
항상 주요하게 사용되는 락의 개념들 중 분산락이라는 개념이 있습니다.
오늘은 그 중 분산락에 대해 간략히 알아봅니다.
락(Lock)이란 무엇일까?
먼저 일상생활에서 간단한 예제를 통해 락의 개념을 알아보도록 하죠.
조금 그렇긴(?) 하지만..🫥 화장실을 예시로 한 번 들어보도록 하겠습니다.
철수, 영철, 민수는 화장실이 모두 급합니다. 하지만 화장실 칸이 하나만 있다고 해보죠.
그럴 때 철수가 화장실에 들어가고 문을 잠그면(락 획득) 영철이와 민수는 화장실에 접근할 수 없게 됩니다.
밖에서 대기를 해야하지요.
철수가 사용을 다 하고 개운한 표정으로 문을 열고 나오면(락 해제) 먼저 줄서있던 영철이가 들어가서 문을 잠급니다(락 획득).
이처럼 락은 공유 자원에 대해 한 번에 하나의 주체만 접근할 수 있도록 제어하는 메커니즘을 일컫습니다.
효율적으로 일정 시간동안 점유해서 사용하는거죠.
프로그래밍에서의 락
프로그래밍에서 락은 여러 스레드나 프로세스가 동시에 같은 자원이나 데이터에 접근할 때 발생하는 문제를 미연에 방지하는 역할을 합니다.
기본적으로 자바에서는 synchronized 키워드를 통해 락을 획득할 수 있습니다.
public class Counter {
private int count = 0;
// synchronized 키워드로 락 적용
public synchronized void increment() {
count++; // 한 번에 하나의 스레드만 실행 가능
}
public synchronized int getCount() {
return count;
}
}만약 위 increment 메소드에 synchronized키워드로 락을 설정하지 않았을 경우를 살펴보겠습니다.
// ❌ 락이 없는 경우 - 문제 발생!
public class UnsafeCounter {
private int count = 0;
public void increment() {
count++; // 이 연산은 실제로 3단계로 나뉨
// 1. count 값을 읽음 (READ)
// 2. 1을 더함 (ADD)
// 3. 결과를 저장 (WRITE)
}
}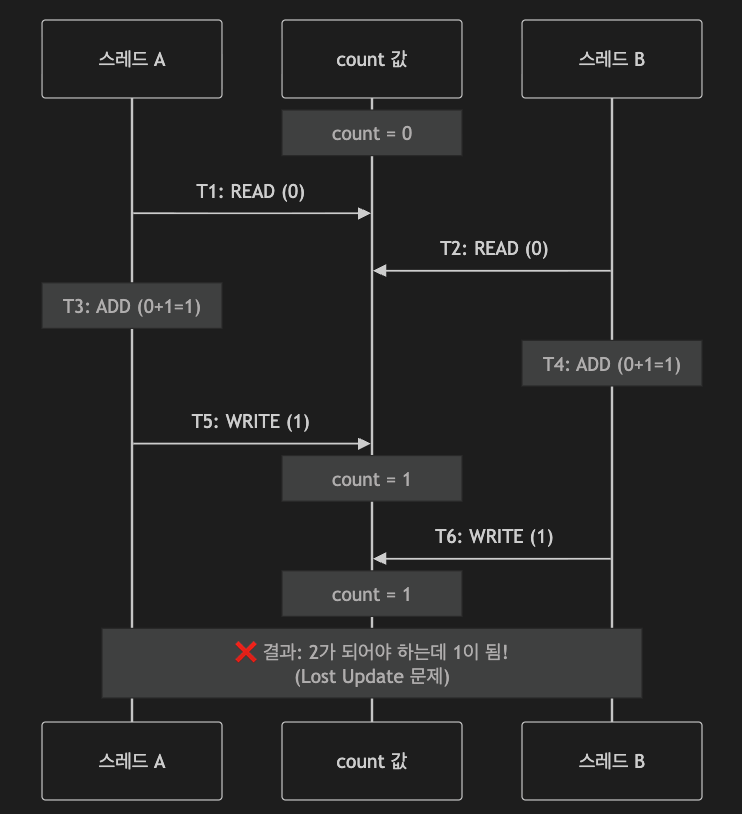
위 시퀀스 다이어그램처럼 결과적으론 2가 되어야 하는데 여전히 카운트가 1인 문제가 발생하게 됩니다.
동시에 접근을 해서 +1씩 하지만 결국 초기 값은 모두 0이었기 때문이죠.
