
데이터 전처리
두 데이터 합치기
- pd.concat()
- pd.merge()
- pd.join
pd.merge()
- 두 데이터 프레임에서 컬럼이나 인덱스를 기준으로 잡고 병합하는 방법
- 기준이 되는 컬럼이나 인덱스를 키값이라고 합니다.
- 기준이 되는 키값은 두 데이터 프레임에 모두 포함되어 있어야 합니다.
- pd.merge(left, right, how='left', on='key')
- left : left join
- right : right join
- outer : full outer join
- on : A.key = B.key
상관계수
- corr()
- correlation의 약자입니다.
- 상관계수가 0.2 이상인 데이터를 비교
데이터 시각화
pandas에서 plot 그리기
data_result['인구수'].plot(kind='bar',figsize=(10,10))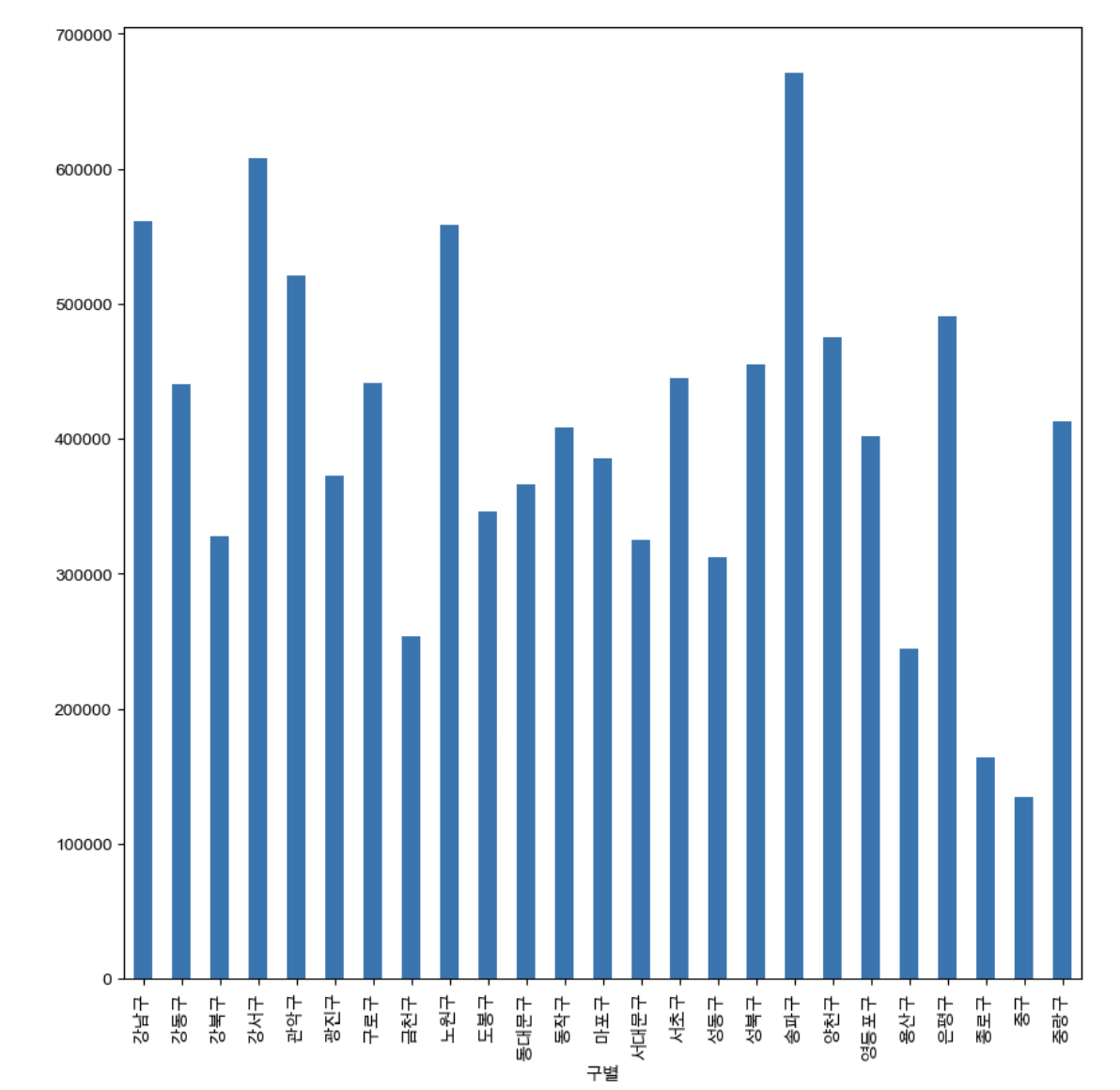
data_result['인구수'].plot(kind='barh',figsize=(10,10))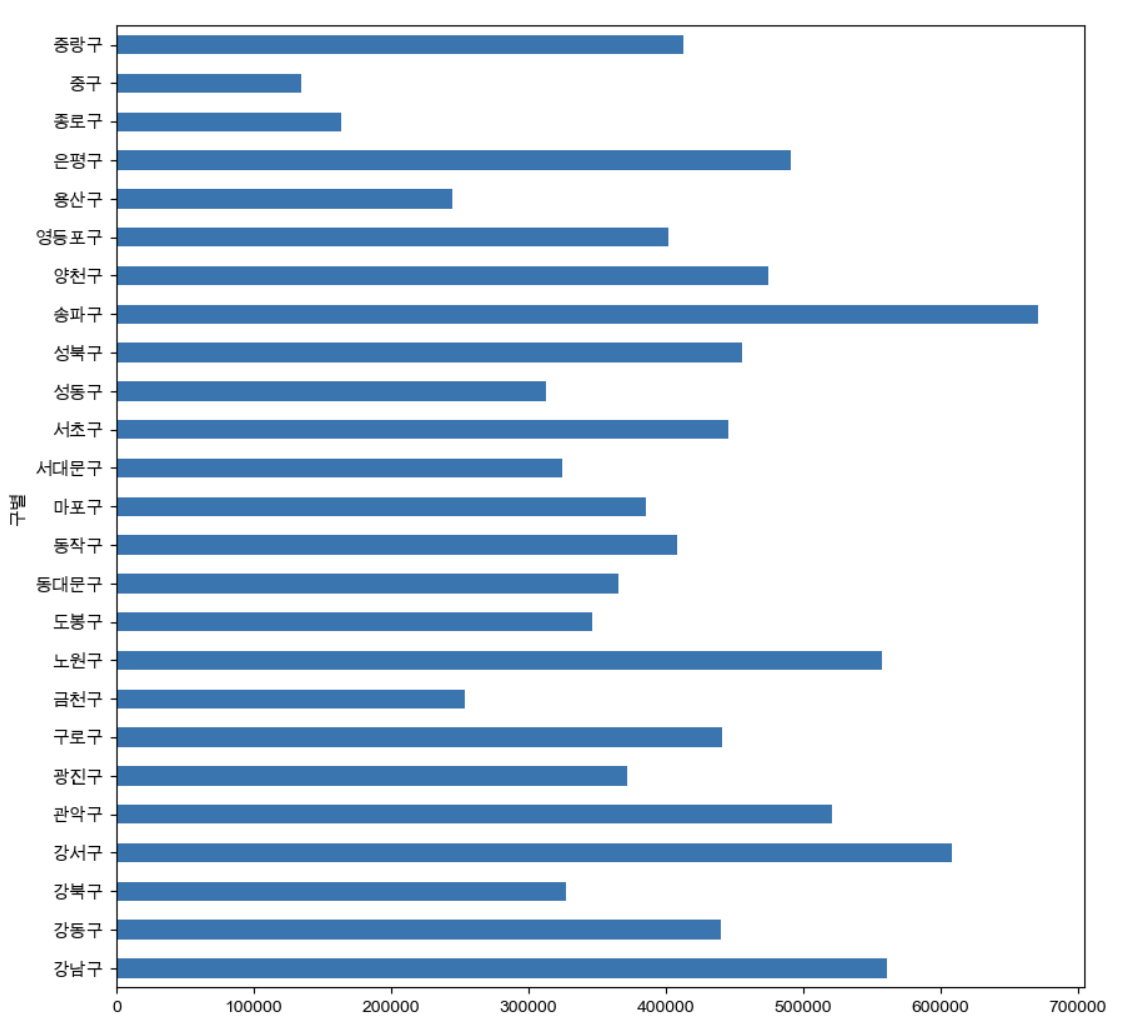
import matplotlib.pyplot as plt
