
학습 주제
lock을 이용해서 어떻게 concurrency control을 구현할 수 있는지 알아본다.
- write lock
- read lock
- 2PL(two-phase locking) protocol
Lock
실제 쓰기 작업(write)은 단순히 값만 바꾸는 작업이 아니다.
인덱스 처리, 파일 처리 등을 고려하면 그 내부 작동은 매우 복잡할 수 있다.
만약 같은 데이터를 read/write하는 트랜잭션이 있다면 예상하지 못한 문제가 발생할 수 있다.
이 문제를 Lock을 통해 해결할 수 있다.
운영체제의 lock과 유사한 개념으로 볼 수 있다.
데이터마다 lock이 있어서 특정 데이터로 작업을 하고 싶다면 lock을 취득해야 한다.
Lock의 종류
Lock의 종류로
write lock,read lock이 있다.

write lock은 이름만 보면 write를 위해서만 사용할 것 같지만 read도 포함하는 lock이니 주의하자.
그런데 두 lock의 특징을 살펴 보면 read에 대한 조건이 다르다.
무슨 의미일까?🤔
lock 호환성에 대해 자세히 알아보자.
Lock 호환성
아래 그림과 같이 read lock - read lock 간의 호환만 가능하고, 이 외의 호환은 불가능하다.
lock간의 호환이 가능하고 불가능하다는 말이 이해가 안 될 수 있다.
각 케이스별 예시를 통해 알아보자.

Write Lock - Write Lock
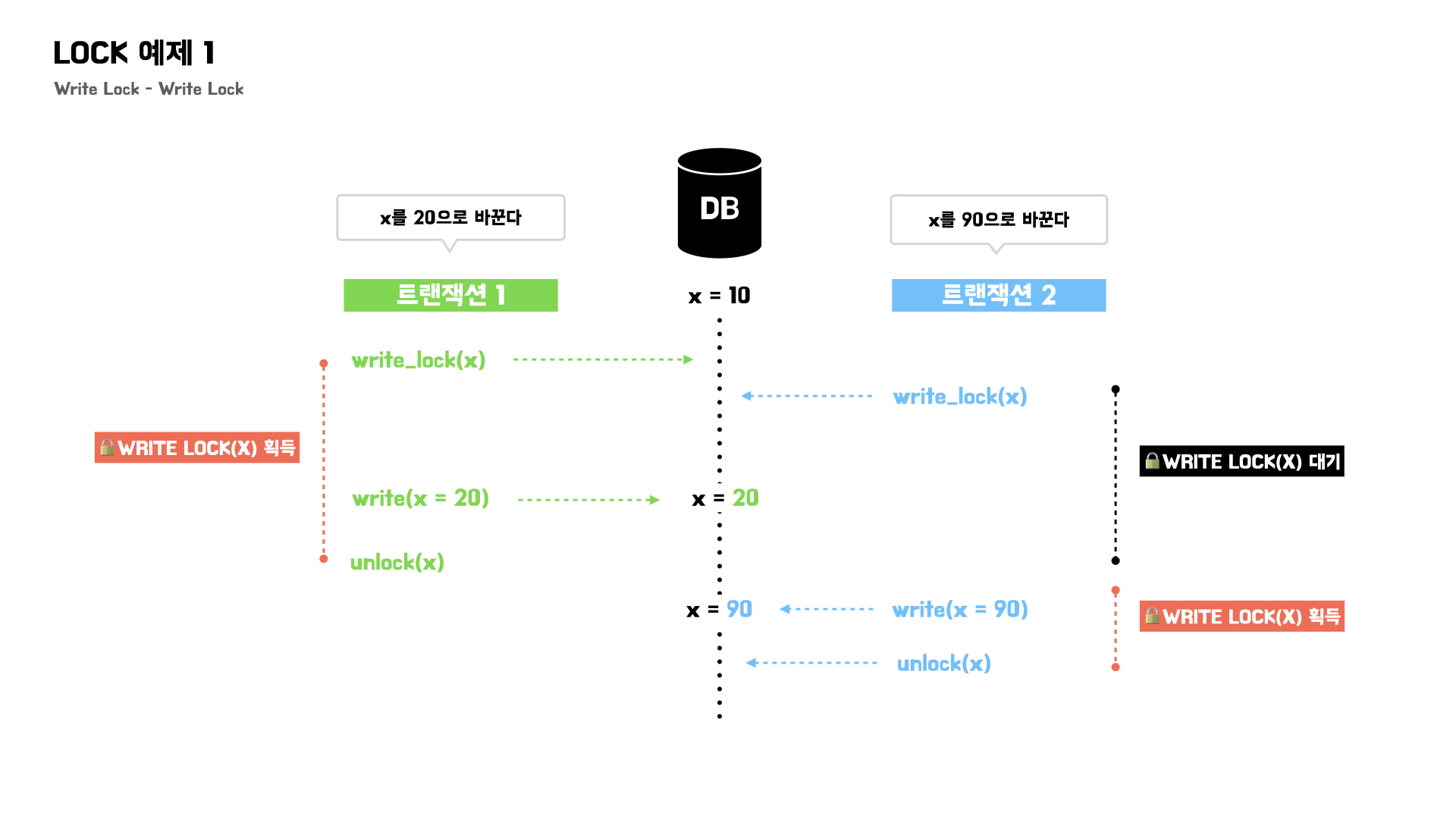
트랜잭션 1, 트랜잭션 2 모두 쓰기 작업을 해야하기 때문에 write lock이 필요하다.
