AlgoExpert
1.Caesar Cipher Encryptor

주어진 문자는 오직 소문자만 존재하고, 주어진 키 값 만큼 shift 시켜 원래의 데이터 타입인 문자로 리턴하는 함수. 얼마만큼 shift 할지 변환하기 위해 키를 26으로 나누고 남은 값을 구하고, 해당하는 문자를 숫자로 represent 하는 함수로 바꾸고 그 키
2.Run-Length Encoding
쉬워보이지만, 이런 문제는 집중력이 필요하다. 숫자값을 문자를 \* 를 이용하여 곱할수 있다는것을 배웠다.
3.Common Characters
주어진 모든 문자열이 갖는 공통된 문자를 찾고 리스트로 리턴 하는 함수 구현 문제이다. 이문제를 처음 봤을때 어떤 단어를 기준으로 하여 루프를 돌려야 하나 고민했지만, 사실 아무 단어를 기준으로 하여도 상관이 없다 제목을 보면 왜인지 알 수 있다. 공통된 문자를 찾는
4.Semordnilap
input: "dog", "god"output: \[ "dog", "god"]version \`\`\`def semordnilap(words): pairSet = set() def semordnilap(words): result = \[]
5.Group Anagrams
6.Find Closest Value in BST

리컬시브를 사용하기 위해 헬퍼 함수가 필요할것이고, 결과값이 타겟값과 가장 가까운 값이고 리턴 값이므로 헬퍼함수의 파라미터에 넣어줘야 값이 바뀔때마다 업데이트 할것이다. 현재값과 타겟값의 차이와 가장 가까운값과 타겟값의 차이를 비교하여 현재값과 타겟값이 더 작다면 가까
7.BST Traversal

inorder,preorder,postorder 순서를 아느냐 물어보는 문제 같다. 먼저 리컬시브는 멈춰야하는 구간이 있어야 무한으로 작동하지 않는데, tree == None 일때 리턴해주고 아니경우에는 순서에따라 (인오더인경우: 왼쪽 -> 어레이 출력 -> 오른쪽)
8.Find Kth Largest Value in BST
내가 생각한 방법은 인오더 traversal 을 해서 정렬시키면 크기가 작은것부터 큰것으로 배열될것이고, k번째 큰 원소값을 리턴하는것이므로 큰것부터 작은것으로 재배열시켜 k-1번째로 리턴하면되는것이다. 이방법외에는 다른 방법이 생각 나지 않았다.
