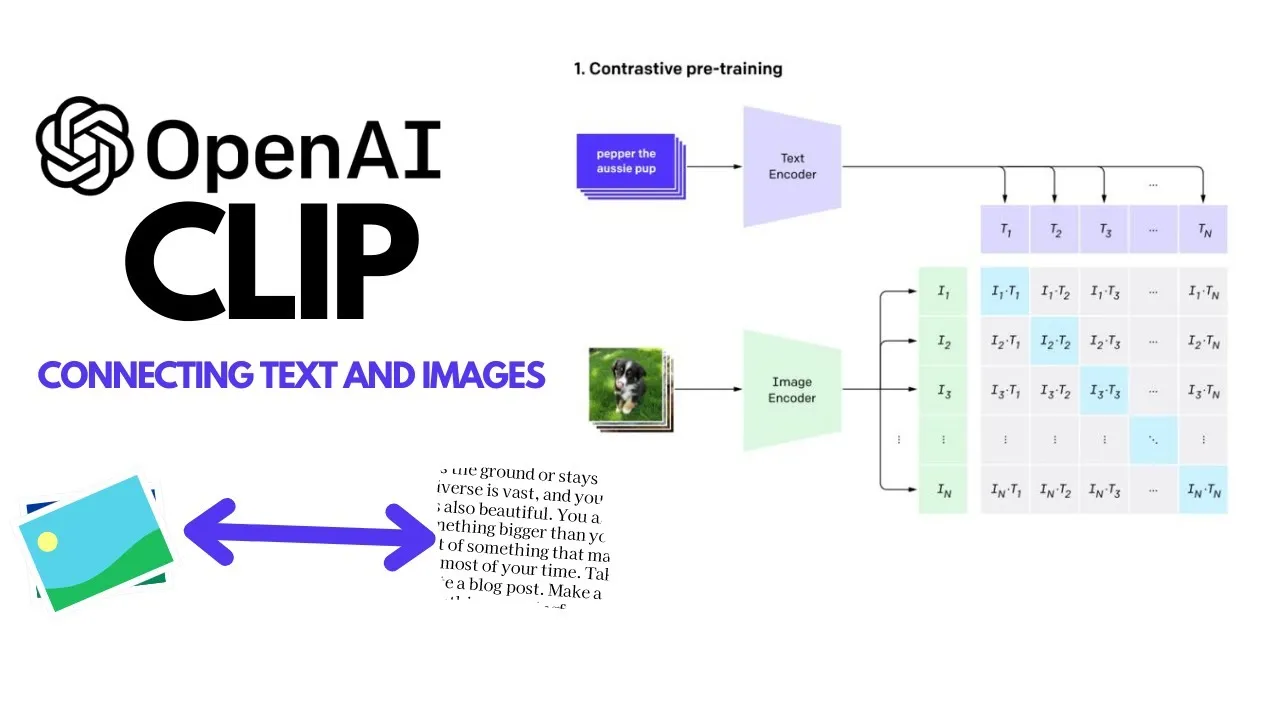
출처: https://mlubbad.com/a-beginners-guide-to-the-clip-model-57fec7613ff5
💡 시작하게 된 계기
최근 A Survey on Multimodal Large Language Models 논문 리뷰 후 멀티모달 분야에서는 학습 데이터의 품질이 중요하다는 것을 느꼈다. 논문에서는 학습 데이터 수집을 위해 웹 상의 이미지-텍스트 쌍의 데이터를 수집한 후 다양한 필터링 방법으로 데이터를 정제한다고 말한다. 그래서 이번 글에서는 다양한 필터링 방법 중 CLIP 모델을 활용하여 이미지-텍스트 유사도를 통한 필터링 과정을 실습해보려 한다.
🛠️ 1. 실습 환경 준비하기
가장 먼저 실습을 위한 파이썬 가상 환경을 설정하고 필요한 라이브러리를 설치합니다. 저는 conda를 사용했습니다.