하지만 write lock을 동시 취득할 수 없기 때문에, 트랜잭션 1이 write lock을 획득하면 트랜잭션 2는 요청 후 대기한다.
트랜잭션 1이 write lock을 반납하면 대기하고 있던 트랜잭션2가 write lock을 취득하고 작업을 진행할 수 있다.
그렇기 때문에 wirte lock - write lock 간의 호환은 불가능하다고 볼 수 있다.
Write Lock - Read Lock

트랜잭션 1은 쓰기 작업, 트랜잭션 2은 읽기 작업을 해야하기 때문에 각각 write lock, read lock이 필요하다.
트랜잭션 1이 먼저 write lock을 취득하고, 트랜잭션 2가 read lock을 요청한다.
동일한 lock을 요청한 것이 아니기 때문에 트랜잭션 2도 read lock을 얻을까? 생각해보자.
앞서 write lock은 write 뿐만 아니라 read에도 lock을 건다고 했다.
그렇기 때문에 read lock을 요청한 트랜잭션 2는 대기 해야한다.
트랜잭션 1이 write lock을 반납하면 대기하던 트랜잭션 2가 read lock을 획득하고 작업을 수행할 수 있다.
그렇기 때문에 write lock - read lock 간의 호환은 불가능하다고 볼 수 있다.
이번에는 동일한 예제로 순서를 바꿔서 생각해보자.
트랜잭션 2가 먼저 read lock을 취득하고, 트랜잭션 1이 write lock을 요청하면 어떻게 될까?🤔

앞선 예제에서 언급했던 것과 같이 write lock은 write, read에 대한 lock이기 때문에 똑같이 대기해야 한다.
마찬가지로 read lock - write lock 간의 호환도 불가능하다고 볼 수 있다.
Read Lock - Read Lock
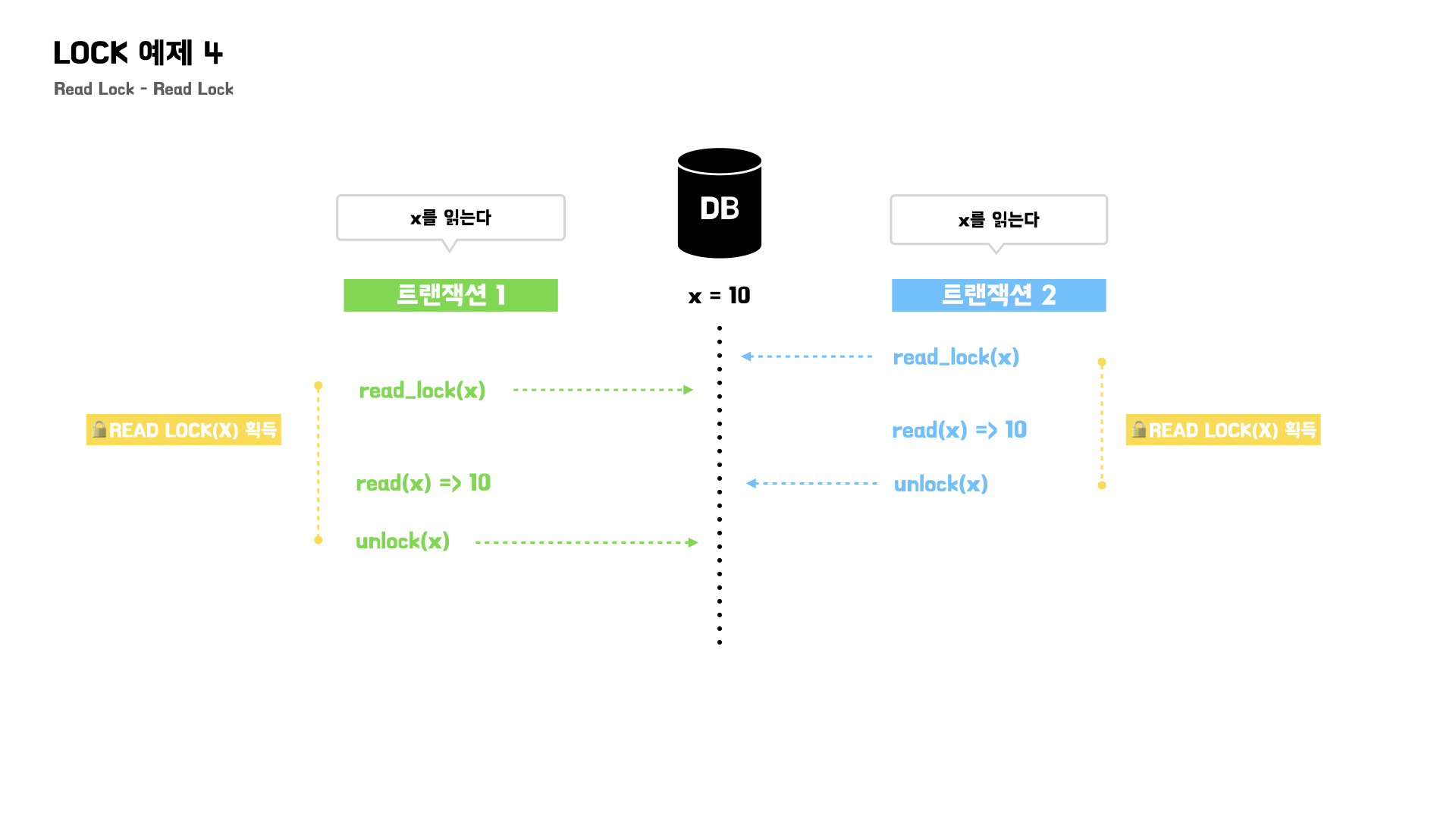
트랜잭션 1, 트랜잭션 2 모두 읽기 작업을 해야하기 때문에 read lock이 필요하다.
