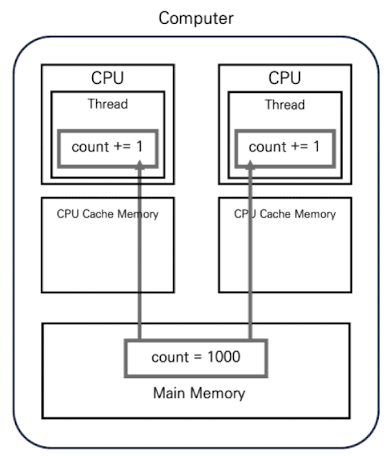
연산이 완료되면 count = 1001이 되지만 스레드는 이 정보를 메인 메모리에 쓰지 않고 CPU 캐시 메모리에 씁니다. CPU 캐시 메모리의 변경된 count 값은 플러시가 일어나지 않으면 메인 메모리로 전파되지 않습니다. 결과적으로 위 그림과 같은 상태가 됩니다.
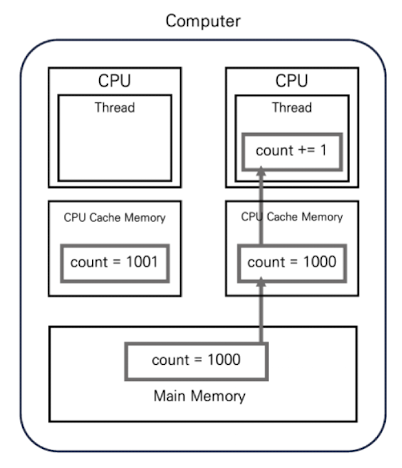
만약 CPU 캐시 메모리의 데이터가 메인 메모리로 전파되지 않은 상태에서 위 그림과 같이 다른 CPU에서 실행되는 스레드에서 count 변수의 값을 읽는 상황을 가정해 본다면 이 스레드는 count 값을 1000으로 인식하게 되며, 이에 대해 count += 1 연산을 실행해 count = 1001을 자신의 CPU 캐시 메모리에 쓰게 됩니다.
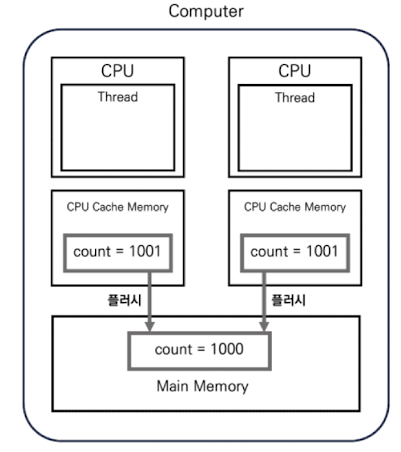
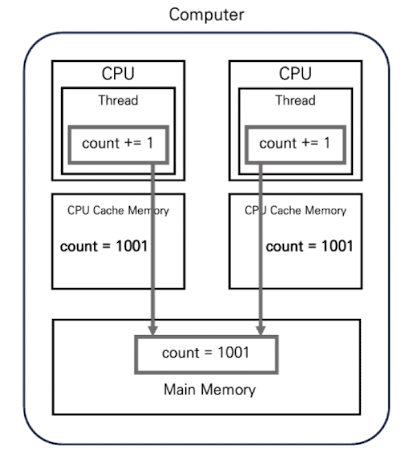
이후 각 CPU 캐시 메모리의 값이 메인 메모리로 플러시가 일어나면 연산은 두 번 일어나지만 위 그림과 같이 count 변수의 값은 하나만 증가하게 됩니다.
이렇게 하나의 스레드에서 변경한 변수의 상태 값을 다른 스레드가 알지 못해 생기는 메모리 동기화 문제를 메모리 가시성 문제라고 합니다.
2) @Volatile 사용해 공유 상태에 대한 메모리 가시성 문제 해결하기
코틀린에서 메모리 가시성 문제를 해결하기 위해서는 다음 코드와 같이 @Volatile 어노테이션을 사용하면 됩니다.
