
데이터 읽기
Pandas
- Python에서 R 만큼의 강력한 데이터 핸들링 성능을 제공하는 모듈
- 단일 프로세스에서는 최대 효율
- 코딩 가능하고 응용 가능한 엑셀로 받아들여도 됨
- 누군가는 스테로이드를 맞은 엑셀로 표현함
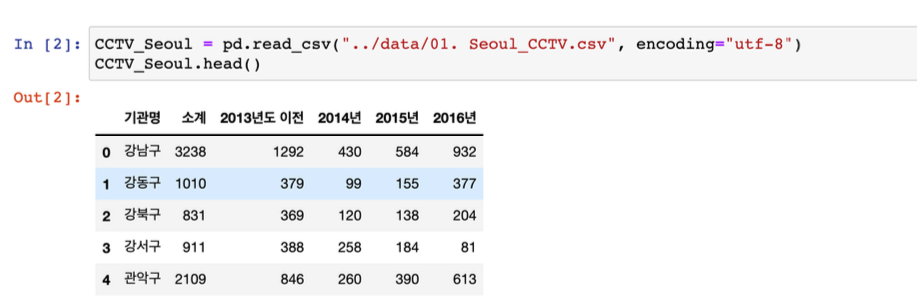
Pandas DataFrame
- column의 이름을 조회할 수 있다.

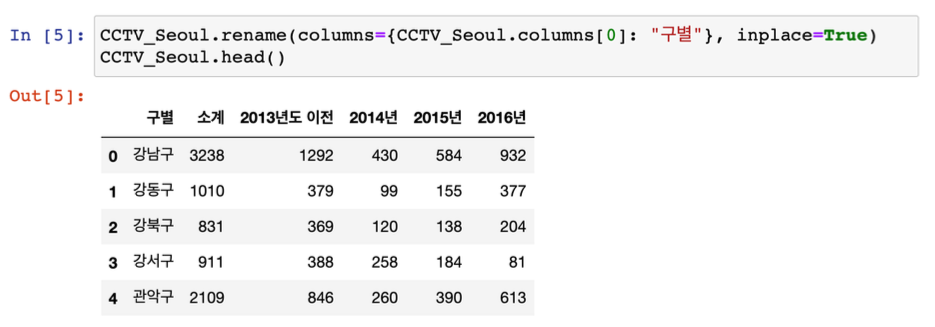
- 컬럼 이름 변경
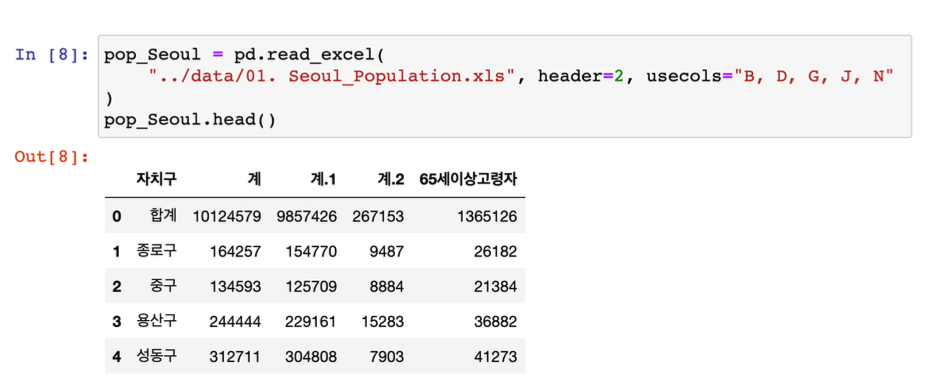
- 자료를 읽기 시작할 행(header)를 지정
- 읽어올 엑셀의 컬럼을 지정(usecols)
Pandas Basic
- pandas는 통상 pd로 import 하고
- 수치해석적 함수가 많은 numpy는 통상 np로 import 한다.

- pandas의 데이터형을 구성하는 기본은 Series이다.

- 날짜(시간)를 이용할 수 있다.