동일한 read lock을 요청하는 것인데 하나의 트랜잭션은 대기해야하지 않을까?🤔
그렇지 않다.
데이터를 변경하는 것이 아니기 때문에 문제될 것이 없으니, 동시에 read lock 획득이 가능하다.
그렇기 때문에 read lock - read lock 간의 호환은 가능하다고 볼 수 있다.
Concurrency Control 과 Lock
하지만 lock만으로 serializable 을 보장할 수 없다.
그럼 실제로 lock을 이용해서 concurrency control이 어떻게 구현될 수 있는지 알아보자.
lock과 이상 현상
예제를 통해 lock을 사용했음에도 발생할 수 있는 이상현상을 알아보자.
각 트랜잭션이 동작하는 순서는 아래와 같다.
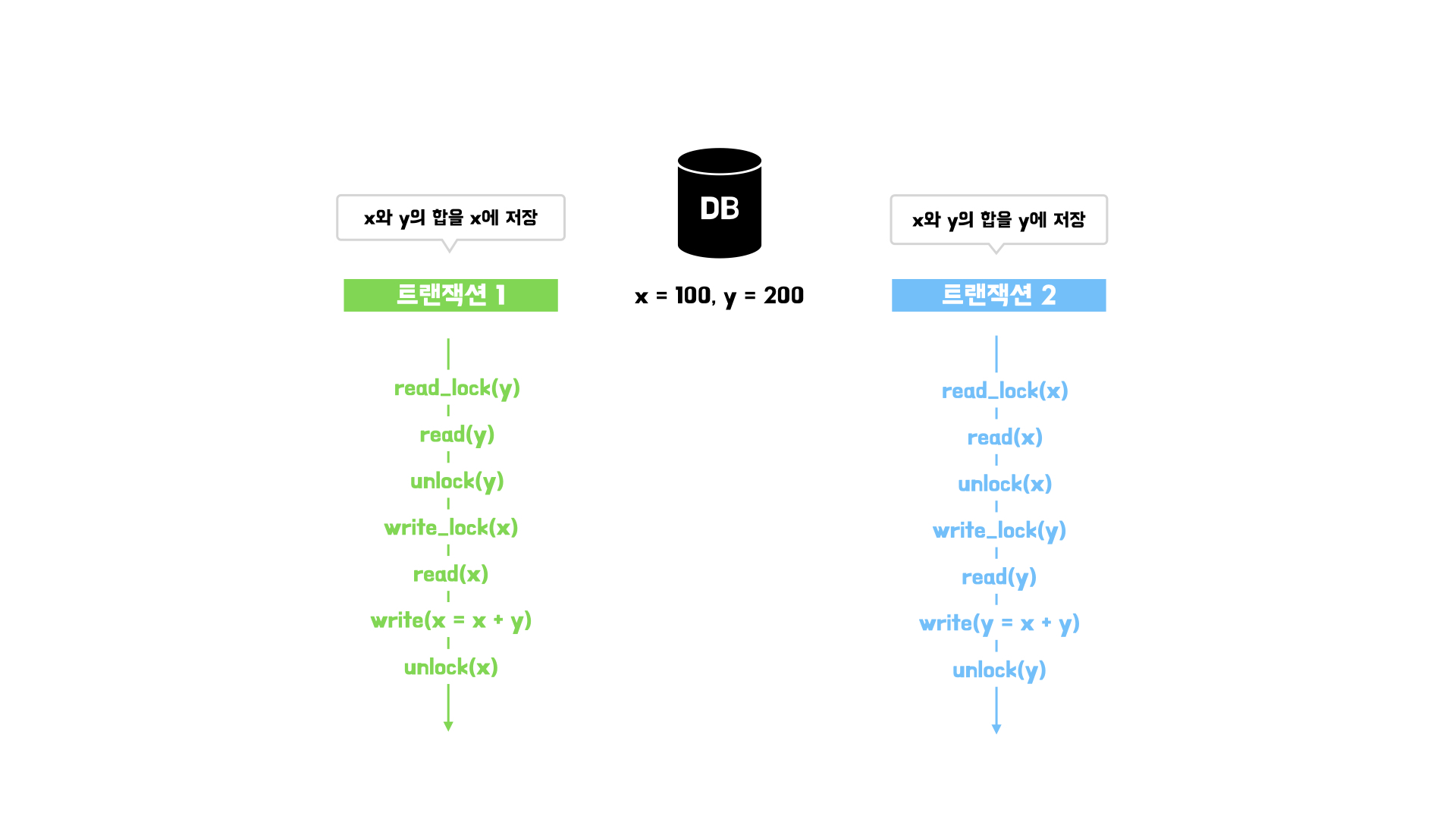
트랜잭션 동작 순서에 따라 어떤 결과를 가져올지 확인해보자.
