
3주차 정리
[목표] 평당 분양가격 구하기.
그러기 위해서는 분양가격을 연산할 수 있는 형태로 만들어준다.
1. 파일 로드하기
나는 당연히 csv 파일이면 tap으로 구분된지 알았는데, 이 데이터들은 기본 전제인 ,로 구분된 데이터이다.
df_last=pd.read_csv("파일 경로", sep=",", encoding="cp949")
df_first=pd.read_csv("파일 경로", sep=",", encoding="cp949")2. 데이터 형태 살펴보기
df_last.shape
df_first.shape
df_last.head()
df_last.tail()
df_first.head()
df_first.tail()
df_last.iloc[:5] # head와 동일하다.
df_last.iloc[-5:] # tail과 동일하다.3. 데이터 요약하기
결측치가 어디에 얼만큼 있는지 알 수 있다.
df_last.info()
df_first.info()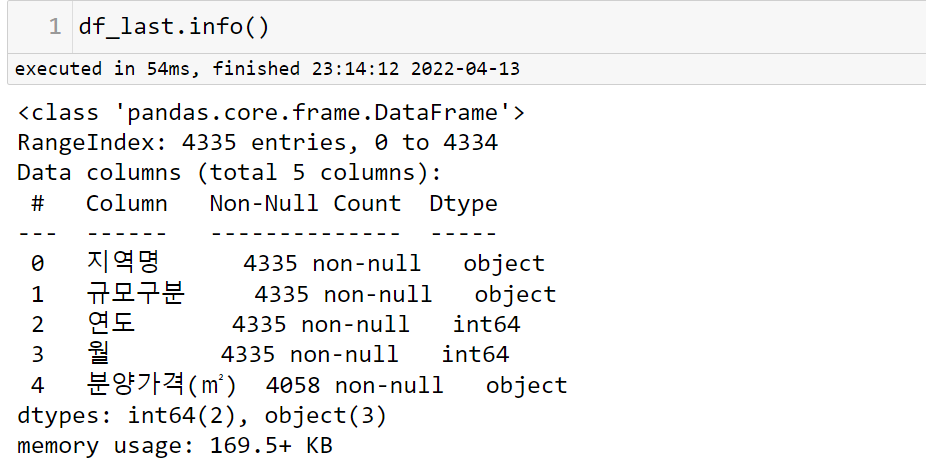
이것을 보면 분양가격에서 결측치가 있음을 알 수 있다.
4. pandas의 object type
- 한 데이터에 여러 종류의 타입이 있으면, array는 타입을 string으로 퉁치지만, series 같은 경우에는 object 타입으로 등장한다.
- np.nan 은 타입이 float 이다.
5. 결측치 확인하기
isnull() 또는 isna()를 이용한다.
sum은 True인 것들의 개수만 세어준다.
df_last.isnull().sum()
df_last.isna().sum()
# sum은 True인 것들의 개수만 세어준다.5-1. 분양 가격 결측치 구하기 (1)
분양 가격이 object type 이기 때문에, 데이터 유형을 변경하기 위해서는 pd.to_numeric을 통해서 데이터 유형을 변경시켜주자. NaN도 어차피 float이기 때문에.. to_numeric 시켜줘도 된다.
df_last["분양가격"] = pd.to_numeric(df_last["분양가격(㎡)"], errors='coerce')errors라는 매개변수에 관하여...

- raise : 기본 값 의미한다.
- ignore : 그냥 무시한다.
- coerce : 잘못된 구문 분석은 NaN을 반환한다. 우리는 이것을 이용할 것이다.
5-2. 분양 가격 결측치 구하기 (2)
- np.nan의 개수를 세어주는 2가지 방법
# 방법 (1)
df_last["분양가격(㎡)"].isnull().sum()
# 방법 (2)
nan_cnt=0
for x in df_last["분양가격(㎡)"]:
if x!=x: # x가 nan인 경우를 의미한다.
nan_cnt+=1
nan_cnt- replace와 isdigit( ) 를 이용하기.
np.nan과 숫자로 변경할 수 있는 것들을 구분시켜주기.
죽었다 깨어나도 np.nan이면 어쩔 수 없지만, 변경할 수 있는 경우에는 고쳐서 float로 변경한 이후에 이용하자.
어차피 series는 object type 덕분에 다양한 타입을 가질 수 있다. 그 부분을 이용하자.
def f1(x):
if x!=x: # x가 np.nan인 경우에는 np.nan이라고 표현하기.
return np.nan
x=x.replace(',','') # 안에 있는 ,를 제거해주기.
if x.isdigit(): # 숫자인 경우에는 float로 변경시켜주기.
return float(x)
return np.nan # 그렇지 않으면 그냥 np.nan이라고 표현하기.
df_last["분양가격2"]=df_last["분양가격(㎡)"].map(f1)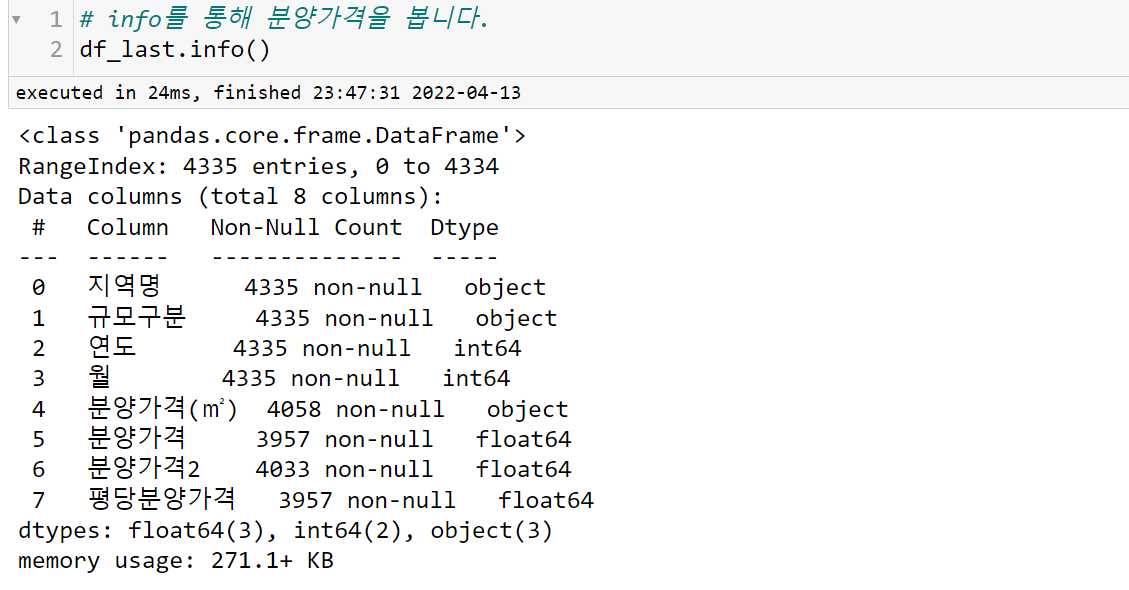
이 자료를 보면 방법 (2)를 사용한 경우에 데이터 손실이 더 적어졌지만 우리는 방법 (1)을 이용할 것이다.
