Fly ai 4기 4주차 day 23 : Azure Machine Learning Studio
0

1. Azure Machine Learning Studio
https://ml.azure.com 에서 작업한다.
작업영역 생성
work space를 만든다
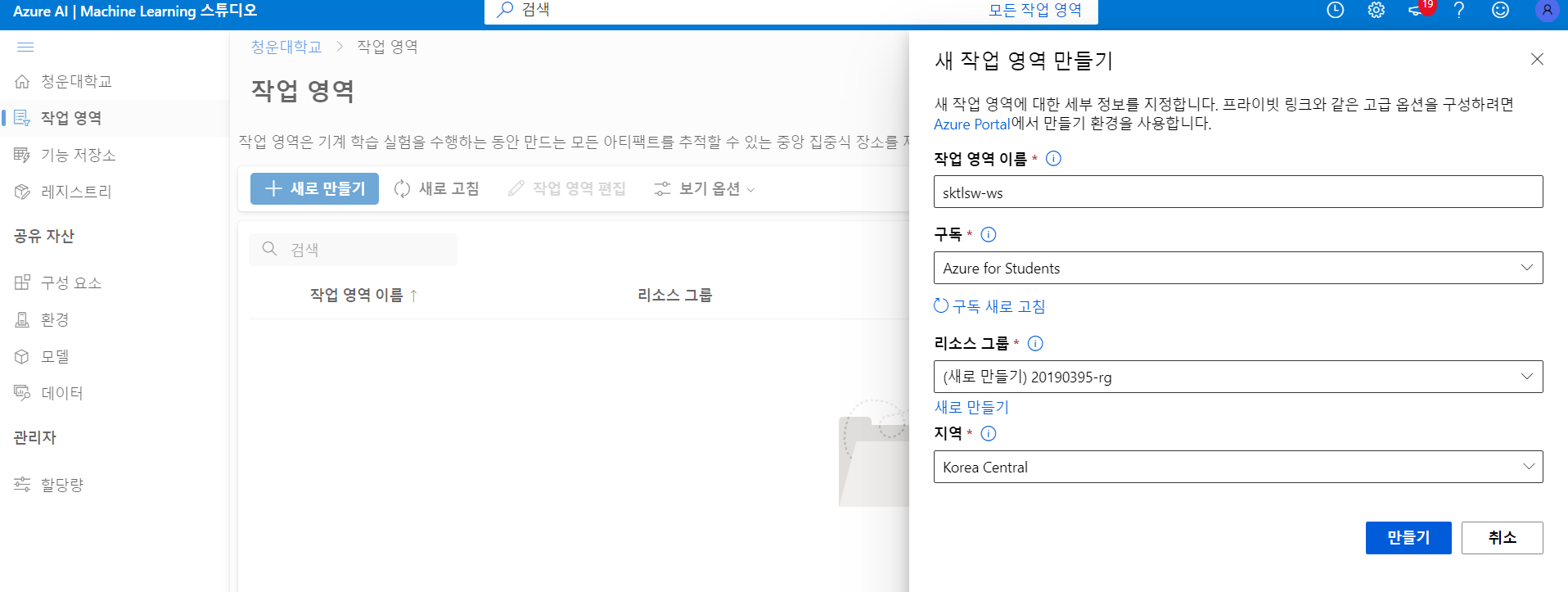
작업영역 화면
portal.azure에 리소스 그룹을 보면 아래와 같이 보인다
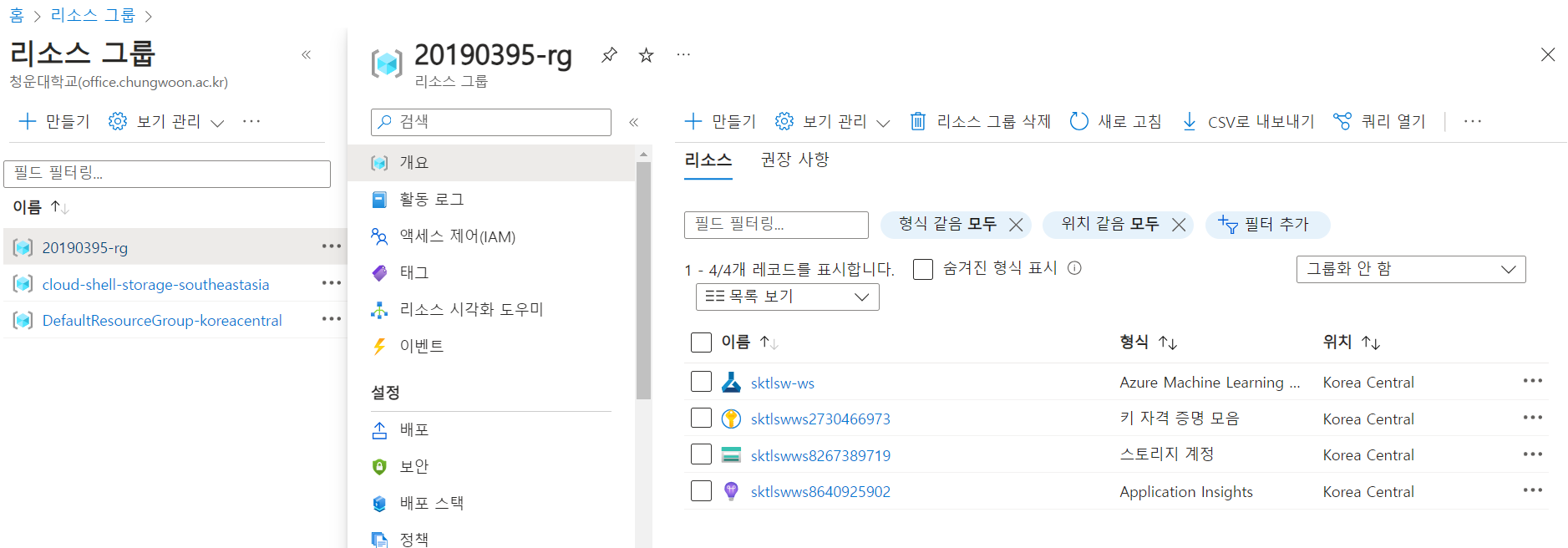