기본적으로 synchronized나 ReentrantLock은 단일서버 환경에서 가장 쉽게 락을 구현할 수 있는 방법입니다.
// 단일 서버에서는 이것으로 충분
private final ReentrantLock lock = new ReentrantLock();
public void processPayment() {
lock.lock();
try {
// 결제 처리 로직
} finally {
lock.unlock();
}
}하지만 본격적인 락 문제는 분산 서버 환경에서 대부분 발생하게 됩니다.
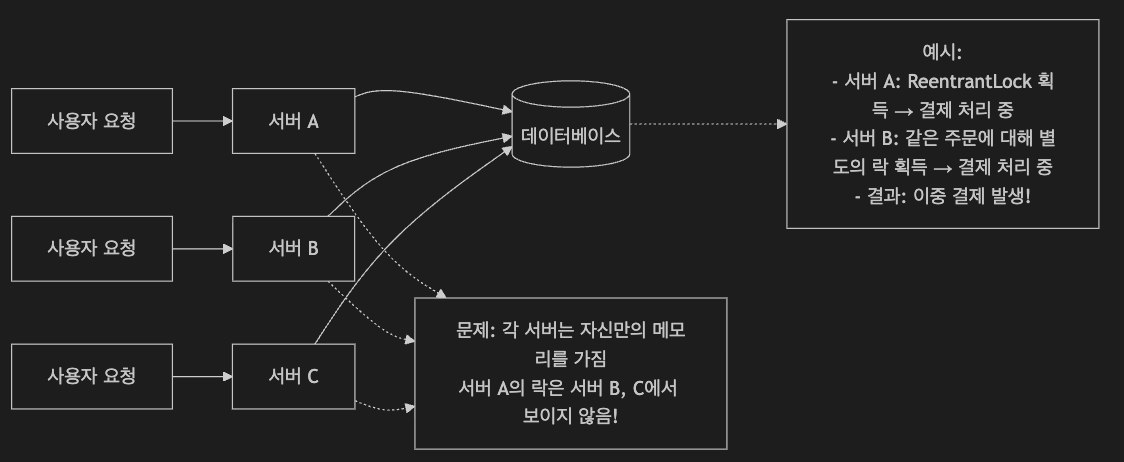
위 도식화된 그림에서 보이는 것 처럼 결국 서버 A와 B그리고 C 모두 각각의 주문에 대한 정보를 처리하기 위해 별도의 락을 생성하게되고, 이렇게 결제가 중복으로 처리되게되면 데이터의 정합성이 깨지게 됩니다.
그럼 왜 분산락이 필요한가?
한 번 예시를 들어서 생각해보죠.
온라인 쇼핑몰이 있습니다. 거기에 철수는 적립금(포인트)를 보유하고 있는 상황입니다.
철수는 이번 쇼핑에서 이 포인트를 사용할 겁니다.
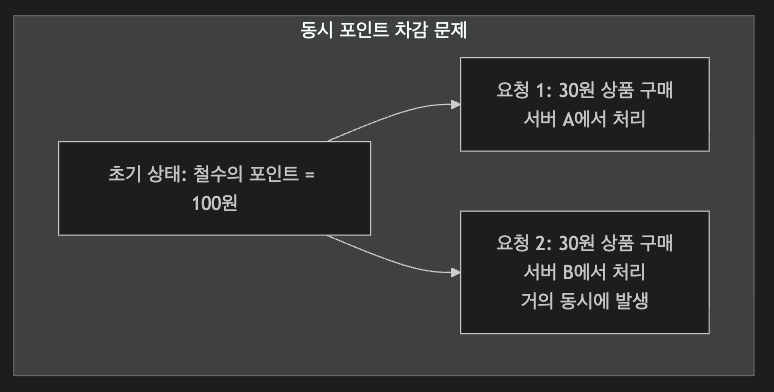
