
[그리디 15] 보물
최적의 일반화
1. 문제 설명하기.
(1) 문제
옛날 옛적에 수학이 항상 큰 골칫거리였던 나라가 있었다. 이 나라의 국왕 김지민은 다음과 같은 문제를 내고 큰 상금을 걸었다.
길이가 N인 정수 배열 A와 B가 있다. 다음과 같이 함수 S를 정의하자.
S = A[0] × B[0] + ... + A[N-1] × B[N-1]
S의 값을 가장 작게 만들기 위해 A의 수를 재배열하자. 단, B에 있는 수는 재배열하면 안 된다.
S의 최솟값을 출력하는 프로그램을 작성하시오.
(2) 입력
첫째 줄에 N이 주어진다. 둘째 줄에는 A에 있는 N개의 수가 순서대로 주어지고, 셋째 줄에는 B에 있는 수가 순서대로 주어진다. N은 50보다 작거나 같은 자연수이고, A와 B의 각 원소는 100보다 작거나 같은 음이 아닌 정수이다.
(3) 출력
첫째 줄에 S의 최솟값을 출력한다.
S의 최솟값을 구하는 문제이기 때문에 탐욕법을 이용하면 된다. 그래서 그리디 문제이다.
2. 문제 해결하기.
물론 이 방법은 문제의 조건을 무시했기 때문에, 옳은 풀이는 아니다.
A를 오름차순으로 정렬하고 B를 내림차순으로 정렬하면 최솟값을 구할 수 있다.
아래의 예제를 보면 이해할 수 있을 것이다.
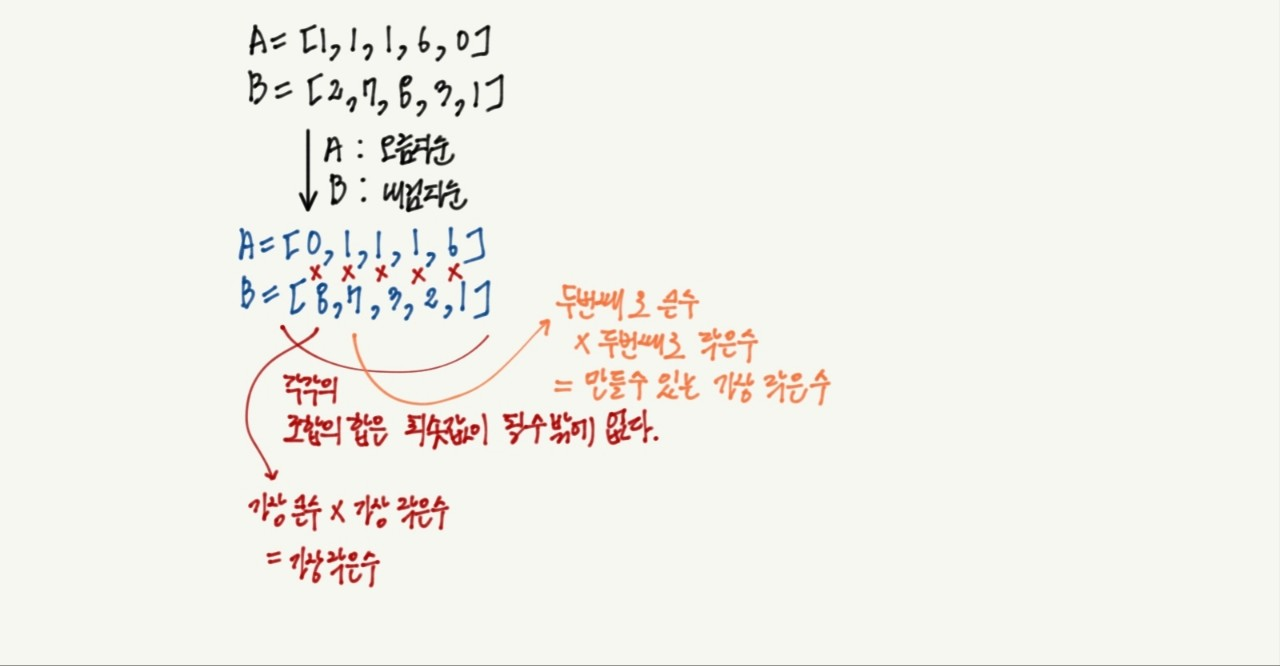
# 최적의 일반화 : 하지만, B를 정렬하면 안된다고 하였으니, 이 방법은 옳은 방법은 아니다.
N=int(input())
A=list(map(int, input().split()))
B=list(map(int, input().split()))
A.sort()
B.sort(reverse=True)
result=0
for idx in range(N):
result+=A[idx]*B[idx]
print(result)문제의 조건에 맞게 B를 정렬하지 않고 구할 수도 있다.