- Pandas에서 가장 많이 사용되는 데이터형은 DataFrame이다.
- index와 colums를 지정하면 된다.
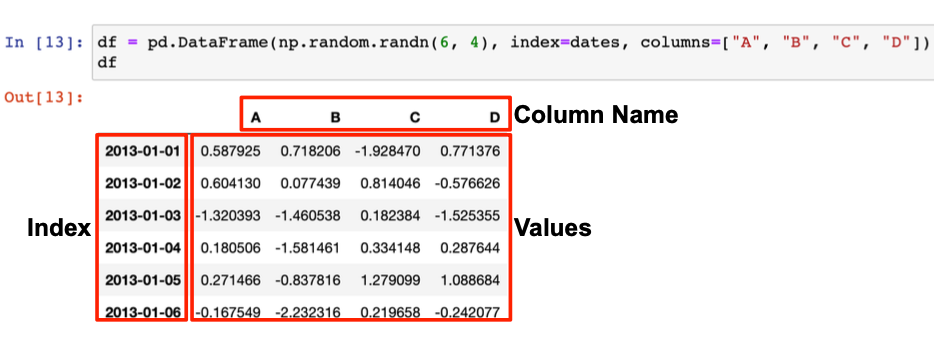
- 데이터 확인: df.head() / df.tail() default=5
- DataFrame의 index 확인: df.index
- DataFrame의 컬럼 확인: df.columns
- DataFrame의 value 확인: df.values
- DataFrame의 기본정보 확인: df.info() ➔ 여기서는 각 컬럼의 크기와 데이터 형태를 확인하는 경우가 많다.
- DataFrame의 통계적 기본정보를 확인: df.describe()
- 데이터 정렬 : sort_values
- 특정 컬럼만 읽기: df["A"]
- df[0:3] : 인덱스나 컬럼의 이름으로 slice하는 경우는 끝을 포함