🔷 1-1 Conda 가상 환경 생성 및 활성화
# 가상환경 만들기
conda create -n clip_filtering_project python=3.10
# 가상환경 설정
conda activate clip_filtering_project🔷 1-2 필수 라이브러리 설치
# 필요한 라이브러리 설치
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip install transformers pillow numpy matplotlib seaborn tqdm📕 라이브러리 설명
torch,torchvision,torchaudio: PyTorch 딥러닝 프레임워크. GPU 사용 여부에 따라 설치 명령이 달라집니다.transformers: Hugging Face의 라이브러리로, 미리 학습된 CLIP 모델을 쉽게 로드하고 사용할 수 있게 해줍니다.pillow: 파이썬 이미지 처리 라이브러리 (PIL의 후속). 이미지 파일을 로드하고 조작하는 데 사용됩니다.numpy: 파이썬의 핵심 과학 계산 라이브러리. 배열 및 행렬 연산에 사용됩니다.matplotlib,seaborn: 데이터 시각화 라이브러리. 히스토그램 등을 그릴 때 사용됩니다.tqdm: 반복문의 진행 상황을 보여주는 멋진 진행 바를 생성합니다 (선택 사항이지만 유용합니다).
📁 2. 데이터셋 준비: Flickr8k 선택
실습 목표(CLIP 필터링 원리 이해)에 집중하기 위해 작고 접근성이 좋은 Flickr8k 데이터셋을 사용했습니다.
Flickr8k는 8,000개의 이미지에 각 5개씩의 캡션이 있는 약 4만 쌍의 이미지-캡션 데이터셋입니다.
저는 Kaggle에서 adityajn105/flickr8k 데이터셋을 직접 다운로드하여 CLIP/data/Flickr8k_Dataset 경로에 압축을 풀었습니다.
링크: https://www.kaggle.com/datasets/adityajn105/flickr8k
🔷 2-1 폴더 구조
CLIP/ 프로젝트의 최상위 폴더
├── data/
│ └── Flickr8k_Dataset/
│ ├── Flicker8k_image/ 이미지 파일들 (JPG)
│ └── captions.txt 캡션 텍스트 파일
└── CLIP_filter.py 파이썬 스크립트 파일
🔷 2-2 Raw data 형태
mage,caption
1000268201_693b08cb0e.jpg,A child in a pink dress is climbing up a set of stairs in an entry way .
1000268201_693b08cb0e.jpg,A girl going into a wooden building .
1000268201_693b08cb0e.jpg,A little girl climbing into a wooden playhouse .
1000268201_693b08cb0e.jpg,A little girl climbing the stairs to her playhouse .
1000268201_693b08cb0e.jpg,A little girl in a pink dress going into a wooden cabin .
1001773457_577c3a7d70.jpg,A black dog and a spotted dog are fighting
1001773457_577c3a7d70.jpg,A black dog and a tri-colored dog playing with each other on the road .
1001773457_577c3a7d70.jpg,A black dog and a white dog with brown spots are staring at each other in the street .
1001773457_577c3a7d70.jpg,Two dogs of different breeds looking at each other on the road .
1001773457_577c3a7d70.jpg,Two dogs on pavement moving toward each other .💻 3. 코드 작성하기
전체 코드는 아래 제 GitHub 리포지토리에서 확인하실 수 있습니다.