6. 평당 분양 가격 구하기.
우리는 평당 분양 가격을 구하기 위해서 분양 가격을 실수로 만들어 준 것이다. 왜냐하면 분양 가격에 * 3.3을 한 결과가 평당 분양 가격이기 때문이다.
df_last["평당분양가격"] = df_last["분양가격"] * 3.3
df_last7. 정말~~ 마지막으로 데이터 요약하기.
df_last.info() # 결측치가 어디에 분포되어 있는지 파악시켜준다.
df_last['지역명'].describe() # 통계값
df_last["분양가격(㎡)"].describe() # 통계값
df_last["분양가격(㎡)"].value_counts() # 값의 개수를 세어준다.8. 추가적인 내용...
자주 쓰이는 중요한 함수들 모음
- lambda
- map
- apply
- str
- 한 줄짜리 lambda() 함수
df_last['연도2']=df_last['연도'].map(lambda x: x%100)
df_last
df_last.info()
df_last['연도2']+1- map() 함수
df1=pd.DataFrame({'a':[1,2,3,1],'b':[4,5,6,8],'c':['g','h','j','k']})
df1.index=[10,20,30,40]
df1
def f1(x):
if x%2==0:
return 'even'
else:
return 'odd'
df1['a']
df1['a_v1']=df1['a'].map(f1)
df1df1=pd.DataFrame({'a':[1,2,3,1],'b':[4,5,6,8],'c':[10,20,30,40]})
df1
df1['c']*2%3
df1['c'].map(lambda x: x*2%3) # 한 줄짜리 함수
def f1(x):
if x<=20:
return 'fail'
else:
return 'pass'
df1['c']
df1['c'].map(f1) # map 함수를 이용해서 series 처리 시켜주기.- apply() 함수
axis=0의 방향으로 모든 series를 처리시켜준다. axis=0은 위에서 아래의 방향이고, 결국 col 부분을 나타낸다.
def f2(col):
return col
df1.apply(f2, axis=0)- 문자열로 만들어주는 str() 함수를 이용해서 연결시켜주기.
axis=1의 방향으로 모든 series를 처리시켜준다. axis=1은 왼쪽에서 오른쪽의 방향이고, 결국 row 부분을 나타낸다.
def f1(x):
return str(x.loc['a'])+'_'+str(x.loc['b'])
df1['d']=df1.apply(f1, axis=1)
df1axis=0의 방향으로 모든 series를 처리시켜준다. axis=0은 위에서 아래의 방향이고, 결국 col 부분을 나타낸다.
def f(col):
return col+10
df1=df1.apply(f, axis=0)
df14주차 정리
[목표] 원하는 형식으로 데이터 집계하기.
1. 규모구분 컬럼을 전용면적 컬럼으로 데이터 변경하기.
규모구분 컬럼을 전용면적 컬럼을 변경하고, 문구들을 단순하게 만들어서 처리하자.
df_last["규모구분"].unique()unique()를 이용해서 규모구분에 어떤 값들이 있는지 살펴보자.
- 전용면적 -> 없애기.
- 초과 -> ~
- 이하 -> 없애기.
- 공백 -> 없애기.
df_last
df_last["전용면적"] = df_last["규모구분"].str.replace("전용면적", "")
df_last
df_last["전용면적"] = df_last["전용면적"].str.replace("초과", "~")
df_last["전용면적"] = df_last["전용면적"].str.replace("이하", "")
df_last["전용면적"] = df_last["전용면적"].str.replace(" ", "")
df_last- strip() 함수와 contains() 함수
문자열 함수
- strip() : 각 문자열에서 공백(개행 포함) 또는 지정된 문자 집합을 제거한다. 더 명확하게 하기 위해서는 str 처리를 해준 뒤에 strip()을 해주면 명확하다.
- contains() : 포함 여부를 알려준다.
s = pd.Series(['1. Ant. ', '2. Bee!\n', '3. Cat?\t', np.nan])
s
s.str.lstrip('123.')
s.str.lstrip('1.')
s.str.rstrip('.!? \n\t')
s.str.strip('123.!? \n\t')
# 3번째와 4번째는 결과가 다르다.2. drop으로 필요 없는 칼럼 제거하기.
axis의 의미
axis=0 : 행을 의미한다.
axis=1 : 열을 의미한다.
(cf) apply 함수에서는...
axis=0, col을 의미한다.
axis=1, row를 의미한다.
df_last_dropped = df_last.drop(["규모구분", "분양가격(㎡)"], axis=1)3. groupby로 데이터 집계하기.
3-1. 1개의 item
df_last.groupby(["1번째 item"])["원하는 칼럼명"].원하는 계산 메소드()함수 이용해서 series에 적용하고 싶은 경우에는 apply를 이용하기~!
def f1(sr1):
return np.mean(sr1)-np.std(sr1)
df_last.groupby(['지역명'])['분양가격'].apply(f1)
def f2(sr1):
if np.mean(sr1)>3000:
return 'H'
else:
return 'L'
df_last.groupby(['지역명'])['분양가격'].mean()
df_last.groupby(['지역명'])['분양가격'].apply(f2)
def f1(sr1):
if np.max(sr1) > 26000:
return "H"
return "L"
df_last.groupby(["연도"])["평당분양가격"].max()
df_last.groupby(["연도"])["평당분양가격"].apply(f1)만약에, np.nan이 있는 경우에는 그것을 제외하고 계산한다. np.nan은 0이 아니다..