9.Branch Sums
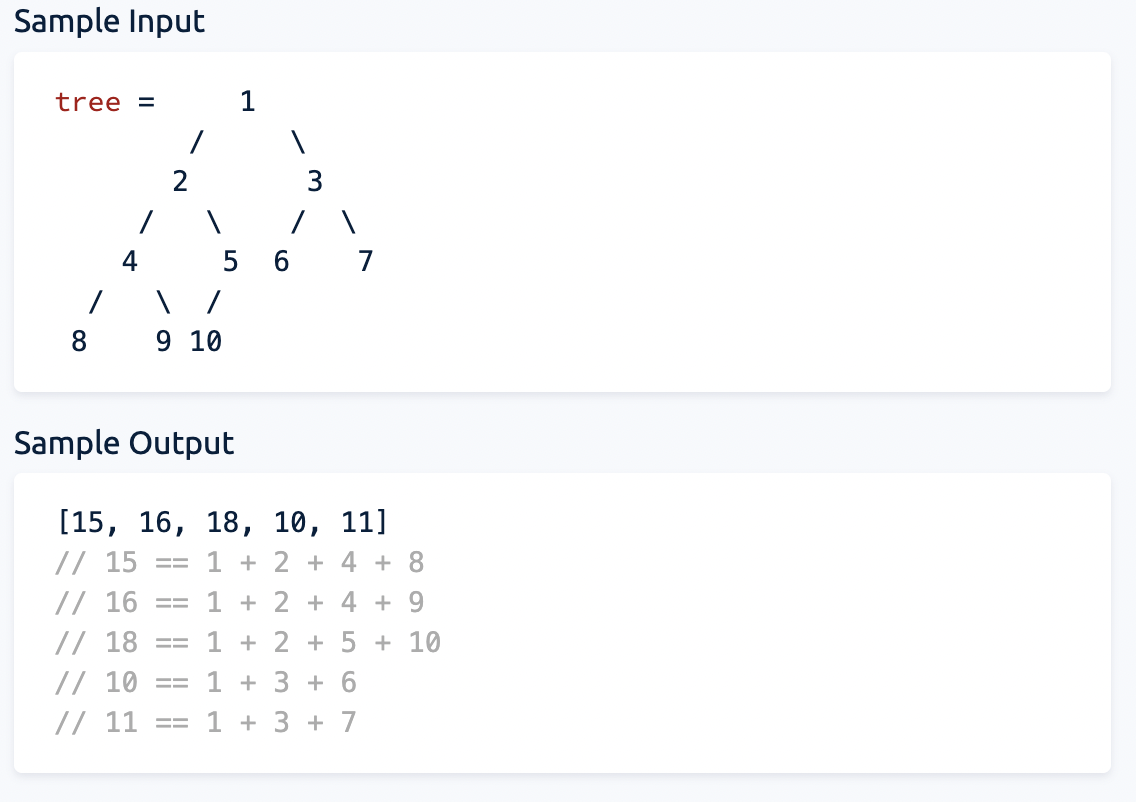
10.Node Depths
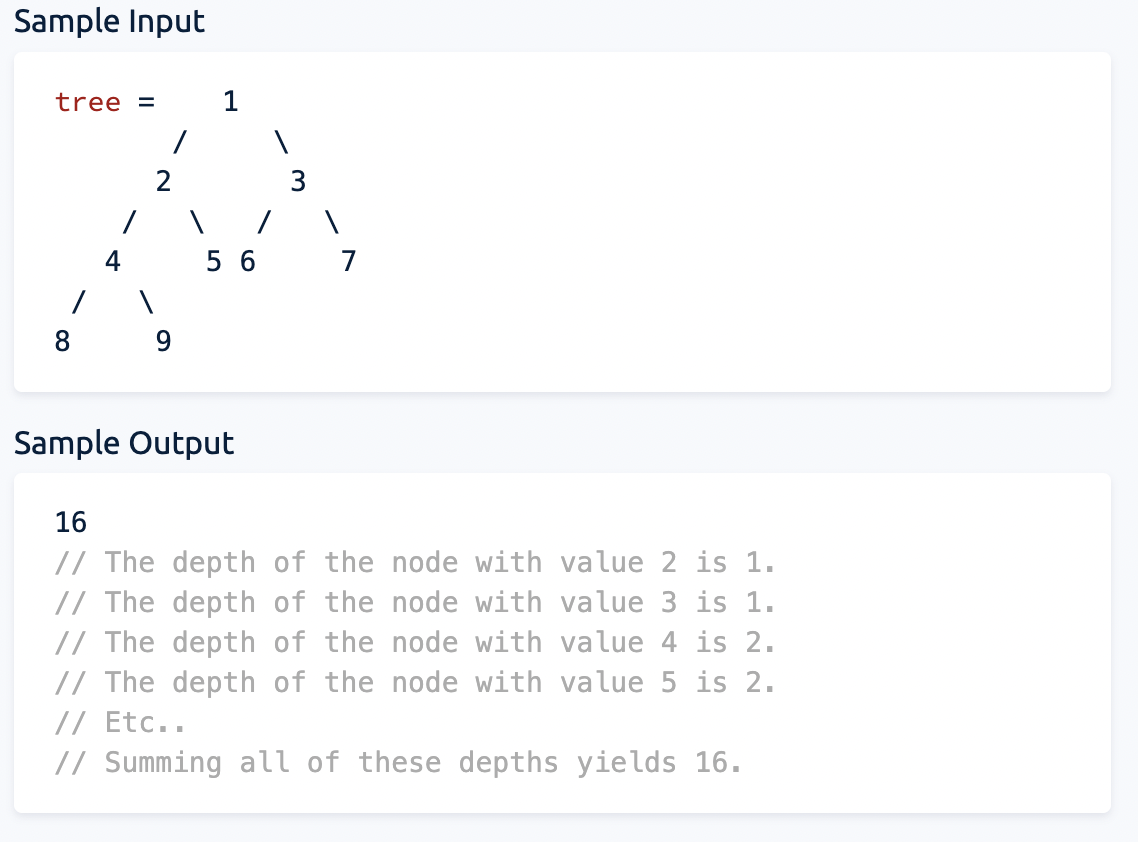
11.Evaluate Expression Tree
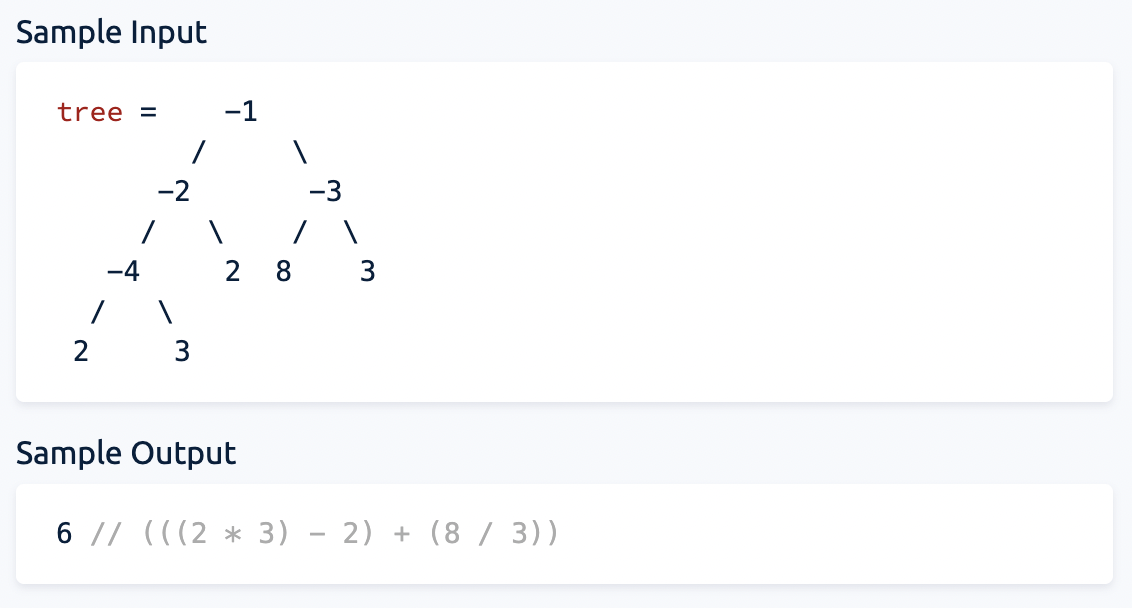
bottom-up 보다는 직관적으로 이해하기 쉬운 top-down recursive 문제다. 탑-다운 인지 바톰-업 인지 보이면 그 다음부터는 수월하다. 어떤 숫자가 어떤 연산자에 해당하는지 주의하여 if elif 를 차례로 나열한다. 연산자는 current tree'
12.Invert Binary Tree

recursive가 좋은점은 코드가 엄청 간결해질수 있다. 여기서 큐 또는 스텍 순서는 별로 상관 없는듯 하다.
13.Symmetrical Tree
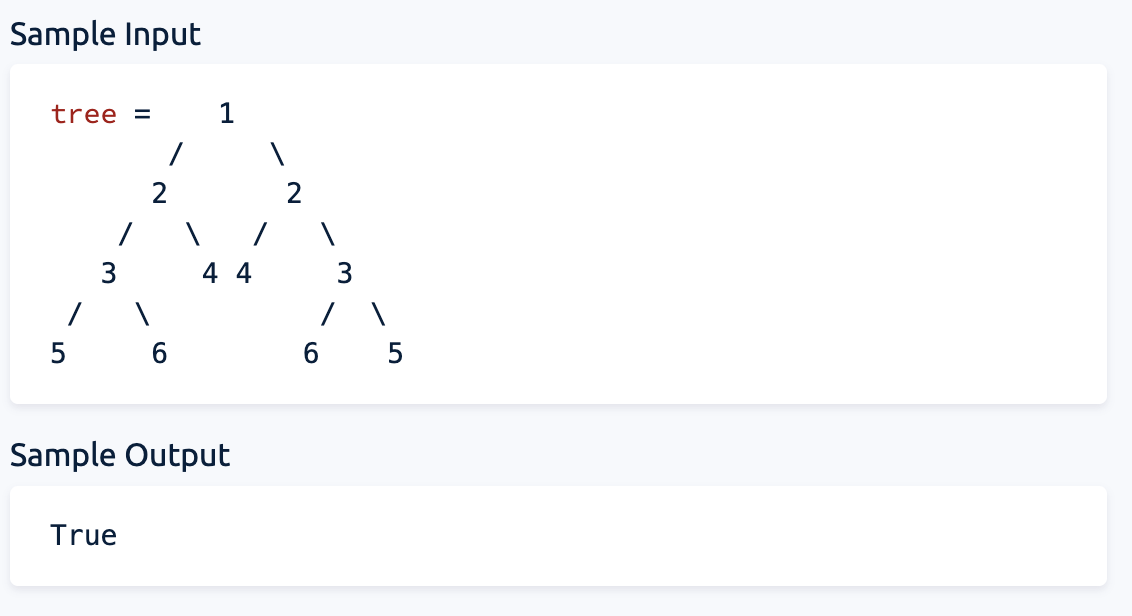
recursive 방법으로는 아직 방법이 떠오르지 않아 구현하지 못하였다. 시간 날때 해보자.
