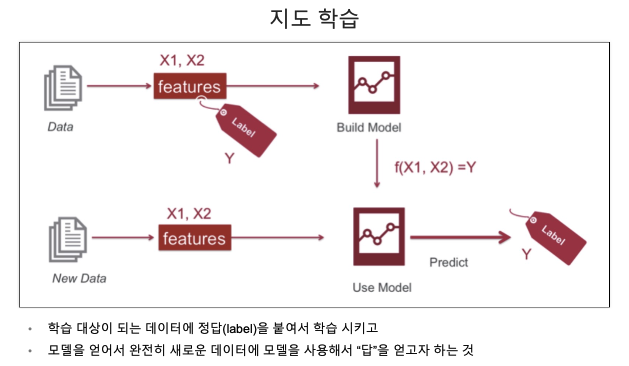
Iris Classification



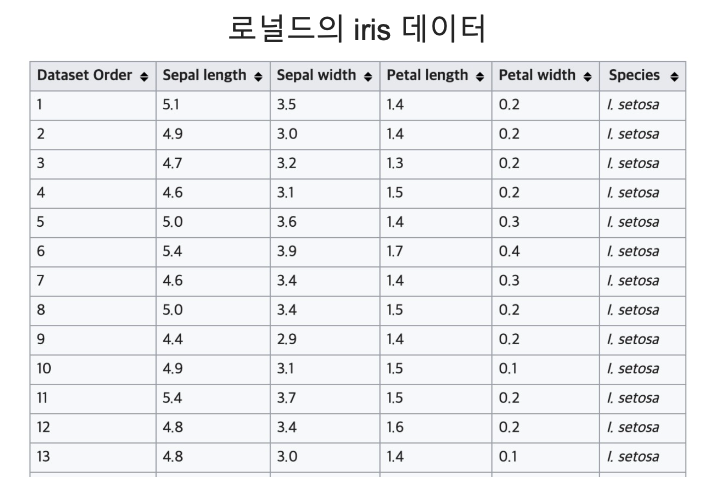
데이터 관찰
from sklearn.datasets import load_iris
iris = load_iris()
iris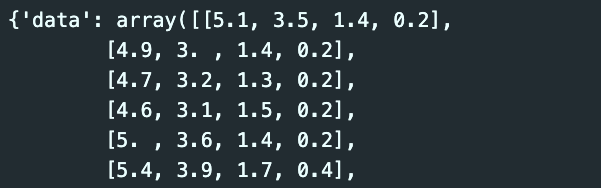
sklearn의 datasets은 Python의 dict 형과 유사하다.
iris.keys()
print(iris['DESCR'])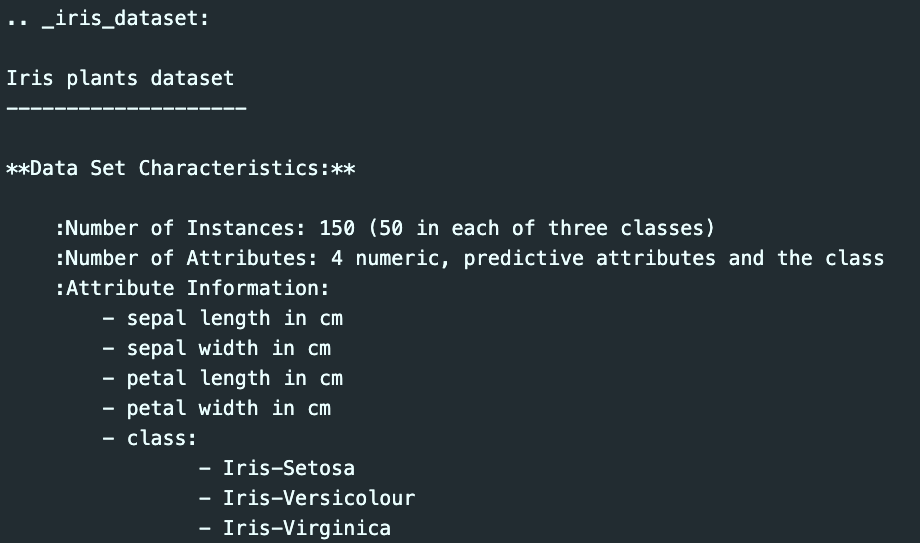
iris['feature_names']
iris['target_names']
iris['target']
iris['data']
import pandas as pd
iris_pd = pd.DataFrame(iris.data, columns=iris['feature_names'])
iris_pd
iris_pd['species'] = iris.target
iris_pd.head() # 0,1,2의 값이 각 품종을 의미한다. 
