
알아보는 이유
최근 서비스 API를 개선하던 중 가장 사용자가 많이 몰리는 서비스의 과도한 DB 조회 IO 비용이 발생하며 전체 서비스가 느려지는 현상을 발견했습니다.

그럼 이러한 문제를 어떻게 해결할 것인가? 번뜩💥 떠오른 아이디어는 'Cache-Aside 패턴을 적용해보자' 였습니다.
DAU가 50만이 넘어 100만을 향해 가는 서비스에 캐시가 미진하게 적용된 부분이 있다니..놀라며 적극적으로 도입을 시도해보았고, 그 결과는 매우 만족스러웠습니다.
Grafana Dashboard로 30초 이상 걸리는 상품 조회나 기본적인 조회들의 Slow API들을 발견하고 Cache-Aside 패턴을 적용한 결과 Slow API들이 사라졌고, API들의 p50 평균 응답 속도를 5000ms에서 150ms로 감소시키는 결과를 만들어냈습니다.
그 내용을 한 번 교육자료로 만들어 공유를 해볼까 합니다.
왜 데이터베이스만으로는 부족한것인가!!
우리가 일반적으로 서비스를 구축하다보면 당연히 데이터베이스를 활용하게 됩니다.
그리고 그 데이터베이스는 일반적으로 디스크에 데이터를 저장하고, 데이터를 읽을 때마다 디스크I/O 작업이 발생하게 됩니다.
하필 또 그 I/O 작업의 비용이 굉장히도 비싸지요.
이러한 과정이 반복되다보면 여러 이슈들이 발생하게 됩니다.
1. 디스크 I/O의 물리적 한계
데이터베이스가 디스크에 저장된 데이터를 읽을 때 발생하는 성능 문제를 이해하기 위해서는 먼저 디스크와 메모리의 근본적 차이를 알아야 합니다.
일반적인 HDD는 초당 100~200 IOPS(Input/Output Operations Per Second)만 처리할 수 있는 반면, RAM은 초당 수백만 IOPS를 처리할 수 있습니다.
이는 메모리가 디스크보다 수천배 이상 빠르다는 것을 의미하죠.
반면 메모리(RAM)는 전기 신호로 데이터를 읽고 쓰기 때문에 거의 즉시 처리됩니다. 디스크가 기계적 움직임을 필요로 하는 것과 달리, 메모리는 전자적으로 동작하므로 데이터 접근 속도가 극적으로 빠릅니다. 이는 마치 도서관에서 책을 찾을 때 책장을 직접 찾아가야 하는 것과, 컴퓨터에서 파일을 검색하는 것의 차이와 비슷합니다.
2. 네트워크 지연
데이터베이스 서버가 애플리케이션 서버와 물리적으로 분리되어 있는 경우, 네트워크를 통한 통신으로 인해 지연이 발생하게 됩니다. 이 지연은 단순히 데이터를 전송하는 시간 뿐만 아니라 데이터베이스가 쿼리를 파싱하고..실행하고..그 결과를 전송해주는 모든 시간이 포함되게 됩니다.
3. 동시성 문제
만약 데이터베이스가 초당 1,000개의 쿼리만 처리할 수 있는 용량을 가지고 있다면 1만명의 사용자 요청이 동시에 들어올 때 산술적으로 대부분의 사용자는 10초 이상을 기다려야 결과를 받아볼 수 있게 됩니다.
이는 사용자 경험에 치명적인 악영향을 미치게 됩니다.
사용자는 본인의 요청에 대한 응답을 받기까지의 불필요하게 긴 시간을 기다려야만 하고, 이는 서비스 이탈로 직결될 수 있다는 점이 아주 심각한 문제이지요.
Cache-Aside 패턴이 뭐길래?
Cache-Aside 패턴은 애플리케이션이 직접 캐시를 관리하는 패턴입니다. 즉, DB와 함께 Redis나 Valkey 등의 메모리 DB를 캐시로 함께 활용하며 데이터베이스 옆에(Aside) 두고 필요할 때 사용한다고 하여 Cache-Aside 패턴이라고 명명되었습니다.
기본적인 Cache-Aside 패턴의 흐름도는 아래와 같습니다.