@Volatile
var chapter11Code2Count = 0
fun main() = runBlocking<Unit> {
withContext(Dispatchers.Default) {
repeat(10_000) {
launch {
chapter11Code2Count += 1
}
}
}
println("count = $chapter11Code2Count")
}
/** 결과:
count = 9770
*/@Volatile 어노테이션이 설정된 변수를 읽고 쓸 때는 CPU 캐시 메모리를 사용하지 않습니다.
즉, 각 스레드는 count 변수 값을 변경시키는 데 CPU 캐시 메모리를 사용하지 않고 메인 메모리를 사용합니다.
따라서 스레드에서는 count 변수의 값을 1 증가시키는 연산을 위해 위 그림과 같이 메인 메모리에서 곧바로 count 변수의 값을 조회해 오며, 값에 대한 변경 연산도 메인 메모리에서 수행합니다.
@Volatile 어노테이션을 사용해 메모리 가시성 문제를 해결했지만 여전히 결괏값을 보면 여전히 기대하는 결괏값인 10000이 아닌 더 적은 값이 나오는것을 확인할 수 있습니다. 메인 메모리에서만 count 변수를 변경하더라도 여전히 여러 스레드가 메인 메모리의 count 변수에 동시에 접근할 수 있기 때문입니다.
4. 공유 상태에 대한 경쟁 상태 문제와 해결 방법
1) 공유 상태에 대한 경쟁 상태 문제
여러 슬드가 동시에 하나의 값에 접근하면서 발생하는 문제를 경쟁 상태 문제라고 합니다.
@Volatile 어노테이션을 사용해 위 그림과 같이 메인 메모리의 변수만 사용하였다고 하더라도 여러 스레드에서 동시에 변수값을 읽어서 연산을 한다면 실제로 두 번의 연산이 일어나지만 count 변수의 값은 하나만 증가하게 됩니다.
이런 경쟁 상태 문제를 해결하기 위해서는 하나의 변수에 스레드가 동시에 접근할 수 없도록 만들어야합니다.
2) Mutext 사용해 동시 접근 제한하기
동시 접근을 제한하는 간단한 방법은 공유 변수의 변경 가능 지점을 임계 영역으로 만들어 동시 접근을 제한하는 것 입니다. 코틀린에서는 코루틴에 대한 임계 영역을 만들기 위한 Mutex 객체를 제공합니다. Mutex 객체의 lock 일시 중단 함수가 호출되면 락이 획득 되며, 이후 해당 Mutex 객체에 대해 unlock이 호출돼 락이 해제될 때까지 다른 코루틴이 해당 임계 영역에 진입할 수 없습니다.
@Volatile
var chapter11Code3Count = 0
val chapter11Code3Mutex = Mutex()
fun main() = runBlocking<Unit> {
withContext(Dispatchers.Default) {
repeat(10_000) {
launch {
chapter11Code3Mutex.lock()
chapter11Code3Count += 1
chapter11Code3Mutex.unlock()
}
}
}
println("count = $chapter11Code3Count")
}
/** 결과:
count = 10000
*/위 코드의 결과를 보면 원하는 기댓값인 10000 이 출력되는 것을 확인할 수 있습니다.
Mutex 객체를 사용해 락을 획득한 후에는 꼭 해제해야 합니다. 만약 해제하지 않으면 해당 임계 영역은 다른 스레드에서 접근이 불가능하게 돼 문제를 일으킬 수 있습니다. 위 코드에서는 간단한 코드에서 lock-unlock 쌍을 이루웠기 때문에 문제가 되지 않지만 코드가 복잡해질수록 lock-unlock 쌍을 개발자의 실수를 일으킬 가능성이 커집니다.
@Volatile
var chapter11Code4Count = 0
val chapter11Code4Mutex = Mutex()
fun main() = runBlocking<Unit> {
withContext(Dispatchers.Default) {
repeat(10_000) {
launch {
chapter11Code4Mutex.withLock {
chapter11Code4Count += 1
}
}
}
}
println("count = $chapter11Code4Count")
}
/** 결과:
count = 10000
*/이런 문제 때문에 Mutex 객체를 사용해 임계 영역을 만들 때는 lock-unlock 쌍을 직접 호출하기보다는 withLock 일시 중단 함수를 사용하는것이 안전합니다. withLock을 사용하면 람다식 실행 이전에 lock이 호출되고, 람다식이 모두 실행되면 unlock이 호출돼 안전하게 Mutex 객체를 사용할 수 있습니다.