import matplotlib.pyplot as plt
import seaborn as sns
sns.boxplot(x= 'sepal length (cm)', y= 'species', data= iris_pd, orient='h' );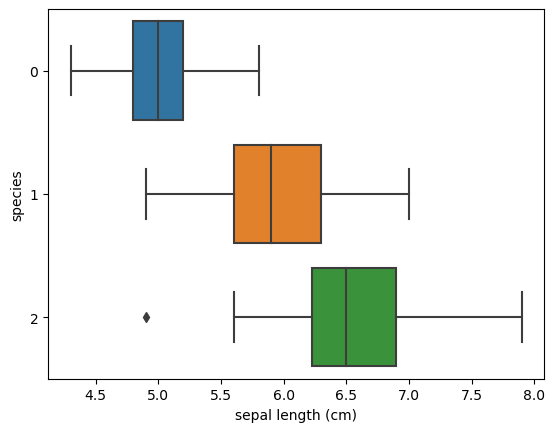
sns.pairplot(iris_pd, hue='species');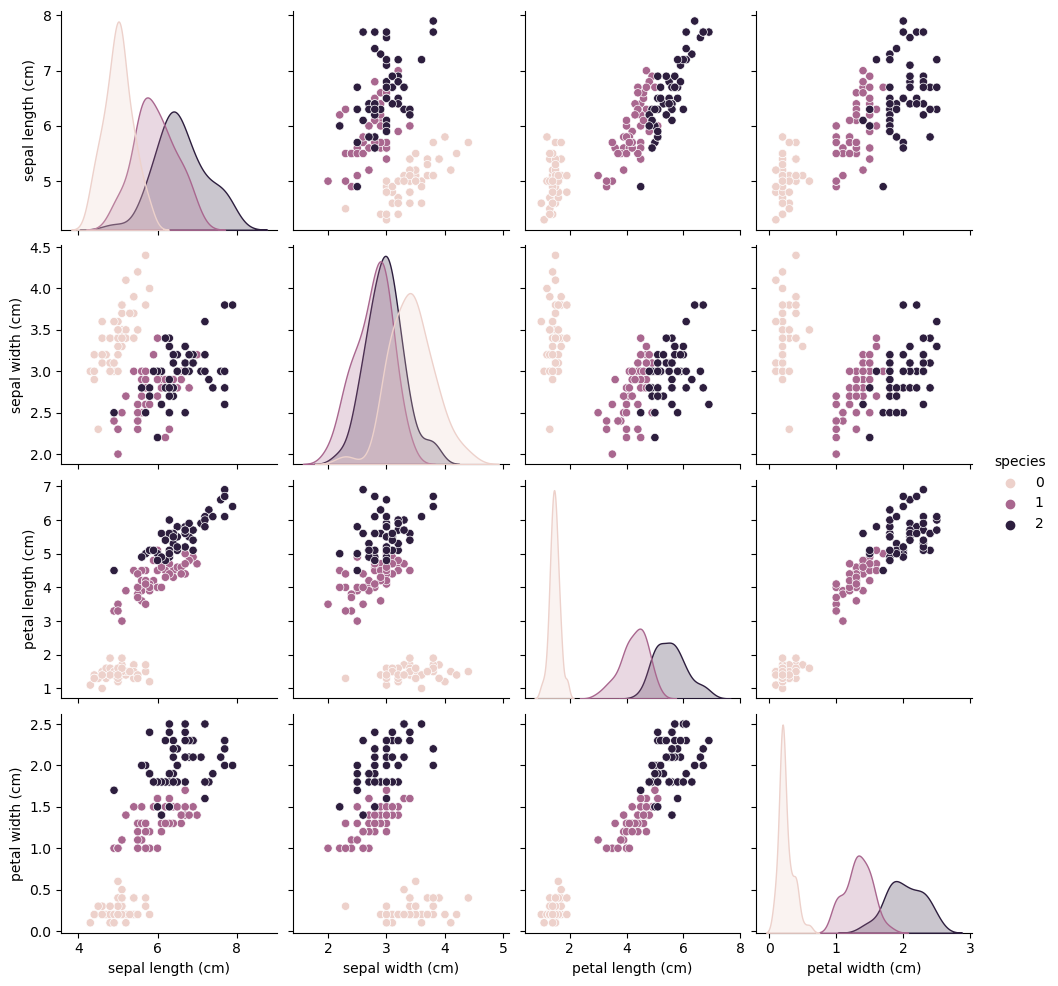
plt.figure(figsize=(12,6))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)',
data=iris_pd, hue='species', palette='Set2');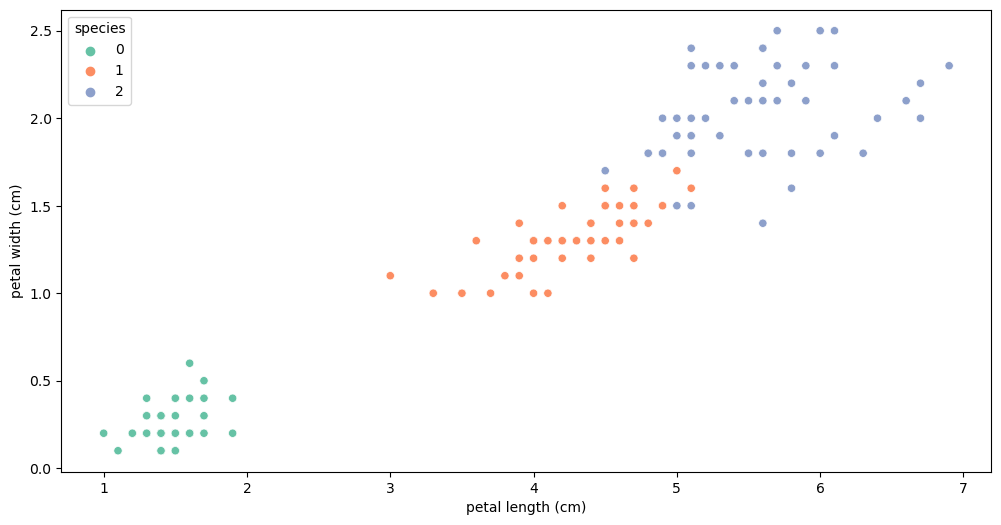