Compute Instance 만들기
파이썬 파일을 실행할 가상 머신을 만들어줘야한다.
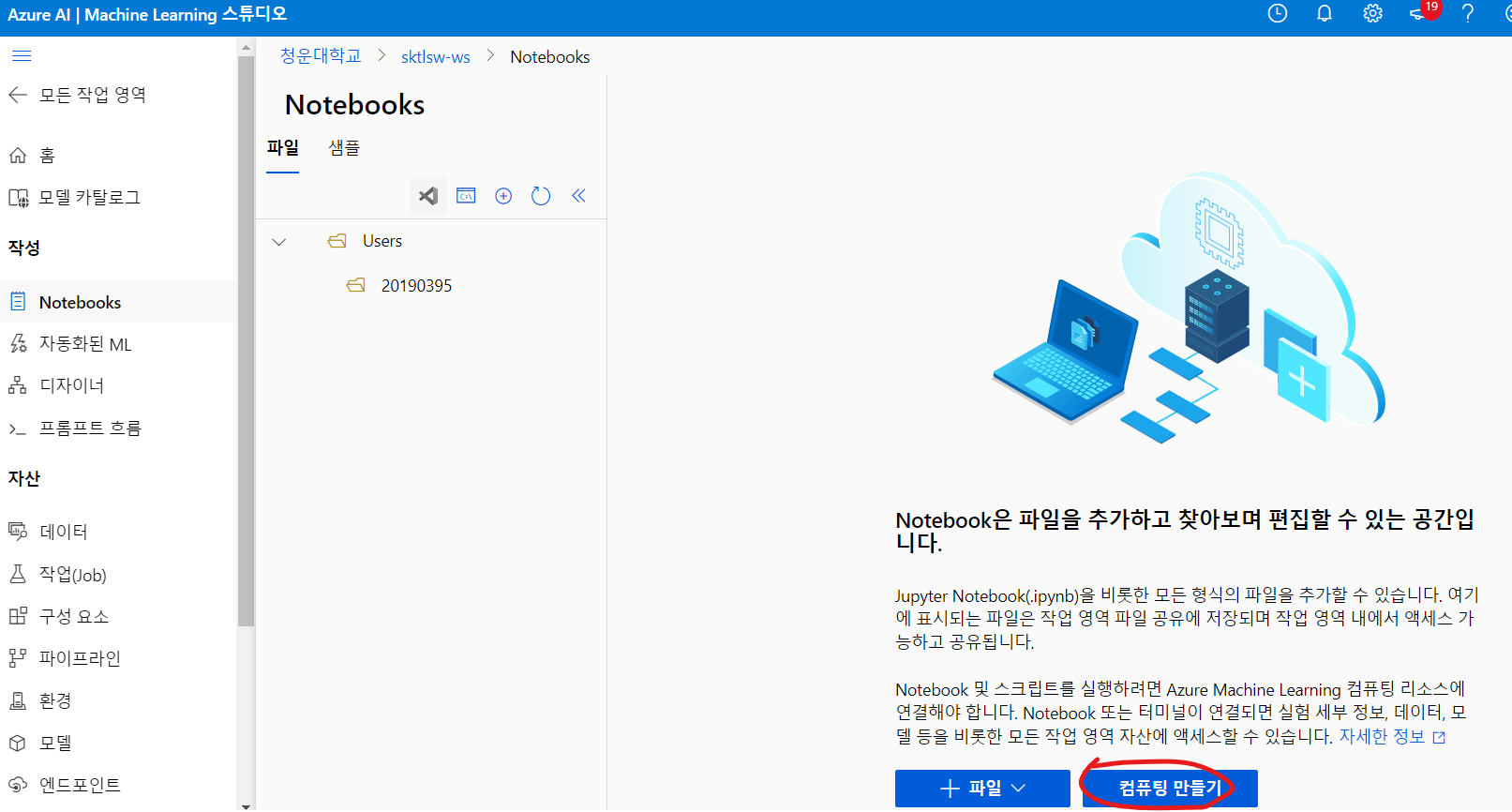
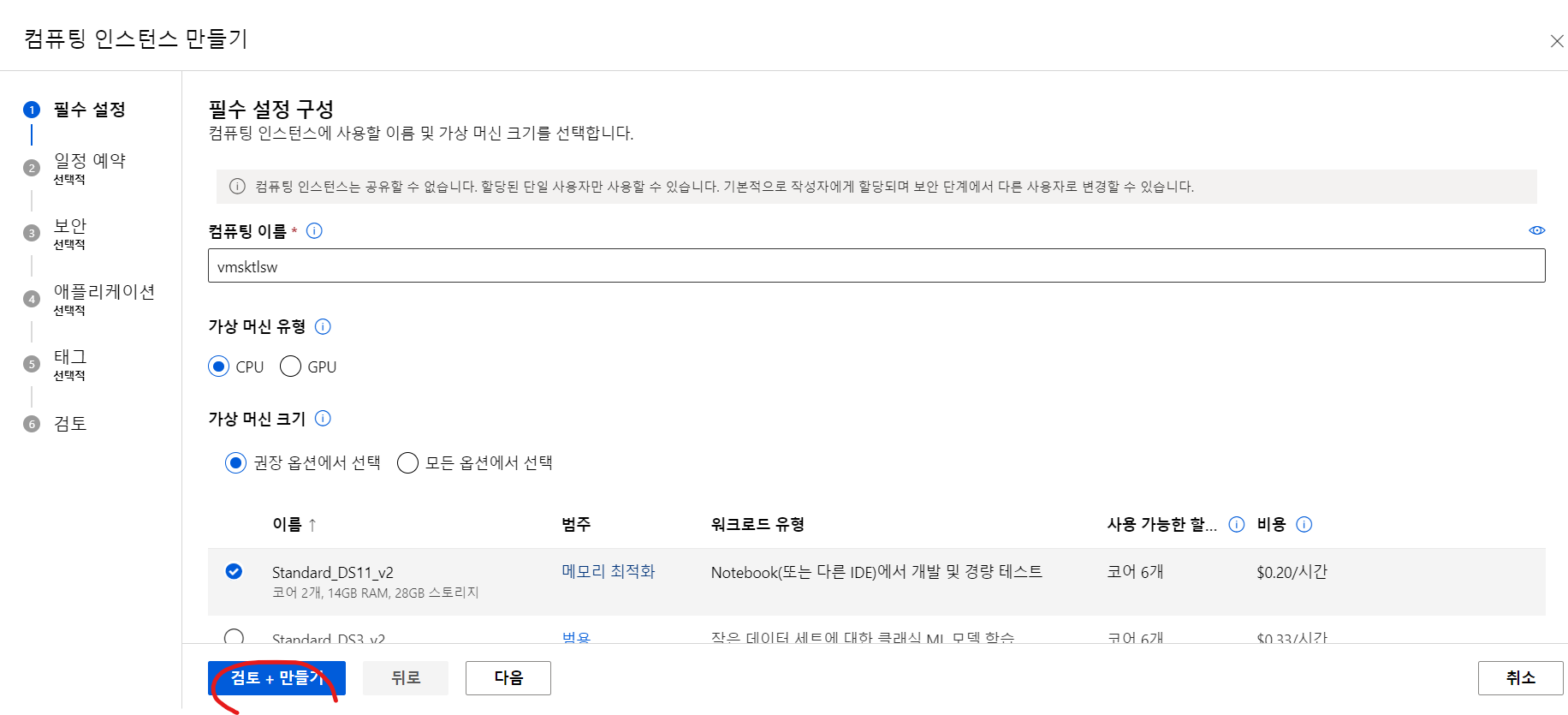
파일 만들기