철수가 중복으로 요청한 프로세스가 각각의 서버(A와 B)에서 수행되다보니 서로의 락을 확인하지 못하고 동시에 30원짜리 상품을 구매하게되고, 각각의 서비스 결과로 포인트는 70원이 남게되는 현상이 발생되게 됩니다.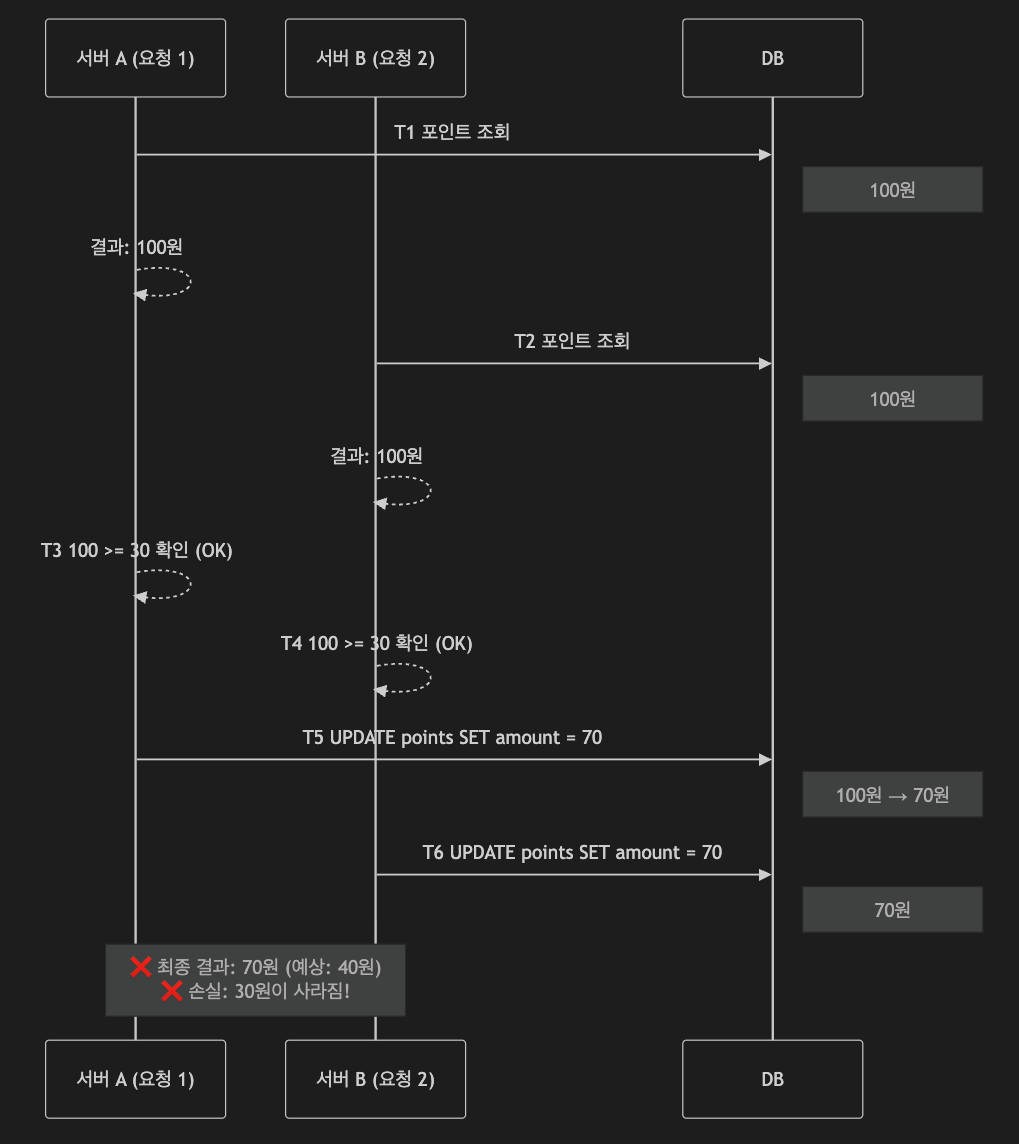
이 상황을 코드로 한 번 보겠습니다.
@Service
public class PointService {
@Autowired
private PointRepository pointRepository;
// ❌ 문제가 있는 코드 - Race Condition 발생!
@Transactional
public void deductPoints(Long userId, int amount) {
// 1. 현재 포인트 조회
Point point = pointRepository.findByUserId(userId);
// 2. 잔액 확인
if (point.getAmount() < amount) {
throw new InsufficientBalanceException("잔액 부족");
}
// 3. 포인트 차감
// 이 사이에 다른 서버에서 같은 사용자의 포인트를 조회할 수 있음!
point.setAmount(point.getAmount() - amount);
pointRepository.save(point);
}
}여기서 Race Condition이 발생하며 최종적인 결과가 예상하지 못한(70원이 남아버리는!) 상황이 되는 것이죠.
