
데이터베이스에 데이터를 관리하려면 SQL을 사용해야 한다. 초기에 자바 애플리케이션은 JDBC API를 사용해서 SQL을 데이터베이스에 전달했는데, 그러면 자바 개발자는 SQL을 능숙하게 다룰 줄 알아야 했을 것이다.
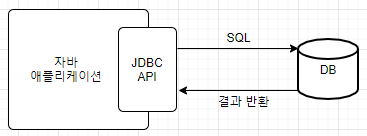
이 장은 주로 SQL를 직접 다루면 어떤 문제점이 있는지, 그리고 JPA는 각 문제를 어떻게 해결해 주는지 알려준다. 먼저 문제점을 설명하고 이를 어떻게 해결하는지 알아보자.
SQL을 직접 다룰 때 발생하는 문제점
1. 반복
반복. 어떤 것을 반복한다는 뜻일까? CRUD 기능을 만들면서 예를 들어보자. Member 객체가 있다.
public class Member {
private String memberId;
private String name;
// ...
}이를 조회하는 MemberDAO가 있다.
public class MemberDAO {
public Member find(String memberId) {
//...
}
}함수를 완성시킨다면 다음과 같은 순서로 진행될 것이다.
// 조회 SQL
String sql = "SELECT MEMBER_ID, NAME FROM MEMBER M WHERE MEMBER_ID = ?";
// SQL 실행
rs = stmt.executeQuery(sql);
// 객체로 매핑
String memberId = rs.getString("MEMBER_ID");
String name = rs.getString("NAME");
Member member = new Member();
member.setMemberId(memberId);
member.setName(name);
// ...아직 문제가 없어 보인다. 그럼 계속 Member를 등록하는 기능도 작성해보자.
public class MemberDAO {
public Member find(String memberId) {
//...
}
public void save(Member member) {
//...
}
}아까 find() 메서드에서 SQL을 작성하고, 실행하고 매핑하는 과정을 다시 해야 한다. 이것은 수정이나 삭제를 할 때도 마찬가지다. 이런 비슷한 작업을 반복해야 할 것이다. 테이블이 100개면 이러한 비슷한 작업을 100번 하는 것이다. 얼마나 반복적인 일인가.
또한, 데이터베이스는 객체 구조와는 다른 데이터 중심의 구조로 되어 있기에 객체를 데이터베이스에 직접 저장하거나 조회할 수 없다.
2. SQL에 의존적인 개발
결국, Member를 관리(CRUD)하는 MemberDAO를 만들었다고 하자. 하지만 요구사항이 추가될 수도 있지 않을까? 회원의 연락처도 함께 저장해달라는 요구사항이 추가되었다고 생각해보자.
먼저 Member 객체를 수정해야 할 것이다.
public class Member {
private String memberId;
private String name;
private String tel; // 추가
// ...
}그러면 만들어 놓았던 MenberDAO도 수정이 필요하다. find()로 예를 들어 보자.
// 조회 SQL
String sql = "SELECT MEMBER_ID, NAME, TEL FROM MEMBER M WHERE MEMBER_ID = ?"; // SQL 변경
// SQL 실행
rs = stmt.executeQuery(sql);
// 객체로 매핑
String memberId = rs.getString("MEMBER_ID");
String name = rs.getString("NAME");
String tel = rs.getString("TEL"); // 추가
Member member = new Member();
member.setMemberId(memberId);
member.setName(name);
member.setTel(tel); // 추가
// ...이러한 과정을 추가, 수정도 마찬가지로 해야 할 것이다.
이번엔 다른 예시를 들어보자. 연관된 객체를 추가하면 어떻게 될까? Member는 어느 한 Team에 소속할 수 있는 요구사항이 추가되었다고 생각해보자.
public class Member {
private String memberId;
private String name;
private String tel;
private Team team; // 추가
// ...
}
public class Team {
private String teamId;
private String teamName;
// ...
