
BeautifulSoup
BeautifulSoup Basic
- insatll
- conda install -c anaconda beautifulsoup4- pip install beautifulsoup4
# import
from bs4 import BeautifulSoup
import numpy as np
import pandas as pd
page = open('../data/03. test_first.html','r').read()
soup = BeautifulSoup(page, 'html.parser')
print(soup.prettify())
soup.head

soup.body

soup.p / soup.find('p')

soup.find_all('p')

soup.find('p', class_="outer-text first-item").text.strip()

soup.findall(class='outer-text') #특정태그 확인

soup.findall('p',class='inner-text second-item')

print(soup.find_all('p')[0].text)
print(soup.find_all('p')[1].string)
print(soup.find_all('p')[1].get_text())
# 태그 리스트에서 텍스트 속성만 출력
for each_tag in soup.find_all('p'):
print('*' * 5)
print(each_tag.text)
# a태그에서 href 속성값에 있는 값 추출
links = soup.find_all('a')
links[0].get('href'), links[1]['href']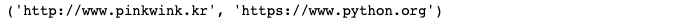
for each in links:
href = each.get('href') # each['href']
text = each.get_text()
print(text + '=> ' + href) 
예제 1-1 네이버 금융
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = 'https://finance.naver.com/marketindex/'
# page = urlopen(url)
response = urlopen(url)
# response.status
soup = BeautifulSoup(response, 'html.parser')
print(soup.prettify())
soup.find_all('span','value'), len(soup.find_all('span','value'))

soup.find_all('span',{'class':'value'})

soup.find_all('span','value')[0].string

예제1-2 네이버금융
import requests
# from urllib.request.Request
from bs4 import BeautifulSoup
url = 'https://finance.naver.com/marketindex/'
response = requests.get(url)
# requests.get(), requests.post()
# requests.text
soup = BeautifulSoup(response.text, 'html.parser')
print(soup.prettify())
# soup.find_all('li','on')
exchangeList = soup.select('#exchangeList > li')
exchangeList, len(exchangeList)
title = exchangeList[0].select_one('.h_lst').text
exchange = exchangeList[0].select_one('.value').text
change = exchangeList[0].select_one('.change').text
updown = exchangeList[0].select_one('div.head_info.point_dn>.blind').text
baseUrl = 'https://finance.naver.com'
link = baseUrl + exchangeList[0].select_one('a').get('href')
title, exchange, change, updown, link
# 4개의 데이터 수정
exchange_datas = []
baseUrl = 'https://finance.naver.com'
for item in exchangeList:
data = {
'title' : item.select_one('.h_lst').text,
'exchange' : item.select_one('.value').text,
'change' : item.select_one('.change').text,
'updown' : item.select_one('div.head_info.point_dn>.blind').text,
'link' : baseUrl + item.select_one('a').get('href')
}
exchange_datas.append(data)
df = pd.DataFrame(exchange_datas)
df.to_excel('./naverFinance.xlsx')예제2 - 위키백과 문서 정보 가져오기
import urllib
from urllib.request import urlopen, Request
html = 'https://ko.wikipedia.org/wiki/{search_words}'
req = Request(html.format(search_words=urllib.parse.quote('여명의_눈동자'))) # 글자를 URL로 인코딩
response = urlopen(req)
soup = BeautifulSoup(response, 'html.parser')
print(soup.prettify())
n = 0
for each in soup.find_all('ul'):
print('=>' + str(n) + '==============')
print(each.get_text())
n += 1

10√2 Data