여기서 Race Condition이란 두 개 이상의 프로세스나 스레드가 공유 자원에 동시에 접근할 때 실행 순서에 따라 결과가 달라지는 상황을 말합니다.
그럼 여기서 분산락을 적용하면 어떤식으로 결과가 바뀌게 될까요?
간단하게 도식화해서 보겠습니다.
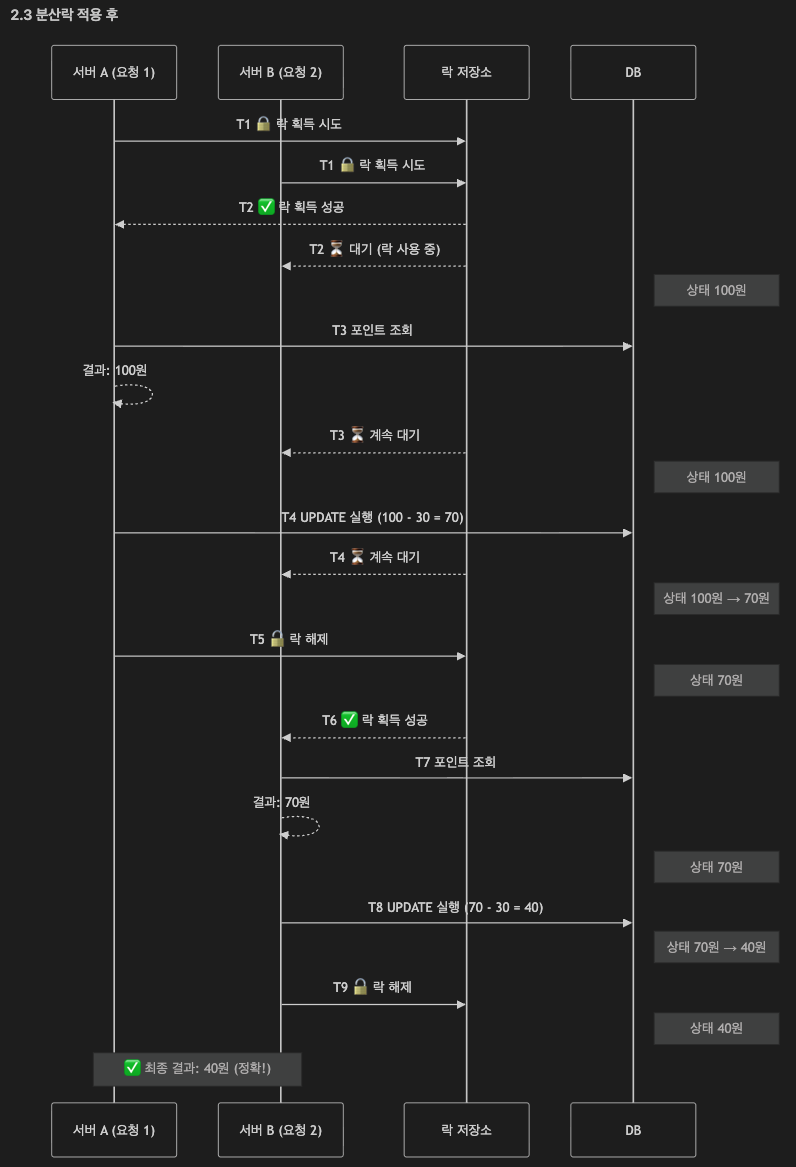
위 처럼 락 획득에 대한 별도의 저장소를 두어 저장소에서 락을 관리하고 순서에 맞게 자원에 접근할 수 있게끔 하는 방식을 분산락이라고 합니다.
분산락(Distributed Lock)
분산락을 다시 정의해보면 분산 시스템 환경에서 여러 서버(노드)가 공유 자원에 대한 경쟁적 접근을 조율하기 위해 사용하는 동기화 메커니즘입니다.
앞서 살펴봤던 것처럼 단일 서버의 경우라면 synchronized 키워드만으로도 충분하지만 여러 서버가 공유할 수는 없습니다. 그렇기 때문에 중앙에 별도의 락 저장소를 두게됩니다.
일반적으로 락 저장소로 사용되는 것은 Redis가 대표적이며 Zookepper 등도 사용되곤 합니다.
