x,y data들로 구성이 된 파일이 있다.
위도,경도를 담고 있으며 이 데이터를 바탕으로 3D 화면을 구성할 수 있는데,
하나의 군집이 아닌 여러개의 군집의 x,y가 무작위로 섞여 있는 경우,
이를 분리해내어 처리해야할 경우가 발생한다.
이를 해결하기 위한 여러가지 알고리즘들이 존재하는데,
우선적으로 고려해야할 점은 군집의 개수를 알고 있느냐? 이다.
군집의 개수를 알고 있으면 생각보다 쉽게 해결해낼 수 있다.
만약 군집의 개수를 모른다면 까다로워지며 정확한 값을 기대하기 힘들다.
일단 군집의 개수를 알고 있다고 가정하고 아래를 보자.
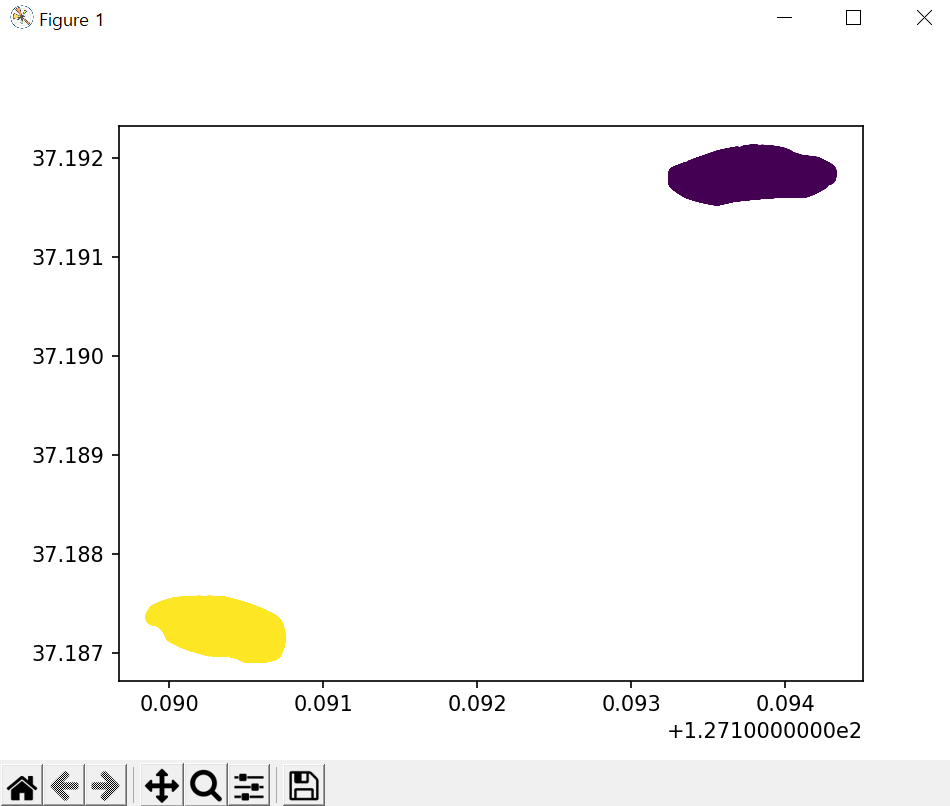
위와 같이 두개의 군집이 있다고 가정할 때,
KMeans라는 알고리즘을 사용하여 x,y들의 군집을 분리해낼 수 있다.
import argparse
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import numpy as np
parser = argparse.ArgumentParser()
parser.add_argument('--input', type=str, default='input.xyz',
help='input xyz file name')
parser.add_argument('--clusters', type=int, default=2,
help='number of clusters')
args = parser.parse_args()
x_list = []
y_list = []
z_list = []
with open(args.input, 'r') as f:
for line in f:
x, y, z = map(float, line.split(','))
x_list.append(x)
y_list.append(y)
z_list.append(z)
print("for loop end")
X = np.array([x_list, y_list]).T
km = KMeans(n_clusters=args.clusters)
y_pred = km.fit_predict(X)
plt.scatter(X[:, 0], X[:, 1], c=y_pred)
plt.show()x,y,z로 되어있는 .xyz 파일을 열어서 x, y , z의 list를 만든 다음
z값은 사실 내 경우에는 필요가 없어서 버렸음.
clusters의 개수를 입력해 pyplot을 이용해서 뿌려주는 코드이다.