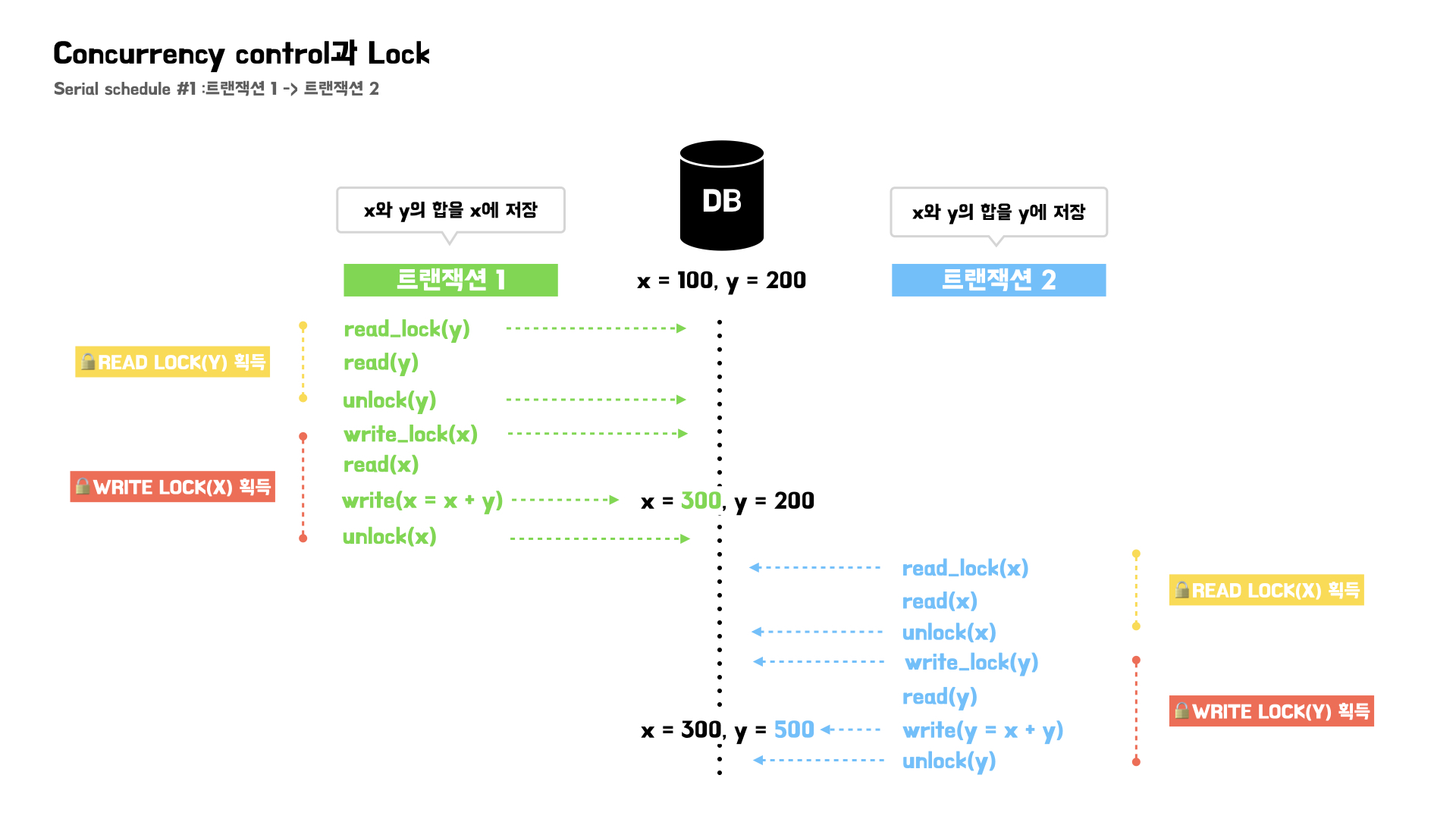
Serial schedule 1
트랜잭션 1의 동작들을 먼저 수행하고, 트랜잭션 2의 동작을 수행하는 스케줄을 먼저 확인해보자.