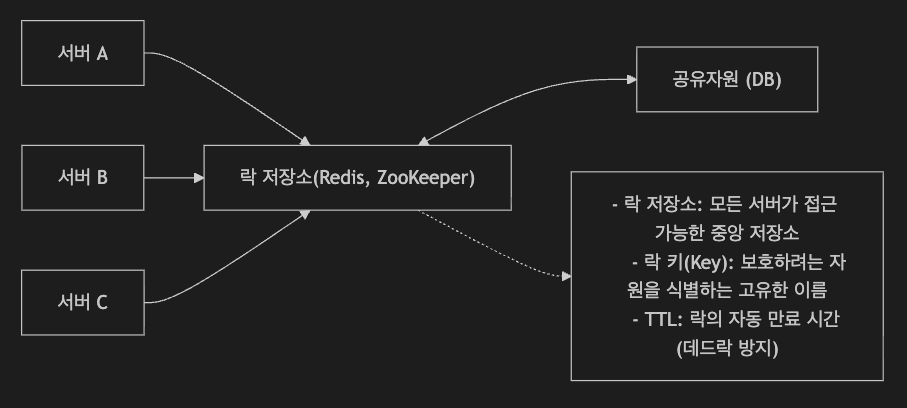
모든 서버는 Redis로 대표되는 락 저장소에 접근하여 락을 획득하고, 그 락을 가지고 공유자원을 호출하는 내부 서비스로 통신을 이어가게 됩니다. 즉, Redis를 개찰구로 활용하는 방식이죠.
분산락을 사용했을 때 분산락의 생명주기는 아래와 같습니다.
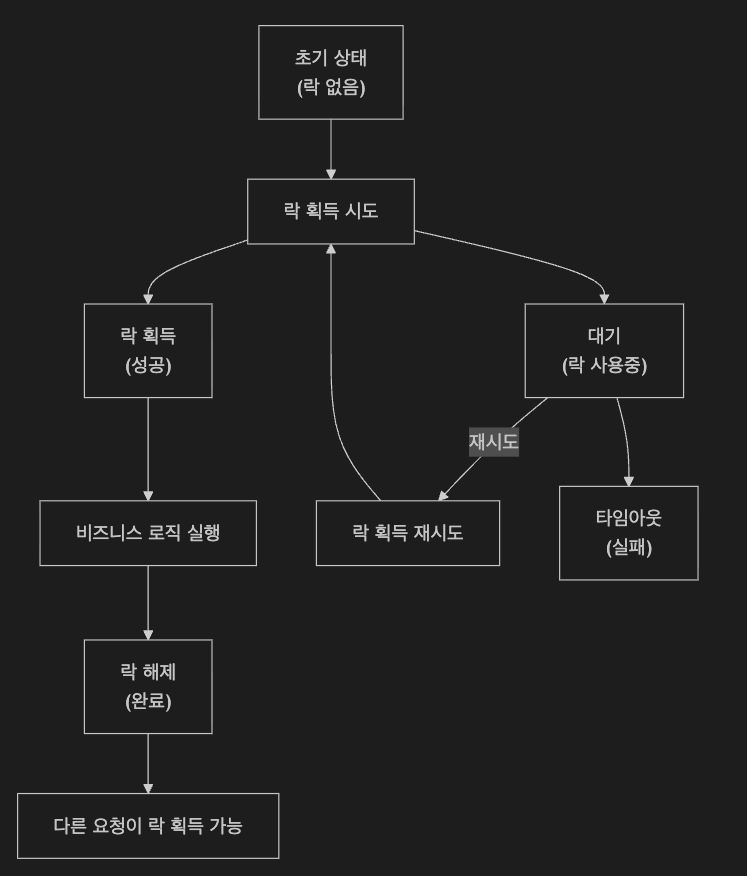
분산락 환경에서 자주 사용하는 문구는 아래와 같습니다.
| 용어 | 영문 | 설명 | 예시 |
|---|---|---|---|
| 락 키 | Lock Key | 락을 식별하는 고유한 문자열 | user:123:point:lock |
| TTL | Time To Live | 락의 자동 만료 시간 | 30초 |
| 획득 | Acquire | 락을 잡는 것 | lock.tryLock() |
| 해제 | Release | 락을 풀어주는 것 | lock.unlock() |
| 재시도 | Retry | 락 획득 실패 시 다시 시도 | 최대 3회 재시도 |
| 대기 시간 | Wait Time | 락 획득을 위해 대기하는 최대 시간 | 5초 |
| 임대 시간 | Lease Time | 락을 보유할 수 있는 최대 시간 | 30초 |
일반적으로 위 내용 중 락 키(Lock Key)에 무엇을 보호할 것인가를 정의하는 가장 확실한 방법입니다.