🔗 링크: https://github.com/Woosci/Model-Study/tree/main/CLIP
🔷 3-1 경로설정
import os
# 파이썬 스크립트가 운영체제(예: Windows)와 상호작용할 수 있는 다양한 기능을 제공합니다.
# 쉽게 말해, 파이썬 코드로 컴퓨터의 파일 시스템(폴더와 파일)을 다루는 작업을 할 수 있게 해줍니다
from PIL import Image
# 파이썬 이미지 라이브러리(Python Imaging Library), 이미지 파일을 다루는 데 사용되는 강력한 외부 라이브러리
from tqdm import tqdm
# CLIP 모델 임베딩 계산 시 사용
# --- 설정 (Flickr8k에 맞게 수정) ---
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
# __file__은 현재 실행되고 있는 파이썬 스크립트 파일의 이름(경로 포함)
# os.path.abspath() 함수는 주어진 경로를 절대 경로(absolute path)로 변환
# 주어진 경로에서 디렉토리(폴더) 부분만 추출합니다. 즉, 파일 이름을 제외한 폴더 경로를 반환
DATA_ROOT_DIR = os.path.join(BASE_DIR, 'data', 'Flickr8k_Dataset')
# BASE_DIR (CLIP 폴더 경로)에 data 폴더와 Flickr8k_Dataset 폴더를 순서대로 합쳐서,
# Flickr8k 데이터셋의 모든 이미지와 캡션 파일이 들어있는 최상위 폴더(CLIP/data/Flickr8k_Dataset)의 절대 경로를 DATA_ROOT_DIR 변수에 저장
# 아래 두 줄은 사용자님의 실제 파일 이름에 맞춰 수정된 것입니다.
IMAGES_DIR = os.path.join(DATA_ROOT_DIR, 'Flicker8k_image') # 이미지들이 들어있는 폴더 경로 (Flicker8k_image)
CAPTIONS_FILE = os.path.join(DATA_ROOT_DIR, 'captions.txt') # 캡션 텍스트 파일 경로 (captions)
# 경로가 올바로 설정되었는지 확인합니다.
print(f"이미지 디렉토리: {IMAGES_DIR}")
print(f"캡션 파일: {CAPTIONS_FILE}")🔷 3-2 데이터 로드
# --- Flickr8k 데이터셋 로드 ---
print("\nFlickr8k 데이터셋 로드 중...")
image_caption_pairs = []
# 이미지 경로, 캡션 텍스트, 이미지 ID를 저장할 리스트. 각 요소는 딕셔너리 형태.
try:
with open(CAPTIONS_FILE, 'r', encoding='utf-8') as f:
# caption 파일을 읽기모드 r로 변환한 후, 인코딩을 utf-8로 지정한다.
# 첫 줄 (헤더) 건너뛰기
header = f.readline()
# 파일에서 한 줄을 읽어온다. 여기서는 첫 번째 줄을 읽어온다.
# 데이터의 첫 줄이 image,caption이라 확인하는 단계
if header.strip() != "image,caption": # 헤더가 예상과 다르면 경고
print(f"경고: 캡션 파일의 헤더가 'image,caption'이 아닐 수 있습니다: {header.strip()}")
for line in f:
parts = line.strip().split(',', 1)
# 쉼표(,)로 분리
# 첫 번째 쉼표까지만 분리하여 캡션 안에 쉼표가 있어도 문제 없도록
# 데이터가 1000268201_693b08cb0e.jpg,A girl going into a wooden building . 형태로 저장되어 있어서 ,를 기준으로 2개의 part로 저장.
if len(parts) == 2:
image_filename, caption_text = parts
image_path = os.path.join(IMAGES_DIR, image_filename)
image_caption_pairs.append({'image_path': image_path, 'caption': caption_text, 'image_id': image_filename})
# {'image_path':이미지 경로,'caption': caption(이미지에 대한 설명),'image_id':파일명} 형태로 저장.
print(f"총 {len(image_caption_pairs)} 개의 이미지-캡션 쌍 로드됨.")
except FileNotFoundError:
# 파이썬에서 파일을 열거나 접근하려 할 때, 해당 경로에 파일이 존재하지 않을 경우 발생하는 특정 유형의 오류
# 만약 try 블록(캡션 파일을 open()하여 읽는 부분)을 실행하는 도중 FileNotFoundError가 발생하면,
# 파이썬은 즉시 현재 실행 중인 코드를 멈추고 이 except FileNotFoundError: 블록으로 점프하여 안의 코드를 실행
print(f"오류: 캡션 파일을 찾을 수 없습니다. 경로를 확인하세요: {CAPTIONS_FILE}")
print("Flickr8k 데이터셋 다운로드 및 압축 해제가 제대로 되었는지, 그리고 경로 설정이 올바른지 확인해주세요.")