이 경우 최종적으로 x=300, y=500의 결과를 가져온다.
Serial schedule 2
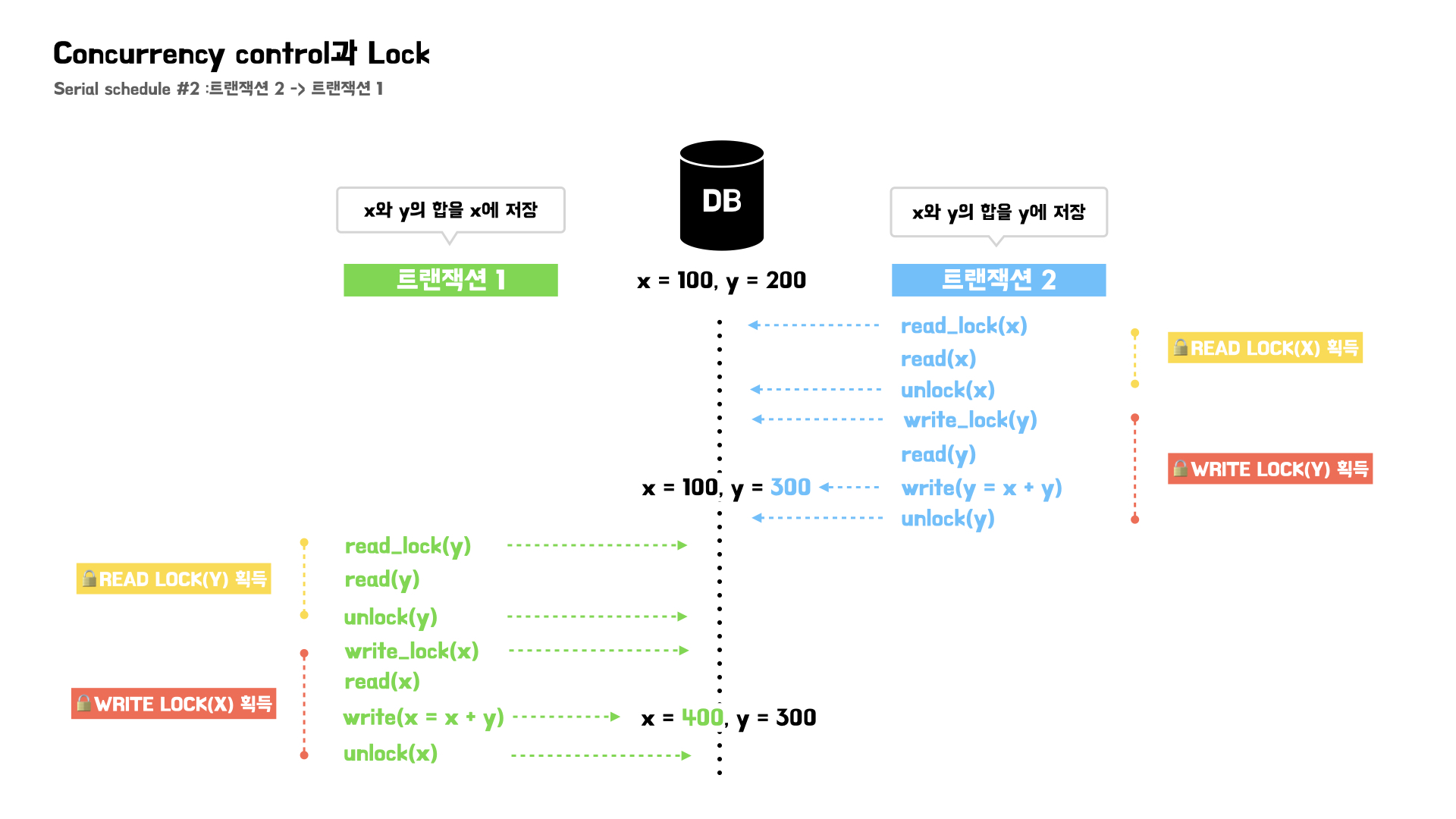
트랜잭션 2의 동작들을 먼저 수행하고, 트랜잭션 3의 동작을 수행하는 스케줄을 확인해보자.
이 경우 최종적으로 x=400, y=300의 결과를 가져온다.
Non-Serial schedule
두 트랜잭션의 operation이 섞여서 실행되는 스케줄을 확인해보자.
이 경우 최종적으로 x=300, y=300의 결과를 가져온다.
이 스케줄은 nonserializable schedule 이고, 이상 현상이 발생한 것이다.

트랜잭션 1은 업데이트 되지 않은 y를 읽고, 트랜잭션 2도 업데이트 되지 않은 x를 읽으면서 이러한 이상 현상이 일어난 것이다.
lock을 획득하기 위한 block 때문 발생한 문제인데, 그렇다면 lock을 모두 획득하고 작업을 시작하면 어떨까?