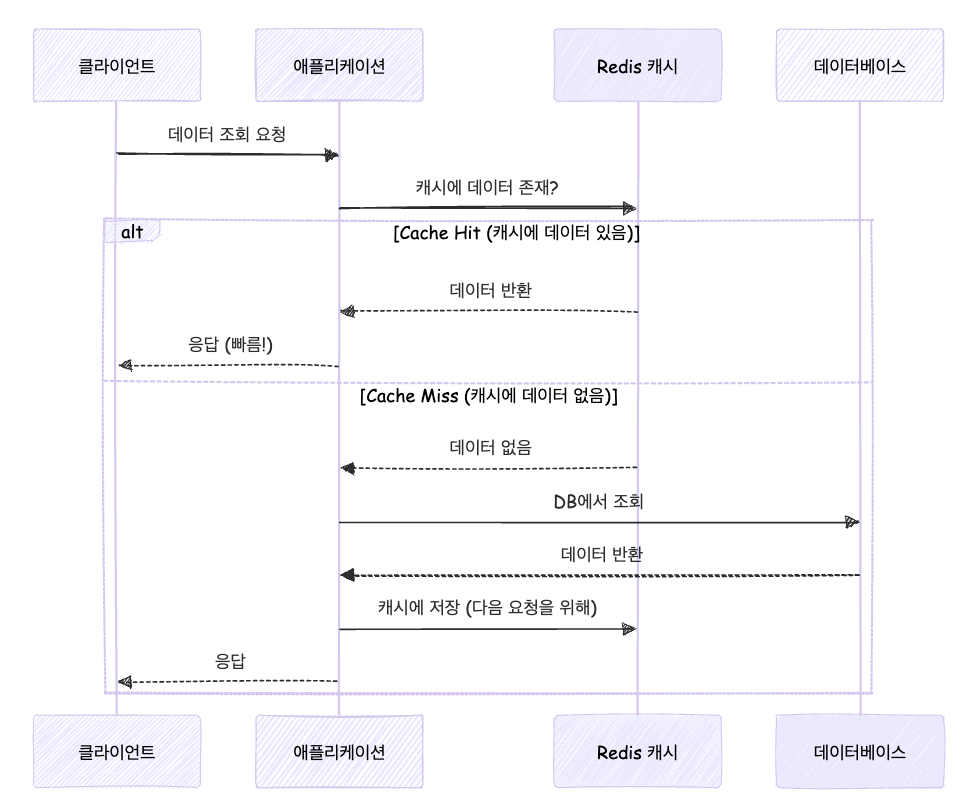
단계별로 한 번 살펴보죠.
1. 캐시 조회
애플리케이션이 먼저 캐시를 확인하여 캐시 내부에 특정 키로 데이터가 존재하는지 확인합니다.
애플리케이션: "Redis에 user:123 데이터가 있나요?"
Redis: "있습니다!" 또는 "없습니다!"실제 코드에서의 구현은 아래와 같이 작업합니다.
// Programmatic 방식 예시
String cacheKey = "user:profile:123";
Object cachedData = redisTemplate.opsForValue().get(cacheKey);
// cachedData가 null이 아니면 Cache Hit, null이면 Cache Miss2. 캐시 조회 결과에 따른 대응
2.1. Cache Hit
캐시에서 해당 데이터가 존재할 경우 애플리케이션은 데이터베이스를 직접 조회할 필요 없이 캐시에서 즉시 데이터를 반환받을 수 있습니다.
이럴 경우 응답시간은 매우 빨라지며 데이터베이스 조회의 비용보다 월등히 아끼게되어 극적인 성능 향상을 가져올 수 있습니다.
또한 데이터베이스에 쿼리를 보내지 않기 때문에 데이터베이스 서버의 부하가 크게 줄어들게 됩니다.
추가로 캐시 서버를 여러대로 분산하여 시스템의 확장성까지 극적으로 향상시킬 수 있습니다.
2.2. Cache Miss
캐시에 데이터가 없는 경우 데이터베이스를 조회해야합니다. 이럴 경우는 대부분 최초의 요청이거나 데이터 변경 이후 신규 데이터에 대한 요청이 대부분일 것이며, TTL 마료 이후 데이터를 조회하는 경우일 것입니다.