exit()
# exit() 함수는 현재 파이썬 스크립트를 강제로 종료
except Exception as e:
# exception: 파이썬에서 발생하는 모든 종류의 예외(오류)를 포괄하는 가장 일반적인 예외 클래스
print(f"데이터셋 로드 중 예상치 못한 오류 발생: {e}")
exit()
# --- 초기 데이터셋 샘플 확인 ---
print("\n--- 데이터셋 샘플 (상위 5개) ---")
sample_pairs = image_caption_pairs[:5]
# data 5개만 sample_pairs에 저장.
for i, pair in enumerate(sample_pairs):
# enumerate(): 리스트의 요소와 그 인덱스를 동시에 반환
img_path = pair['image_path']
caption = pair['caption']
image_id = pair['image_id']
print(f"샘플 {i+1} - 이미지 ID: {image_id}")
print(f" 이미지 경로: {img_path}")
print(f" 캡션: {caption}")
try:
with Image.open(img_path).convert("RGB") as img:
# Image.open(img_path)로 이미지 파일을 엽니다.
# .convert("RGB")는 이미지를 3채널 RGB 형식으로 변환합니다.
# 만약 이미지가 그레이스케일(1채널)이나 RGBA(4채널, 투명도 포함)인 경우에도 CLIP 모델이 기대하는 RGB 형식으로 맞춰줍니다.
# 'with ... as' 구문은 파일을 열고 작업이 끝나면 자동으로 파일을 닫아주어 리소스 누수를 방지합니다.
print(f" 이미지 크기: {img.size}, 모드: {img.mode}")
# 이미지 객체(img)의 .size 속성(너비, 높이 튜플)과 .mode 속성(색상 모드)을 출력합니다.
# 이 정보를 통해 이미지가 제대로 로드되었는지, 예상하는 형식인지 확인할 수 있습니다.
except FileNotFoundError:
print(f" **오류: 이미지 파일을 찾을 수 없습니다.** 경로를 확인하세요: {img_path}")
print(" 'Flicker8k_image' 폴더에 이미지가 제대로 압축 해제되었는지 확인해주세요.")
except Exception as e:
print(f" **오류: 이미지 로드 중 문제 발생:** {e}")
print("-" * 30)
print("\n데이터셋 로드 및 초기 탐색 완료. 다음 단계로 진행할 준비가 되었습니다.")🔻 출력결과

샘플 1 - 이미지 ID: 1000268201_693b08cb0e.jpg
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\1000268201_693b08cb0e.jpg
캡션: A child in a pink dress is climbing up a set of stairs in an entry way .
이미지 크기: (375, 500), 모드: RGB
------------------------------
샘플 2 - 이미지 ID: 1000268201_693b08cb0e.jpg
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\1000268201_693b08cb0e.jpg
캡션: A girl going into a wooden building .
이미지 크기: (375, 500), 모드: RGB
------------------------------
샘플 3 - 이미지 ID: 1000268201_693b08cb0e.jpg
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\1000268201_693b08cb0e.jpg
캡션: A little girl climbing into a wooden playhouse .
이미지 크기: (375, 500), 모드: RGB
------------------------------
샘플 4 - 이미지 ID: 1000268201_693b08cb0e.jpg
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\1000268201_693b08cb0e.jpg
캡션: A little girl climbing the stairs to her playhouse .
이미지 크기: (375, 500), 모드: RGB
------------------------------
샘플 5 - 이미지 ID: 1000268201_693b08cb0e.jpg
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\1000268201_693b08cb0e.jpg
캡션: A little girl in a pink dress going into a wooden cabin .