2PL Protocol(Two-Phase Locking)
앞선 문제를 해결하기 위한 방법으로 2PL Protocol을 사용할 수 있다.
2PL Protocol은 트랜잭션에서 모든 locking operation이 최초의 unlock operation 보다 수행되도록 하는 프로토콜이다.
한 번 unlock이 수행되면 다시 lock을 취득하지 않는다.
serializable 을 보장한다.
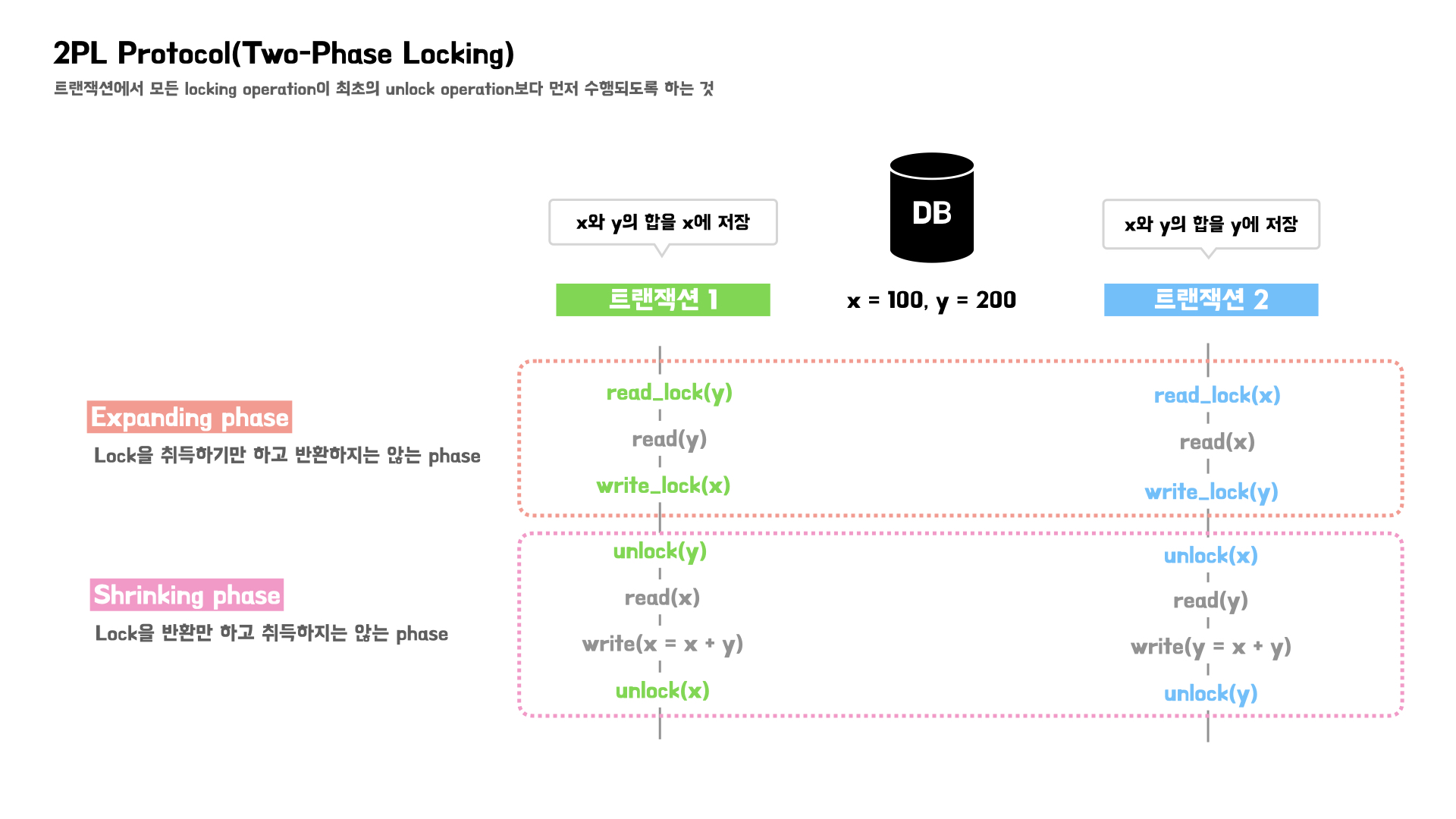
이름에서 나타나는 것 처럼 스케줄을 2개의 Phase를 구분한다.
-
Expanding phase(growing phase): lock 취득부
-
Shrinking phase(contracting phase): lock 반환부
2PL Protocol과 Deadlock
2PL Protocol을 사용하면 실행 순서에 따라서 특정 deadlock이 발생할 수 있다.