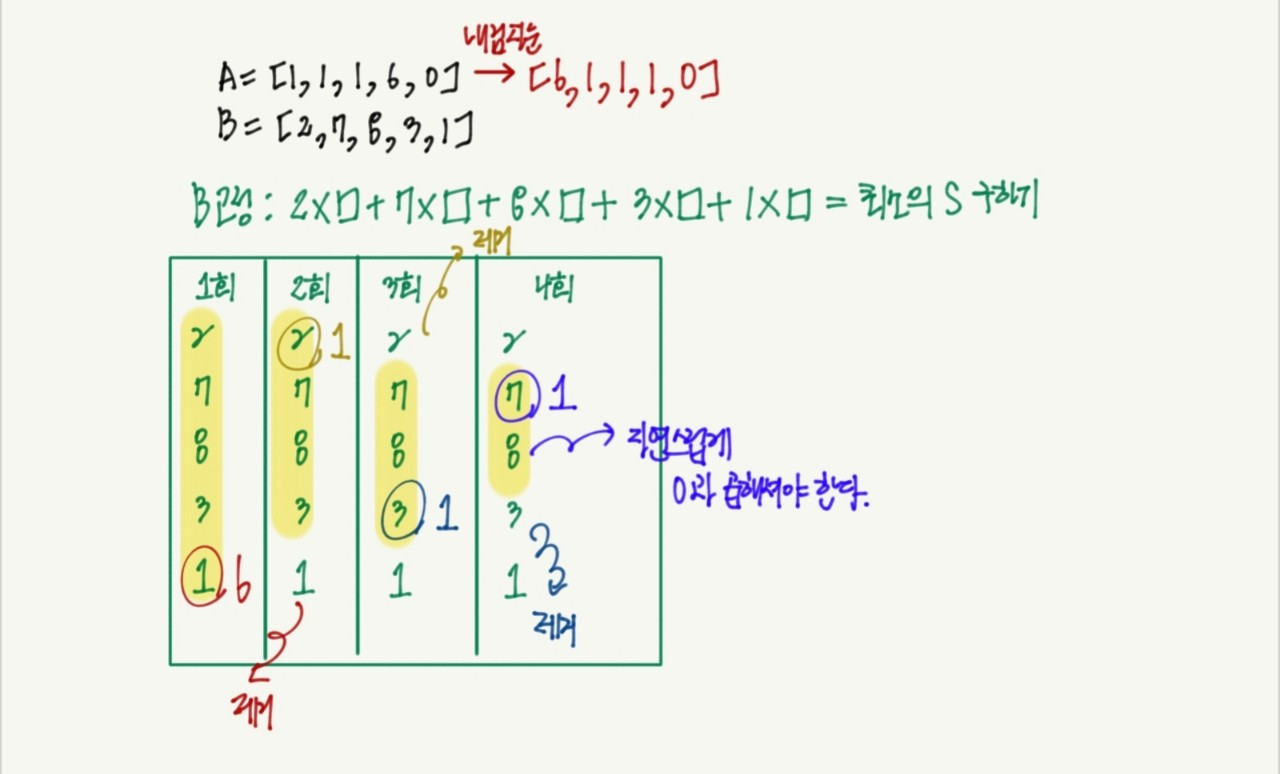
B 전체를 계속 돌리면서, B와 맞는 A를 골라주면 된다. B가 가장 작을 때, A는 가장 커야 된다. 그래야 S가 최소가 될 것이다.
Step 1. A를 내림차순으로 정렬하고, B를 무한 반복문을 이용하여 계속 돌린다.
Step 2. 기준이 되는 B를 고른다. (기준을 B의 첫 번째 인덱스의 값이라고 두자.)
Step 3. 가장 작은 B를 찾아준다.
Step 4. 그 B를 A의 첫 번째 요소와 곱해서 더해준다. 그 값은 result (즉 S) 라고 둔다.
Step 5. 이미 정해진 A의 요소와 B의 요소를 없애기 위하여 pop, remove를 이용한 뒤에 A,B를 새롭게 갱신해준다.
Step 6. N이 1이 되는 시점에서 종료한다. 종료 조건은 반복문이 시작하기 전에 넣어야 런타임 에러(IndexError)가 뜨지 않는다.
주의할 점은 알고리즘에서의 위치와 실제 코드의 위치를 같게 해야된다는 점이다. 코드의 위치가 달라지면 의미가 달라지기 때문에, 원하는 값이 나오지 않을 수가 있기 때문이다.
주석을 단 부분은 내가 실수한 부분이기 때문에 잘 봐두자!
# 최적의 일반화
N=int(input()) # 50보다 작거나 같은 자연수
A=list(map(int, input().split())) # 각 요소는 100보다 작거나 같은 음이 아닌 정수
B=list(map(int, input().split()))
A.sort(reverse=True) # 내림차순 정렬하기.
result=0
while True:
init_min=B[0] # 위치 중요하다.
# 무한 반복문 밖에 두면 계속 init_min=1일 수 밖에 없다.
if N==1: # 종료 조건을 위로 올려주기.
result+=A[0]*B[0]
break
for idx in range(N):
if init_min<=B[idx]:
continue
else:
init_min=B[idx]
result+=A[0]*init_min # 위치 중요하다.
# A 날린 후에 0번째 곱해주면 다른 값이 나오기 때문이다.
A.pop(0)
B.remove(init_min)
N-=1
print(result)3. 리스트 요소를 제거하는 함수들
- pop() : 리스트에서 인덱스를 이용하여 요소 제거하기. 제거되는 값 반환 O
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
fruits.pop() # 제거되는 요소가 반환된다. 마지막 요소가 제거된다.
fruits
fruits = ['orange', 'apple', 'pear', 'banana', 'kiwi', 'apple', 'banana']
fruits.pop(1) # 제거되는 요소가 반환된다. 인덱스 1 위치인 apple이 제거된다.
fruits- remove() : 리스트에서 지정된 값을 이용하여 요소 제거하기.
## 단, 값이 여러 개인 경우에는 첫 번째 위치의 요소 제거하기.
l=[1,2,3]
l.remove(1)
l
## 단, 값이 여러 개인 경우에는 첫 번째 위치의 요소 제거하기.
l=[1,1,1,2,3,4,4,5]
l.remove(4)
print(l)
l.remove(1)
print(l)- del : 리스트에서 인덱스를 이용하여 요소 제거하기. 제거되는 값 반환 X
## pop은 값은 반환하지만, del은 값을 반환하지 않는다.
a = [-1, 1, 66.25, 333, 333, 1234.5]
del a[0]
print(a)
del a[2:4]
print(a)
del a[:]
print(a)