3-2. 2개 이상의 items
df_last.groupby(["1번째 item", "2번째 item"])["원하는 칼럼명"]
.원하는 계산 메소드()
df_last.groupby(["1번째 item", "2번째 item"])["원하는 칼럼명"]
.원하는 계산 메소드().to_frame()
# dataframe 형태로 변경시켜줄 수 있다.4. groupby + unstack
unstack은 multi-index인 경우에만 사용 가능하다.
g.unstack() # 가장 마지막 인덱스를 위로 올린다.
g.unstack().transpose().head() # transpose
g.unstack(0).head() # 가장 처음 인덱스를 위로 올린다.5. pivot_table로 데이터 집계하기.
5-1. 1개의 item
위의 코드와 아래의 코드는 동일하다. groupby를 이용해서, pivot_table을 이용해서 둘다 동일한 코드를 작성할 수 있다.
df_last.groupby(["지역명"])["평당분양가격"].mean().to_frame()
pd.pivot_table(df_last, index=["지역명"], values=["평당분양가격"], aggfunc=np.mean)
# aggfunc의 default : np.mean 이다.5-2. 2개 이상의 items
pd.pivot_table(df_last, index=["지역명","연도"], values=["평당분양가격"], aggfunc=np.mean)
# aggfunc의 default : np.mean 이다.aggfunc = {1번째 value: 1번째 value에 사용할 계산 메소드, 2번째 value: 2번째 value에 사용할 계산 메소드}를 이용해서 각자 다른 aggfunc을 넣어줄 수 있다.
df1=pd.pivot_table(df_last, index=["전용면적","연도"], aggfunc={'평당분양가격': np.mean, '분양가격': np.mean})
df16. pivot_table + unstack
pd.pivot_table(df_last, index=["지역명","연도"], values=["평당분양가격"], aggfunc=np.mean).unstack()아니면 columns를 이용해서 굳이 unstack 사용하지 않고 풀이할 수 있다.
pd.pivot_table(df_last, index="지역명", columns="연도", values=["평당분양가격"], aggfunc=np.mean).unstack()7. 지역별 전용면적별 평당분양가격 평균 구하기.
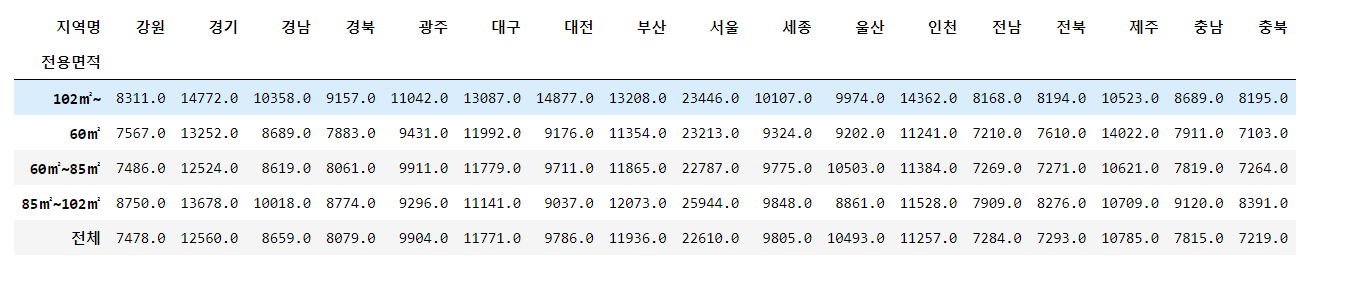
# 방법 (1) : groupby 이용하기.
df_last.groupby(["전용면적", "지역명"])["평당분양가격"].mean().unstack().round()
# 방법 (2) : pivot_table 이용하기.
df_last.pivot_table(index=["전용면적", "지역명"], values="평당분양가격", aggfunc=np.mean).unstack().round()
df_last.pivot_table(index="전용면적", columns="지역명", values="평당분양가격", aggfunc=np.mean).unstack().round()7-1. groupby + pivot_table 에서의 데이터 확인하기.
## 방법1
p = pd.pivot_table(df_last, index=["연도", "지역명"], values="평당분양가격")
p.head()
p.loc[2017]
## 방법2
p = pd.pivot_table(df_last, index="지역명", columns= "연도", values="평당분양가격")
p.head()
p[2017]
p[[2017]] 8. pandas로 시각화하기.
지역명으로 분양가격의 평균을 구하고 선그래프로 시각화 합니다.
g = df_last.groupby(["지역명"])["평당분양가격"].mean().sort_values(ascending=False) # 내림차순 8-1. plot
그냥 plot만 해주면, x축에 모두 나오지 않기 때문에 ticks와 labels를 설정해주었다. 그리고 도화지의 사이즈도 크게 만들어주었다.
g.plot(figsize=(10,3))
_=plt.xticks(ticks=np.arange(len(g)), labels=g.index) # ticks와 label를 적어주기.8-2. bar
rot=0을 이용해서 x축의 라벨을 보기 좋게 만들어주었다.
_=g.plot(kind="bar", rot=0, figsize=(10, 3))8-3. hist
bar와는 다른 모습으로 등장한다. 위의 그림과는 완전 다른 모습을 보여준다. x가 평당분양가격이고, y가 빈도수를 나타낸다.
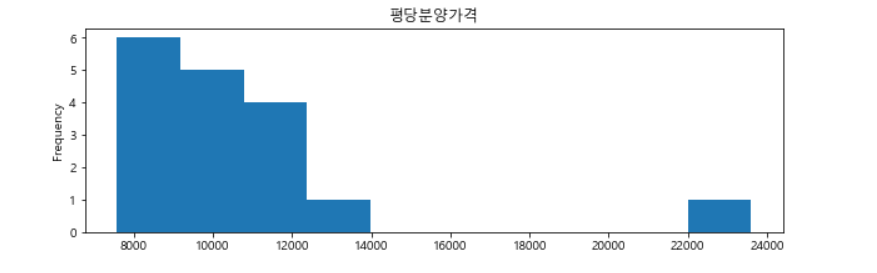
g.plot(kind='hist', figsize=(10, 3), title='평당분양가격')8-4. box
_=g.plot(kind='box', figsize=(5, 5))8-5. 내가 만든 도화지 위에 그림 그리기.
fig=plt.figure(figsize=(10,3), dpi=100) # dpi는 선명도를 의미한다.
ax1=fig.subplots()
# fig는 도화지를 의미하고, ax1은 도화지 안의 구역을 의미한다.
# subplots를 이용해서 도화지 안의 구역을 원하는 만큼 만들어낼 수 있다.
fig=plt.figure(figsize=(5,5), dpi=100)
(ax1,ax2,ax3,ax4)=fig.subplots(2,2).flatten()
# flatten 처리를 해주는 것이 좋은게 나중에 디테일한 부분들을 정돈할 수 있기 때문이다.5주차 정리
[목표] pandas & seaborn으로 시각화하기.