# import matplotlib as mpl
from matplotlib import rc
plt.rcParams['axes.unicode_minus']= False # 마이너스 부호 때문에 한글이 깨질 수가 있어 주는 설정
rc('font',family='Arial Unicode MS')
# matplotlib inline
get_ipython().run_line_magic('matplotlib','inline')data_result.head()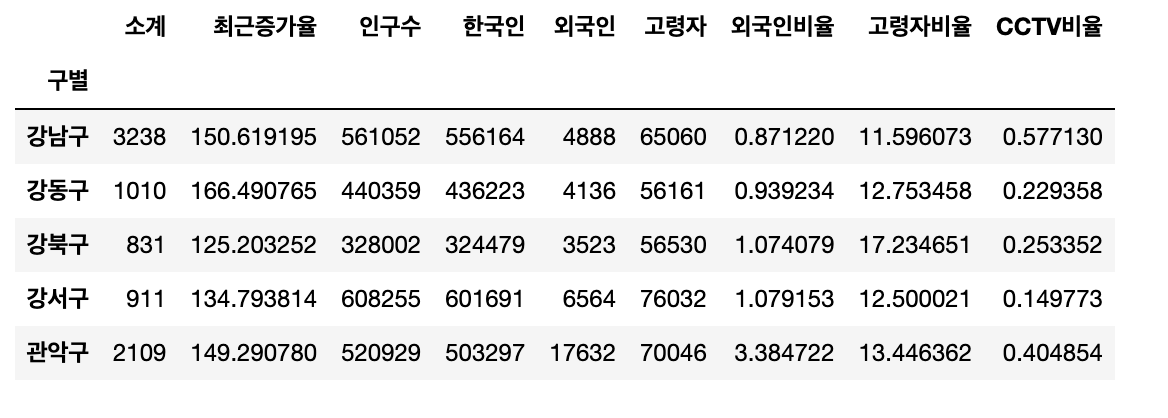
소계 컬럼 시각화
