
최댓값
- 자료구조에서 가장 큰 값을 찾는다.

코드
class MaxAlgorithm:
def __init__(self,ns):
self.nums = ns
self.maxNum = 0
def getMaxNum(self):
self.maxNum = self.nums[0]
for n in self.nums:
if self.maxNum < n:
self.maxNum = n
return self.maxNum
ma = MaxAlgorithm([-2,-4,5,7,10,0,8,20,-11])
maxNum = ma.getMaxNum()
print(f'maxNum: {maxNum}')최솟값
- 자료구조에서 가장 작은 값을 찾는다.

코드
class MinAlgorithm:
def __init__(self,ns):
self.nums = ns
self.minNum = 0
def getMinNum(self):
self.minNum = self.nums[0]
for n in self.nums:
if self.minNum > n:
self.minNum = n
return self.minNum
ma = MinAlgorithm([-2,-4,5,7,10,0,8,20,-11])
minNum = ma.getMinNum()
print(f'minNum: {minNum}')최빈값
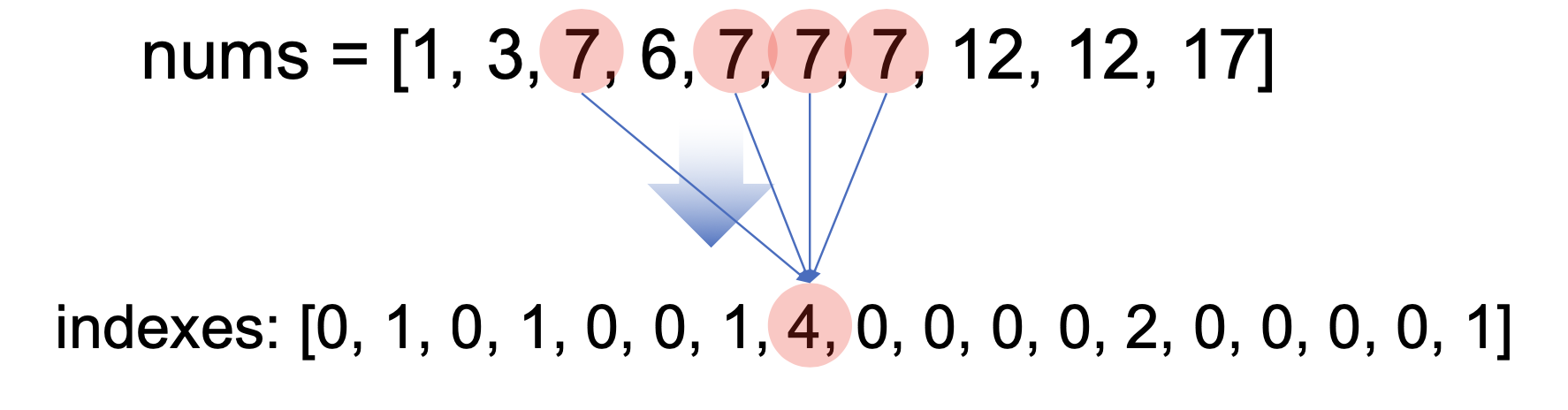
- 데이터에서 빈도수가 가장 많은 데이터를 최빈값이라고 한다.
코드
class MaxAlgorithm:
def __init__(self, ns):
self.nums = ns
self.maxNum = 0
self.manNumIdx = 0
def setMaxIdxAndNum(self):
self.maxNum = self.nums[0]
self.maxNum = 0
for i, n in enumerate(self.nums):
if self.maxNum < n:
self.maxNum = n
self.maxNumIdx = i
def getMaxNum(self):
return self.maxNum
def getMaxNumIdx(self):
return self.maxNumIdx
nums = [1, 3, 7, 6, 7, 7, 7, 12, 12, 17]
maxAlo = MaxAlgorithm(nums)
maxAlo.setMaxIdxAndNum()
maxNum = maxAlo.getMaxNum()
print(f'maxNum: {maxNum}')
indexes = [0 for i in range(maxNum + 1)]
print(f'indexes: {indexes}')
print(f'indexes length: {len(indexes)}')
for n in nums:
indexes[n] = indexes[n] + 1
print(f'indexes: {indexes}')
maxAlo = MaxAlgorithm(indexes)
maxAlo.setMaxIdxAndNum()
maxNum = maxAlo.getMaxNum()
maxNumIdx = maxAlo.getMaxNumIdx()
print(f'maxNum: {maxNum}')
print(f'maxNumIdx: {maxNumIdx}')
print(f'즉, {maxNumIdx}의 빈도수가 {maxNum}로 가장 높다. ')근삿값
- 특정 값(참값)에 가장 가까운 값을 근삿값이라고 한다.