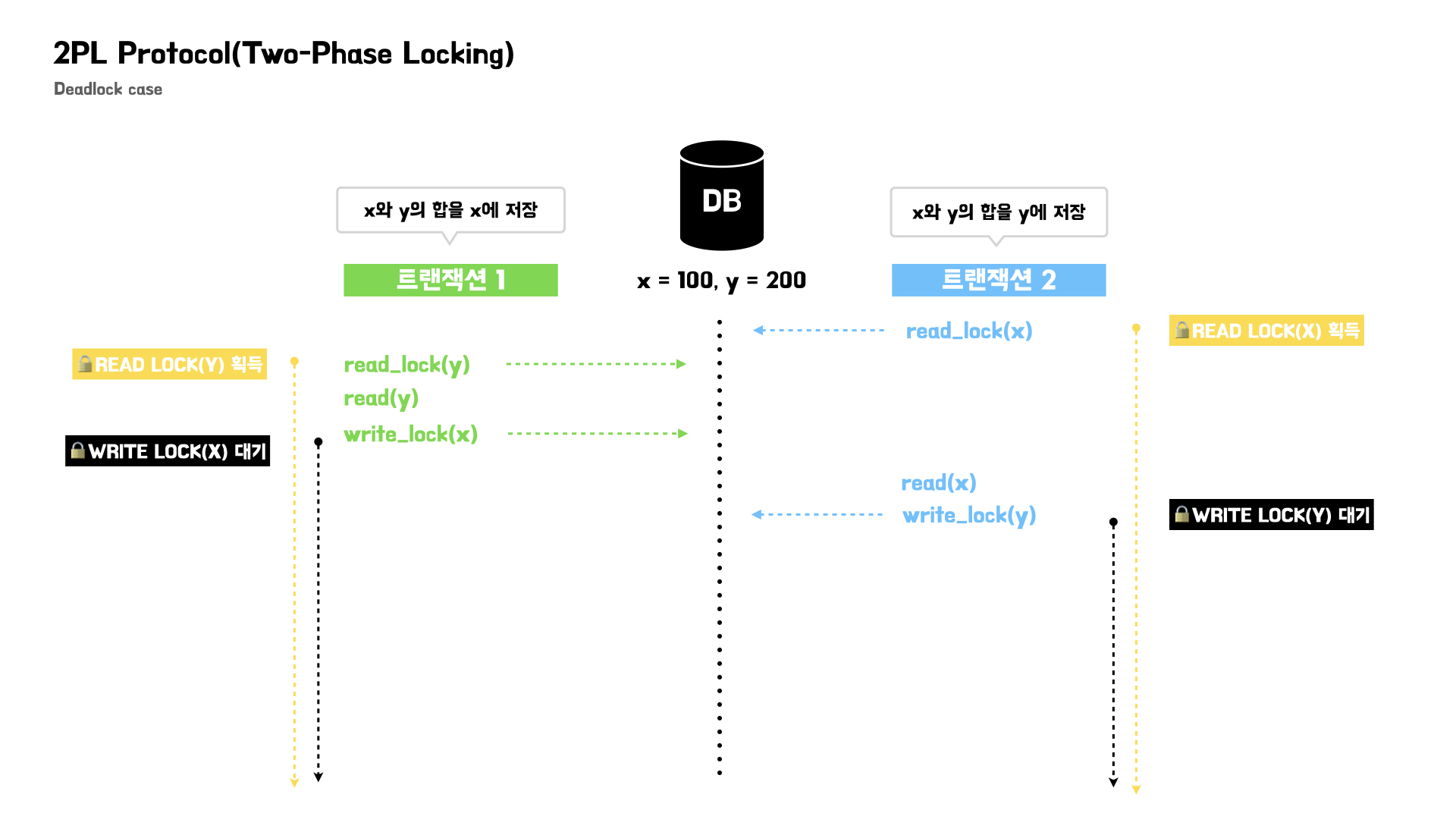
위 예시를 보면 트랜잭션1 은 x에 대한 write lock, 트랜잭션 2는 y에 대한 write lock을 획득하기 위한 무한정 대기가 발생한다.
이렇게 2PL Protocol을 사용할 때 deadlock이 발생할수도 있다.