data_result['소계'].plot(kind='barh', grid=True, figsize=(10,10));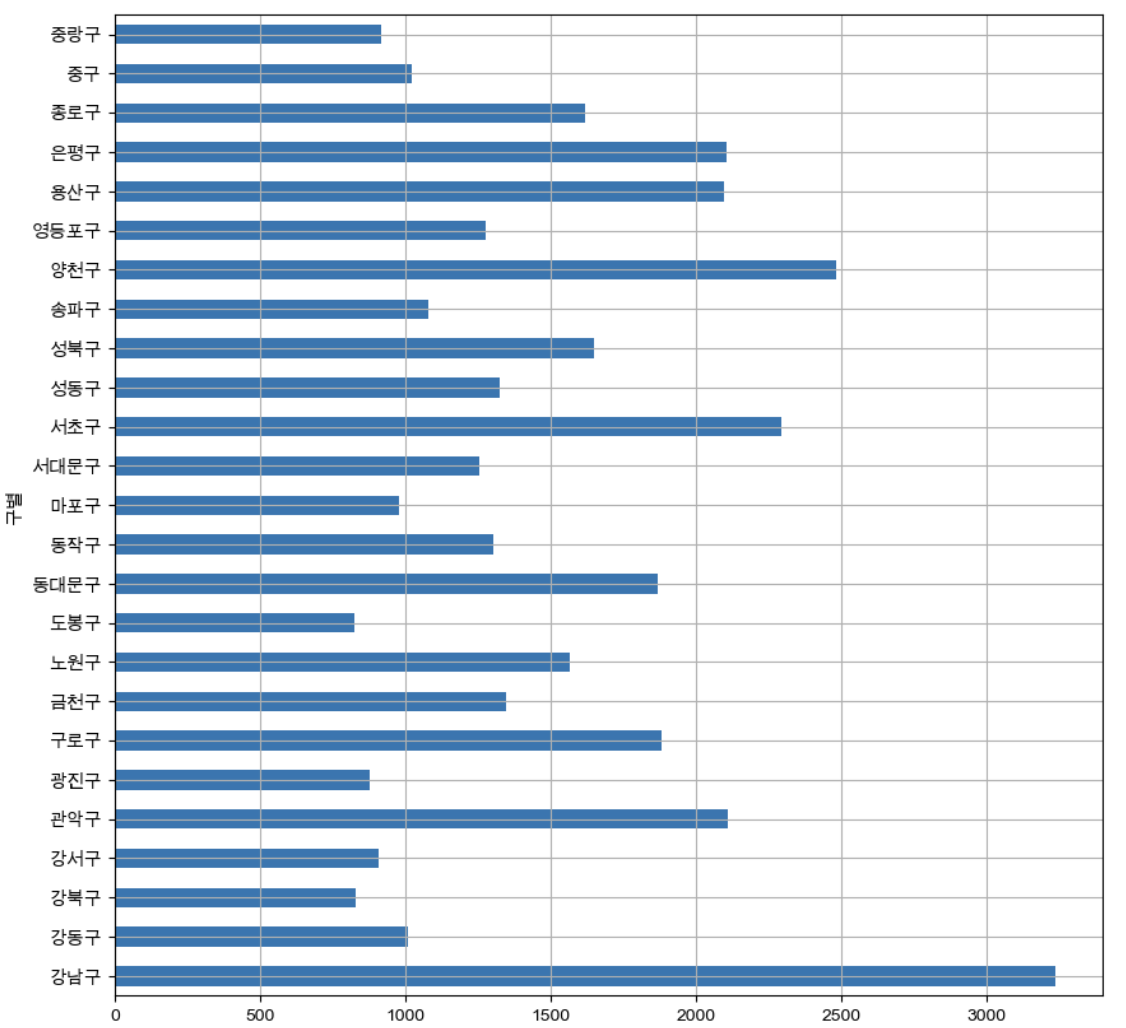
def drawGraph():
data_result['소계'].sort_values().plot(
kind='barh', grid=True, title='가장 CCTV가 많은 구 ', figsize=(10,10));
drawGraph()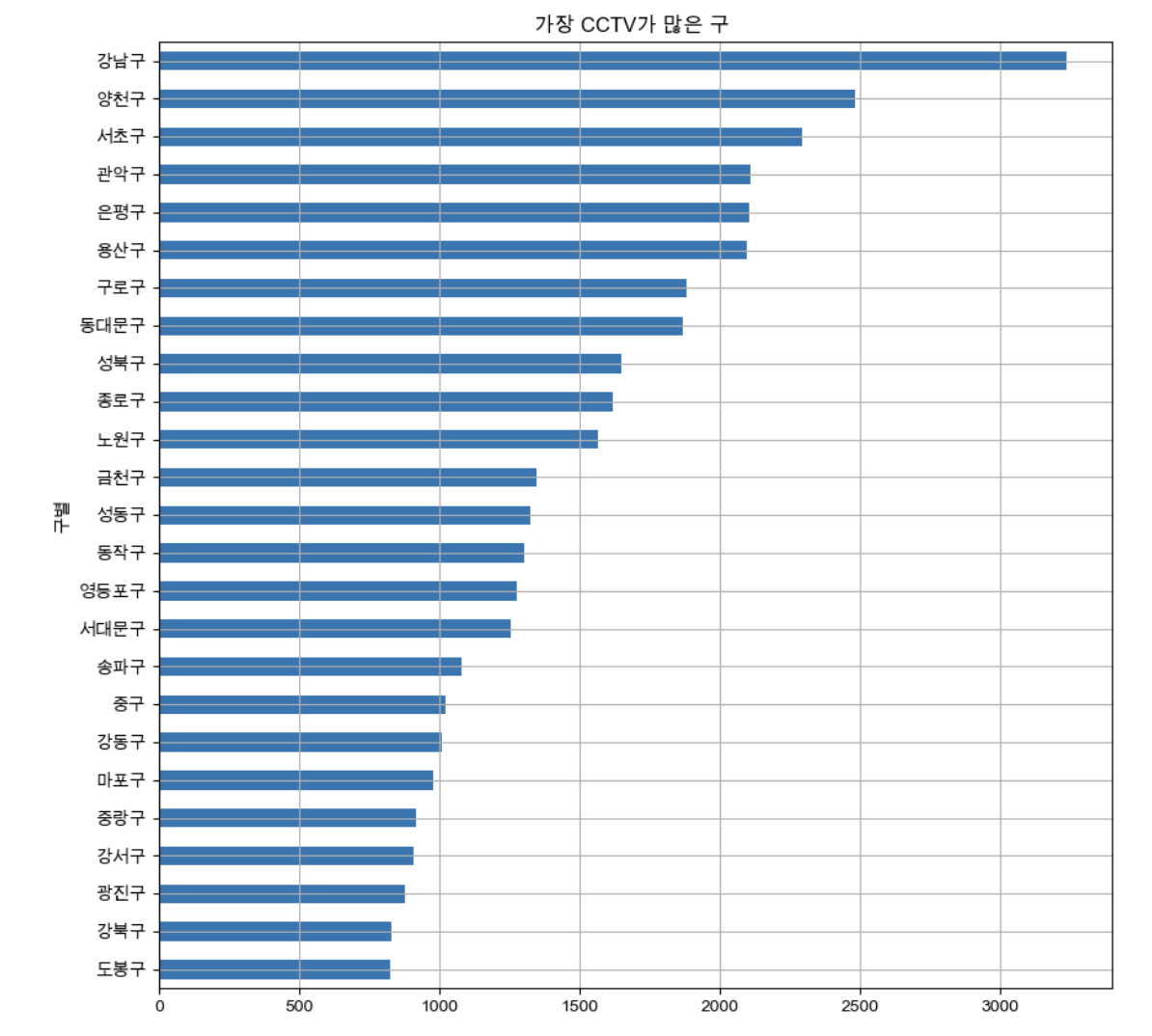
def drawGraph():
data_result['CCTV비율'].sort_values().plot(