}그럼 소속 팀의 이름을 조회하려면 어떻게 해야할까?
member.getTeam().getTeamName();이렇게 하면 요구사항을 만족한 것일까? 아니다. MemberDAO의 find() 메서드에 SQL("SELECT MEMBER_ID, NAME, TEL FROM MEMBER M WHERE MEMBER_ID = ?")을 보면 Team을 조회하는 SQL문이 없다. 따라서 find()의 SQL을 다시 수정해야 한다.
SELECT M.MEMBER_ID, M.NAME, M.TEL, T.TEAM_ID, T.TEAM_NAME
FROM MEMBER M
JOIN TEAM T
ON M.TEAM_ID = T.TEAM_ID여기서는 생략했지만, 객체로 매핑하는 과정도 추가된다. 이렇게 되면 개발자는 요구사항이 추가 될 때마다 매번 DAO를 열어 코드를 확인하고 수정해야 할 것이다.
이처럼 SQL에 모든 것을 의존하는 상황에서 개발자들은 엔티티를 신뢰하고 사용할 수 없다. DAO에서 어떤 SQL이 실행되고 어떤 객체들이 함께 조회되는지 일일이 확인해야 한다. 이런 강한 의존관계 때문에 필드를 하나 추가할 때도 DAO의 대부분을 변경해야 하는 문제가 발생한다.
요약하면 이러하다.
- 진정한 의미의 계층 분할이 어렵다.
- 엔티티를 신뢰할 수 없다.
- SQL에 의존적인 개발을 피하기 어렵다.
패러다임의 불일치
1. 상속
객체는 상속이라는 기능이 있지만, 테이블은 없다.
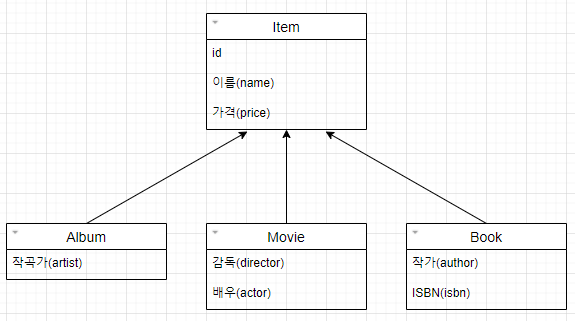
그나마 데이터베이스 모델링에서 이야기하는 슈퍼타입 서브타입 관계를 사용하면 객체 상속과 유사한 형태로 테이블을 설계할 수 있다.

그림을 참고하여 코드를 만들어보자.
abstract class Item {
Long id;
String name;
int price;
}
class Album extends Item {
String artist;
}
class Movie extends Item {
String director;
String actor;
}
class Book extends Item {
String author;
String isbn;
}만약 데이터베이스에 저장하려면 어떻게 해야 할까? Item을 상속받고 있는 Album 객체를 예시로 Album 객체를 저장하려면 두 SQL을 만들어야 한다.
INSERT INTO ITEM ...
INSERT INTO ALBUM ...다른 객체도 마찬가지다. 이러면 부모 객체에서 부모 데이터만 꺼내서 ITEM용 INSERT SQL과 자식 객체에서 자식 데이터만 꺼내서 ALBUM용 INSERT SQL를 작성해야 한다. 그러면 코드량이 많아지지 않을까? 그리고 자식 타입에 따라서 DTYPE도 저장해야 한다.
조회하는 것도 쉬운 일은 아니다. 만약 Album을 조회한다면 ITEM과 ALBUM을 조인해서 조회한 후 Album 객체를 생성해야 한다.
2. 연관관계
- 객체 - 참조를 사용하여 연관관계를 가지고 있는 객체에 접근하여 조회
- 테이블 - 외래 키를 사용하여 연관관계를 가지고 있는 테이블을 조인하여 조회
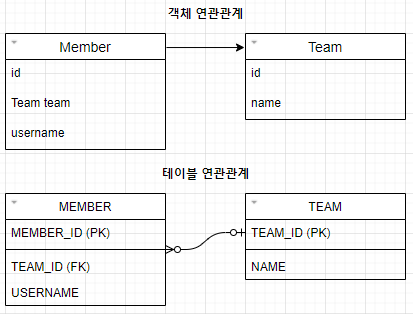
위 그림과 같이 연관관계를 가지고 있다고 하자.
class Member {
Team team;
// ...