5-1. pandas로 시각화하기.
5-1-1. box
(주의) box만 나머지 그림과는 약간 그리는 방식이 다르다.
box만 column인 지역명이 x축으로 들어가고, 나머지 그림은 연도가 x축으로 들어간다.
columns 부분이 x축으로 들어가고, index에 따른 value 값이 y축으로 들어간다.
p.plot(kind="box", figsize=(,), rot=30)
# 원하는 만큼 처리해주기. 여기서 p는 데이터이다.
p = df_last.pivot_table(index="월", columns=["연도", "전용면적"], values="평당분양가격") ## columns이 multiindex로 생겨남
p
p.plot.box(figsize=(15, 3), rot=30)밑의 코드는 (연도, 전용면적)이 x축으로 들어가고, 월에 따른 평당분양가격이 y축으로 들어간다.
5-1-2. line
p.plot(kind="line", figsize=(,))
plt.legend(bbox_to_anchor=(x, y, width, height), loc=원하는 위치)
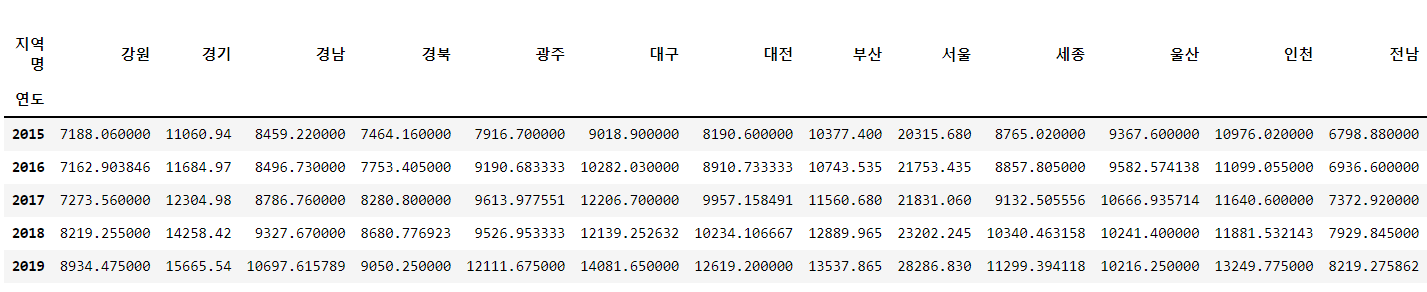
# legend에서 이용하면 된다.q = df_last.pivot_table(index="지역명", columns="연도", values="평당분양가격")
q
q.plot(figsize=(15, 3), rot=30)
# 그래프의 밖에 legend 표시하도록 설정
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)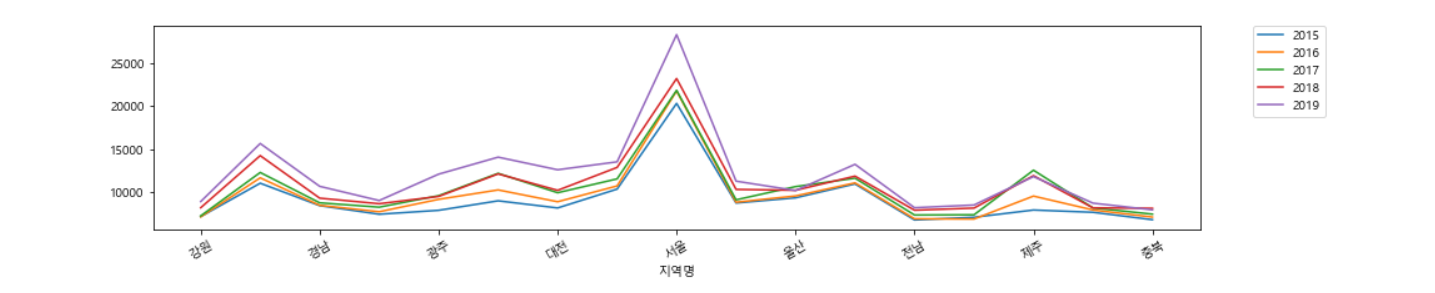
p = df_last.pivot_table(index="연도", columns="지역명", values="평당분양가격")
p
p.plot(figsize=(15, 3), rot=30)
# 그래프의 밖에 legend 표시하도록 설정
plt.legend(bbox_to_anchor=(1.05, 1), loc=2, borderaxespad=0.)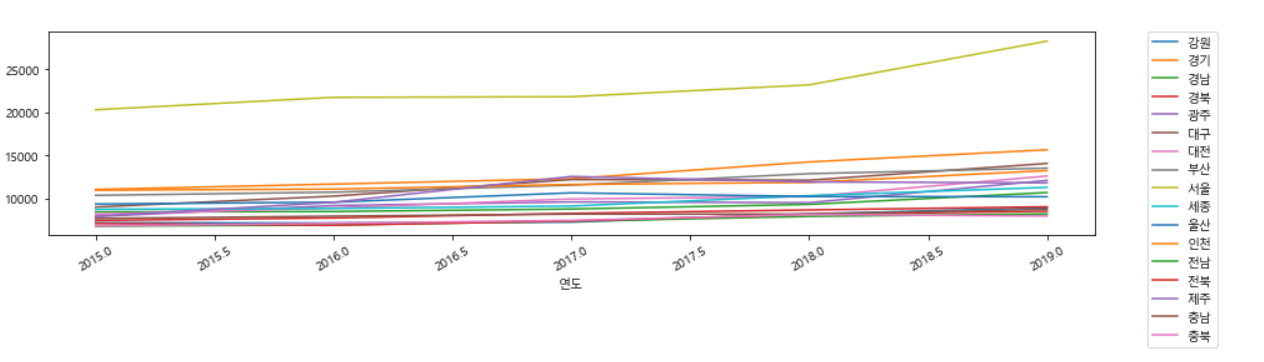
bbox_to_anchor=(x, y, width, height) 와 loc은 범례의 위치를 지정해준다.
ax.set_xticklabels(ax2.get_xticklabels(), fontsize=20)
# 원래 가지고 있던 라벨을 가지고 오기 위해서 get_xticklabels를 이용한다. 그 다음에 set_xticklabels를 이용한다.5-1-3. 도화지에 여러 개의 그림 그리기.
fig=plt.figure(figsize=(20, 10), dpi=200)
(ax1, ax2, ax3, ax4)=fig.subplots(2,2).flatten()
# flatten() 처리를 해줘야 디테일을 조정할 수 있다.
# ax=ax1
# ax=ax2
# ax=ax3
# ax=ax4
# 위의 코드를 이용해서 그림의 위치를 정해주면 된다.5-1-4. 위의 것들 말고도...
bar 등등 많이 존재한다. 필요할 때 마다 찾아서 사용하면 된다.