work space 파일을 만들어 가상머신으로 실행시키면 잘 작동이 된다.

2. Speech(tts, stt)
스피치 서비스 만들기
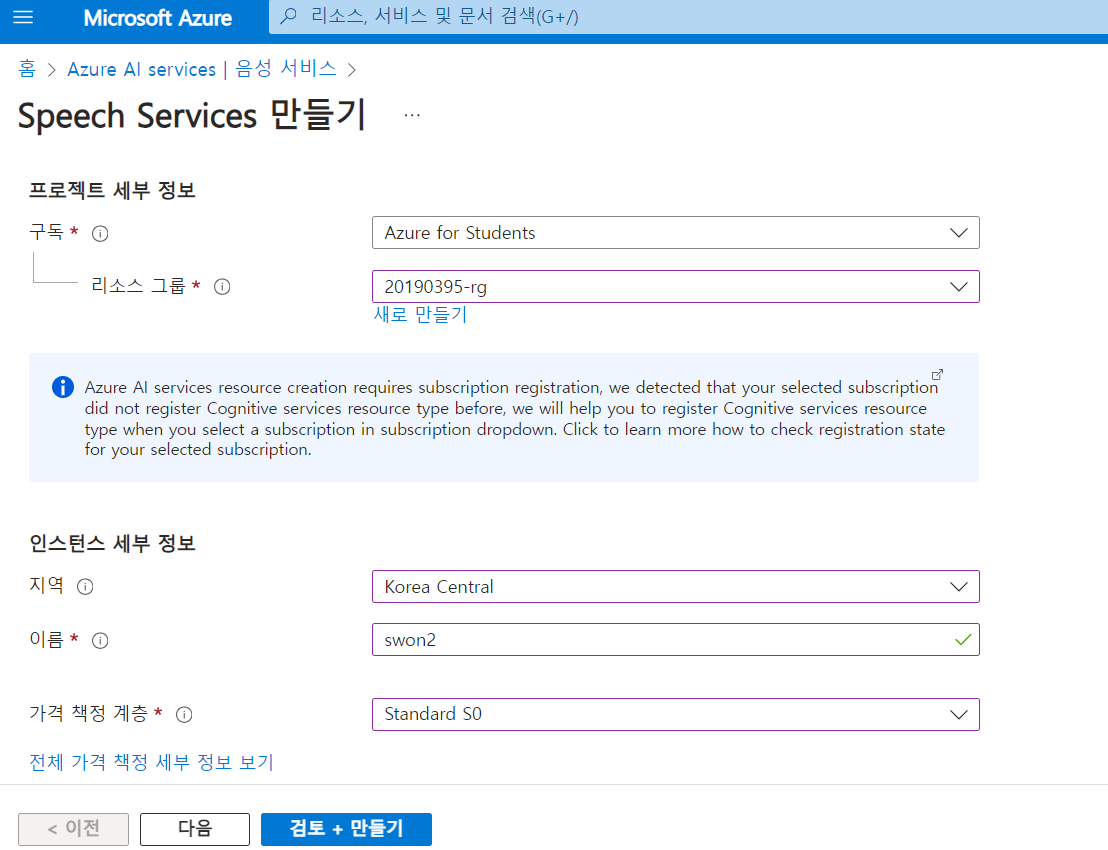
바탕화면에 tts 폴더 하나를 만들고 vs code로 열어준다.