이는 일반적은 데이터베이스 조회가 일어난다고 이해할 수 있을 것 같습니다.
3. 캐시 업데이트
만약 데이터의 신규 추가, 업데이트, TTL의 만료 등으로 인해 캐시에 데이터가 없는 상황에서 조회라고 한다면 해당 데이터에 대해서는 데이터베이스 조회 이후 캐시에 업데이트 하는 부분이 추가되어야 합니다.
애플리케이션: "다음 요청을 위해 Redis에 저장하겠습니다"
Redis: "저장 완료!"실제 구현 코드는 다음과 같을 것입니다.
// TTL과 함께 캐시에 저장
redisTemplate.opsForValue().set(
cacheKey, // 키: "user:profile:123"
user, // 값: User 객체
CACHE_TTL_SECONDS, // TTL: 3600초 (1시간)
TimeUnit.SECONDS // 시간 단위
);이후에는 사용자의 요청에 응답을 Return 하면 됩니다.
그럼 Cache-Aside 패턴의 장단점은?
이번에는 Cache-Aside 패턴의 장단점을 살펴보겠습니다.
Cache-Aside 패턴의 장점
1. DB 부하 감소
Cache-Aside 패턴의 가장 큰 장점 중 하나는 데이터베이스 부하를 크게 감소시킬 수 있다는 것입니다. 자주 조회되는 데이터는 캐시에서 제공되기 때문에, 데이터베이스는 실제로 데이터 변경이 필요한 경우에만 접근하게 됩니다. 이를 통해 DB 쿼리 수를 80-90%까지 감소시킬 수 있습니다.
실제 예시를 들어보면, 인기 상품 정보를 1시간에 100만 번 조회한다고 가정했을 때, 캐시를 사용하지 않으면 데이터베이스는 100만 번의 쿼리를 처리해야 합니다. 하지만 캐시를 사용하고 Cache Hit Rate가 90%라면, 실제로 데이터베이스에 전달되는 쿼리는 10만 번으로 줄어듭니다. 이는 90%의 쿼리가 데이터베이스를 거치지 않고 캐시에서 처리되었다는 의미이며, 데이터베이스 서버의 부하를 크게 줄일 수 있습니다.
2. 응답 속도 향상
메모리 기반 캐시는 디스크 기반 데이터베이스보다 수천 배 빠르기 때문에, 캐시를 사용하면 응답 속도가 극적으로 향상됩니다. 데이터베이스에서 직접 조회할 때는 평균 50-100ms가 걸리는 반면, 캐시를 사용하면 1-5ms 정도로 응답할 수 있어 약 95%의 시간이 절약됩니다. 이는 사용자 경험(UX)을 크게 개선하며, 특히 모바일 환경이나 느린 네트워크 환경에서도 빠른 응답을 제공할 수 있게 해줍니다.
3. 유연성 (Flexibility)
Cache-Aside 패턴의 또 다른 중요한 장점은 유연성입니다. 캐시와 데이터베이스가 독립적으로 동작하기 때문에, 캐시가 다운되어도 데이터베이스로 Fallback 할 수 있습니다. 또한 캐시 전략을 자유롭게 변경할 수 있어, 비즈니스 요구사항에 따라 TTL이나 캐시 키 전략을 유연하게 조정할 수 있습니다.
Fallback의 중요성:
Redis 서버가 다운되어도 애플리케이션이 반드시 정상 동작해야 하지요. Cache-Aside 패턴은 이를 가능하게 합니다. 캐시에서 데이터를 조회하려고 시도하다가 실패하면, 자동으로 데이터베이스에서 조회하도록 구현할 수 있습니다:
try {
// 캐시에서 조회 시도
Object cached = redisTemplate.opsForValue().get(cacheKey);
if (cached != null) {
return cached;
}
} catch (Exception e) {
// Redis 다운 시 DB로 Fallback
log.error("Redis 연결 오류. DB로 Fallback", e);
}
// DB에서 조회
return userRepository.findById(id);4. 비용 효율성
Cache-Aside 패턴을 사용하면 비용 측면에서도 큰 이점을 얻을 수 있습니다. 데이터베이스 서버를 스케일 업하거나 아웃하는 것은 상당한 비용이 드는 반면, 캐시 서버는 상대적으로 저렴합니다.
