자연어처리
임베딩
임베딩은 사람이 사용하는 언어를 컴퓨터가 이해할 수 있는 언어(숫자) 형태인 벡터로 변환한 결과 혹은 일련의 과정을 의미
희소 표현 기반 임베딩
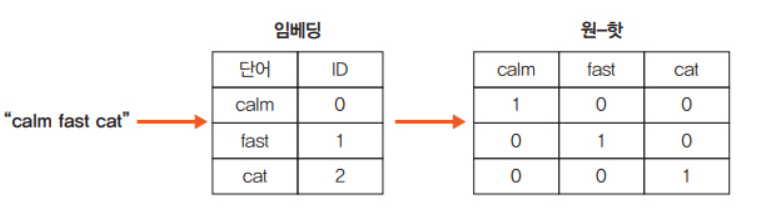
- 희소표현은 대부분의 값이 0으로 채워져 있는 경우로 대표적으로 원-핫 인코딩이 있음
치명적인 단점
-
단어간의 의미를 얻지 못함
-
하나의 단어를 표현하는 데 말뭉치(corpus)에 있는 수만큼 차원이 존재하기
때문에 복잡해짐 -
원-핫 인코딩에 대한 대안으로 신경망에 기반하여 단어를 벡터로 바꾸는
방법론들이 주목을 받고 있음 -
예를 들어 워드투벡터(Word2Vec), 글로브(GloVe), 패스트텍스트(FastText) 등이
대표적인 방법론
예측 기반 임베딩
-
예측 기반 임베딩은 신경망 구조 혹은 모델을 이용하여 특정 문맥에서 어떤 단어가 나올지 예측하면서 단어를 벡터로 만드는 방식
-
대표적으로 워드투벡터가 있음
word2vector
-
CBOW
- CBOW(Continuous Bag Of Words)는 단어를 여러 개 나열한 후 이와 관련된 단어를 추정하는 방식. 즉, 문장에서 등장하는 n개의 단어 열에서 다음에 등장할 단어를 예측
-
skip-gram
- skip-gram 방식은 CBOW 방식과 반대로 특정한 단어에서 문맥이 될 수 있는 단어를 예측. 즉, skip-gram은 다음 그림과 같이 중심 단어에서 주변 단어를 예측하는 방식을 사용
패스트텍스트
-
워드투벡터는 사전에 없는 단어에 대해서는 벡터 값을 얻을 수 없음
-
패스트텍스트는 노이즈에 강하며, 새로운 단어에 대해서는 형태적 유사성을 고려한 벡터 값을 얻기 때문에 자연어 처리 분야에서 많이 사용되는 알고리즘
Transformer
등장배경
RNN의 한계
- GPU 병렬처리가 안됨
- Long-term dependency problem
Self-Attention
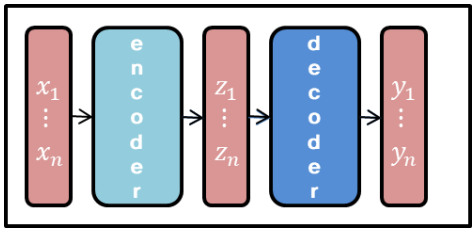
– Encoder : input seq (x) ➔ latent seq (z)
– Decoder : latent seq (z) ➔ output seq (y)
– Autoregressive : 이전 단계의 output이 다음 단계의 input으로 사용
Transformer 구조
Input Embedding
-
inputs에 입력된 데이터를 컴퓨터가 이해할 수 있도록 행렬 값으로 바꿔줌
-
Input Embedding 레이어는 인덱스 값들을 받아 이를 각각의 단어 임베딩 벡터값으로 바꿔줌
Positional Encoding
-
트랜스포머는 입력되는 문장을 순차적으로 처리하지 않고 병렬로 한번에
처리하기 때문에 단어의 위치 정보를 다른 방식으로 알려줘야 함 -
트랜스포머는 입력되는 문장을 순차적으로 처리하지 않고 병렬로 한번에
처리하기 때문에 단어의 위치 정보를 다른 방식으로 알려줘야 함
Scaled Dot-Product Attention
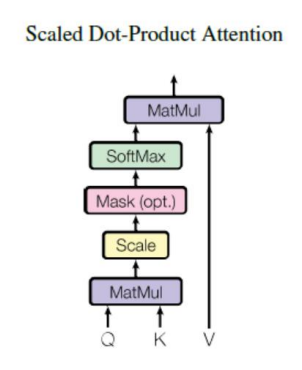

Attention = 쿼리 x 키 x 값 = Q, K 내적으로 단어간
유사성을 구하고 V(중요도)를 곱해서
중요하고 관련있는 단어에 더 관심을 둔다.
Multi-Head Attention
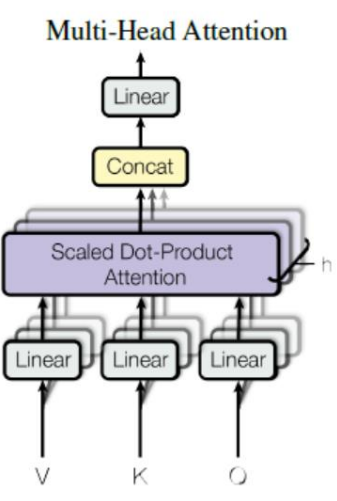
Multi-head : 여러 관점에서 attention을 달리준다.
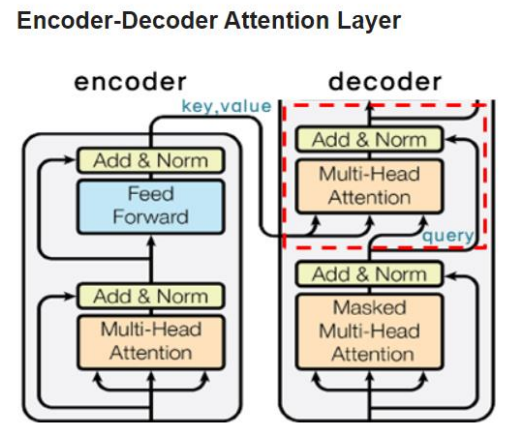
Encoder Decoder
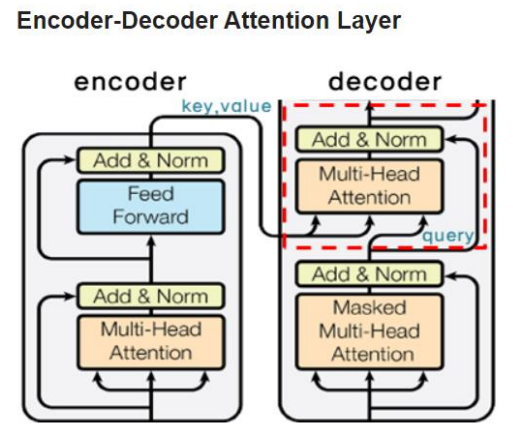
처음 나오는 MHA는 Query, Key, Value가 모두 같은 Self-Attention과 달리 Encoder의 출력값과 Decoder의 입력값을 이용하는 Encoder-Decoder Attention 이다.
t 시점의 예측에 도움이 되는 Encoder의 출력값들만 이용하고자 하는 것이 목적
Query는 Decoder의 Masked Self-Attention을 거친 입력값이, Key와 Value는 Encoder의 출력값이 된다.