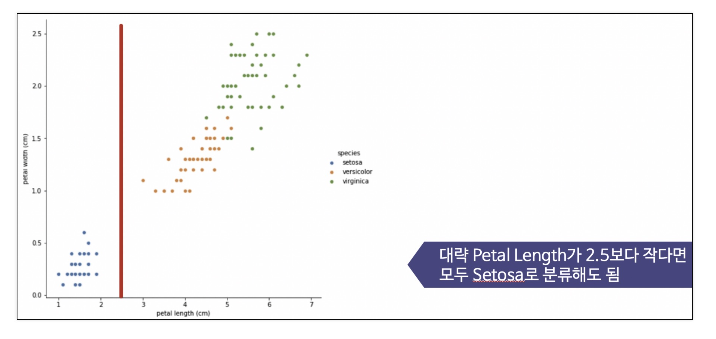
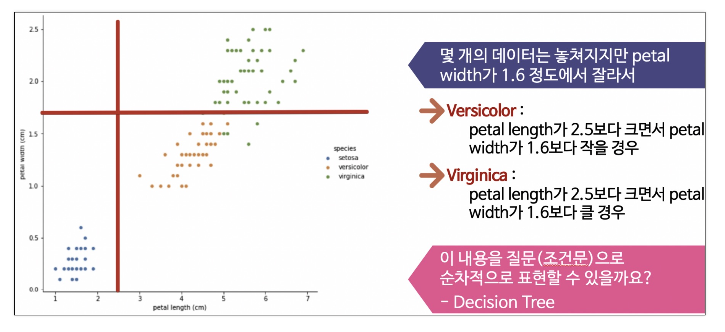
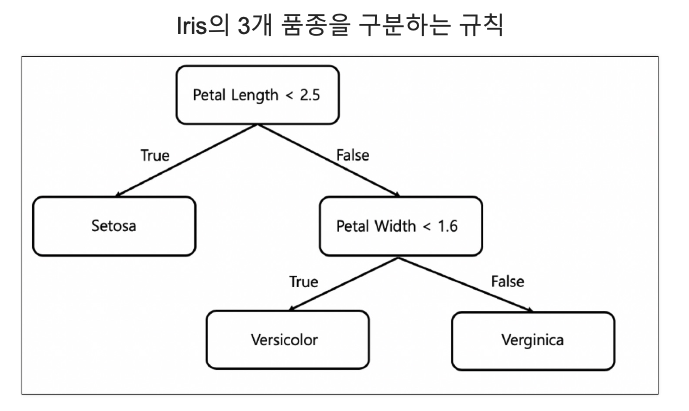
Decision Tree
데이터 변경
iris_12 = iris_pd[iris_pd['species'] != 0]
iris_12.info()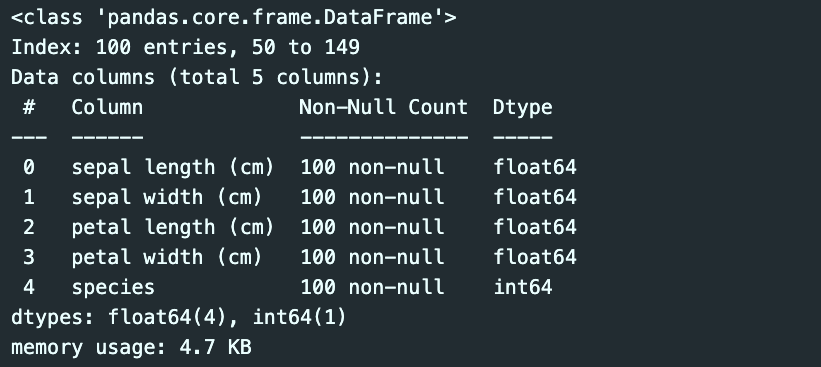
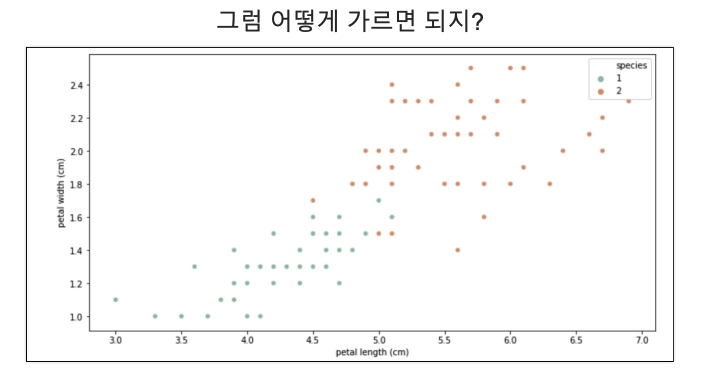
두 개의 데이터에 집중
plt.figure(figsize=(12,6))
sns.scatterplot(x='petal length (cm)', y='petal width (cm)',
data=iris_12, hue='species', palette='Set2');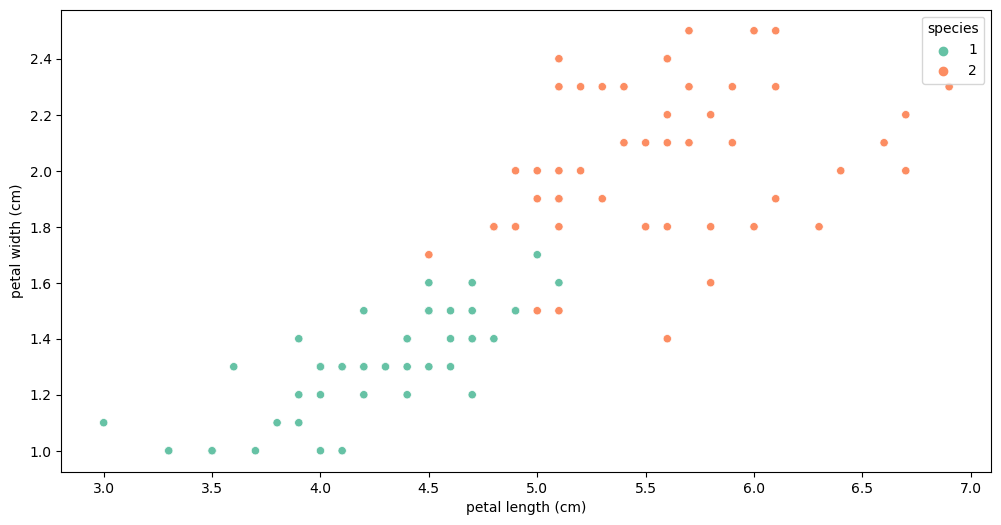