이미지 크기: (375, 500), 모드: RGB
------------------------------🔷 3-3 CLIP 유사도 연산
# --- CLIP 모델 로드 및 임베딩 계산 ---
from transformers import CLIPProcessor, CLIPModel
# CLIPProcessor: CLIP 모델의 입력 형식에 맞게 이미지를 전처리(크기 조절, 정규화 등)하고,
# 텍스트를 토큰화(단어/문자를 모델이 이해하는 숫자로 변환)하는 역할
# CLIPModel: 미리 학습된(pre-trained) CLIP 모델의 아키텍처와 가중치를 로드하는 역할
import torch
# PyTorch의 핵심 라이브러리
import torch.nn.functional as F
# 다양한 신경망 관련 함수(예: 활성화 함수, 손실 함수, 풀링 함수 등)를 제공합니다.
# 현재 코드에서는 F.normalize() 함수를 사용하여 벡터를 정규화하는 데 사용
import numpy as np
# 다차원 배열(넘파이 배열)을 효율적으로 다루고, 선형 대수, 푸리에 변환 등 수치 계산을 수행하는 데 사용
# 현재 코드에서는 PyTorch 텐서로 계산된 임베딩 결과를 다시 넘파이 배열로 변환하여 저장하거나(cpu().numpy()),
# 이후 matplotlib이나 seaborn 같은 시각화 라이브러리에 데이터를 전달할 때 사용
import matplotlib.pyplot as plt
# 파이썬에서 데이터를 시각화하는 데 사용되는 가장 기본적인 라이브러리
# CLIP 유사도 분포를 히스토그램으로 그릴 때 (plt.figure(), plt.title(), plt.xlabel(), plt.ylabel(), plt.grid(), plt.show()) 사용
import seaborn as sns
# 데이터 시각화 라이브러리입니다. 통계적인 그래프를 쉽게 그릴 수 있도록 도와줍니다.
# sns.histplot() 함수를 사용하여 CLIP 유사도 분포의 히스토그램과 KDE(커널 밀도 추정) 곡선을 함께 그리는 데 사용
print("\nCLIP 모델 로드 중...")
device = "cpu"
# VScode에서 실행하기 때문에 GPU 사용 불가.
model_name = "openai/clip-vit-base-patch32"
# openai/clip-vit-base-patch32는 OpenAI가 학습시킨 CLIP 모델 중 하나로,
# Vision Transformer (ViT) 아키텍처의 "Base" 크기에 32x32 패치 크기를 사용했다는 의미를 가집니다.
# 이 이름을 통해 라이브러리가 해당 모델의 파일(모델 가중치, 설정, 전처리 정보 등)을 인터넷에서 찾아 다운로드
processor = CLIPProcessor.from_pretrained(model_name)
# 미리 학습된 프로세서 설정을 로드
# 이미지: 모델에 따라 이미지를 특정 크기(예: 224x224 픽셀)로 조절하고, 픽셀 값을 특정 범위로 정규화해야 합니다.
# 텍스트: 자연어 텍스트를 모델이 이해할 수 있는 숫자 토큰 시퀀스로 변환(토큰화)해야 합니다.
# 이 토큰화 과정에는 어휘(vocabulary)와 특정 규칙(예: 특수 토큰 추가)이 필요합니다.
model = CLIPModel.from_pretrained(model_name)
# CLIPModel 객체를 생성하고, 지정된 model_name에 해당하는 미리 학습된 모델의 아키텍처와 학습된 가중치(weights)를 로드
model.to(device)
