Proportional Share, Fair Share
반환시간이나 응답시간의 최적화 보다는, 스케줄러가 각 작업에게 일정비율의 CPU사용을 보장하는게 목적
아래 lottery scheduling, stride scheduling, CFS 등이 있다.
Lottery Scheduling
• 방법
다음에 실행될 프로세스를 추첨을 통해 결정
더 자주 수행되야 하는 프로세스는 당첨 기회를 더 많이 준다.
타임 슬라이스가 끝날 때마다 무작위적으로(deterministic하지 않게) 추첨함
• 장점
구현상의 장점은 다음과 같다
» 단순한 구현
구현에 필요한 것은 난수발생기, 프로세스들의 집합을 표현하는 자료구조(리스트 등), 추첨권의 전체 개수 뿐이며 코드 또한 간단하다.
무작위성 방식의 장점은 아래와 같다.
» 특이상황 대응
더 전통적인 방식이 잘 해결하지 못하는 특이상황에 잘 대응
» 적은 메모리 사용
관리해야 할 상태 정보가 거의 없으므로 매우 가벼움 (메모리 사용량 적음)
» 빠른 속도
매우 빠름, 난수 발생시간만 빠르다면 매우 빠르고 속도가 요구되는 많은 경우 사용가능, 속도 향상을 위해 추첨과정을 덜 무작위하게 (pseudo-random) 만들기도 함
• 무작위성의 단점
» 작업 비율의 부정확한 분배
길이가 짧을수록 무작위성은 원하는 비율을 정확히 보장하지는 않는다.
하지만, 작업이 장시간 실행될수록 원하는 비율에 수렴함 (아래 그림 참고)
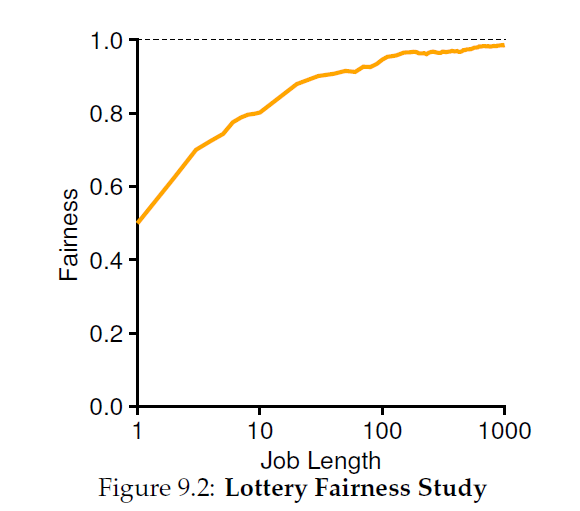
• Ticket
추첨권(ticket)은 프로세스에게 (또는 사용자 등등에게) 특정 자원을 할당할 수 있는 몫을 나타내며,
소유한 티켓수/전체 티켓수 가 자신의 몫이 됨
• Lottery Mechanism
아래 3가지 추첨기법은 어떤 프로세스와 작업 혹은 사용자 끼리 상호작용하는지에 따라 구분되며 순서대로 다음과 같다
- Self . sub -> Self
- Self -> Other
- Self -> Self
» Ticket currency
추첨권 화폐(Ticket currency)는 사용자가 시스템에게 부여받은 추첨권과 자신의 프로세스에게 분배한 화폐간의 가치를 자동으로 맞춰준다 (환전과 유사)
예를 들어
-
사용자 A,B가 각각 100장의 추첨권을 받고
-
A는 자신의 프로세스 a1,a2에게 자신의 화폐로 500, 500개의 추첨권을 할당하고,
B는 자신의 프로세스 b에게 자신의 기준화폐로 10장중 10장을 할당했다.
이 경우 a1,a2에게 부여된 A의 기준에서 500인 화폐는 전체 기준에 맞게 각각 추첨권 50장으로, b에게 부여된 B기준화폐 10은 추첨권 100장으로 변환된다.