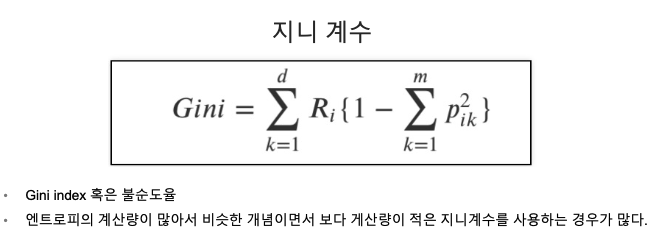
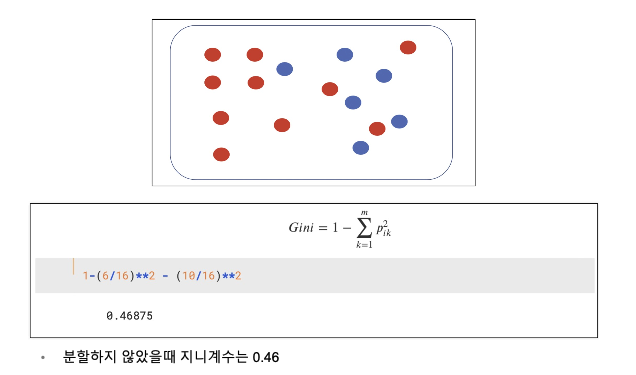
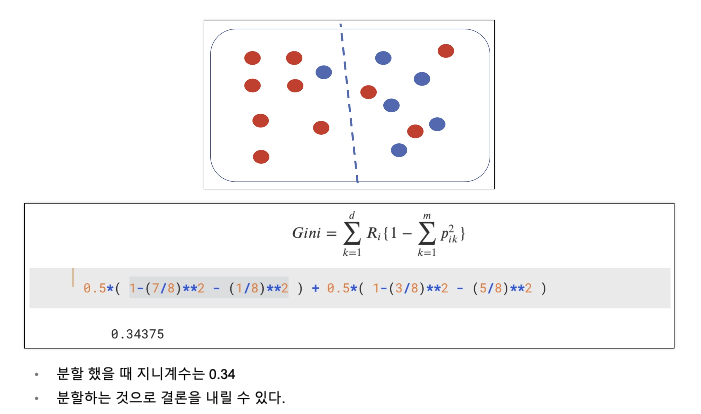
Decision Tree의 분할 기준 (Split Criterion)
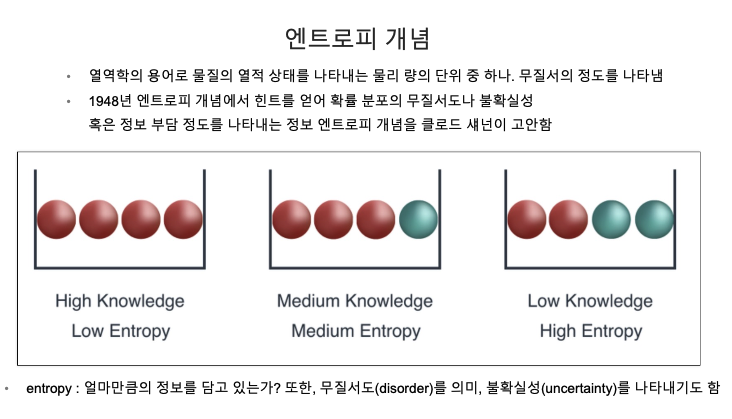
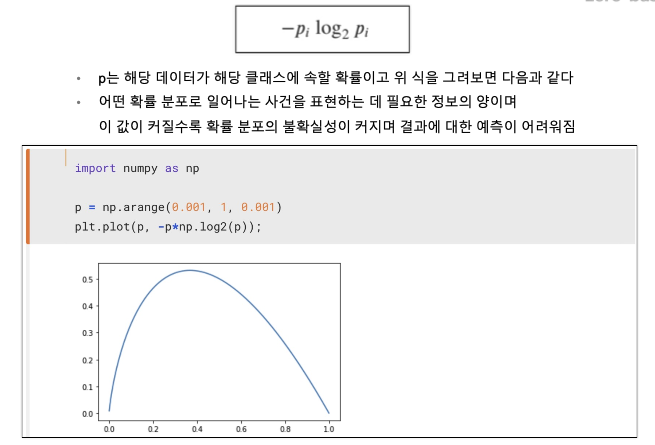
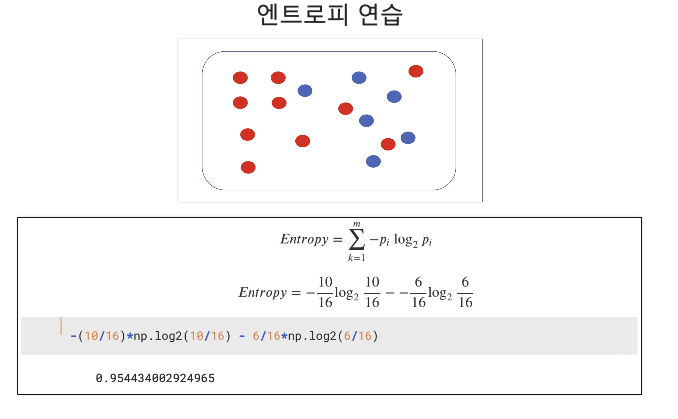
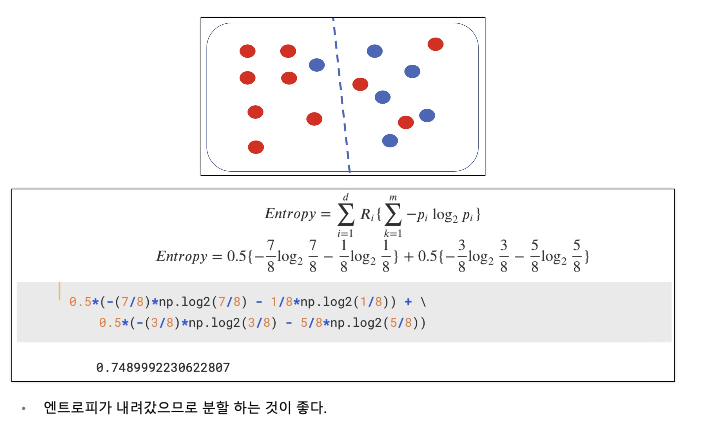
정보 획득 (Information Gain)
- 정보의 가치를 반환하는 데 발생하는 사전의 확률이 작을수록 정보의 가치는 커진다.