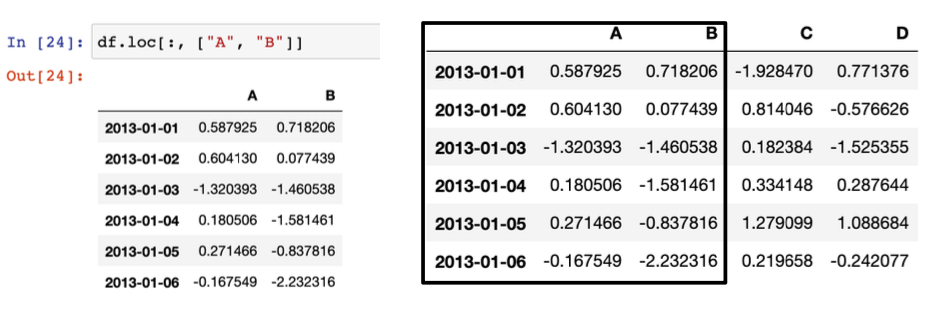
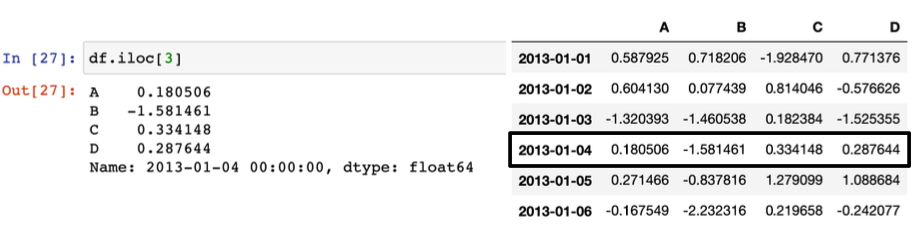
- Pandas Slice - option LOC(이름) , iLOC (번호)
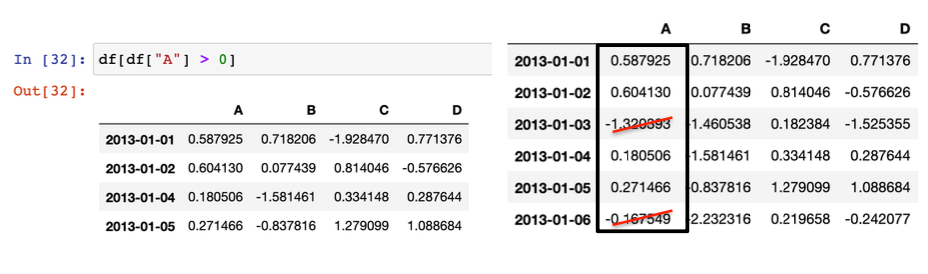
- Pandas Slice under condition
- 컬럼 추가 또는 수정
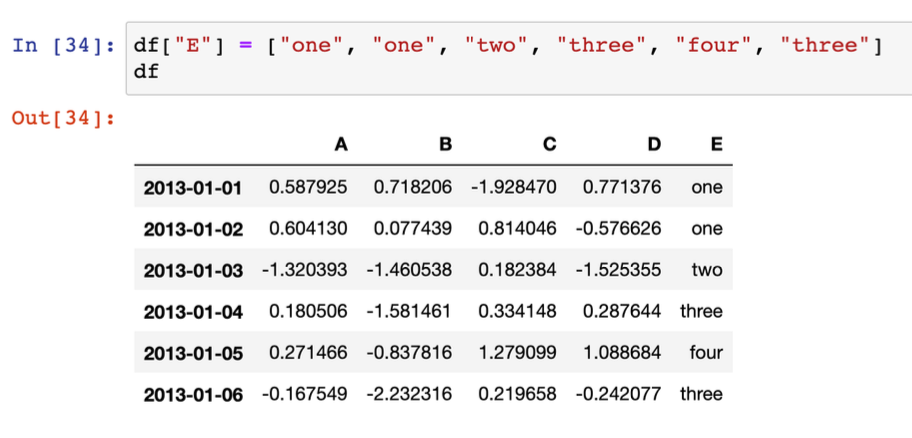
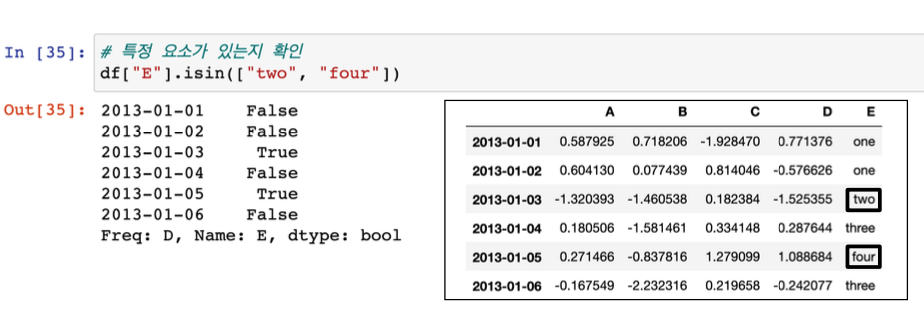
- 특정 요소가 있는지 확인
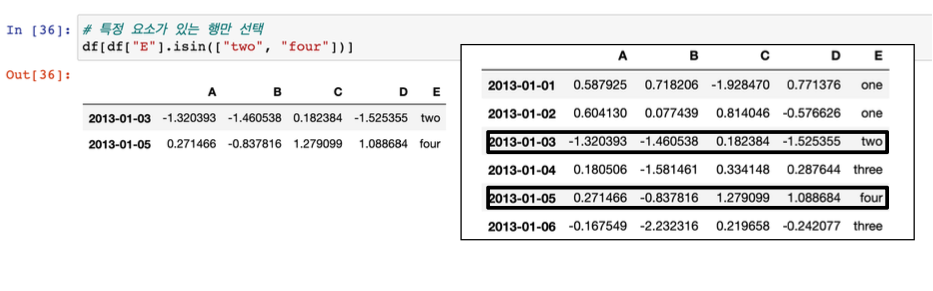
- 특정 요소가 있는 행만 선택
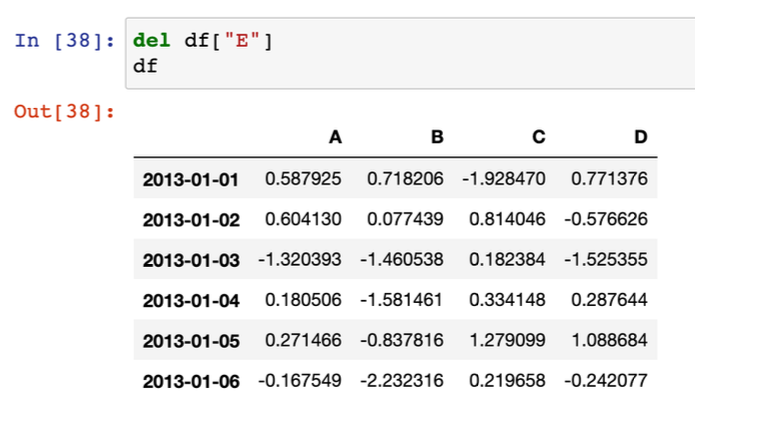
- 특정 컬럼 제거
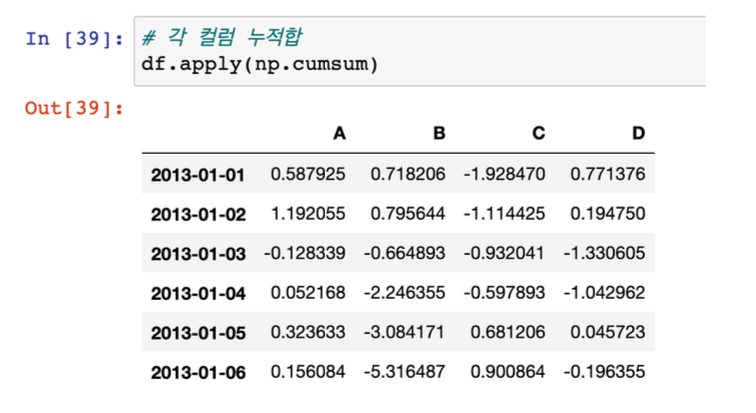
- 각 컬럼 누적합

10√2 Data