(강의 영상에서는 해결방법까지는 다루지 않아서 넘어감)
2PL Protocol의 종류
-
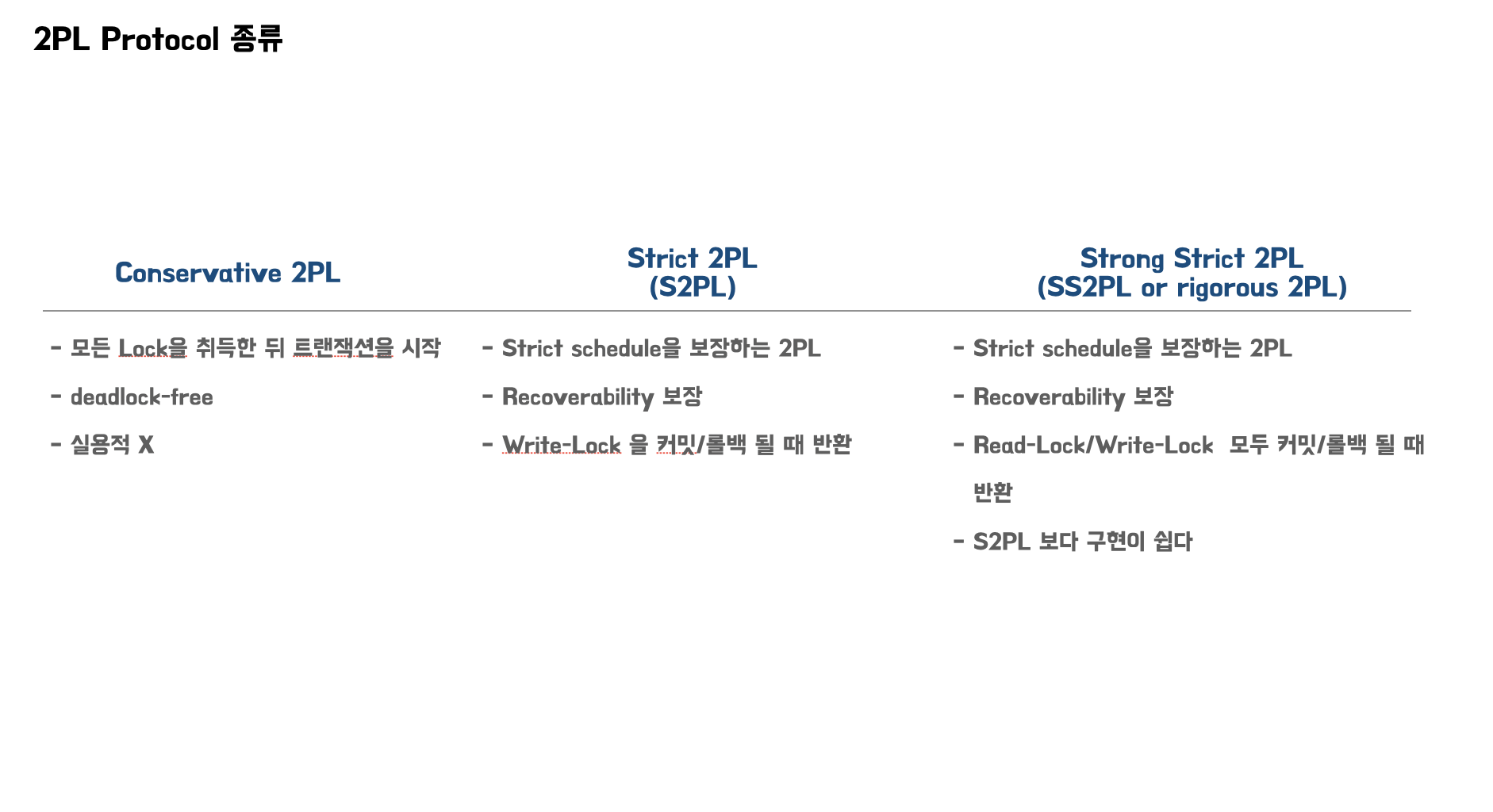
Conservative 2PL
- 모든 Lock을 취득한 뒤 트랜잭션을 시작한다.
- Deadlock이 발생하지 않는다.
- 모든 Lock을 취득해야 시작할 수 있기 때문에, 트랜잭션 자체를 시작하기 어려울 수 있다.
- 모든 Lock을 다 취득하기 어려운 상황들이 있기 때문에 실용적이지 못하다.
-
Strict 2PL
- Strict Schedule을 보장한다.
- Recoverability 를 보장한다.
- 트랜잭션이 커밋/롤백 될 때 write-lock을 반환한다.
-
Strong Strict 2PL
- Strict Schedule을 보장한다.
- Recoverability 를 보장한다.
- 트랜잭션이 커밋/롤백 될 때 read-lock/write-lock을 반환한다.
- S2PL 보다 구현이 쉽다.
- Lock을 오래 가지고 있기 때문에 다른 트랜잭션은 lock 획득이 늦어지는 단점이 있다.
초창기 RDBMS에서는 S2PL, SS2PL이 많이 쓰였다.
Lock과 MVCC
하지만 Lock 호환성을 이용한 2PL 방식은 문제가 있다.
read-read를 제외하고는 한 쪽이 block이 되니까 전체 처리량이 좋지 않다.
그리고 read-write가 서로를 block하는 것 만이라도 해결하고자 찾은 방법이 MVCC 이다.

현재는 많은 RDBMS 에서 Lock과 MVCC를 함께 사용하고 있다.
정리
- 정리하자면 트랜잭션의 isolation이 보장되기 위해 concurrency control이 이 존재한다.
- 그리고 이 concurrency control를 lock을 통해 어떻게 구현할 수 있는지 살펴봤다.
- 2PL 프로토콜을 따르도록 lock을 설계를 해서 RDBMS를 구현하면 그 concurrency control은 serializability를 보장한다.
- 초창기에는 Recoverability를 보장하기 위해서 Strict 2PL, Strong Strict 2PL를 사용했었고, 현재는 성능을 올리기 위해서 MVCC를 많이 적용한다.
참고 자료