- 정보 이득이란 어떤 속성을 선택함으로 인해서 데이터를 더 잘 구분하게 되는것.

Scikit Learn

sklearn을 이용한 결정나무의 구현
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier()
iris_tree.fit(iris.data[:, 2:], iris.target)
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:,2:])
y_pred_tr
iris.target
accuracy_score(iris.target, y_pred_tr)
데이터 나누기 - Decision Tree를 이용한 Iris 분류
과적합
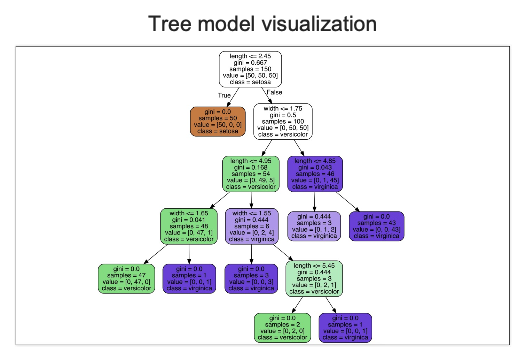
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(iris_tree);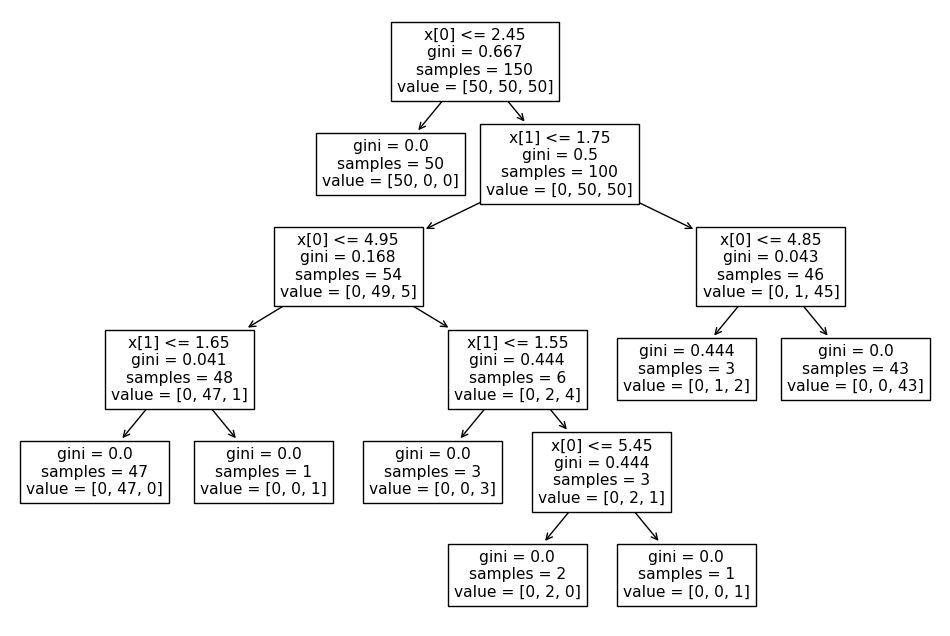
iris의 품종을 분류하는 결정나무 모델이 데이터를 분류
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=iris.data[:,2:], y=iris.target, clf=iris_tree, legend=2)
plt.show()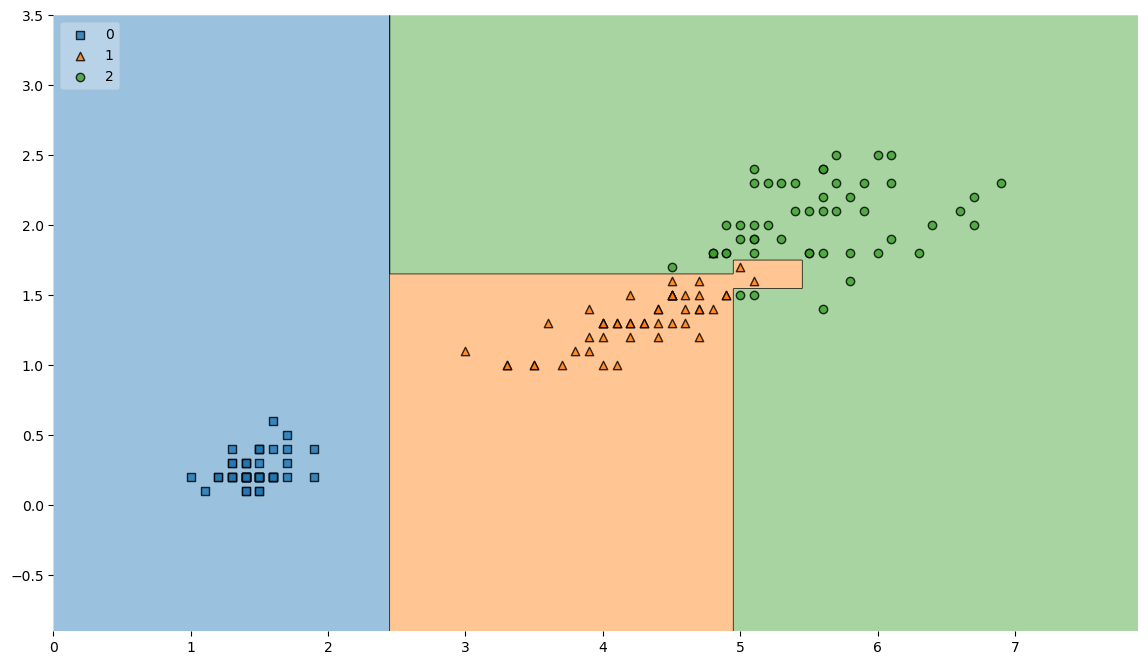
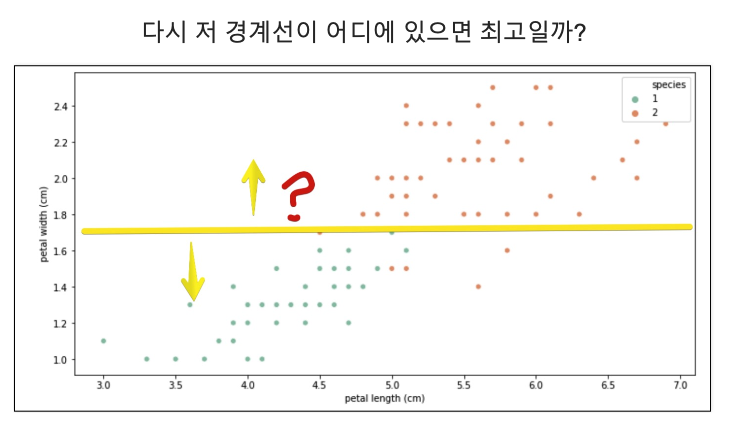
- Accuracy가 높게 나왔다고 해도 좀 더 들여다 볼 필요가 있다.
- 저 경계면은 올라른 걸까?
- 저 결과는 내가 가진 데이터를 벗어나서 일반화 할수 있는 걸까?
- 얻은 데이트는 유한가고 그 데이터를 이용해서 일반화를 추구하게 된다.
- 이때 복잡한 경계면은 모델의 성능을 결국 나쁘게 만든다.