코드
import random
nums = random.sample(range(0,50),20)
print(f'nums: {nums}')
inputNum = int(input('input number: '))
print(f'inputNum: {inputNum}')
nearNum = 0
minNum = 50
for n in nums:
absNum = abs(n - inputNum)
if absNum < minNum:
minNum = absNum
nearNum = n
print(f'nearNum: {nearNum}')평균
- 여러 수나 양의 중간값을 갖는 수를 평균이라고 한다.
코드
import random
nums = random.sample(range(1,100),10)
print(f'nums: {nums}')
total = 0
for n in nums:
total += n
average = total / len(nums)
print(f'average: {average}')
# 50이상 90이하 수들의 평균
import random
nums = random.sample(range(1,100),30)
print(f'nums: {nums}')
total = 0
targetNum = []
for n in nums:
if n >= 50 and n <=90:
total += n
targetNum.append(n)
average = total / len(targetNum)
print(f'targetNum: {targetNum}')
print(f'average: {round(average,2)}')
# 정수들의 평균
nums = [ 4, 5.12, 0, 5, 7.34, 9.1, 9, 3, 3.159, 1, 11, 12.789]
print(f'nums: {nums}')
targetNum = []
total = 0
for n in nums:
if n - int(n) == 0:
total += n
targetNum.append(n)
average = total / len(targetNum)
print(f'targetNum: {targetNum}')