» Ticket transfer
추첨권 양도(Ticket transfer)를 통해 프로세스는 추첨권을 다른 프로세스에게 넘겨줄 수 있다.
클라이언트/서버 환경에서 특히 유용하다.
클라이언트는 서버에 요청한 작업을 빨리 완료할 수 있도록 서버에게 추첨권을 잠깐 양도하여 서버 성능을 극대화하고,
요청을 완수하면 서버는 추첨권을 클라이언트에게 돌려준다.
» Ticket inflation
신뢰하지 않는 프로세스들이 상호 경쟁할땐 무의미하지만,
프로세스들이 서로 신뢰할 때 유용하다.
어떤 프로세스가 더 많은/적은 cpu를 필요로한다면 시스템에 이를 알려서 소유한 추첨권의 수를 조절함.
• Lottery Scheduling 구현
추첨 스케줄링의 가장 큰 장점은 구현이 단순하단 점이다.
난수발생기, 프로세스들의 집합을 표현하는 자료구조(리스트 등), 추첨권의 전체 개수 뿐이다.

일반적으로 리스트를 내림차순으로 정렬하면 이 과정이 가장 효율적이다.
(특히 적은 수의 프로세스가 대부분의 추첨권을 소유하고 있을 때)
• 추첨권 배분 방식
사용자가 추첨권을 어떻게 배분해야 할지 잘 알고있다고 가정하고,
각 사용자에게 추첨권을 나눠준 후 사용자가 알아서 작업들에게 추첨권을 배분한다.
Stride Scheduling (deterministic scheduling)
• 방법
보폭(stride)와 pass를 통해 결정론적 방법 사용
임의의 큰 값을 각 프로세스의 추첨권갯수로 나누어 보폭을 계산
한번 실행시 마다 프로세스의 pass를 보폭만큼 증가시켜 cpu사용량을 추적
스케줄러는 pass값이 제일 작은 프로세스를 선택해 실행
• 구현
curr = remove_min(queue); // pass값이 최소인 클라이언트 선택
schedule(curr); // 자원을 타임 퀀텀(=타임슬라이스) 만큼 선택된 프로세스에게 할당
curr->pass += curr->stride; // 다음 pass 값을 보폭 값을 이용해 갱신
insert(queue, curr); //curr을 다시 큐에 저장 • Stride vs Lottery
» cpu 분배
stride scheduling 은 CPU 분배를 정확하게 할 수 있다.
추첨방식은 적은 작업일수록 cpu 분배율이 비교적 부정확함
» 상태정보
추첨 스케줄링은 보폭(stride) 스케줄링과 달리 상태정보(cpu사용 현황, pass값 등)가 필요없다
» 새로운 프로세스 추가
보폭 스케줄링에서는 새로운 프로세스가 도착하면 pass값 설정이 문제가 된다.
새로운 프로세스에 pass값을 0으로 주면 프로세스가 도착할때 마다 새로 도착한 프로세스만 한동안 실행하게 된다.
반면, 추첨 스케줄링에서는 새로운 프로세스에 추첨권만 배분해주면 cpu 사용비율을 유지할 수 있으므로 추첨권 방식은 새로운 프로세스 추가가 쉽다.
리눅스 CFS (Completely Fair Scheduling)
부하에 잘 견디도록 확장성과 성능을 보장하는 스케줄러, 스케줄링 오버헤드를 최소화 하는것이 목표
• 기본 원리
스케줄링 오버헤드를 최대한 줄이는것이 현대 스케줄러의 목표
문맥교환 비용절감과 시스템 공정성간의 상충관계를 vruntime, sched_latency, min_granularity등의 변수들을 이용해 조정한다.