그리고 여러 개의 그래프를 한번에 그리는 경우에는
fig.tight_layout()이 코드를 이용하자.
5-2. seaborn으로 시각화하기.
5-2-1. barplot
sns.barplot으로 pandas.bar를 표현할 수 있다.
pandas에서는 데이터 전처리 시에 계산 메소드를 지정해야하지만, sns에서는 estimator를 이용해서 계산 메소드를 지정할 수 있다. (전처리 과정을 건너뛸 수 있다...)
sns.barplot(data=df_last, x="", y="", estimator=원하는 계산 메서드)Matplotlib VS Seaborn
# 1. matplotlib 이용하기
df_last.head()
df2=df_last.pivot_table(index="지역명", values="평당분양가격", aggfunc=np.mean)
df2
df2.plot(kind="bar", rot=0, cmap="spring")
# 2. seaborn 이용하기
sns.barplot(data=df2, x=df2.index, y="평당분양가격", estimator=np.mean)
# sns.barplot(data=df_last, x=df2.index, y="평당분양가격"
, estimator=np.mean) : Error위와 같은 경우에는 hue가 필요하다. hue가 있는 경우에는 legend도 생성된다.
# 1. matplotlib 이용하기
df5=df_last.pivot_table(index="지역명", values="평당분양가격", columns="연도")
df5.plot(kind="bar", rot=0, figsize=(13,5))
# 2. seaborn 이용하기
plt.figure(figsize=(13,5))
sns.barplot(data=df_last, x="지역명", y="평당분양가격", hue="연도", ci=None)밑의 코드는 seaborn + hue를 이용해서 그림을 그리자... plot으로 안되는 경우도 꽤 많다...
5-2-2. boxplot [Seaborn boxplot, Pandas boxplot]
plot.box는 안되지만 pandas의 boxplot은 seaborn의 boxplot와 비슷하게 출력할 수 있다.
Pandas.boxplot VS Pandas.box
Pandas의 boxplot 코드 설명
df.boxplot(column="y축", by="x축")# 1. matplotlib 이용하기