가상환경을 만들어주고 activate 한다
python -m venv venv
pip install python-dotenv azure-cognitiveservices-speech 다 설치했다면 .env 파일을 설정해준다
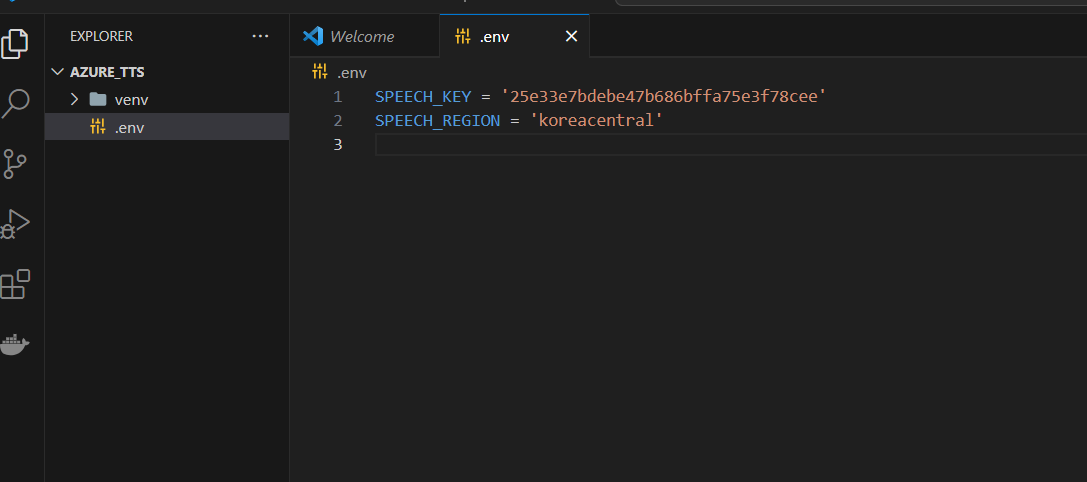
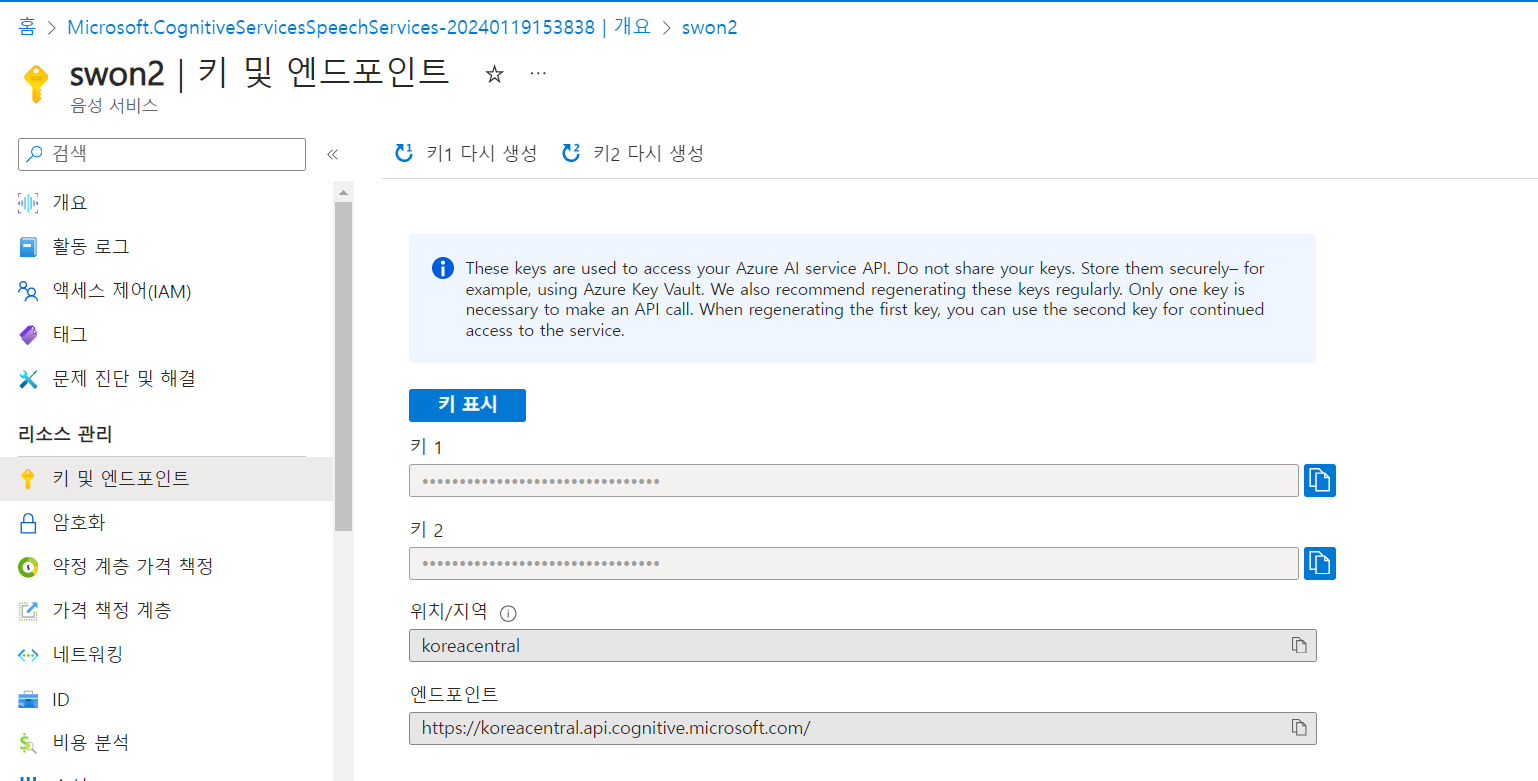
key값과 region값은 portal azure에 있다.
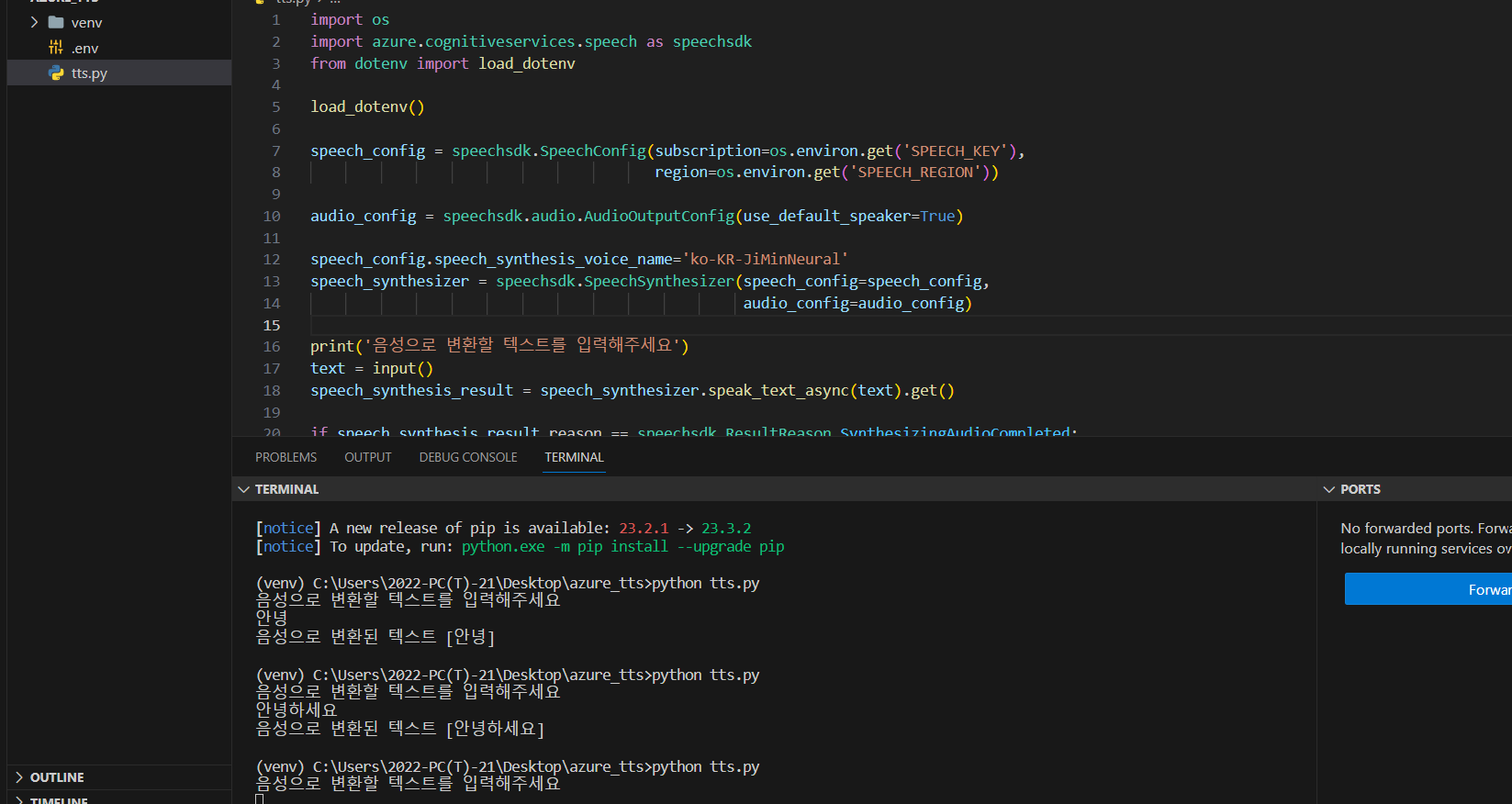
tts.py 파일을 만들고 아래 코드를 넣어준다.
import os
import azure.cognitiveservices.speech as speechsdk
from dotenv import load_dotenv
load_dotenv()
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('SPEECH_KEY'),
region=os.environ.get('SPEECH_REGION'))
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)
speech_config.speech_synthesis_voice_name='ko-KR-JiMinNeural'
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config,
audio_config=audio_config)
print('음성으로 변환할 텍스트를 입력해주세요')
text = input()
speech_synthesis_result = speech_synthesizer.speak_text_async(text).get()
if speech_synthesis_result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
print('음성으로 변환된 텍스트 [{}]'.format(text))
elif speech_synthesis_result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = speech_synthesis_result.cancellation_details
print("음성 변환 취소됨 {}".format(cancellation_details))
if cancellation_details == speechsdk.CancellationReason.Error:
if cancellation_details.error_details:
print("에러 : {}".format(cancellation_details.error_details))
print("키(key)와 지역(region)을 설정하셨나요?")
이제 python tts.py를 실행하고 듣고싶은 텍스트를 입력하면 소리가 잘 나온다.
