1. Scaling 종류
a. Scale up/down
서비스 운영 중 트래픽 증가로 인해 서버의 CPU, 메모리, 저장공간과 같은 기존 시스템의 성능을 높이는 방식으로 Scale up을 시도합니다. 하지만 CPU, 메모리는 일정 수준 이상으로는 비용 대비 성능 증가 폭이 작습니다. 또한 이렇게 구축한 시스템은 높은 초기 비용을 요구하는 문제가 있습니다. 이후 서비스 트래픽이 감소하여 Scale down을 해야하는 경우 기존에 구축한 비용이 낭비되는 단점이 있습니다.
b. Scale in/out
Scale up/down의 문제로 인해 Scale in/out 방식이 대안으로 존재합니다. 하나의 서버 성능을 높이는 Scale up과 달리 Scale out은 비슷한 성능의 서버를 병렬적으로 배치합니다. 이런 병렬적인 확장을 위해 로드밸런서와 같은 트래픽 분산 장치가 필수적입니다. 이런 병렬적 시스템 확장을 통해 가격 대비 성능 향상 효과가 높습니다. (진짜로?)
이와 같이 Scale out으로 확대된 시스템은 Scale in을 통해 서비스를 축소할 때도 효과적입니다. 전체 시스템을 변경하는 것이 아닌 병렬적으로 배치된 시스템의 여러 서버 중 일부 서버를 제거하여 시스템의 크기를 줄일 수 있습니다. 이를 통해 최소한의 비용으로 시스템의 크기를 줄일 수 있습니다.
결론적으로 Scale up/down 보다 Scale in/out으로 탄력적인 시스템 관리가 가능해집니다. 또한 여러대의 서버로 트래픽을 분산하여 시스템 안정성을 높일 수 있습니다. 하지만, 그와 동시에 병렬 처리를 위한 복잡한 아키텍쳐를 이해하고 로드밸런서와 같은 장비를 운용해야한다는 부담이 존재합니다.
2. 어떤 상황에 무엇을 사용해야하나?
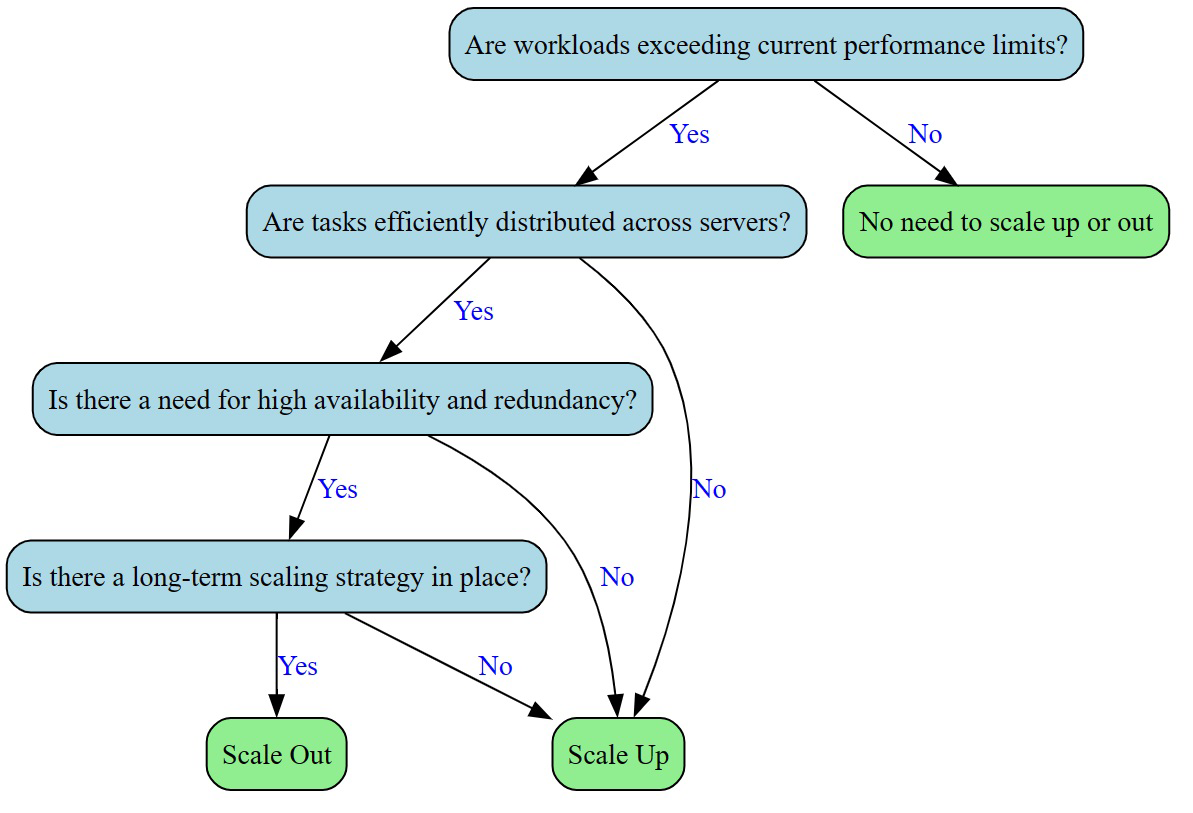
위 그림은 시스템 확장에 대한 의사결정 다이어그램입니다. 다음의 기준에 따라 수직적 확장과 수평적 확장 중 하나를 결정할 수 있겠습니다.
- 워크로드가 현재 성능을 초과하는지
- 작업이 서버에 효율적으로 분산되어있는지
- 고가용성과 중복성이 필요한지
- 장기적인 확장 전략이 있는지
출처

아니요