print(f'average: {round(average,2)}')재귀
- 나 자신을 다시 호출하는 것을 재귀라고 한다

코드
def recusion(num):
if num > 0:
print('*' * num)
return recusion(num - 1)
else:
return 1
recusion(10)
# 10!
def factorial(num):
if num > 0:
return num * factorial(num-1)
else:
return 1
print(f'factorial(10): {factorial(10)}')병합정렬
- 자료구조를 분할하고 각각의 분할된 자료구조를 정렬한 후 다시 병합하여 정렬한다.
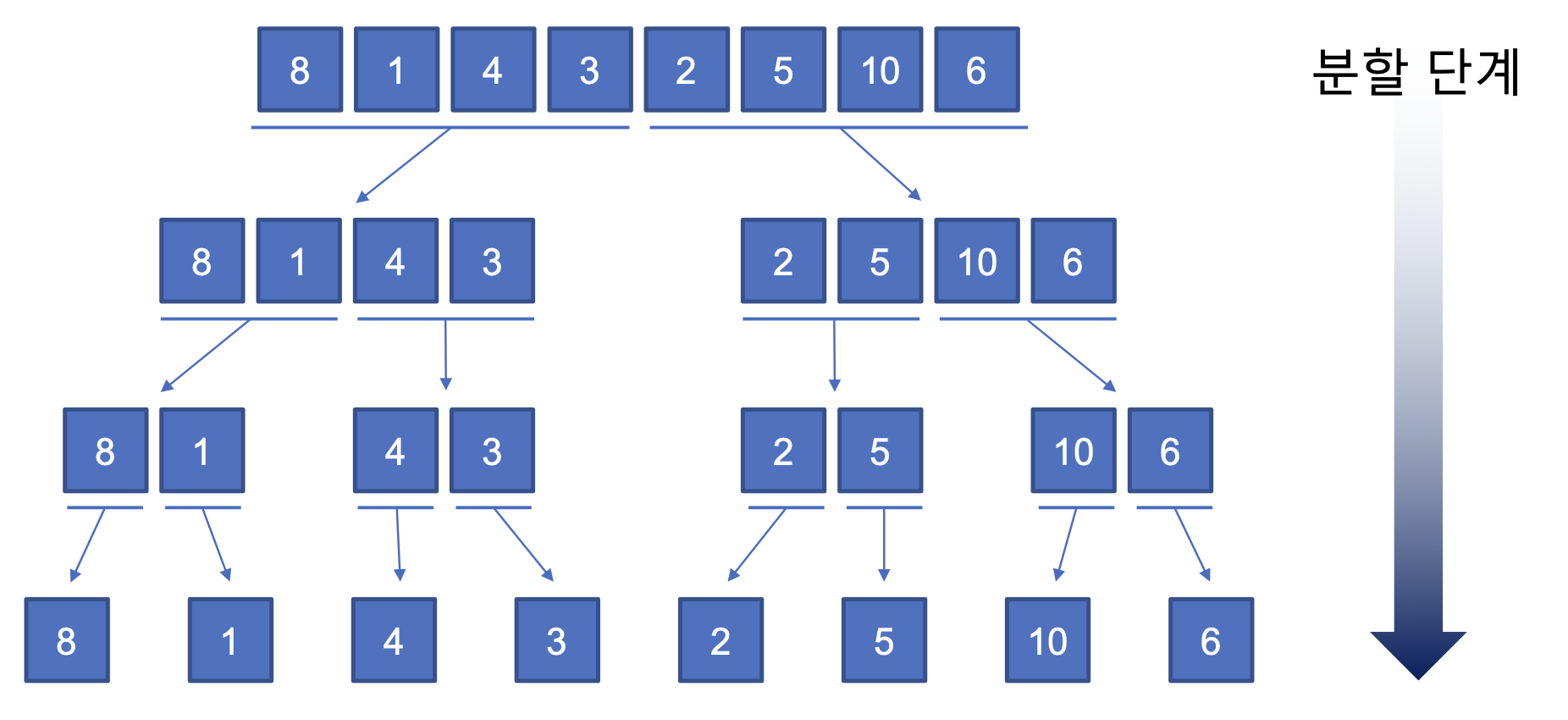
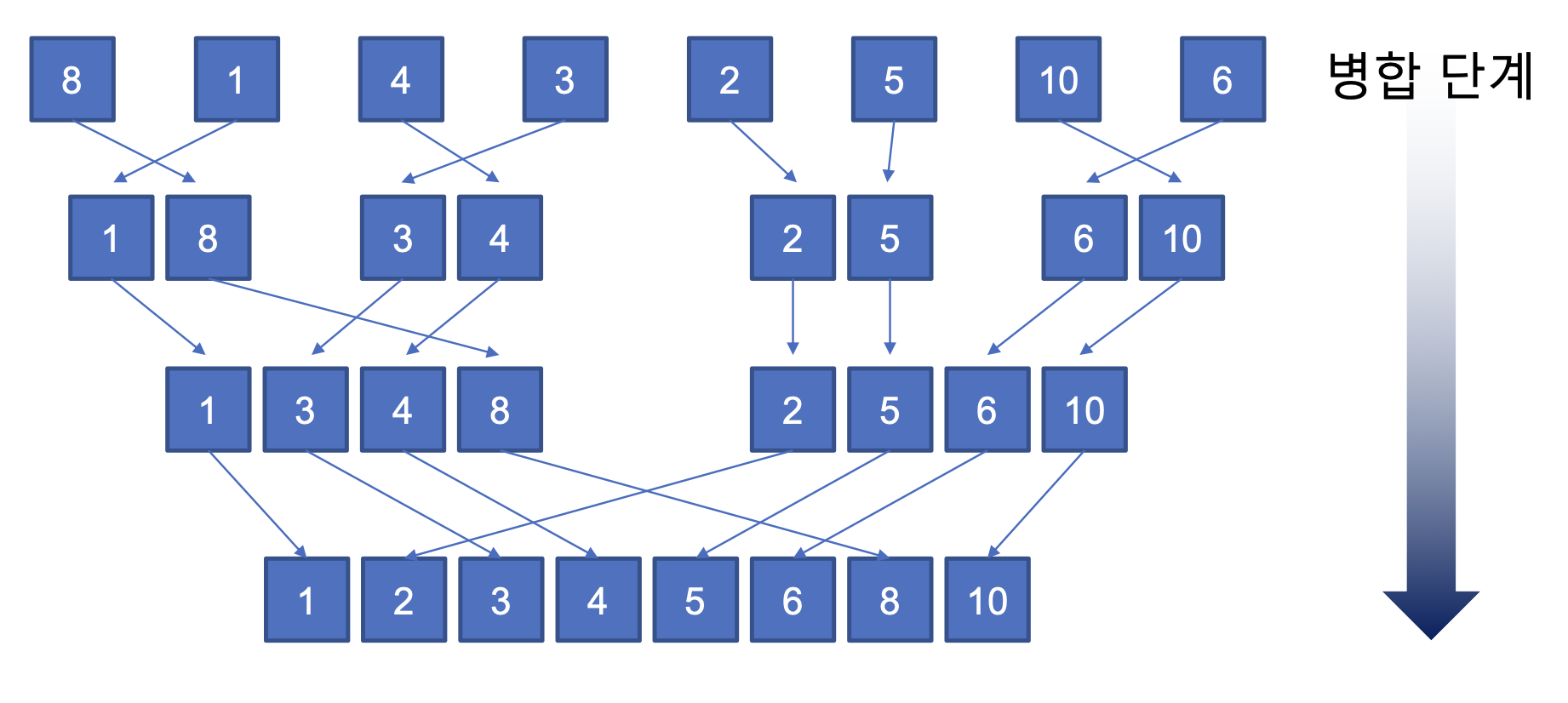
코드
def mSort(ns):
if len(ns) < 2:
return ns
midIdx = len(ns) // 2
leftNums = mSort(ns[0:midIdx])
rightNums = mSort(ns[midIdx:len(ns)])
mergeNums = []
leftIdx = 0; rightIdx = 0
while leftIdx < len(leftNums) and rightIdx < len(rightNums):
if leftNums[leftIdx] < rightNums[rightIdx]:
mergeNums.append(leftNums[leftIdx])
leftIdx += 1
else:
mergeNums.append(rightNums[rightIdx])
rightIdx += 1
mergeNums = mergeNums + leftNums[leftIdx:]
mergeNums = mergeNums + rightNums[rightIdx:]
return mergeNums
nums = [8, 1, 4, 3, 2, 5, 10, 6]
print(f'mSort(nums): {mSort(nums)}')퀵정렬
- 기준 값보다 작은 값과 큰 값으로 분리한 후 다시 합친다.