kind='barh', grid=True, title='가장 CCTV가 많은 구 ', figsize=(10,10));
drawGraph()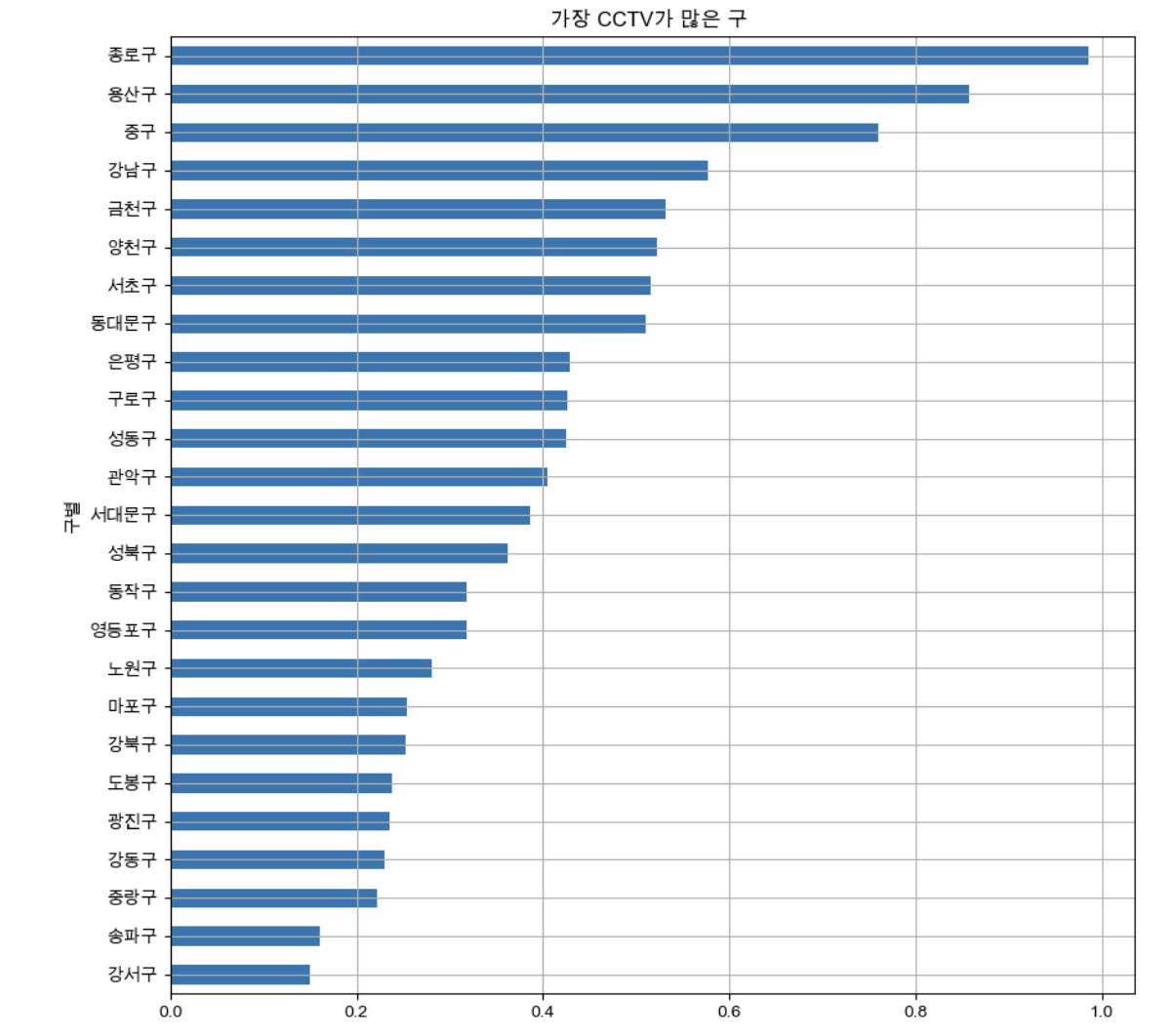
데이터 경향 표시
인구수와 소계 컬럼으로 scatter plot 그리기
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'], data_result['소계'], s=50)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid(True)
plt.show()