잘못된 락 키 설계는 성능 문제 뿐만 아니라 동시성 문제까지 일이킬 수 있다는 점을 명심해야 합니다.
아래처럼 너무 넓은 범위의 키 값을 생성하면 성능에 저하를 불러일으킬 수 있습니다.
// 모든 사용자의 포인트 작업이 직렬화됨 - 성능 저하!
String lockKey = "point-lock";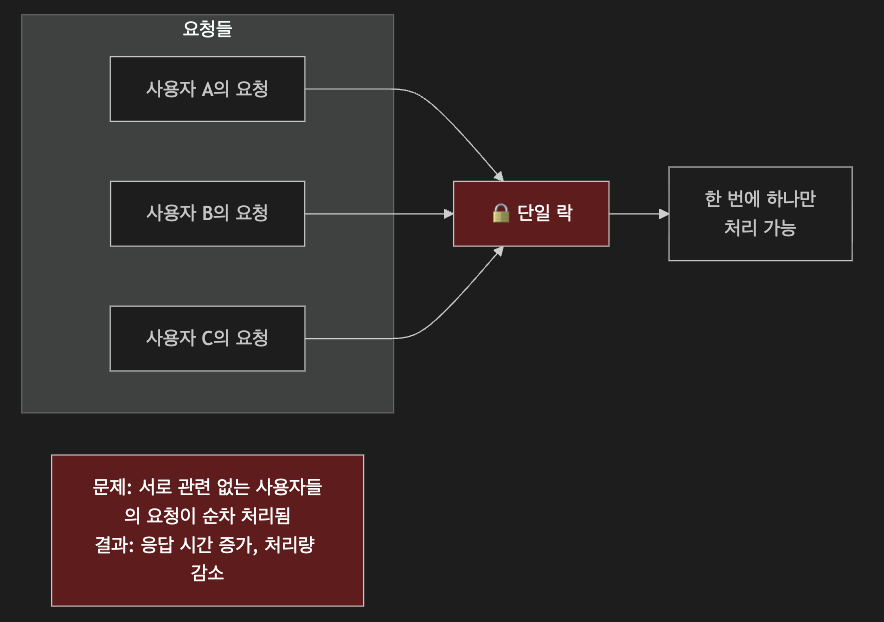
올바르게 적절한 범위의 락키를 활용할 경우 분산락 환경에서 유용하게 사용할 수 있습니다.
// 사용자별로 독립적인 락 - 다른 사용자 영향 없음
String lockKey = "user:" + userId + ":point:lock";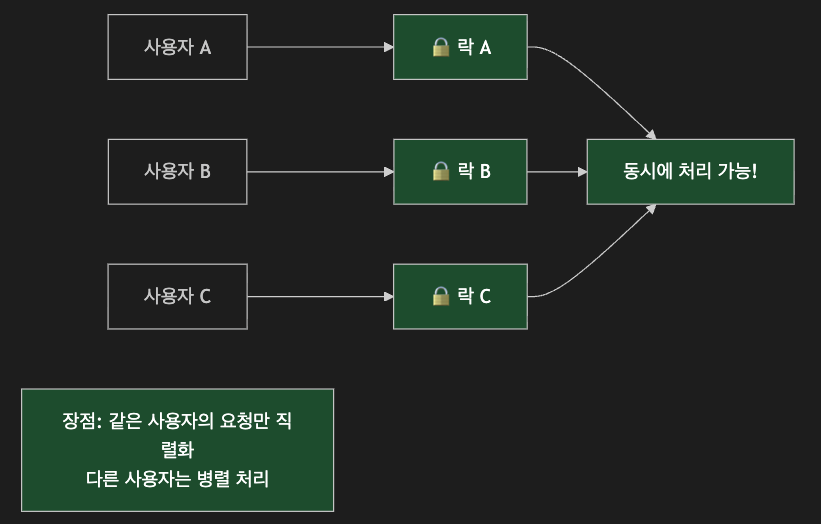
마치며.
이번엔 분산락에 대해 간략하게 알아보았습니다.
분산락이 왜 필요한지, 그리고 어떤 환경에서 사용이 되는지에 대해 알 수 있었습니다.
다음 글에서는 본격적으로 분산락을 Redis로 어떻게 구현하는지에 대해 알아보도록 하겠습니다.
긴 글 읽어주셔서 감사드립니다!🫡