# 로드된 model 객체를 device 변수(이 경우 "cpu")가 가리키는 계산 장치로 옮깁니다.
print(f"CLIP 모델 '{model_name}' 로드 완료. (디바이스: {device})")
print("\n이미지 및 텍스트 임베딩 계산 중... (시간이 다소 소요될 수 있습니다)")
all_image_features = []
all_text_features = []
all_similarities = []
processed_pairs = [] # 성공적으로 처리된 쌍 저장
BATCH_SIZE = 32 # 배치 사이즈
# tqdm을 사용하여 진행 상황 바 표시
for i in tqdm(range(0, len(image_caption_pairs), BATCH_SIZE), desc="CLIP 임베딩 계산"):
# BATCH_SIZE만큼 건너뛰면서 숫자를 생성
# desc="CLIP 임베딩 계산": 진행 바 옆에 표시될 설명 텍스트
batch_pairs = image_caption_pairs[i:i + BATCH_SIZE]
batch_images = []
batch_texts = []
current_processed_batch_pairs = []
for pair in batch_pairs:
try:
img = Image.open(pair['image_path']).convert("RGB")
# RGB로 변환하여 CLIP에 적합하게, 실제 이미지
batch_images.append(img)
# batch 이미지 리스트에 저장
batch_texts.append(pair['caption'])
# batch 텍스트 리스트에 저장
current_processed_batch_pairs.append(pair)
# 성공적으로 로드된 페어만 추가, 이미지 경로와 caption이 저장된 것!
except FileNotFoundError:
# print(f"경고: 이미지 파일을 찾을 수 없습니다: {pair['image_path']}")
continue # 다음 쌍으로 넘어감
except Exception as e:
# print(f"경고: 이미지 로드 또는 처리 중 오류 발생 ({pair['image_path']}): {e}")
continue # 다음 쌍으로 넘어감
if not batch_images:
# batch_images 리스트가 비어있을 경우를 감지합니다. 즉, 현재 배치에 처리할 유효한 이미지가 하나도 없는 상태를 확인
continue
# continue 문을 만나면, 현재 반복(iteration)의 나머지 코드를 모두 건너뛰고, 루프의 다음 반복으로 즉시 넘어갑니다.
try:
# CLIP 프로세서로 이미지와 텍스트 전처리
inputs = processor(
text=batch_texts,
# 현재 배치에 있는 모든 캡션 텍스트(batch_texts 리스트)를 processor의 텍스트 처리 부분에 입력
# 텍스트를 CLIP 모델의 어휘집(vocabulary)에 따라 개별 토큰(단어 조각)으로 분리하고,
# 각 토큰을 고유한 숫자 ID로 변환합니다. 그리고 모든 시퀀스 길이를 맞추기 위해 패딩을 추가합니다.
# 이 결과도 숫자 텐서(정수형)이며, 텍스트의 토큰 ID 시퀀스
images=batch_images,
# 현재 배치에 있는 모든 이미지 객체(batch_images 리스트, PIL.Image 형식)를 processor의 이미지 처리 부분에 입력
# 이미지를 모델이 요구하는 특정 해상도(예: 224x224 픽셀)로 크기를 조절하고, 픽셀 값을 정규화하며,
# 이를 다차원 숫자 배열인 PyTorch 텐서로 변환합니다. 이 텐서는 이미지의 원본 픽셀 값을 숫자 형태로 인코딩한 것
return_tensors="pt",
# 전처리된 결과를 PyTorch 텐서(tensor) 형식으로 반환하도록 지정
padding=True,
# batch_texts 내의 모든 텍스트 시퀀스 길이를 가장 긴 시퀀스의 길이에 맞춰 패딩(padding)하도록 지정
# 트랜스포머 기반 모델은 한 번에 처리하는 배치 내의 모든 시퀀스(텍스트 토큰 시퀀스) 길이가 동일해야 효율적으로 작동할 수 있습니다.
truncation=True
# 텍스트 길이 제한
# 텍스트 시퀀스의 길이가 모델의 최대 입력 길이를 초과할 경우 잘라내도록(truncate) 지정합니다.
).to(device)
# processor가 반환한 inputs (전처리된 이미지 및 텍스트 텐서)를 cpu 계산 장치로 이동
with torch.no_grad():
# 역전파 계산 안함, 경사(gradient) 계산을 비활성화
outputs = model(**inputs)
image_features = outputs.image_embeds # 이미지 임베딩
text_features = outputs.text_embeds # 텍스트 임베딩
# 임베딩 정규화 (코사인 유사도 계산을 위해 필수)
image_features = F.normalize(image_features, p=2, dim=-1)
# p=2는 L2-노름(Euclidean norm)
# dim=-1: 정규화를 수행할 차원(dimension)을 지정
# [배치_크기, 임베딩_차원] 형태의 텐서
# 임베딩 벡터의 길이를 1로 만듭니다.
text_features = F.normalize(text_features, p=2, dim=-1)
# 코사인 유사도 계산 (두 벡터의 내적)
similarities = (image_features * text_features).sum(dim=-1)
# 요소별 곱셈(element-wise multiplication)을 수행
# 결과는 (32, 512) 형태의 텐서
# dim=-1은 다시 마지막 차원(임베딩 차원)에 걸쳐 합산
all_image_features.extend(image_features.cpu().numpy())
all_text_features.extend(text_features.cpu().numpy())
all_similarities.extend(similarities.cpu().numpy())
processed_pairs.extend(current_processed_batch_pairs)
# 성공 처리된 쌍만 리스트에 추가
# extend()를 사용하면 배열 안의 개별 임베딩 벡터들이 모두 평탄화되어 하나의 연속된 리스트가 됩니다.
except Exception as e:
# print(f"경고: 배치 처리 중 오류 발생: {e}")
continue # 이 배치는 건너뛰고 다음 배치로 진행
print(f"총 {len(processed_pairs)} 개의 이미지-캡션 쌍에 대해 임베딩 및 유사도 계산 완료.")
# 계산된 유사도 데이터를 최종 데이터셋에 추가
for i, pair in enumerate(processed_pairs):
pair['clip_similarity'] = all_similarities[i]🔷 3-4 시각화
# --- 단계 4: 결과 분석 및 시각화 ---
print("\n--- 결과 분석 및 시각화 ---")
# 1. 유사도 분포 시각화
plt.figure(figsize=(10, 6))
sns.histplot(all_similarities, bins=50, kde=True)
plt.title('Distribution of CLIP Similarities')
plt.xlabel('CLIP Cosine Similarity')
plt.ylabel('Frequency')
plt.grid(axis='y', alpha=0.75)
plt.show() # 그래프 창 띄우기
# 2. 필터링 임계값 설정
# 히스토그램을 보고 적절한 임계값을 선택하세요.
# 예시: 0.25 (LAION 논문에서 0.26~0.28 정도 사용)
FILTERING_THRESHOLD = 0.25