14.Binary Tree Diameter
글로벌을 쓸수 있을때글로벌 쓸수 없을때
15.Height Balanced Binary Tree
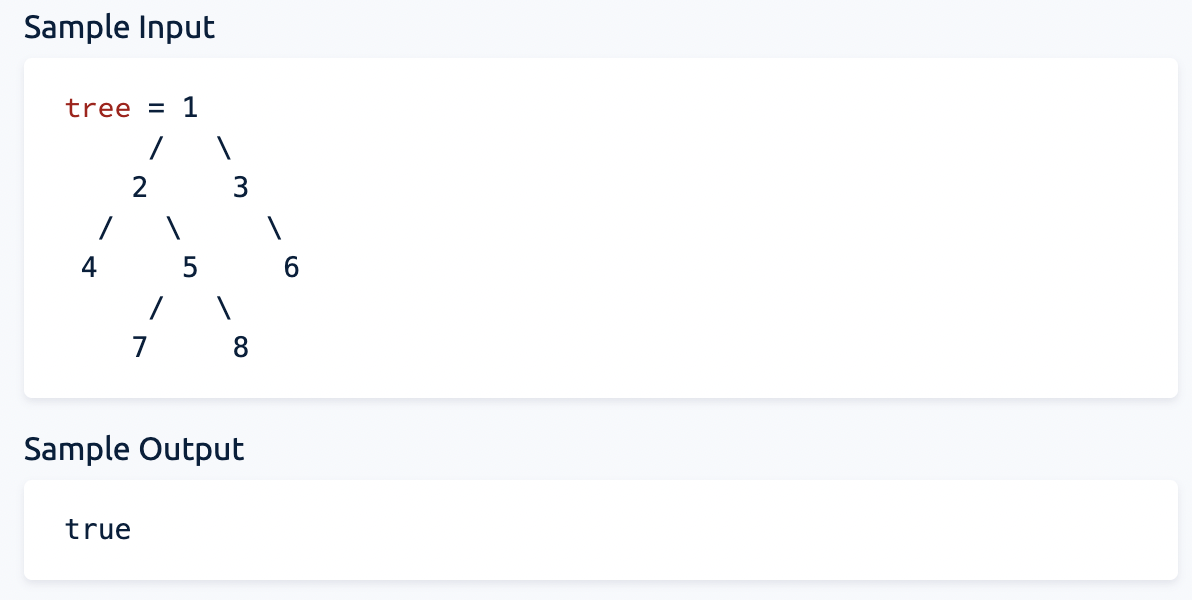
16.Minimum Characters For Words

모든 단어의 캐릭터에 대한 로컬해시를 만들고 로컬해시의 가치값을 이용해 글로벌 해시를 업데이트 한다. 글로벌 해시를 돌면서 가치값이 있다면, 해당하는 키를 결과 어레이에 append 하므로 hash.keys() 가 아닌 hash.items() 이라는것.