public suspend fun lock(owner: Any? = null)Mutex의 lock 함수는 suspend fun 입니다. 즉, 일시 중단 함수로써 여러 코루틴에서 lock을 호출 했을 때 이미 다른 코루틴에서 lock을 호출한 상태라면 unlock이 호출될때 까지 스레드를 양보하고 일시 중단 합니다. 이로써 Mutex 객체는 스레드를 양보하여 다른 코루틴과 협력하는 특성을 활용할 수 있도록 합니다.
3) 공유 상태 변경을 위해 전용 스레드 사용하기
스레드 간에 공유 상태를 사용해 생기는 문제점은 복수의 스레드가 공유 상태에 동시에 접근할 수 있기 때문에 일어납니다. 따라서 공유 상태에 접근할 때 하나의 전용 스레드만 사용하도록 강제하면 공유 상태에 동시에 접근하는 문제를 해결할 수 있습니다.
@Volatile
var chapter11Code5Count = 0
val chapter11Code5Dispatcher = newSingleThreadContext("CountCHangeThread")
fun main() = runBlocking<Unit> {
withContext(Dispatchers.Default) {
repeat(10_000) {
launch {
increaseCount()
}
}
}
println("count = $chapter11Code5Count")
}
suspend fun increaseCount() = coroutineScope {
withContext(chapter11Code5Dispatcher) {
chapter11Code5Count += 1
}
}
/** 결과:
count = 10000
*/위 코드에서는 count 변수값을 변경하기 위한 CountChangeThread 스레드만을 사용하는 CoroutineDispatcher 객체를 만들어 사용하도록 했습니다. 따라서 launch 코루틴이 Dispatchers.Default에서 실행 되더라도 변수를 호출할 때는 CountChangeThread 단일 스레드만 사용하므로 결과에는 count = 10000이 나오는 것을 확인할 수 있습니다.
11-2. CoroutineStart의 다양한 옵션들 살펴보기
코루틴에 실행 옵션을 주기 위해 launch나 async 등의 코루틴 빌더 함수의 start 인자로 CoroutineStart 옵션을 전달할 수 있습니다.
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): JobCoroutineStart의 옵션은 아래와 같습니다.
- CoroutineStart.DEFAULT
- CoroutineStart.ATOMIC
- CoroutineStart.UNDISPATCHED
- CoroutineStart.LAZY
- 이 옵션은 코루틴 빌더를 생성하고 바로 코루틴을 실행하지 않도록 하는 옵션입니다.
1. CoroutineStart.DEFAULT
코루틴 빌더의 start 인자로 CoroutineStart.DEFAULT를 사용하면 코루틴 빌더 함수를 호출한 즉시 생성된 코루틴의 실행을 CoroutineDispatcher 객체에 예약하며, 코루틴 빌더 함수를 호출한 코루틴은 계속해서 실행 됩니다.
fun main() = runBlocking<Unit> {
launch {
println("작업1")
}
println("작업2")
}
/** 결과:
작업2
작업1
*/위 코드에서는 launch 함수를 호출 할 때 start 인자로 아무 값도 넘어가지 않았으므로 CoroutineStart.DEFAULT가 적용 됩니다. 따라서 메인 스레드에서 실행되는 runBlocking 코루틴에 의해 launch 함수가 호출되면 메인 스레드를 사용하는 CoroutineDispatcher 객체에 launch 코루틴의 실행이 즉시 예약 됩니다. 하지만 runBlocking 코루틴이 메인 스레드를 양보하지 않고 계속해서 실행되므로 launch 코루틴은 실행되지 못하여, runBlocking 코루틴에 의해 작업2가 출력되고 나서야 launch 코루틴이 실행 됩니다.
이는 코루틴의 매우 일반적인 동작으로 스레드를 양보하기 전까지 스레드를 점유하는 코루틴의 특성과 양보받은 스레드를 사용해 실행되는 코루틴의 특성을 잘 나타내고 있습니다.
