11일차
오전: dacon 기온 예측
오후: 제주도 시간별 외식업 이용자 수 예측
1. 기온예측 해커톤
1.1 베이스 라인 작성
import pandas as pd
train_csv_path = '/content/drive/MyDrive/fly_ai/3주차/dacon_기온예측/train.csv'
submission_csv_path = '/content/drive/MyDrive/fly_ai/3주차/dacon_기온예측/sample_submission.csv'
train_df = pd.read_csv(train_csv_path)
submission_df = pd.read_csv(submission_csv_path)
print(train_df.head())
print(submission_df.head())
일시 최고기온 최저기온 일교차 강수량 평균습도 평균풍속 일조합 일사합 일조율 평균기온
0 1960-01-01 2.2 -5.2 7.4 NaN 68.3 1.7 6.7 NaN NaN -1.6
1 1960-01-02 1.2 -5.6 6.8 0.4 87.7 1.3 0.0 NaN NaN -1.9
2 1960-01-03 8.7 -2.1 10.8 0.0 81.3 3.0 0.0 NaN NaN 4.0
3 1960-01-04 10.8 1.2 9.6 0.0 79.7 4.4 2.6 NaN NaN 7.5
4 1960-01-05 1.3 -8.2 9.5 NaN 44.0 5.1 8.2 NaN NaN -4.6
일시 평균기온
0 2023-01-01 0
1 2023-01-02 0
2 2023-01-03 0
3 2023-01-04 0
4 2023-01-05 0
시간이 중요할 것이라 생각했기때문에 결측치를 바로 전 날의 데이터를 넣음
train_df['최고기온'].fillna(method='bfill', inplace=True) # 뒤의 값으로 대체
train_df['최저기온'].fillna(method='bfill', inplace=True)
train_df['일교차'].fillna(method='bfill', inplace=True)
train_df['강수량'].fillna(method='bfill', inplace=True)
train_df['평균풍속'].fillna(method='bfill', inplace=True)
train_df['일조합'].fillna(method='bfill', inplace=True)
train_df['일사합'].fillna(method='bfill', inplace=True)
train_df['일조율'].fillna(method='bfill', inplace=True)
train_df.isnull().sum()
일시 0
최고기온 0
최저기온 0
일교차 0
강수량 0
평균습도 0
평균풍속 0
일조합 0
일사합 0
일조율 0
평균기온 0
dtype: int64# '일시' 열을 datetime 형식으로 변환
train_df['일시'] = pd.to_datetime(train_df['일시'])
# '월' 정보를 추출하여 '계절' 변수 생성
train_df['월'] = train_df['일시'].dt.month
train_df['계절'] = train_df['월'].apply(lambda x: '봄' if 3 <= x <= 5 else ('여름' if 6 <= x <= 8 else ('가을' if 9 <= x <= 11 else '겨울')))
# 날짜 데이터 변환
train_df['일시'] = pd.to_datetime(train_df['일시'])
train_df = train_df.set_index('일시')
# 데이터의 시간 간격 지정
train_df.index.freq = 'D'
# 일시 컬럼이 인덱스로 할당됩니다.
train_df.head()