더 중요한 것은 성능 개선 효과입니다. 데이터베이스 서버 확장으로는 2~4배의 성능 개선을 얻을 수 있지만, 캐시 서버 추가로는 10~100배의 성능 개선을 얻을 수 있습니다.
(얼추..저의 계산...입니다.)
이는 투자 대비 효과가 매우 크다는 것을 의미합니다. 가성비가 정말 좋지요!
Cache-Aside 패턴의 단점
1. 초기 지연 (Cold Start)
Cache-Aside 패턴의 첫 번째 단점은 초기 지연, 즉 Cold Start 문제입니다. 첫 번째 요청은 항상 데이터베이스 조회가 필요하기 때문에, 캐시가 비어있을 때는 느린 응답 시간을 경험하게 됩니다. 이는 서비스가 방금 시작되었거나, 캐시가 초기화된 직후에 발생하는 문제입니다.
이 문제를 해결하기 위한 방법으로는 캐시 워밍업(Cache Warming)이 있습니다. 서비스 시작 전에 자주 사용되는 데이터를 미리 캐시에 로드하는 것입니다. 또한 예측적 캐싱을 통해 사용자가 요청할 가능성이 높은 데이터를 미리 캐시에 저장하는 방법도 있습니다. 이를 통해 첫 사용자도 빠른 응답 시간을 경험할 수 있습니다.
2. 데이터 일관성 문제 (Consistency)
Cache-Aside 패턴의 가장 큰 도전 과제 중 하나는 캐시와 데이터베이스 간의 데이터 불일치 가능성입니다. 예를 들어, 데이터베이스에서 데이터를 업데이트했지만 캐시는 여전히 이전 데이터를 유지하고 있을 수 있습니다. 이는 사용자에게 오래된 정보를 보여주는 결과를 초래할 수 있습니다.
이 문제를 해결하기 위해서는 데이터 업데이트 시 캐시를 무효화(Invalidation)하는 것이 필수적입니다! 또한 TTL(Time To Live)을 설정하여 일정 시간이 지나면 자동으로 캐시가 만료되도록 할 수 있습니다.
이를 통해 일정 시간 내에는 최신 데이터로 갱신되도록 보장할 수 있습니다.
3. 캐시 관리 복잡도
Cache-Aside 패턴을 사용하면 애플리케이션 코드에서 캐시 로직을 직접 관리해야 합니다. 캐시 키 설계, TTL 설정, 캐시 무효화 전략 등 고려해야 할 사항이 증가합니다. 이는 코드의 복잡도를 높이고, 개발자가 더 많은 것을 신경 써야 한다는 의미입니다.
복잡도를 줄이기 위한 방법으로는 Spring의 @Cacheable 어노테이션과 같은 캐시 추상화를 사용하는 것이 있습니다. 또한 캐시 로직을 별도의 캐시 매니저 클래스로 분리하여 관리할 수 있습니다. 마지막으로 프로젝트 전체에서 일관된 키 네이밍 규칙을 사용하여 캐시 키를 표준화하는 것도 중요합니다.
개인적으론 직접 구현하는 방식(Programmatic)을 더 선호하긴 합니다.
4. 메모리 사용량
캐시는 메모리에 데이터를 저장하기 때문에, 캐시 서버의 메모리 제한이 있습니다. 만약 메모리가 부족해지면 Eviction(캐시 제거) 정책에 따라 오래된 데이터가 자동으로 제거됩니다. 이는 Cache Miss를 증가시킬 수 있습니다.
메모리를 효율적으로 관리하기 위해서는 TTL을 적절히 설정하여 오래된 데이터가 자동으로 삭제되도록 해야 합니다. 또한 LRU(Least Recently Used)나 LFU(Least Frequently Used)와 같은 적절한 Eviction Policy를 선택해야 합니다.
마지막으로 캐시 메모리 사용량을 지속적으로 모니터링하여 메모리 부족 상황을 미리 감지하고 대응할 수 있어야 합니다.
이번 포스팅에선 Cache-Aside가 무엇이고 왜 써야 하는지에 대해서 간략하게 알아보았습니다.
긴 글 읽어주셔서 감사드립니다! 🫡