2. CoroutineStart.ATOMIC
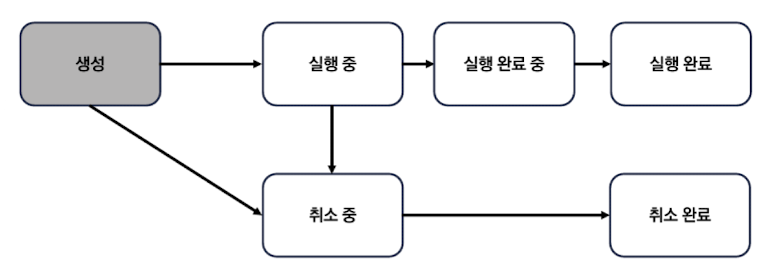
코루틴이 실행 요청됐지만 CoroutineDispatcher 객체가 사용할 수 있는 스레드가 모두 작업중이어서 스레드로 보내지지 않는 경우 코루틴은 생성 상태에 머무는데 이를 실행 대기 상태라고 합니다.
만약 실행 대기 상태의 코루틴이 취소되면 어떤일이 일어날까요? 일반적인 코루틴은 실행되기 전에 취소되면 실행되지 않고 종료 됩니다.
fun main() = runBlocking<Unit> {
val job = launch {
println("작업1")
}
job.cancel()
println("작업2")
}
/** 결과:
작업2
*/위 코드에서는 runBlocking이 스레드를 양보할때 까지 lauch 코루틴은 실행 대기 상태로 머물게 됩니다. runBlocking 코루틴이 완료되기 전에 job.cancel()을 호출하면 작업1은 출력되지 않는것을 확인할 수 있습니다.
하지만 start 인자로 CoroutineStart.ATOMIC 옵션을 적용하면 해당 옵션이 적용된 코루틴은 실행 대기 상태에서 취소되지 않습니다.
fun main() = runBlocking<Unit> {
val job = launch(start = CoroutineStart.ATOMIC) {
println("작업1")
}
job.cancel()
println("작업2")
}
/** 결과:
작업2
작업1
*/위 코드의 실행 결과를 보면 launch 코루틴이 실행 대기 중 상태 일때 취소가 되었지만 정상적으로 실행되는 것을 볼 수 있습니다. 즉, CoroutineStart.ATOMIC 옵션은 코루틴의 실행 대기 상태에서 취소를 방지하기 위한 옵션 입니다.
3. CoroutineStart.UNDISPATCHED
일반적인 코루틴은 실행이 요청되면 CoroutineDispatcher 객체의 작업 대기열에서 대기하다가 CoroutineDispatcher 객체에 의해 스레드에 할당돼 실행 됩니다. 하지만 CoroutineStart.UNDISPATCHED 옵션이 적용된 코루틴은 CoroutineDispatcher 객체의 작업 대기열을 거치지 않고 호출자의 스레드에서 즉시 실행됩니다.
fun main() = runBlocking<Unit> {
val job = launch(start = CoroutineStart.UNDISPATCHED) {
println("작업1")
}
job.cancel()
println("작업2")
}
/** 결과:
작업1
작업2
*/일반적인 코루틴이 생성되고 실행될때의 동작은 사용 가능한 스레드가 생길때 까지 실행 대기 상태에 머물게 됩니다. 하지만 CoroutineStart.UNDISPATCHED 옵션이 적용되면 호출자의 스레드를 점유해서 먼저 실행하게 하고, 실행이 완료 되면 점유한 스레드의 점유를 풀게 됩니다.