최고기온 최저기온 일교차 강수량 평균습도 평균풍속 일조합 일사합 일조율 평균기온 월 계절
일시
1960-01-01 2.2 -5.2 7.4 0.4 68.3 1.7 6.7 4.81 28.1 -1.6 1 겨울
1960-01-02 1.2 -5.6 6.8 0.4 87.7 1.3 0.0 4.81 28.1 -1.9 1 겨울
1960-01-03 8.7 -2.1 10.8 0.0 81.3 3.0 0.0 4.81 28.1 4.0 1 겨울
1960-01-04 10.8 1.2 9.6 0.0 79.7 4.4 2.6 4.81 28.1 7.5 1 겨울
1960-01-05 1.3 -8.2 9.5 0.0 44.0 5.1 8.2 4.81 28.1 -4.6 1 겨울1.2 학습
# prophet에서 데이터를 인식하도록 일시는 ds로, target값인 평균기온은 y로 지정해줍니다.
train_df = train_df.reset_index()
train_df = train_df.rename(columns={'일시': 'ds', '평균기온': 'y'})
train_df = train_df.drop(['일조율', '평균풍속'], axis=1)
#모델 학습
prophet = Prophet()
prophet.fit(train_df)
#모델 예측
future_data = prophet.make_future_dataframe(periods = 358, freq = 'd') #periods는 예측할 기간
forecast_data = prophet.predict(future_data)
forecast_data[['ds','yhat']].tail(5)
ds yhat
23364 2023-12-20 0.399567
23365 2023-12-21 0.292523
23366 2023-12-22 0.160250
23367 2023-12-23 0.095147
23368 2023-12-24 -0.092838
#결과 저장
submission_df.to_csv("prophet_submission.csv", index=False)결과는 3.10114 로 174등을 했다. 데이콘 코드공유를 많이 참조하긴 하였지만 시계열 데이터경험으로는 좋았다.

2. 제주도 외식업 이용자 수 예측
2.1 베이스라인 작성
import pandas as pd
df = pd.read_csv('/content/drive/MyDrive/fly_ai/3주차/제주도_사고예측/시간대별 외식업 이용자수.csv', encoding='euc-kr')
base_year_month time_range sex age_range user_count
0 201901 09~12 남성 20대 이하 33760
1 201901 09~12 남성 30대 132276
2 201901 09~12 남성 40대 173193
3 201901 09~12 남성 50대 108671
4 201901 09~12 남성 60대 37139
#이상값 확인
for column in df.columns:
value_counts = df[column].value_counts()
print(f"Column '{column}':\n{value_counts}\n")
#이상치 발견되어 대체
other_rows = df[df['time_range'] == '기타']
half_length = len(other_rows) // 2
df.loc[other_rows.head(half_length).index, 'time_range'] = '00~06'
# 나머지 '기타'인 행을 '06~09'로 변경
df.loc[other_rows.tail(half_length).index, 'time_range'] = '06~09'
#인덱스 지정
df['sex'] = df['sex'].apply(lambda x: 0 if x == '남성' else 1)
age_range_mapping = {'20대 이하': 0, '30대': 1, '40대': 2, '50대': 3, '60대': 4, '70대 이상': 5}
df['age_range'] = df['age_range'].map(age_range_mapping)
# time_range를 09, 12, 15, 18, 21, 00, 06로 분할하여 첫 번째 값을 시간으로 인덱싱
df['hour'] = df['time_range'].str.split('~').str[0].astype(int)
# 00을 24로 변경
df['hour'] = df['hour'].replace(0, 24)
# 분할 후 데이터프레임 확인
print(df)2.2 학습
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
# 시계열 형식으로 데이터 변환
df['timestamp'] = pd.to_datetime(df['base_year_month'], format='%Y%m') + pd.to_timedelta(df['hour'], unit='h')
# 필요한 열만 선택
data = df[['timestamp', 'sex', 'age_range', 'user_count']]
# 시계열 데이터를 기반으로 user_count를 예측하는 문제로 변환
data = data.set_index('timestamp')
data.sort_index(inplace=True)
# 특성 및 타겟 선택
X = data[['sex', 'age_range']]