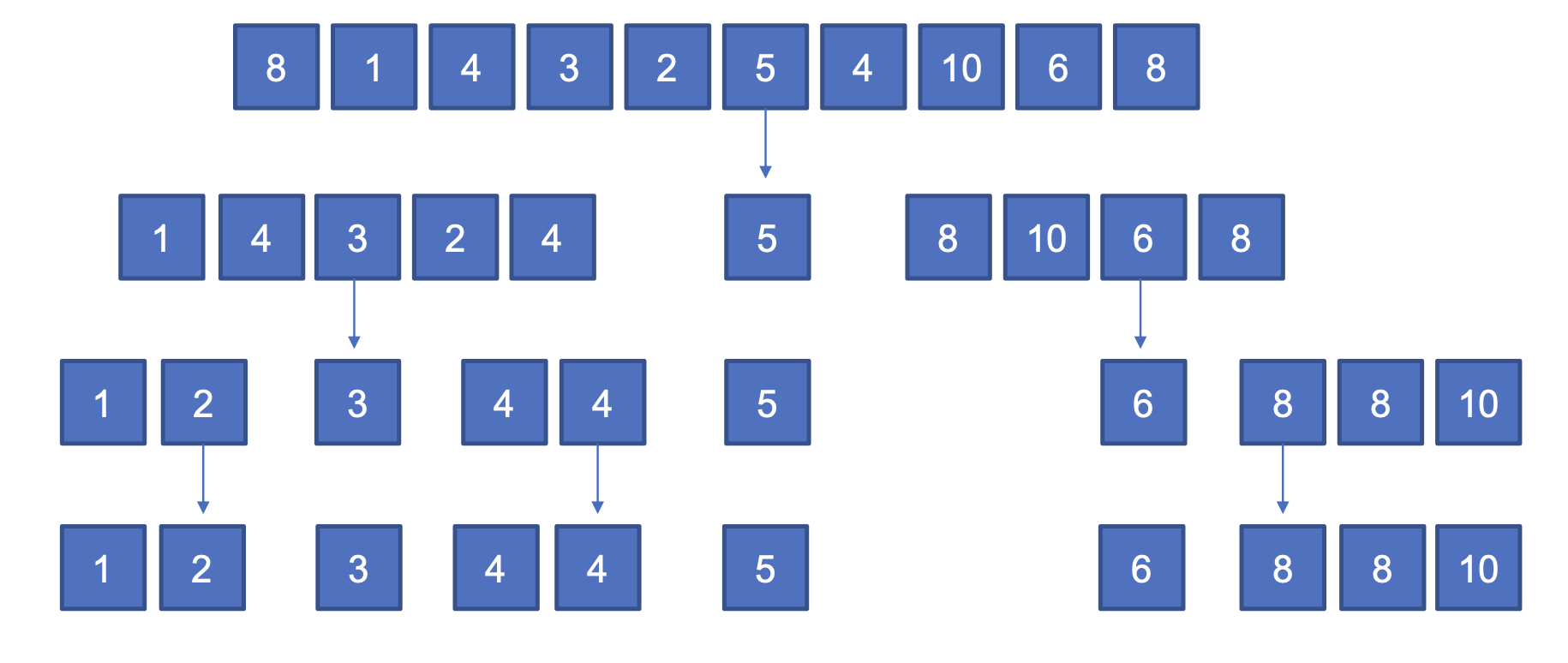
코드
def qSort(ns):
if len(ns) < 2:
return ns
midIdx = len(ns) // 2
midVal = ns[midIdx]
smallNums = []; sameNums = []; bigNums =[]
for n in ns:
if n < midVal:
smallNums.append(n)
elif n == midVal:
sameNums.append(n)
else:
bigNums.append(n)
return qSort(smallNums) + sameNums + qSort(bigNums)
nums = [8, 1, 4, 3, 2, 5, 4, 10, 6, 8]
print(f'qSort(nums): {qSort(nums)}')
10√2 Data