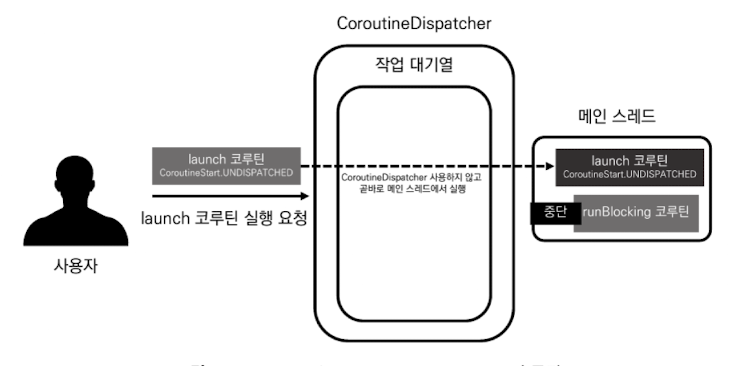
CoroutineStart.UNDISPATCHED가 적용된 코루틴은 CoroutineDispatcher 객체의 작업 대기열을 거치지 않고 곧바로 호출자의 스레드에 할당돼 실행 됩니다. 주의할 점은 처음 코루틴 빌더가 호출됐을 때만 CoroutineDispatche 객체를 거치지 않고 실행된다는 것입니다. 만약 코루틴 내부에서 일시 중단 후 재개되면 CoroutineDispatcher 객체를 거쳐 실행 됩니다.
11-3 무제한 디스패처
1. 무제한 디스패처란?
무제한 디스패처란 코루틴을 자신을 실행시킨 스레드에서 즉시 실행하도록 만드는 디스패처입니다. 이때 호출된 스레드가 무엇이든지 상관없기 때문에 실행 스레드가 제한되지 않으므로 무제한 디스패처라는 이름이 붙여졌습니다.
fun main() = runBlocking<Unit> {
launch(Dispatchers.Unconfined) {
println("launch 코루틴 실행 스레드: ${Thread.currentThread().name}")
}
}
/** 결과:
launch 코루틴 실행 스레드: main
*/이 코드에서 runBlocking 코루틴은 메인 스레드에서 실행되며, runBlocking 코루틴에서 호출되는 launch 코루틴 빌더 함수는 코루틴을 Dispatchers.Unconfined를 사용해 실행합니다. 이때 launch 함수를 호출하는 스레드는 메인 스레드이므로 Dispatchers.Unconfined를 사용해 실행되는 launch 코루틴은 자신을 실행시킨 메인 스레드에서 실행됩니다.
2. 무제한 디스패처의 특징
1) 코루틴이 자신을 생성한 스레드에서 즉시 실행된다.
코루틴이 무제한 디스패처를 사용해 실행되는 것과 제한된 디스패처를 사용해 실행되는 것에는 무슨차이가 있을까요?
fun main() = runBlocking<Unit>(Dispatchers.IO) {
println("runBlocking 코루틴 실행 스레드: ${Thread.currentThread().name}")
launch(Dispatchers.Unconfined) {
println("launch 코루틴 실행 스레드: ${Thread.currentThread().name}")
}
}
/** 결과:
runBlocking 코루틴 실행 스레드: DefaultDispatcher-worker-1
launch 코루틴 실행 스레드: DefaultDispatcher-worker-1
*/이 코드에서는 runBlocking 코루틴이 실행될 때 Dispatchers.IO를 사용하도록 설정하였고, launch 코루틴은 무제한 디스패처를 사용해 실행되도록 하였습니다.
그러면 runBlocking 코루틴은 Dispatchers.IO의 공유 스레드풀의 스레드 중 하나를 사용해 실행되고, 그 내부에서 실행되는 launch 코루틴은 runBlocking 코루틴이 사용하던 스레드를 그대로 사용해 실행되는 것을 출력된 DefaultDispatcher-worker-1 스레드를 통해 확인할 수 있습니다.
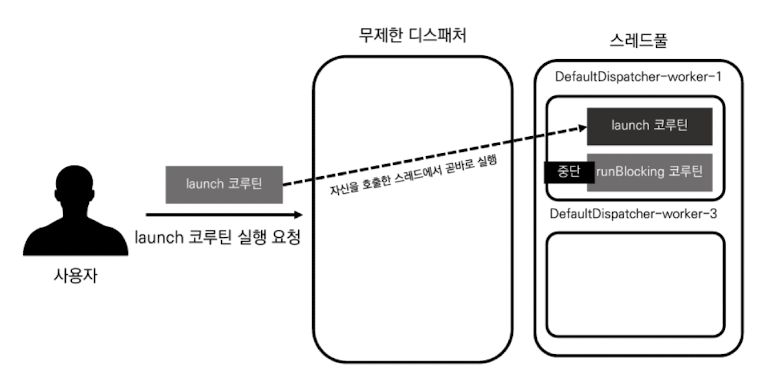
무제한 디스패처를 사용하는 코루틴은 현재 자신을 실행한 스레드를 즉시 점유해 실행되며, 이는 제한된 디스패처를 사용하는 코루틴의 동작과 대조 됩니다.