y = data['user_count']
# MinMaxScaler를 사용하여 데이터 스케일링
scaler_X = MinMaxScaler()
X_scaled = scaler_X.fit_transform(X)
scaler_y = MinMaxScaler()
y_scaled = scaler_y.fit_transform(y.values.reshape(-1, 1))
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y_scaled, test_size=0.2, shuffle=False)
# LSTM 입력 형태로 변환
def create_sequences(X, y, seq_length):
X_sequences, y_sequences = [], []
for i in range(len(X) - seq_length):
X_sequences.append(X[i:i+seq_length])
y_sequences.append(y[i+seq_length])
return np.array(X_sequences), np.array(y_sequences)
seq_length = 5 # 임의의 시퀀스 길이
X_train_seq, y_train_seq = create_sequences(X_train, y_train, seq_length)
X_test_seq, y_test_seq = create_sequences(X_test, y_test, seq_length)
# 모델 정의
model = Sequential()
# 첫 번째 LSTM 레이어
model.add(LSTM(units=50, activation='relu', return_sequences=True, input_shape=(X_train_seq.shape[1], X_train_seq.shape[2])))
model.add(Dropout(0.2))
# 두 번째 LSTM 레이어
model.add(LSTM(units=50, activation='relu', return_sequences=True))
model.add(Dropout(0.2))
# 세 번째 LSTM 레이어
model.add(LSTM(units=50, activation='relu'))
model.add(Dropout(0.2))
# 출력 레이어
model.add(Dense(units=1))
# 모델 컴파일
model.compile(optimizer='adam', loss='mean_squared_error')
# 모델 학습
model.fit(X_train_seq, y_train_seq, epochs=20, batch_size=32, validation_data=(X_test_seq, y_test_seq))
Epoch 18/20
69/69 [==============================] - 1s 15ms/step - loss: 0.0299 - val_loss: 0.0357
Epoch 19/20
69/69 [==============================] - 1s 13ms/step - loss: 0.0302 - val_loss: 0.0352
Epoch 20/20
69/69 [==============================] - 1s 12ms/step - loss: 0.0299 - val_loss: 0.03532.3 결과
y_pred_scaled = model.predict(X_test_seq)
y_pred = scaler_y.inverse_transform(y_pred_scaled)
y_actual = scaler_y.inverse_transform(y_test_seq.reshape(-1, 1))
# 예측값과 실제값 비교
compare_df = pd.DataFrame({'Actual': y_actual.flatten(), 'Predicted': y_pred.flatten()})
print(compare_df)
Actual Predicted
0 99175.0 64615.609375
1 95139.0 61042.718750
2 20397.0 80592.960938
3 382685.0 114360.953125
4 320305.0 124056.015625
import matplotlib.pyplot as plt
# 테스트 데이터에 대한 예측
y_pred_scaled = model.predict(X_test_seq)
y_pred = scaler_y.inverse_transform(y_pred_scaled)
y_actual = scaler_y.inverse_transform(y_test_seq.reshape(-1, 1))
# 결과 시각화
plt.figure(figsize=(10, 6))
plt.plot(y_actual, label='Actual')
plt.plot(y_pred, label='Predicted')
plt.title('Actual vs Predicted User Counts')
plt.xlabel('Time Step')
plt.ylabel('User Counts')
plt.legend()
plt.show()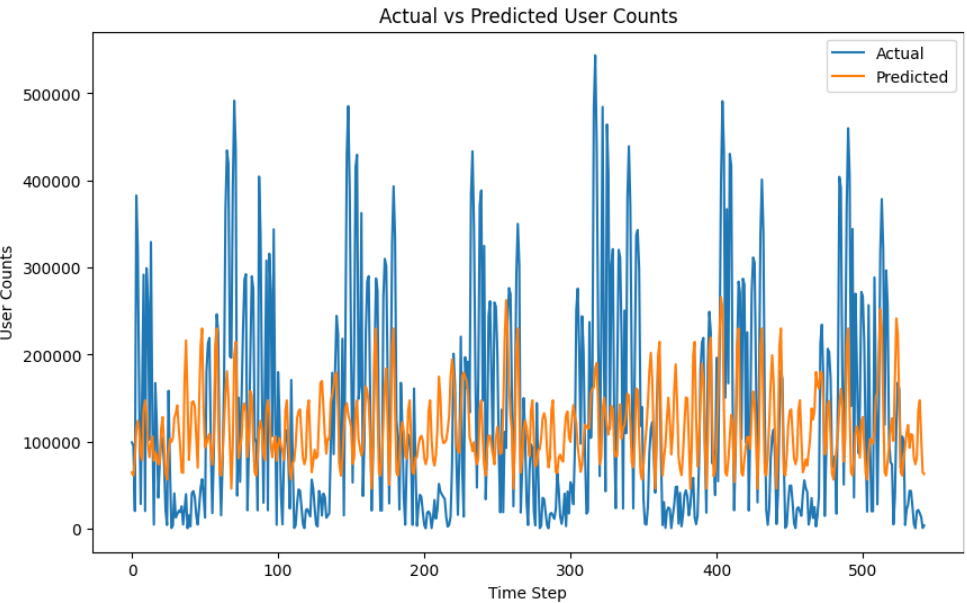
예측 결과를 보니 정확도가 많이 낮았다.
시계열 데이터를 처리하는데 시간 데이터가 9~12(시) 이런식으로 범주형으로 묶여있다보니 데이터 전처리가 미숙했던 것 같다. 여러 실험을 해봐야할 것 같다.

개발자