df_last.boxplot(column="평당분양가격", by="지역명", figsize=(13,5))
# 2. seaborn 이용하기
plt.figure(figsize=(13,5))
sns.boxplot(data=df_last, x="지역명", y="평당분양가격")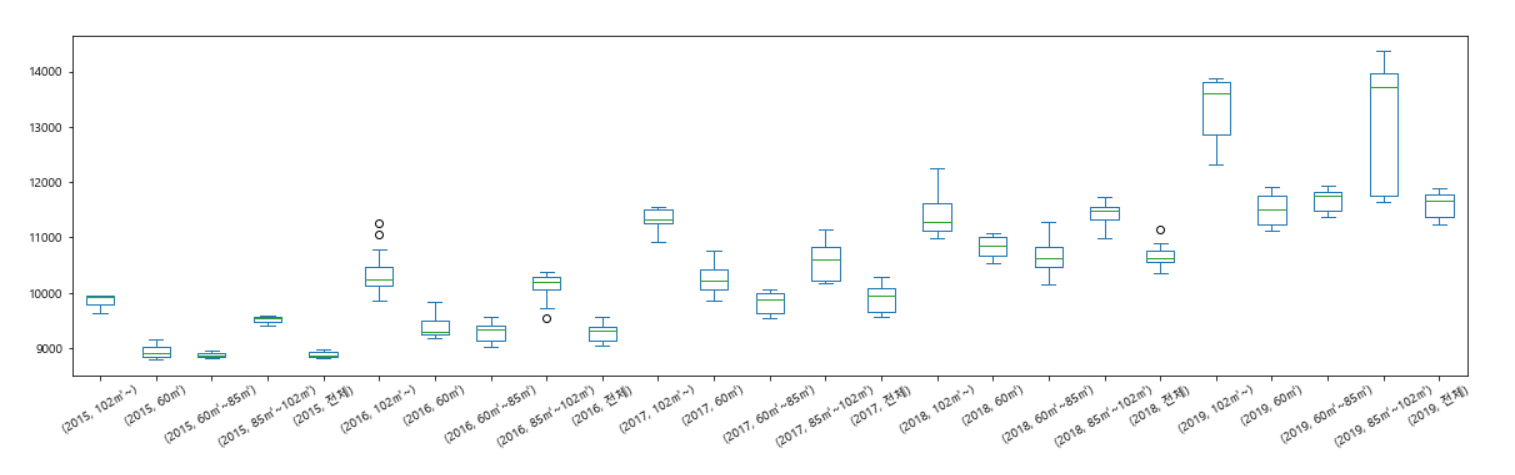
# 1. pandas box 이용하기
df_last.head()
df=df_last.pivot_table(index="월", columns=["연도", "전용면적"], values="평당분양가격")
df
df.plot(kind="box", figsize=(20,5), rot=30)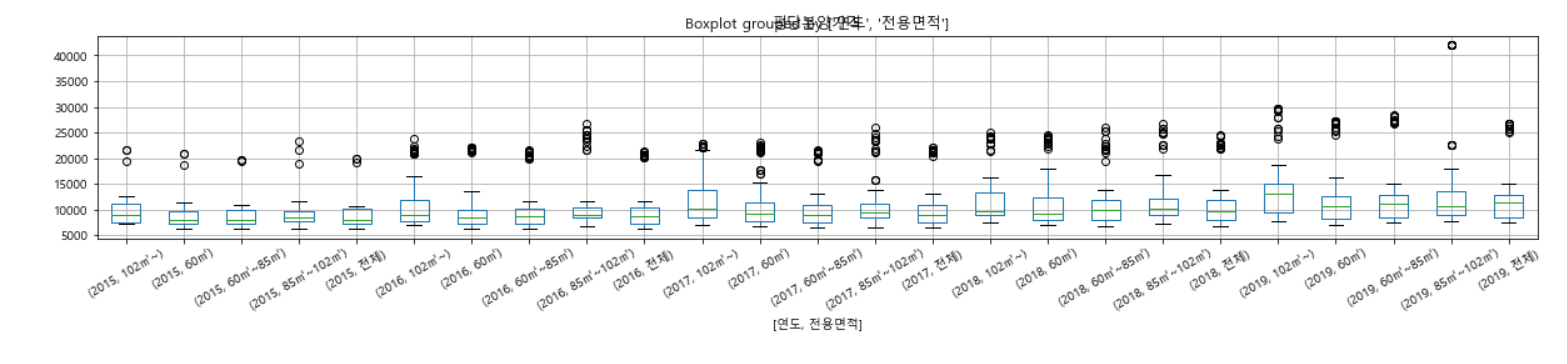
# 2. pandas boxplot 이용하기
df_last.boxplot(column='평당분양가격', by=['연도','전용면적'], figsize=(20,3), rot=30)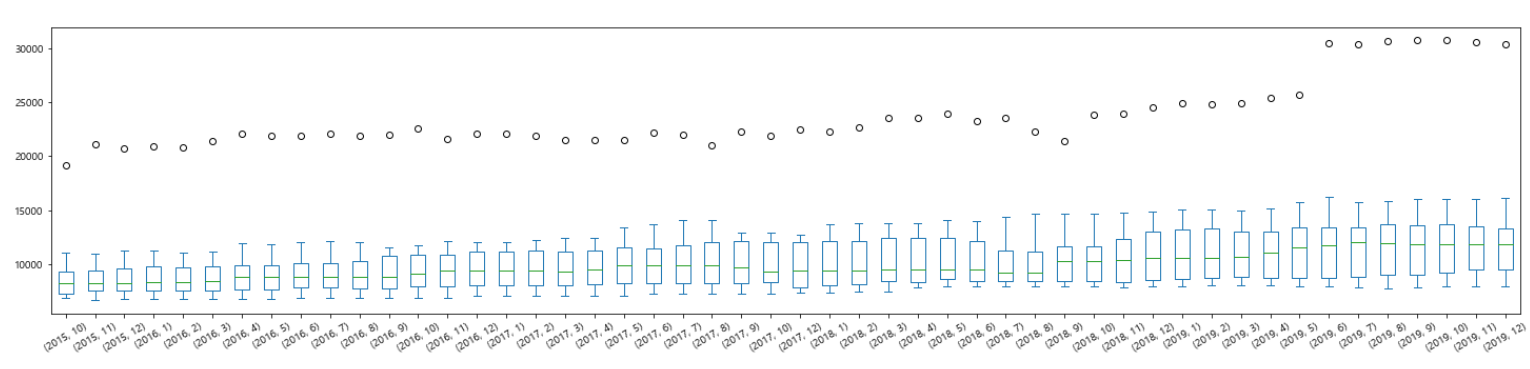
# 1. pandas의 box 이용하기
df7=df_last.pivot_table(columns=["연도", "월"], values="평당분양가격", index="지역명")
df7
df7.plot(kind="box", figsize=(25,5), rot=30)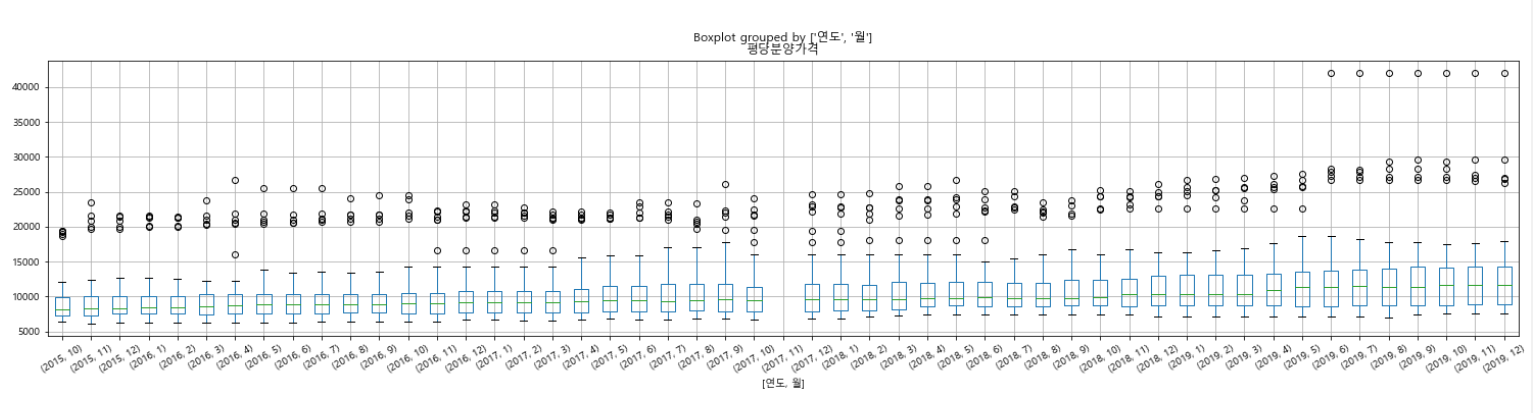
# 2. pandas의 boxplot으로 그려내기
df_last.boxplot(column="평당분양가격", by=["연도", "월"], figsize=(25,5), rot=30)5-2-3. violinplot
sns.violinplot(data=df, x, y, hue)5-2-4. lineplot
sns.lineplot(data=df, x, y, hue)6주차 정리
[목표] histogram & melt, concat 이용해서 데이터 합치기.
6-1. 이상치 확인하기.
max, min 같은 이상치를 확인할 수 있다.
df_last["평당분양가격"].describe()
max_price = df_last["평당분양가격"].max()
max_price
# 서울의 평당분양가격이 최대값을 갖는 행 가져오기
df_last.loc[df_last["평당분양가격"] == max_price]위의 코드를 이용하면 최댓값 이상치를 찾아서 보여줄 수 있다.
6-2. 히스토그램 그리기.