제한된 디스패처는 코루틴의 실행을 요청 받으면 작업 대기열에 적재한 후 해당 디스패처에서 사용할 수 있는 스레드 중 하나로 보내 실행되도록 합니다.
2) 중단 시점 이후의 재개는 코루틴을 재개하는 스레드에서 한다
무제한 디스패처를 사용해 실행되는 코루틴은 자신을 실행시킨 스레드에서 스레드 스위칭 없이 즉시 실행되지만 일시 중단 전까지만 자신을 실행시킨 스레드에서 실행됩니다. 만약 무제한 디스패처를 사용하는 코루틴이 일시 중단 후 재개된다면 자신을 재개시키는 스레드에서 실행 됩니다.
fun main() = runBlocking<Unit>(Dispatchers.IO) {
launch(Dispatchers.Unconfined) {
println("일시 중단 전 실행 스레드: ${Thread.currentThread().name}")
delay(100L)
println("일시 중단 후 실행 스레드: ${Thread.currentThread().name}")
}
}
/** 결과:
일시 중단 전 실행 스레드: DefaultDispatcher-worker-1
일시 중단 후 실행 스레드: kotlinx.coroutines.DefaultExecutor
*/일시 중단 전에는 launch 함수를 호출한 메인 스레드에서 코루틴이 실행되는 것을 볼 수 있습니다. 하지만 일시 중단 후 재개될 때는 DefaultExecutor라고 불리는 스레드에서 실행되는 것을 확인할 수 있습니다. DefaultExecutor 스레드는 delay 함수를 실행하는 스레드로 delay 함수가 일시 중단을 종료하고 코루틴을 재개할 때 사용하는 스레드 입니다.
11-4 코루틴의 동작 방식과 Continuation
1. Continuation Passing Style
일반적으로 코드가 실행될 때는 코드 라인이 순서대로 실행되는 방식으로 동작하지만 코루틴은 코드를 실행하는 도중 일시 중단하고 다른 작업으로 전환 후 필요한 시점에 다시 실행을 재개하는 기능을 지원합니다. 코루틴이 일시 중단을 하고 재개하기 위해서는 코루틴의 실행 정보가 어딘가에 저장돼 전달되어야 합니다.
코틀린은 코루틴의 실행 정보를 저장하고 전달하는 데 CPS(Continuation Passing Style) 라고 불리는 프로그래밍 방식을 채택하고 있습니다. CPS는 Continuation 을 전달하는 스타일이라는 뜻으로 여기서 Continuation은 이어서 실행해야 하는 작업을 나타냅니다.
CPS를 채택한 코틀린은 코루틴에서 이어서 실행해야 하는 작업 전달을 위해 Continuation 객체를 제공합니다.
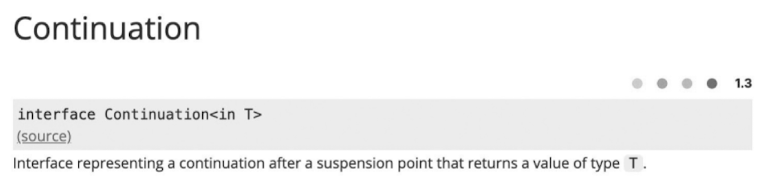

코틀린 문서에서 제공하는 Continuation 인터페이스에 대한 설명은 위와 같습니다.
Continuation 객체는 코루틴의 일시 중단 시점에 코루틴의 실행 상태를 저장하며, 여기에는 다음에 실행해야 할 작업에 대한 정보가 포함 됩니다. 따라서 Continuation 객체를 사용하면 코루틴 재개 시 코루틴의 상태를 복원하고 이어서 작업을 진행할 수 있습니다. 이처럼 Continuation 객체는 코루틴의 실행에 매우 핵심적인 역할을 하고 있습니다.