Team getTeam() {
return team;
}
}
class Team {
// ...
}Member 객체는 Team을 참조하고 있기 때문에 Member 객체에서 Team 객체를 조회 할 수 있다.
member.getTeam(); // member -> team 접근그럼 MEMBER 테이블은 어떻게 조회할까? MEMBER 테이블과 TEAM 테이블을 조인하면 조회할 수 있다.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_ID여기서 둘의 차이점을 이야기하면 객체에서는 member -> team가 가능하지만 team -> member는 참조가 없기 때문에 불가능하다. 하지만 테이블은 외래 키로 MEMBER JOIN TEAM과 TEAM JOIN MEMBER 둘 다 가능하다.
만약 객체를 테이블에 맞춰 모델링하면 어떨까?
class Member {
String id;
Long teamId; // TEAM_ID FK 컬럼 사용
String username;
}
class Team {
Long id;
String name;
}하지만 이러면 Team을 참조할 수 없다. 관계형 데이터베이스는 조인이라는 기능이 있어서 외래 키를 사용하여 참조할 수 있지만, 객체는 Team 객체를 참조하고 있어야 member.getTeam()이 가능하다. 이렇게 관계형 데이터베이스 형식에 맞추면 연관된 객체를 참조하기 어려워진다.
그러면 Member가 Team을 참조하고, 데이터베이스에 저장할 때 Team의 id를 가져와 저장하면 해결되지 않을까? 물론 해결되지 않는다. 왜일까? 지금까지 작성한 것을 토대로 MemberDAO의 find() 메서드를 작성해보자.
먼저 SQL문은 이렇게 작성될 것이다.
SELECT M.*, T.*
FROM MEMBER M
JOIN TEAM T ON M.TEAM_ID = T.TEAM_IDfind() 메서드는 어떨까?
public Member find(String memberId) {
// SQL 실행
// ...
// 데이터베이스에서 조회한 Member 관련 정보를 모두 입력
Member member = new Member();
// ...
// 데이터베이스에서 조회한 Team 관련 정보를 모두 입력
Team team = new Team();
// ...
// 회원과 팀 관계 설정
member.setTeam();
return member;
}많이 생략했지만, 결과적으로 코드량이 많아진다. 이렇게 패러다임 불일치를 해결하고자 코드를 작성하는 것도 비용된다.
3. 객체 그래프 탐색
객체 그래프 탐색은 이전 예시처럼 객체에서 소속된 팀을 조회할 때 member.getTeam() 같은 것을 말한다.
다음과 같이 연관관계를 가지고 있다고 해보자.
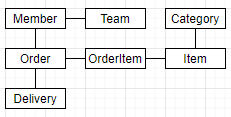
어떻게 Member에서 Item를 객체 그래프 탐색할까? 다음과 같이 할 것이다.
member.getOrder().getOrderItem().getItem();근데 과연 작성한 find() 메서드로 이런 객체 그래프 탐색이 가능할까? 불가능하다. 작성한 SQL에는 MEMBER와 TEAM에 대한 데이터만 조회했기 때문이다. SQL을 직접 다룬다면 처음 실행하는 SQL에 따라 객체 그래프를 어디까지 탐색할 수 있는지 정해진다.
이렇게 SQL에 종속되어있으면 어떤 문제점이 있을까? 그럼 한 번에 전부 조회할까? Member를 조회하기 위해 SQL로 모든 데이터를 조회하는 것은 현실성 없을 것이다. 따라서 우리는 필요에 따라 필요한 데이터를 조회해야 한다. 그러면 Member 조회하는 메서드를 여러 개 만드는 일이 벌어질 수 있다.
memberDAO.getMember(); // Member만 조회
memberDAO.getMemberWithTeam(); // Member와 Team 조회
memberDAO.getMemberWithOrder(); // Member와 Order 조회4. 비교
데이터베이스는 기본 키의 값으로 각 row를 구분한다. 반면 객체는 "=="와 "equals()"로 구분한다. 두 개의 차이는 무엇일까?
- 동일성 비교 ==, 주소 값을 비교한다.
- 동등성 비교 equals(), 객체 내부의 값을 비교한다.