데이터 분리

새롭게 다시 시작
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()데이터를 훈련/테스트로 분리
- 8:2 확률로 특성(features)과 정답(labels)를 분리
from sklearn.model_selection import train_test_split
features = iris.data[:,2:]
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels,
random_state=13)X_train.shape, X_test.shape 
- stratify : 각 클래스별로 동일 비율로 할떄 쓰는 옵션
훈련용/테스트용이 잘 분리 되었는지 체크
import numpy as np
np.unique(y_test, return_counts=True)
train 데이터만 대상으로 결정나무 모델을 만들어 보자
- 일관성을 위해 random_state만 고정
- 모델일 단순화시키기 위해 max_depth를 조정
from sklearn.tree import DecisionTreeClassifier
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
train 데이터에 대한 accuracy 확인
from sklearn.metrics import accuracy_score
y_pred_tr = iris_tree.predict(iris.data[:,2:])
accuracy_score(iris.target, y_pred_tr)
iris 꽃을 분류하는 결정나무 모델
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize =(12,8))
plot_tree(iris_tree);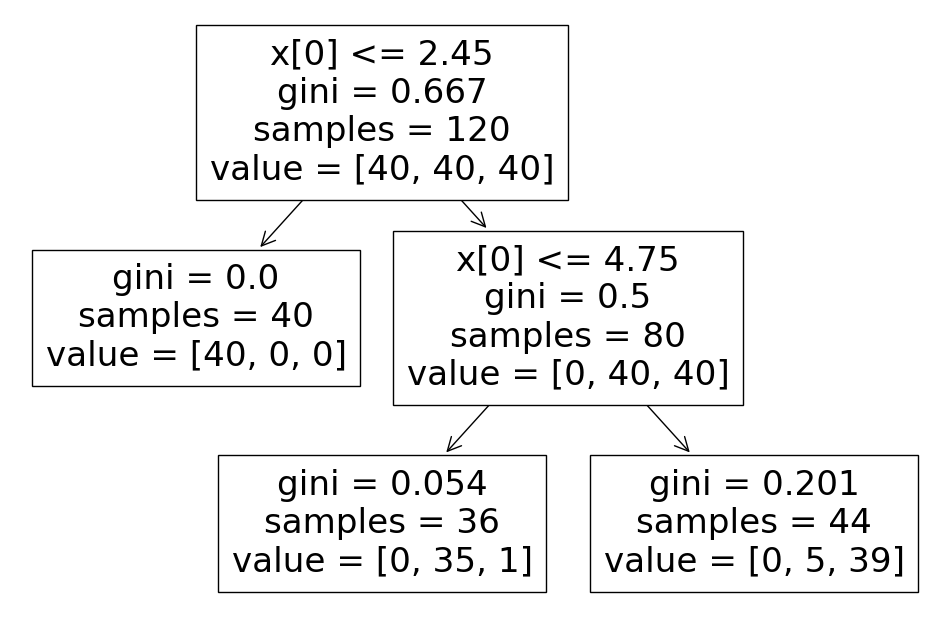
훈련데이터에 대한 결정경계
from mlxtend.plotting import plot_decision_regions
plt.figure(figsize=(14,8))
plot_decision_regions(X=X_train, y=y_train, clf=iris_tree, legend=2)
plt.show()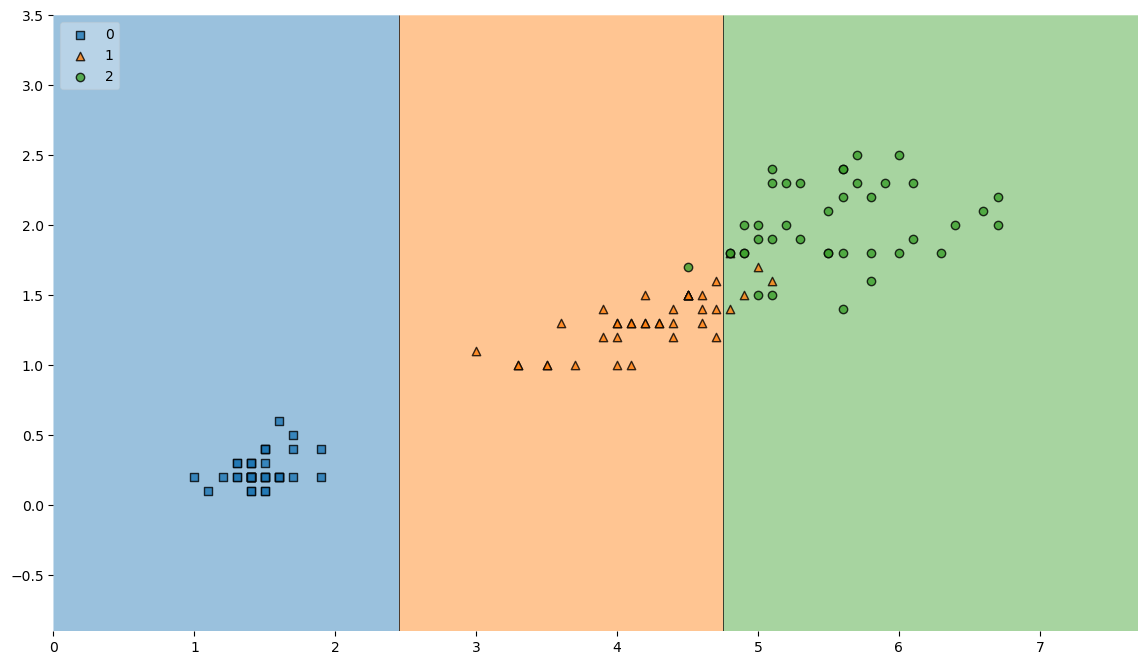
테스트 데이터에 대한 accuracy
y_pred_test = iris_tree.predict(X_test)
accuracy_score(y_test, y_pred_test)
결과
plt.figure(figsize=(14,8))
plot_decision_regions(X=X_test, y=y_test, clf=iris_tree, legend=2)
plt.show()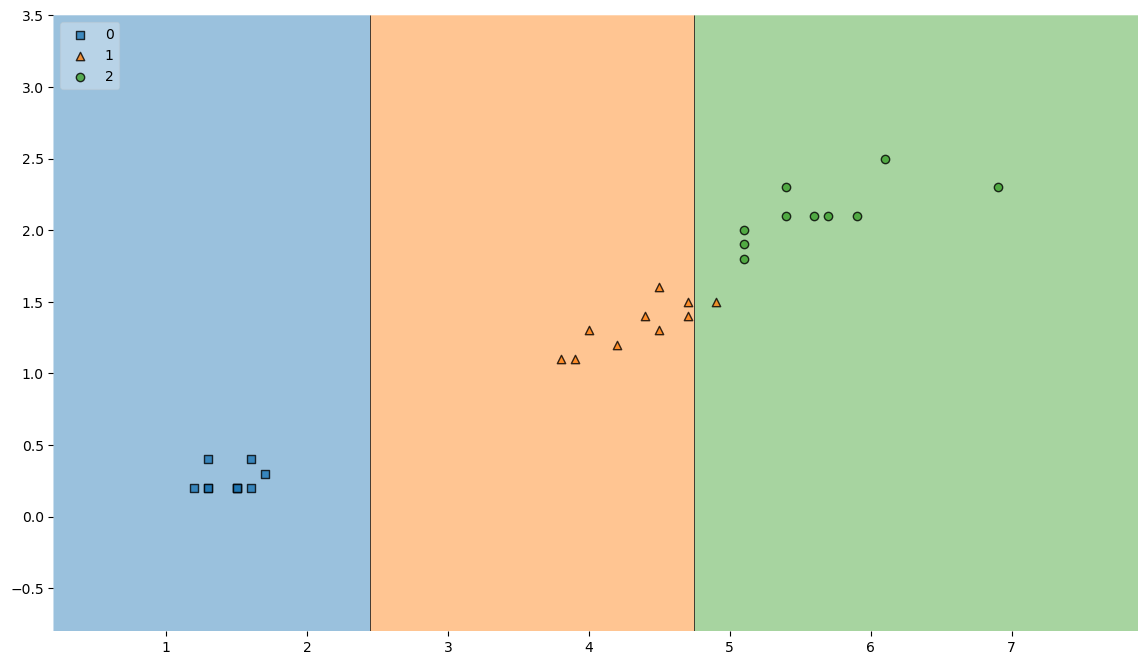
전체 데이터에서 관찰
scatter_highlight_kwargs = {'s':150, 'label':'Test data', 'alpha':0.9}
scatter_kwargs = {'s':120, 'edgecolor':None, 'alpha':0.9}
plt.figure(figsize=(12,8))
plot_decision_regions(X=features, y=labels, X_highlight=X_test, clf=iris_tree, legend=2,
scatter_highlight_kwargs=scatter_highlight_kwargs,
scatter_kwargs=scatter_kwargs,
contour_kwargs={'alpha':0.2}) 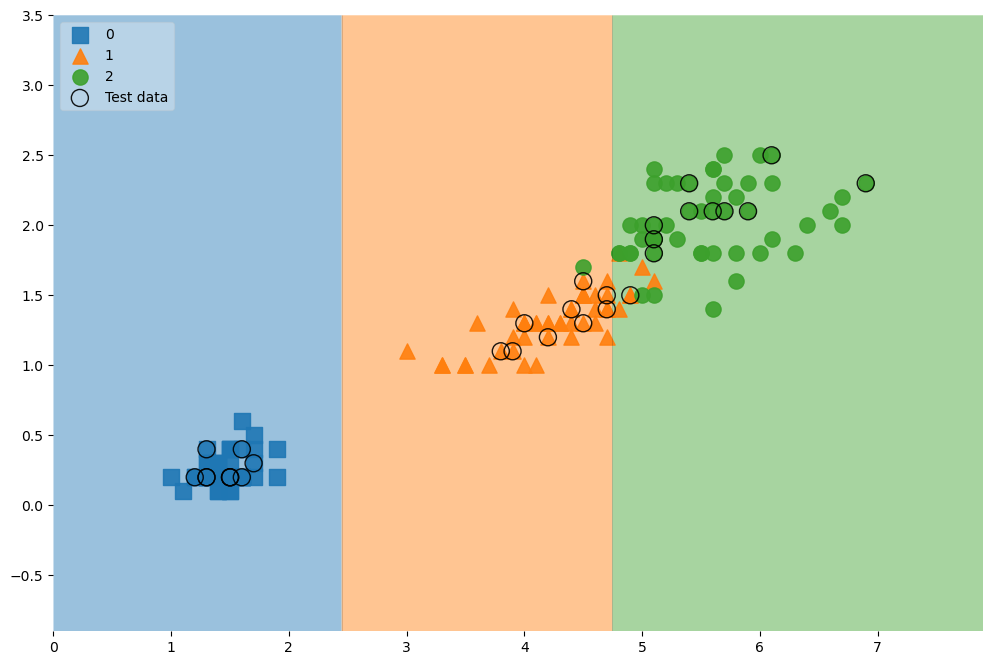