6-2-1. hist [in Pandas]
Series인 경우
df_last["원하는 칼럼명"].hist(bins=50, figsize=(,))DataFrame인 경우
axs=df_last.hist(bins=50, figsize=(,))
(ax1, ax2, ax3, ax4)=axs.flatten()
# 디테일을 조정하고 싶은 경우, 원하는 도화지 부분을 골라서 디테일 조정하기.6-2-2. plot.hist [in Pandas]
Series인 경우
df_last["원하는 칼럼명"].plot.hist(bins=50, figsize=(,))DataFrame인 경우
위의 경우와는 다르게 한 개의 도화지 위에 그래프 모두가 그려진다.
df_last.plot.hist(bins=50, figsize=(,))6-2-3. histplot [in Seaborn]
Series인 경우
sns.histplot(df_last["원하는 칼럼명"], kde=True)DataFrame인 경우
한 개의 도화지 위에 그래프 모두가 그려진다.
sns.histplot(df_last)6-2-4. seaborn kdeplot [in Seaborn]
Series인 경우
sns.kdeplot(data=df_last["원하는 칼럼명"])DataFrame인 경우
원하는 칼럼명을 리스트를 이용해서 넣어주고 그래프를 그려주자.
sns.kdeplot(data=df_last[["원하는 칼럼명1", "원하는 칼럼명2"]])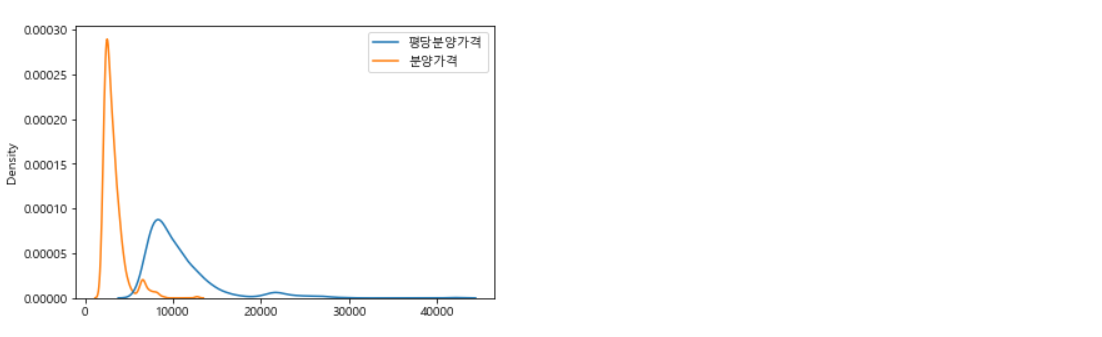
6-3. 기타 데이터 처리하기.
결측치가 없는 행들만 가져와서 그래프를 그리기.
not_null=df_last.loc[df_last["원하는 칼럼"].notnull(), "원하는 칼럼"] # [row, column]
not_nullnot_null을 이용해서 원하는 그래프를 이용해서 그려주면 된다.
df_last["원하는 칼럼"].value_counts() # 값을 세어주기
df_last["원하는 칼럼"].value_counts().index
# 그 값에 대한 인덱스 가져오기
df_last["원하는 칼럼"].value_counts().unique()
# 중복되지 않은 값을 가져오기6-4. 2013년 ~ 2015년 데이터 처리하기.
df_first = pd.read_csv("전국평균 분양가격 (2013년12월_2015년8월).csv", encoding="cp949")
df_first.shape
df_first.head()
df_first.info()
# 결측치 확인하기
df_first.isnull().sum()df_first를 확인한 결과 결측치가 존재하지 않음을 알 수 있다.
6-5. melt
df.melt(id_vars, value_vars, var_name, value_name)melt > pivot_table > reset_index() 시켜주면 index가 default로 들어간다. 그리고 columns를 이용해서 칼럼명 변경 가능하다.
- reset_index()를 사용하는 이유 : 모든 칼럼을 칼럼으로 이용하고 싶기 때문이다.
- 연도와 월 분리하는 함수
def parse_year(date):
year=date.split("년")[0]
year=int(year)
return year
def parse_month(date):
month=date.split("년")[-1].replace("월","")
month=int(month)
return month
today_date="2022년4월"
parse_year(today_date)
parse_month(today_date)map을 이용해서 각각 새로운 칼럼에 담아주면 된다.
df_last_melt.sample(10)이것을 이용해서 무작위로 10개를 골라낼 수 있다.
6-6. concat
- 일단 intersection을 이용하여 공통적인 칼럼만 가져온다.
df_first_melt.columns
df_last.columns
cols=df_last.columns.intersection(df_first_melt.columns)
cols- 공통적인 칼럼을 이용해서 데이터를 새롭게 준비한다.
# df_first_melt에서 공통된 컬럼만 가져온 뒤
# copy로 복사해서 df_first_prepare 변수에 담습니다.
df_first_prepare = df_first_melt[cols]
df_first_prepare.head()
# 이전 데이터에는 전용면적이 없기 때문에 "전체"만 사용하도록 합니다.
# loc를 사용해서 전체에 해당하는 면적만 copy로 복사해서 df_last_prepare 변수에 담습니다.
df_last_prepare = df_last.loc[df_last["전용면적"] == "전체", cols].copy()
df_last_prepare.head()- concat을 이용해서 두개의 데이터를 연결시켜준다. (default axis=0, 위에서 아래로 이어준다.)
df = pd.concat([df_first_prepare, df_last_prepare])
df- df의 값의 개수를 value_counts()를 이용해서 확인한다.
df["원하는 칼럼"].value_counts()7주차 정리
[목표] heatmap 그리기 & 데이터 내림차순 정렬 후 그래프 그리기.
7-1. heatmap
Seaborn heatmap VS Matplotlib pcolor
7-1-1. seaborn으로 heatmap 그리기.
plt.figure(figsize=(15,7), dpi=100)
ax=sns.heatmap(t, cmap="Blues", annot=True, fmt=".0f")
# annot = 셀 안에 값 넣어주기
# fmt = 값을 어디 까지 나타낼 것인지 정해주기'
# ax.get_yticklabels()
ax.set_yticklabels(ax.get_yticklabels(), rotation=0)t.T를 이용해서 데이터를 transpose 한 이후에 heatmap을 그려줄 수 있다.
7-1-2. matplotlib으로 pcolor 그리기.