drawGraph()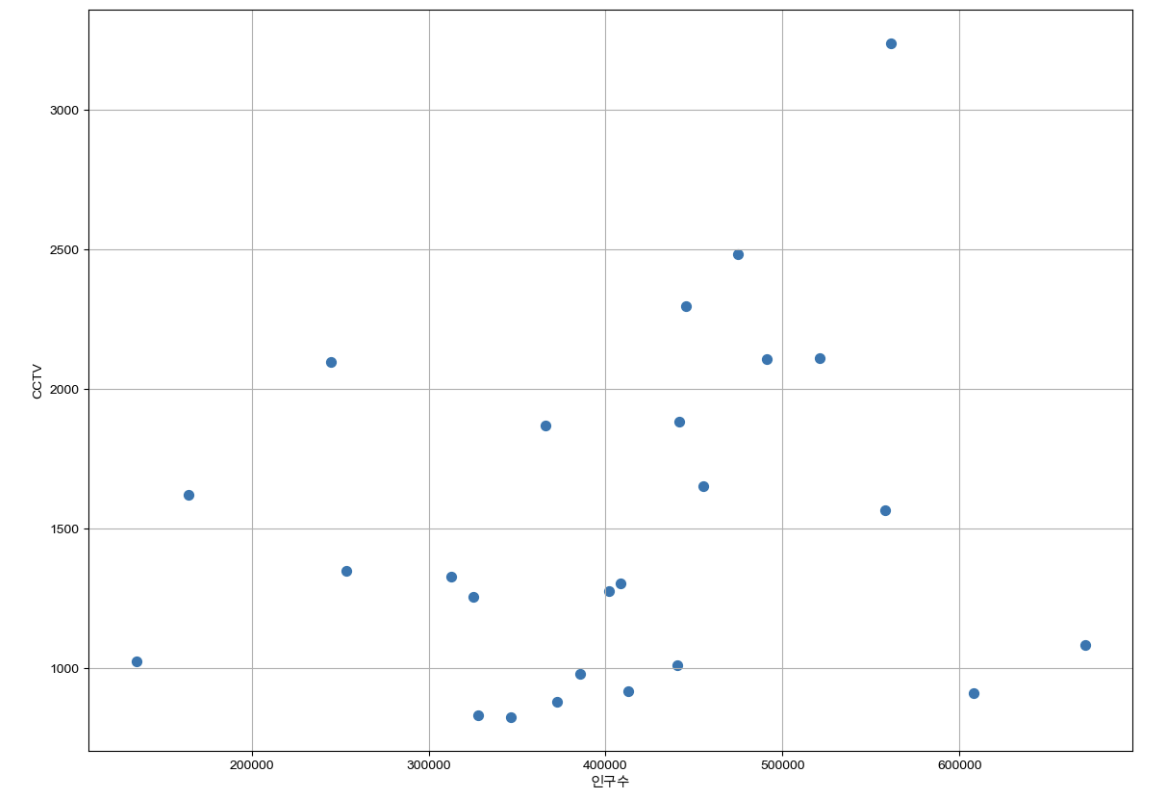
Numpy를 이용한 1차 직선 만들기
- np.polyfit() : 직선을 구성하기 위한 계수를 계산
- np.poly1d() : polyfit으로 찾은 계수로 파이썬에서 사용할 수 있는 함수로 만들어주는 기능
import numpy as np
fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1)
f1 = np.poly1d(fp1)
f1(400000) # 출력값 1509 - 인구가 40만인 구에서 서울시의 전체 경향에 맞는 적당한 CCTV 수는 ?