전체 특성을 사용한 결정나무 모델
features = iris.data
labels = iris.target
X_train, X_test, y_train, y_test = train_test_split(features, labels,
test_size=0.2,
stratify=labels,
random_state=13)
iris_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
iris_tree.fit(X_train, y_train)
plt.figure(figsize =(12,8))
plot_tree(iris_tree);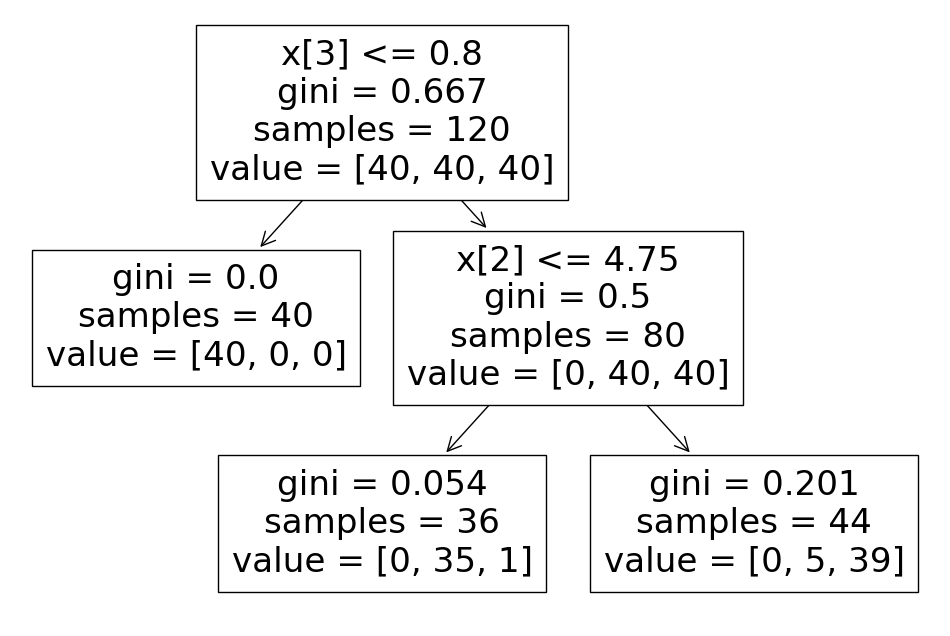
모델을 사용하는 방법
test_data = np.array([[4.3, 2., 1.2,1.]])
iris_tree.predict(test_data)
iris_tree.predict_proba(test_data)
각 클래스별 확률이 아니라 범주 값을 알고 싶다면
iris.target_names[iris_tree.predict(test_data)]
주요 특성 확인하기
iris_tree.feature_importances_
iris_tree = DecisionTreeClassifier(max_depth=5, random_state=13)
iris_tree.fit(X_train, y_train)
iris_tree.feature_importances_
dict(zip(iris.feature_names, iris_tree.feature_importances_))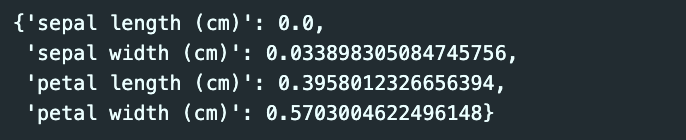
zip & unpacking





10√2 Data