filtered_pairs = [pair for pair in processed_pairs if pair['clip_similarity'] >= FILTERING_THRESHOLD]
rejected_pairs = [pair for pair in processed_pairs if pair['clip_similarity'] < FILTERING_THRESHOLD]
print(f"\n총 처리된 쌍: {len(processed_pairs)} 개")
print(f"필터링 기준 (유사도 >= {FILTERING_THRESHOLD}): {len(filtered_pairs)} 개 (남은 데이터)")
print(f"필터링으로 제거된 쌍: {len(rejected_pairs)} 개 (제거된 데이터)")
print(f"제거된 비율: {len(rejected_pairs) / len(processed_pairs) * 100:.2f}%")
# 3. 제거된 데이터 샘플 확인
print("\n--- 제거된 데이터 샘플 (유사도 낮음) ---")
# 유사도가 낮은 순서로 정렬하여 확인
rejected_pairs_sorted = sorted(rejected_pairs, key=lambda x: x['clip_similarity'])
# 가장 유사도가 낮은 5개 샘플 출력
for i, pair in enumerate(rejected_pairs_sorted[:5]):
img_path = pair['image_path']
caption = pair['caption']
similarity = pair['clip_similarity']
print(f"샘플 {i+1} (유사도: {similarity:.4f})")
print(f" 이미지 경로: {img_path}")
print(f" 캡션: {caption}")
try:
img = Image.open(img_path)
img.thumbnail((128, 128)) # 이미지 크기 줄여서 출력 (선택 사항)
# img.show() # 이미지를 새 창으로 띄워볼 때 사용 (주피터 노트북이 아니라면 여러 창이 뜰 수 있음)
except Exception as e:
print(f" 이미지 로드 또는 표시 오류: {e}")
print("-" * 30)
print("\n실습 완료!")🔷 3-5 결과
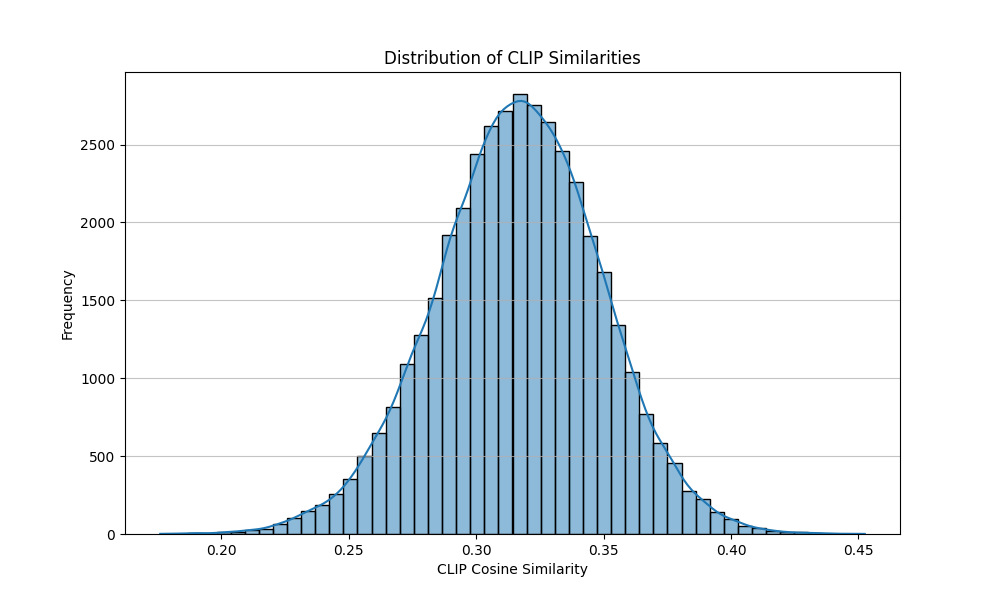
--- 결과 분석 및 시각화 ---
총 처리된 쌍: 40455 개
필터링 기준 (유사도 >= 0.25): 39486 개 (남은 데이터)
필터링으로 제거된 쌍: 969 개 (제거된 데이터)
제거된 비율: 2.40%
--- 제거된 데이터 샘플 (유사도 낮음) ---
샘플 1 (유사도: 0.1760)
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\2966190737_ceb6eb4b53.jpg
캡션: These people are in uniform at a lacrosse type game .
------------------------------
샘플 2 (유사도: 0.1793)
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\1387461595_2fe6925f73.jpg
캡션: A man in a suit and two men in orange vests standing around
------------------------------
샘플 3 (유사도: 0.1846)
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\3050976633_9c25cf6fa0.jpg
캡션: These people are playing a soccer type game .
------------------------------
샘플 4 (유사도: 0.1848)
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\2045928594_92510c1c2a.jpg
캡션: The woman stands in front of a rock pond and wears a red shirt .
------------------------------
샘플 5 (유사도: 0.1867)
이미지 경로: 🚫\CLIP\data\Flickr8k_Dataset\Flicker8k_image\2308978137_bfe776d541.jpg
캡션: almost 2 dozen people are riding on the outside of a cart down a road
------------------------------
실습 완료!🤔 내 생각
모델을 직접 구현해서 학습하는 것과 활용해보는 것은 전혀 다른 느낌인 것 같다. Github에 있는 CLIP 모델을 직접 구현한 코드보다는 훨씬 다루기 쉬운 것 같다.
실제로 내가 연구를 진행하기 위해서는 파이프라인을 구축 후 실험을 진행해야 하니까 많이 연습해보면 좋을 것 같다.