만약 클러스터의 개수를 모른다면
elbow method라는 방식을 사용할 수 있다.
elbow method는 kmeans 알고리즘의 cluster를 증가시켜가며 SSE라는 값을 얻어낸
다음 팔꿈치가 꺾이는 것처럼 보이는 구간이 cluster라고 추정하는 기법이다.
이전의 코드에서 KMeans의 cluster를 for loop으로 1부터 증가시키며 sse값을 뽑아낸다음
kneed package의 KneeLocator를 사용해 꺾이는 지점을 찾아주면 된다.
python .\elbow.py
Number of clusters: 1, SSE: 3.5843272744834103
Number of clusters: 2, SSE: 0.028648079633010838
Number of clusters: 3, SSE: 0.01878577280569933
Number of clusters: 4, SSE: 0.01166689983089582
Number of clusters: 5, SSE: 0.009631803221178292
Number of clusters: 6, SSE: 0.008118685391493801
Number of clusters: 7, SSE: 0.006882333378932449
Number of clusters: 8, SSE: 0.006000348532121687
Number of clusters: 9, SSE: 0.005326704384333017
위와 같이 1부터 9까지의 cluster를 차례대로 돌린 뒤, SSE값의 추이를 그래프로 보면 다음과 같다.
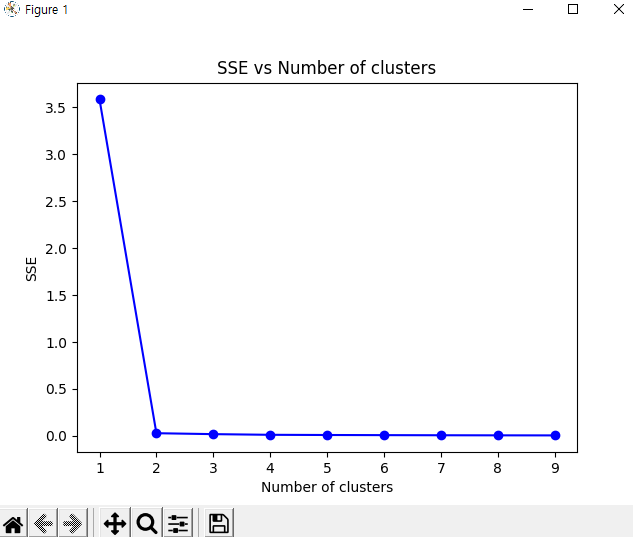
위 그림에서 꺾이는 지점이 2인걸 알 수 있다. 그러면 군집의 개수가 2개라고 추정할 수 있는 것이다.
물론 군집의 개수가 많고 다양하면 시간도 오래걸리고 scale의 차이에 따라 군집을 어떻게 지정할 것인지에 대한 문제가 발생하기 때매, 사람이 눈으로 보는 것과 결과가 달라질 수 있다.
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from tqdm import tqdm
from kneed import KneeLocator
# 입력 데이터 로드
data = pd.read_csv('cluster2.xyz', delimiter=',', header=None, usecols=[0,1])
# 클러스터 개수의 범위를 지정합니다.
k_range = range(1,10)
# 각 클러스터 개수에서의 SSE 값을 계산합니다.
sse_values = []
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=0, n_init=10)
kmeans.fit(data)
sse_values.append(kmeans.inertia_)
print(f"Number of clusters: {k}, SSE: {sse_values[k-1]}")
# 최적의 클러스터 개수를 찾습니다.
kl = KneeLocator(range(1,len(sse_values)+1), sse_values, curve='convex', direction='decreasing')
optimal_k = kl.elbow
print("found elbow: ", optimal_k)
# 최적의 클러스터 개수로 KMeans 알고리즘을 적용합니다.
kmeans = KMeans(n_clusters=optimal_k, random_state=0, n_init=10)
kmeans.fit(data)
labels = kmeans.predict(data)
# 각 데이터 포인트를 클러스터에 따라 색으로 구분하여 시각화합니다.
colors = ['r', 'g', 'b', 'c', 'm', 'y', 'k']
for i in range(optimal_k):
plt.scatter(data[labels == i][0], data[labels == i][1], s=50, c=colors[i % len(colors)], label=f"Cluster {i+1}")
plt.xlabel('x')
plt.ylabel('y')
plt.title(f"Clustering results with {optimal_k} clusters")
plt.legend()
plt.show()
# SSE 값을 그래프로 나타냅니다.
plt.plot(range(1, len(sse_values)+1), sse_values, 'bo-')
plt.xlabel('Number of clusters')
plt.ylabel('SSE')
plt.title("SSE vs Number of clusters")
plt.show()코드는 위와 같다.