17.Longest Substring Without Duplication
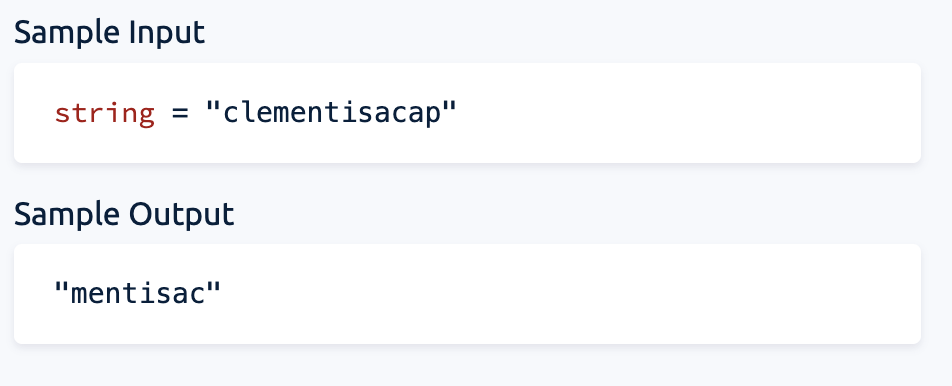
알고리즘 - 해시 이유 - 각각의 캐릭터에 해당하는 인덱스 넘버가 필요하다 (캐릭터:인덱스) TODO: longest substring 언제 업데이트 해야하는지, duplicate 발견했을때 어떻게 다루어야 하는지(새로 시작하려면 시작포인터를 업데이트 해야하는지, 한다
18.베스트앨범
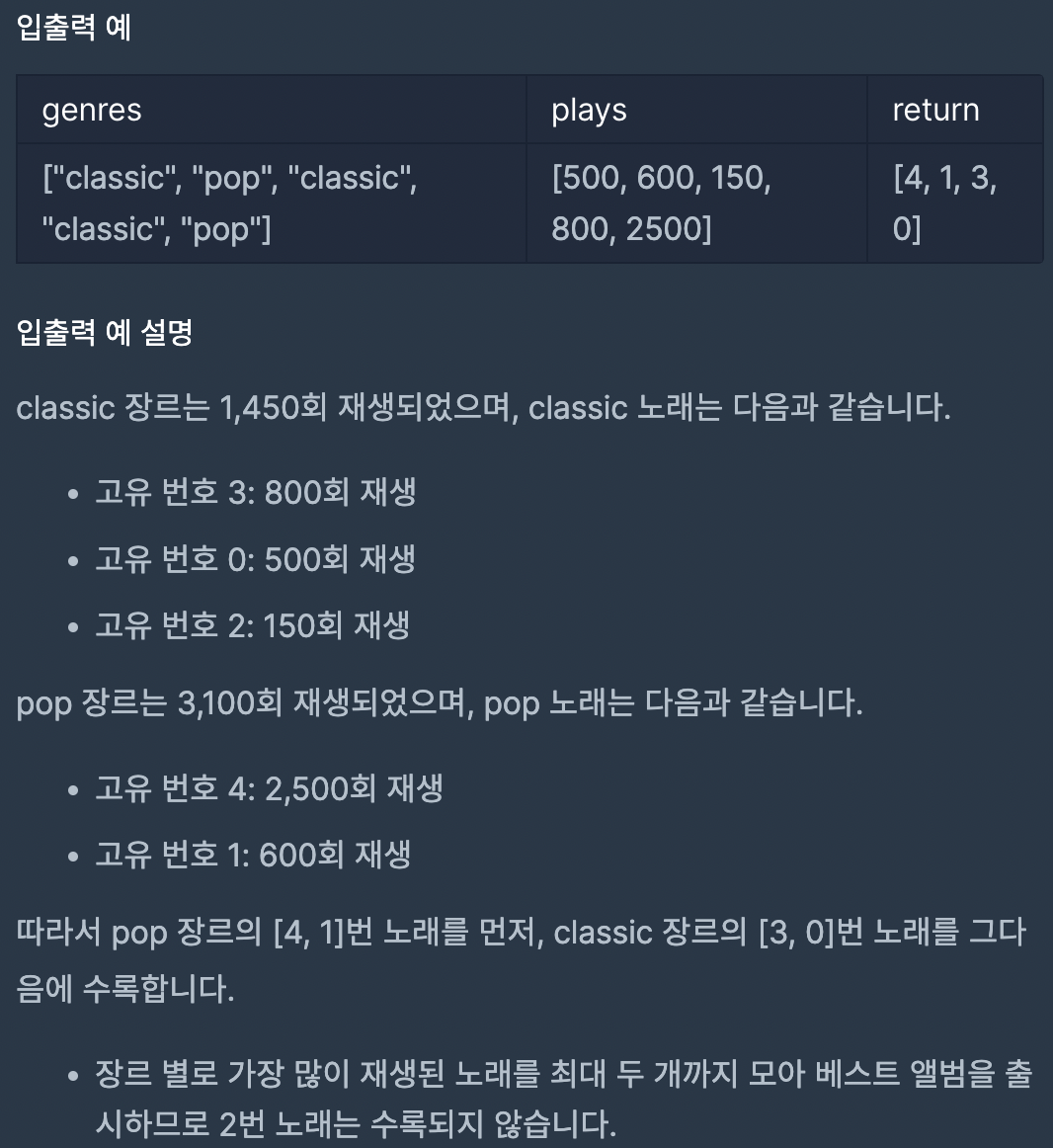
19.River Sizes

20.sort K-SortedArray