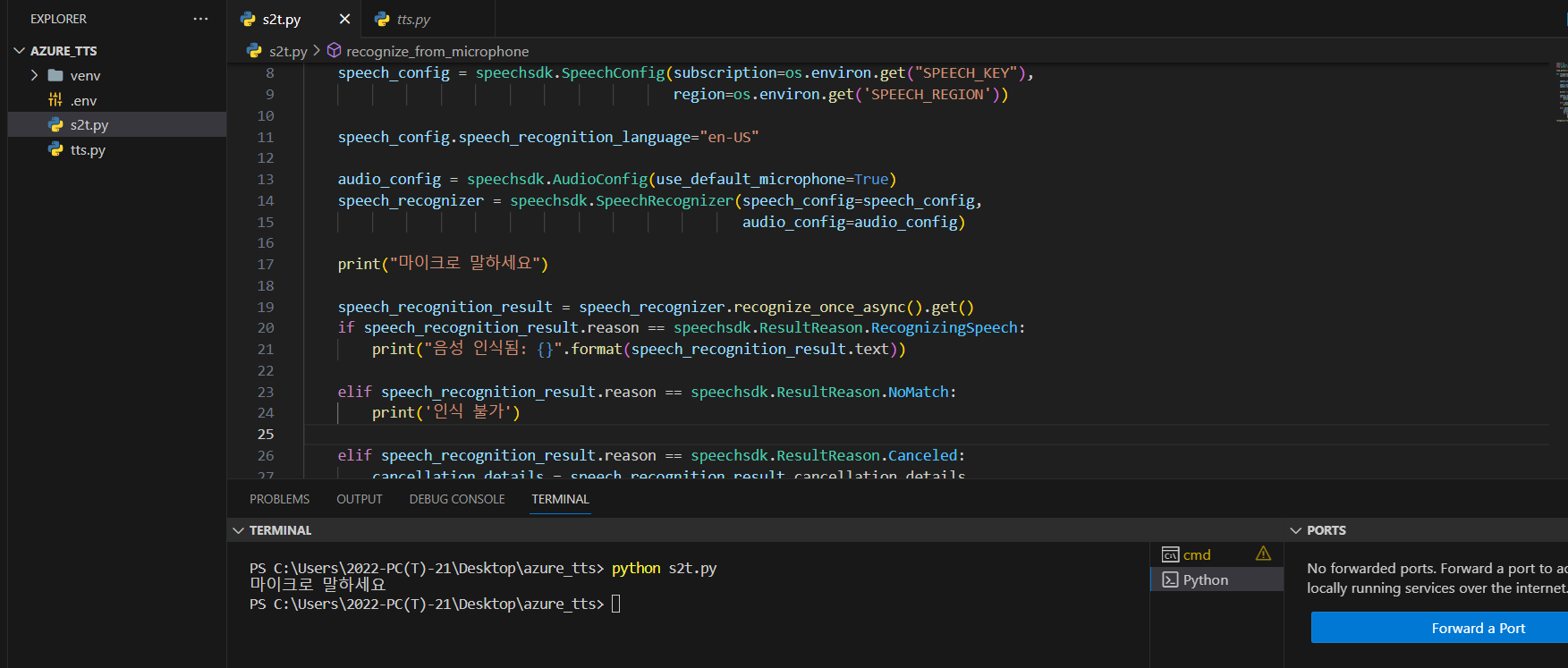
stt.py 파일 생성 후 아래 코드 입력
import os
import azure.cognitiveservices.speech as speechsdk
from dotenv import load_dotenv
load_dotenv()
def recognize_from_microphone():
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get("SPEECH_KEY"),
region=os.environ.get('SPEECH_REGION'))
speech_config.speech_recognition_language="en-US"
audio_config = speechsdk.AudioConfig(use_default_microphone=True)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=speech_config,
audio_config=audio_config)
print("마이크로 말하세요")
speech_recognition_result = speech_recognizer.recognize_once_async().get()
if speech_recognition_result.reason == speechsdk.ResultReason.RecognizingSpeech:
print("음성 인식됨: {}".format(speech_recognition_result.text))
elif speech_recognition_result.reason == speechsdk.ResultReason.NoMatch:
print('인식 불가')
elif speech_recognition_result.reason == speechsdk.ResultReason.Canceled:
cancellation_details = speech_recognition_result.cancellation_details
print("음성을 텍스트로 변환 취소됨 {}".format(cancellation_details.reason))
if cancellation_details.reason == speechsdk.CancellationReason.Error:
print('에러 : {}'.format(cancellation_details.error_details))
print("키(key)와 지역(region) 변수를 설정하셨나요?")
recognize_from_microphone()stt.py 를 실행하면 speech to text이 작동된다.

개발자