그럼 어떤 문제가 있을까? 이전 find()를 사용해보자.
String memberId = "100";
Member member1 = memberDAO.find(memberId);
Member member2 = memberDAO.find(memberId);과연 member1 == member2는 같을까? false이다. 둘은 데이터베이스에서 같은 row이다. 하지만 객체 측면에서는 find()를 실행할 때마다 new Member()로 새로운 인스턴스가 생성된다. 따라서 조회할 때마다 주소 값이 바뀐다.
JPA란 무엇인가?
JPA(Java Persistance Api)는 자바 진영의 ORM(객체와 관계형 데이터베이스를 매핑한다는 뜻) 기술 표준이고, 애플리케이션과 JDBC 사이에서 동작한다.
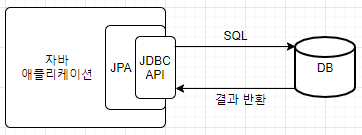
JPA가 앞서 말한 SQL을 직접 다룰 때 발생하는 문제점, 패러다임의 불일치를 해결해주는 것이다.
1. JPA 소개
역사는 이러하다. 과거 자바 진영에 엔터프라이즈 자바 빈즈(EJB)라는 기술 표준을 만들었는데, 너무 복잡하고 기술 성숙도도 떨어지고 자바 엔터프라이즈(J2EE) 애플리케이션 서버에서만 동작했다.
이때 하이버네이트가 등장했다. 하이버네이트는 EJB와 비교해서 가볍고 실용적이고 기술 성숙도도 높고, 자바 엔터프라이즈 애플리케이션 서버 없이도 동작했다.
많은 개발자가 사용하자 EJB 3.0에서 하이버네이트를 기반으로 새로운 자바 ORM 기술 표준을 만들었는데 이게 JPA다.
2. 왜 JPA를 사용해야 하는가?
생산성
JPA를 사용하면 반복적인 코드와 CRUD의 SQL을 개발자가 직접 작성하지 않아도 된다.
jpa.persist(member); // 저장
Member member = jpa.find(memberId); // 조회 유지보수
SQL에 의존하고 있으면 엔티티에 필드 하나만 추가해도 CRUD SQL과 결과를 매핑하기 위한 코드를 모두 수정해야 했다. 반면 JPA를 사용하면 JPA가 대신 처리해주기 때문에 수정해야 할 코드가 줄어든다.
패러다임의 불일치 해결
JPA를 사용하면 위(패러다임의 불일치 해결)에서 설명한 4가지 문제점들을 해결해준다. 자세한 내용은 책을 공부하면서 알아보자.
성능
String memberId = "100";
Member member1 = jpa.find(memberId);
Member member2 = jpa.find(memberId);같은 회원을 2번 조회하는 코드이다. JDBC API를 사용했다면 데이터베이스와 두 번 통신했을 것이다. 하지만 JPA를 사용하면 조회한 Member 객체를 재사용하기 때문에 한 번 통신한다. (이는 영속성과 관련 있다. 해당 책의 3장에 있다.)
데이터 접근 추상화와 벤더 독립성
관계성 데이터베이스는 같은 기능도 벤더마다 사용법이 다른 경우가 많다. 그러면 각각 사용법을 배워야 하나? 그러면 또 데이터베이스에 종속되지 않나? JPA는 애플리케이션과 데이터베이스 사이에 추상화된 데이터 접근 계층을 제공해서 애플리케이션이 특정 데이터베이스 기술에 종속되지 않도록 한다.
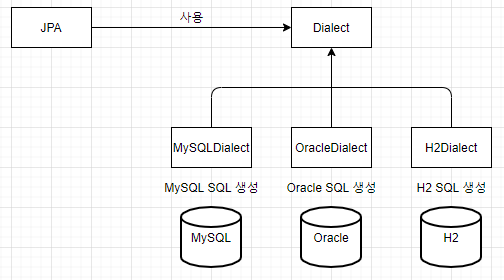
표준
JPA는 자바 진영의 ORM 기술 표준이다. 표준을 사용하면 다른 구현 기술로 손쉽게 변경할 수 있다.