- 경향선을 그리기 위한 x 데이터 생성- np.linspace(a, b, n) : a부터 b까지 n개의 등간격 데이터 생성
fx = np.linspace(100000, 700000, 100)
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'], data_result['소계'], s=50)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='g')
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.grid(True)
plt.show()
drawGraph()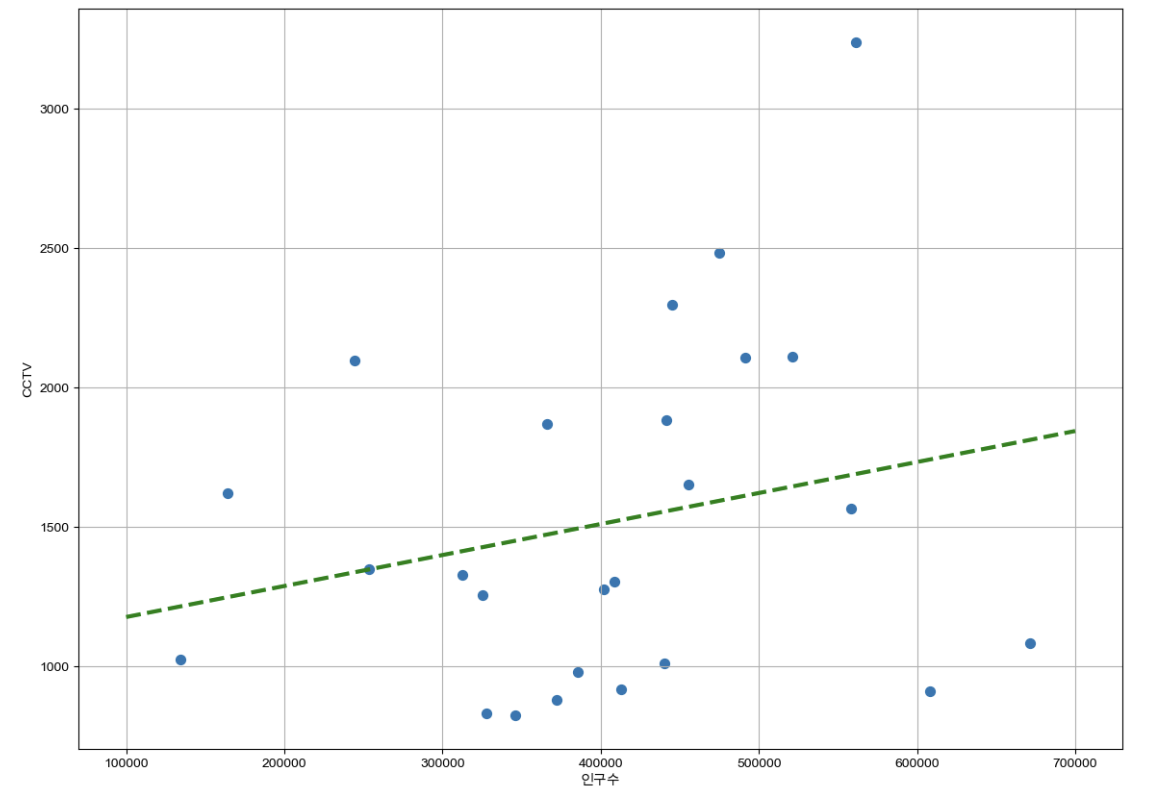
강조 데이터 시각화
그래프 다듬기
- 경향과의 오차 만들기
- 경향(trend)과의 오차를 만들자- 경향은 f1 함수에 해당 인구를 입력
- f1 (data_result['인구수'])
fp1 = np.polyfit(data_result['인구수'], data_result['소계'], 1)
f1 = np.poly1d(fp1)
fx = np.linspace(100000,700000, 100)data_result['오차'] = data_result['소계'] - f1(data_result['인구수'])
## 경향과 비교해서 데이터의 오차가 너무 나는 데이터를 계산
df_sort_f = data_result.sort_values(by='오차', ascending=False)
df_sort_t = data_result.sort_values(by='오차', ascending=True)
## 경향 대비 CCTV를 많이 가진구
df_sort_f.head() from matplotlib.colors import ListedColormap