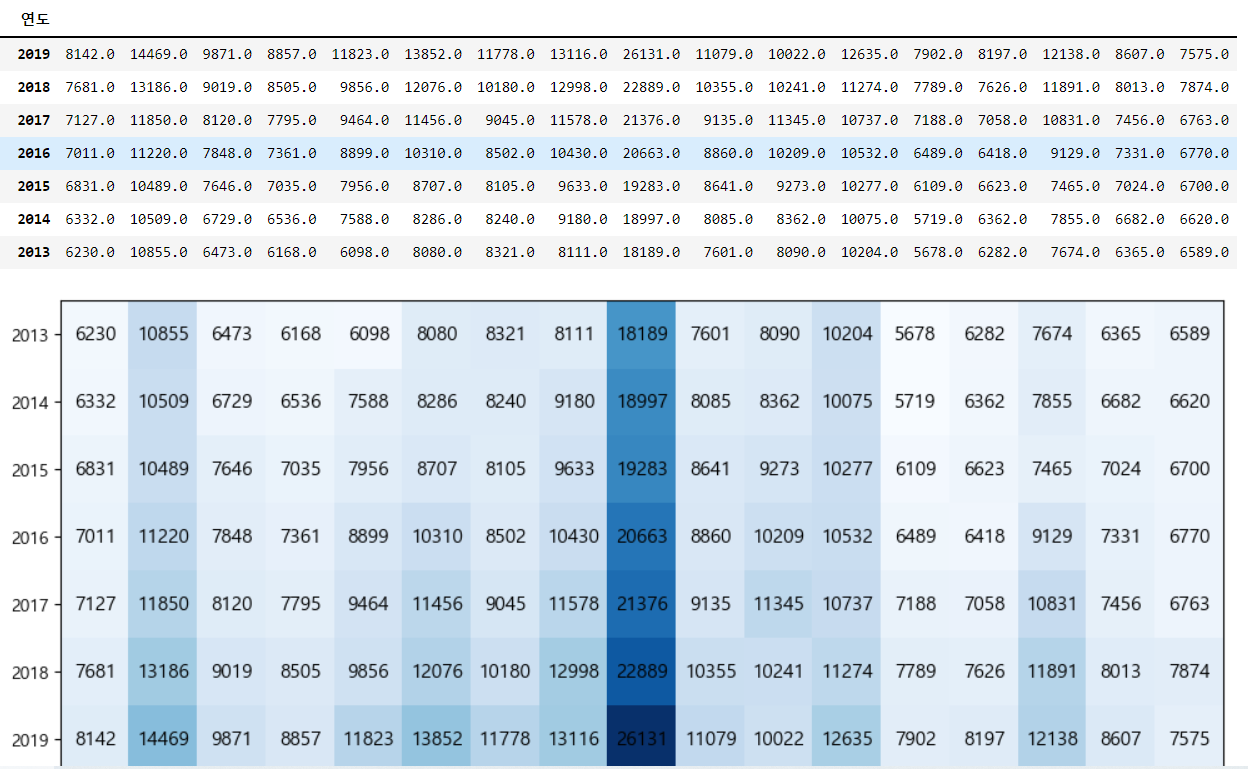
p-color는 밑에서 부터 데이터가 들어간다~! 주의하기. 필요에 따라서 데이터의 순서를 바꾸기도 해야 한다.
fig=plt.figure(figsize=(15,5), dpi=100)
ax=fig.subplots()
t2=t.iloc[::-1]
t2
# p-color는 데이터를 밑에서 부터 넣기 때문에 데이터의 순서를 변경해줘야 한다.
hm1=ax.pcolor(t2, cmap="Blues") # pcolor
_=fig.colorbar(hm1, ax=ax) #colorbar
col_len=len(t2.columns)
row_len=len(t2.index)
for r in range(row_len): # 행의 인덱스
for c in range(col_len): # 열의 인덱스
_=ax.text(c+0.5, r+0.5, int(t2.iloc[r, c]),ha="center", va="center", color="k", fontsize=11)
# 텍스트 넣어주기
# ax.get_xticklabels() get_xticklabels를 이용해서 label 있는지 없는지 확인하기.
ax.set_yticks(np.arange(row_len)+0.5)
ax.set_yticklabels(t2.index)
ax.set_xticks(np.arange(col_len)+0.5)
ax.set_xticklabels(t2.columns)7-2. graph
7-2-1. barplot
sns.barplot(data=df, x, y, hue, estimator, ci=None, palette)7-2-2. lineplot & pointplot
sns.lineplot(data=df, x, y, hue, estimator, ci=None)
sns.pointplot(data=df, x, y, hue, estimator, ci=None)하나의 ax에 다른 그림을 한꺼번에 그릴 수 있다.
7-2-3. boxplot
sns.boxplot(data, x, y)7-2-4. violinplot
sns.violinplot(data, x, y)7-3. 내림차순 정렬 후 graph 그리기.
내림차순 데이터로 그래프 그리는 순서
1. 원하는 pivot_table이나 grouping을 한 뒤에, sort_values (by와 ascending=False) 을 이용해서 내림차순으로 만들어준다.
2. 원하는 그래프를 그려주기.
# groupby 또는 pivot_table로 평당분양가격 평균 구하고, sort_values 함수 사용
mean_price = df.groupby(["지역명"])["평당분양가격"].mean().to_frame().sort_values(by="평당분양가격", ascending=False)
mean_price = df.pivot_table(index="지역명", values="평당분양가격").sort_values(by="평당분양가격", ascending=False)
mean_priceplot.bar 로 barghaph 그리기.
DataFrame, Series 딱히 중요하지 않다.. 두개 모두 잘 그려지고 있다.
fig=plt.figure(figsize=(20,5))
ax1,ax2=fig.subplots(1,2)
mean_price['평당분양가격'].plot.bar(ax=ax1)
mean_price.plot.bar(ax=ax2)seaborn으로 barplot 그리기.
mean_price
fig=plt.figure(figsize=(12, 12))
ax1,ax2,ax3=fig.subplots(3,1)
sns.barplot(data=mean_price, x=mean_price.index, y="평당분양가격", palette="Blues_r", ax=ax1)
sns.barplot(data=mean_price.reset_index(), x='지역명', y="평당분양가격", palette="Blues_r", ax=ax2)
# 아예 reset_index() 처리를 해주고 index를 이용하지 않기
sns.barplot(data=df, x='지역명', y="평당분양가격", palette="Blues_r", ax=ax3, order=mean_price.index) # order='지역명' 이런식으로는 불가능여기서 주의할 점 ! boxplot과 violinplot은 좀 다르다... 위에서는 직접 데이터를 만들어서 넣어줬지만, 데이터를 만든 후에 df로 그래프를 그리고 2개는 order를 이용해서 index를 넣어준다...!