하지만 Continuation 객체는 코루틴의 실행에 매우 핵심적인 역할을 한다는 표현이 조금 의아할 수 있습니다. 현재까지 코루틴에 대한 것들을 학습하면서 수 많은 코루틴을 일시 중단시키고 재개시켰지만 Continuation 객체를 언급한 적이 없기 때문입니다. 그 이유는 우리가 사용하는 코루틴 API는 모두 고수준 API 이기 때문입니다. 코루틴 라이브러리에서 제공하는 고수준 API는 Continuation 객체를 캡슐화해 사용자에게 노출하지 않지만 내부적으로는 코루틴의 일시 중단과 재개가 Continuation 객체를 통해 이루워지고 있습니다.
우리가 개발을 할 때는 Continuation 객체를 직접 다룰일을 거의 없지만 코루틴이 일시 중단과 재개를 일으키는 방식을 좀 더 깊게 이해하기 위해서는 Continuation 객체가 어떻게 동작하는지 이해하는 것이 필요로 합니다.
2. 코루틴의 일시 중단과 재개로 알아보는 Continuation
코루틴에서 일시 중단이 일어나면 Continuation 객체에 실행 정보가 저장되며, 일시 중단된 코루틴은 Continuation 객체에 대해 resume 함수가 호출돼야 재개됩니다.
fun main() = runBlocking<Unit>(Dispatchers.IO) {
println("runBlocking 코루틴 일시 중단 호출")
suspendCancellableCoroutine<Unit> { continuation: CancellableContinuation<Unit> ->
println("일시 중단 시점의 runBlocking 코루틴 실행 정보 : ${continuation.context}")
}
println("일시 중단된 코루틴이 재개되지 않아 실행되지 않는 코드")
}
/** 결과:
runBlocking 코루틴 일시 중단 호출
일시 중단 시점의 runBlocking 코루틴 실행 정보 : [BlockingCoroutine{Active}@7ddc5191, Dispatchers.IO]
...
*/이 코드에서 runBlocking 코루틴은 일시 중단 호출을 출력하고, suspendCancellableCoroutine 함수를 호출합니다. suspendCancellableCoroutine 함수가 호출되면 runBlocking 코루틴은 일시 중단되며, 실행 정보가 Continuation 객체에 저장돼 suspendCancellableCoroutine 함수의 람다식에서 CancellableContinuation 타입의 수신 객체로 제공됩니다.
결과를 보면 runBlocking 코루틴의 실행 정보를 알 수 있습니다.
public suspend fun delay(timeMillis: Long) {
if (timeMillis <= 0) return // don't delay
return suspendCancellableCoroutine sc@ { cont: CancellableContinuation<Unit> ->
// if timeMillis == Long.MAX_VALUE then just wait forever like awaitCancellation, don't schedule.
if (timeMillis < Long.MAX_VALUE) {
cont.context.delay.scheduleResumeAfterDelay(timeMillis, cont)
}
}
}우리가 delay 함수를 호출하면 suspendCancellableCoroutine이 호출되며, scheduleResumeAfterDelay 함수를 통해 일정 시간 이후에 Continuation 객체를 재개시키는 방식으로 동작하는 것을 확인할 수 있습니다. 이 처럼 Continuation 객체는 코루틴의 일시 중단 시점에 코루틴의 실행 정보를 저장하며, 재개 시 Continuation 객체를 사용해 코루틴의 실행을 복구할 수 있습니다.
3. 다른 작업으로부터 결과 수신해 코루틴 재개하기
코루틴 재개 시 다른 작업으로부터 결과를 수신받아야 하는 경우에는 suspendCancellableCoroutine 함수의 타입 인장에 결과로 반환받는 타입을 입력하면 됩니다.
fun main() = runBlocking<Unit>(Dispatchers.IO) {
val result = suspendCancellableCoroutine<String> { continuation: CancellableContinuation<String> ->
thread {
Thread.sleep(1000L)
continuation.resume("실행 결과")
}
}
println(result)
}
/** 결과:
실행 결과
*/thread 함수가 새로운 스레드에서 코드 블록이 실행되도록 만들어 1초간 대기 후 continuation에 대한 resume을 실행 결과와 함꼐 호출하면 이 값은 result에 할당되고 runBlocking 코루틴이 재개됩니다.