# colormap 을 사용자 정의 (user define)로 세팅
color_step = ['#e74c3c','#2ecc71','#95a9a6','#2ecc71','#3498db','#3498db']
my_cmap = ListedColormap(color_step)
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'], data_result['소계'], s=50, c=data_result['오차'], cmap=my_cmap)
plt.plot(fx, f1(fx), ls='dashed', lw=3, color='g')
for n in range(5):
# 상위 5개
plt.text(
df_sort_f['인구수'][n] * 1.02, # x 좌표
df_sort_f['소계'][n] * 0.98, # y 좌표
df_sort_f.index[n], # title
fontsize=15,
)
# 하위 5개
plt.text(
df_sort_t['인구수'][n] * 1.02, # x 좌표
df_sort_t['소계'][n] * 0.98, # y 좌표
df_sort_t.index[n], # title
fontsize=15,
)
plt.text(df_sort_f['인구수'][0] * 1.02 ,df_sort_f['소계'][0]*0.98 ,df_sort_f.index[0] , fontsize=15)
plt.xlabel('인구수')
plt.ylabel('CCTV')
plt.colorbar()
plt.grid(True)
plt.show()
drawGraph()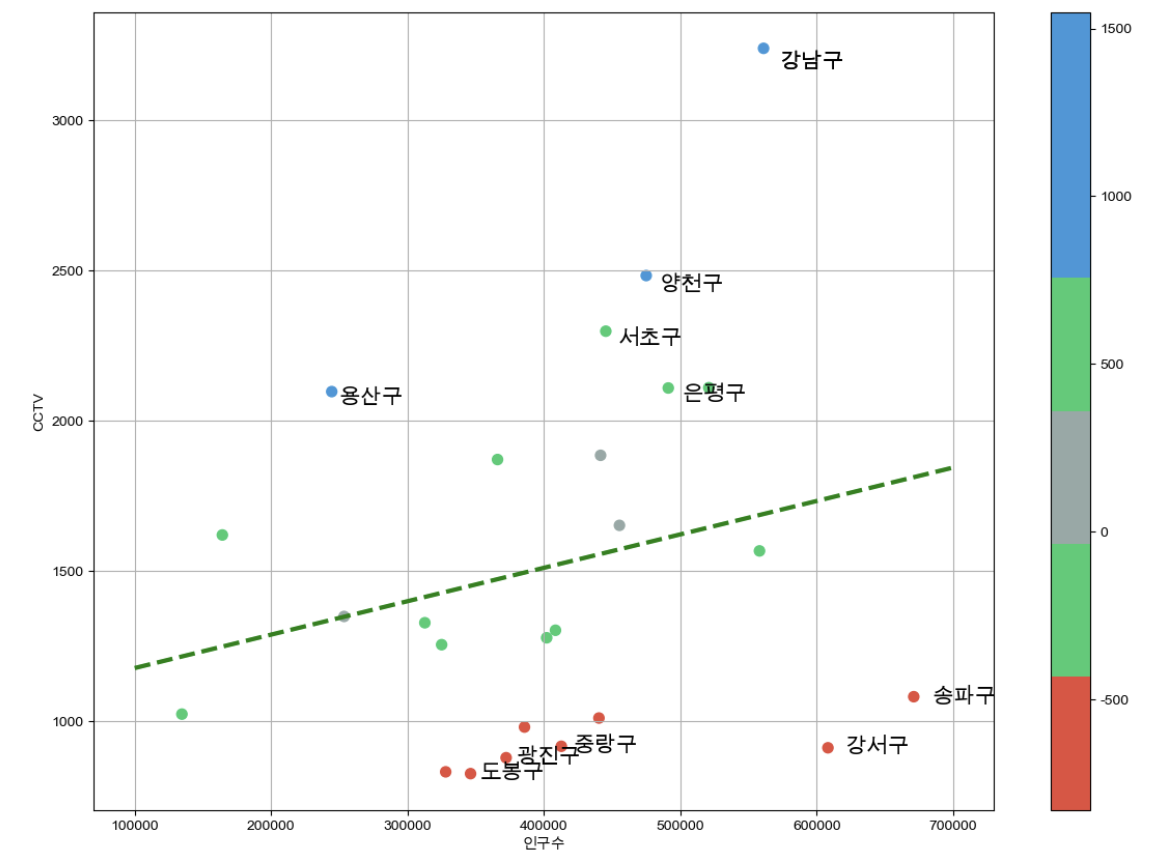

10√2 Data