타이머 인터럽트에 근간해 작동함
또한, 타임 슬라이스 길이가 타이머 인터럽트 주기의 정수배가 아니라도 잘 작동
왜냐하면 vruntime을 정확히 계산해 이를 기반으로 스케줄링하므로 궁극적으로는 cpu를 공평하게 분배
CFS는 현재 프로세스의 타임 슬라이스 소진 후 가장 낮은 vruntime을 가진 프로세스를 선택해 실행
• Niceness (가중치)
CFS는 티켓이 아닌 nice레벨 사용 (UNIX의 고전적 메커니즘)
아래 그림은 nice에 대응하는 weight(가중치)를 나타냄 (nice가 낮을수록 높은 우선순위)

prio_to_weight[i]는 nice level -20 + i 의 가중치를 나타낸다.
이를 이용해 nice 레벨, 같은 nice레벨에서 프로세스간 우선순위를 고려한 스케줄링을 한다.
CFS에서 타임 슬라이스와 vruntime을 산출할때도 nice레벨에 따른 weight를 반영
» time slice

» vruntime
실제 process실행 시간을 측정후 niceness 가중치를 반영해 프로세스의 vruntime을 결정
vruntime은 실제 사용시간과 같은속도로 증가

1024는 nice level 0의 weight를 의미
» sched_latency
여러 프로세스가 cpu를 번갈아 사용할 때, cpu사용후 다시 스케줄 될때까지의 최대 시간간격
이를 프로세스들의 가중치를 적절히 반영해 프로세스의 타임 슬라이스를 결정
» min_granularity
너무 많은 프로세스가 실행중이라면 sched_latency를 너무 잘게 분배하느라 지나치게 많은 문맥교환 발생으로 인한 성능저하 위험이 있다.
이를 방지하기 위해 최소 타임슬라이스인 min_granularity를 정해놓고, 타임 슬라이스를 결정할 때 min_granularity보다 작은 값이 계산되면 최소한 min_granularity만큼의 타임슬라이스를 보장해준다.
• Red-Black Tree
균형 이진 탐색 트리의 일종, avl 트리에 비해 여유롭게 균형을 유지해 삽입과 삭제 속도가 보다 빠름
Red - Black Tree 모식도
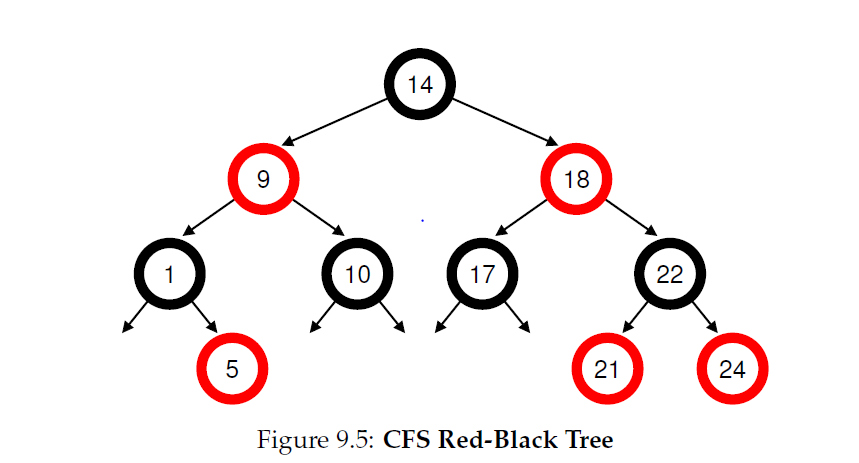
CFS의 알고리즘 효율성을 위해 사용하며, 실행중이거나 실행가능한 프로세스들만 보관
(프로세스가 sleep상태 (I/O대기 또는 네트워크 패킷 도착 기다릴때)가 되면 프로세스를 트리에서 제거하고 다른곳에 보관)
트리의 depth를 낮게 유지하기 위한 작업을 수행
탐색연산을 로그시간 O(log N)의 복잡도로 수행
• I/0, Sleep process의 처리
» 장기간 Sleep process로 인한 문제점
I/O대기 또는 네트워크 패킷 도착 등으로 인해 프로세스가 장기간 sleep하게 되면 vruntime이 다른 프로세스에 비해 뒤쳐지게 된다.
이로인해 장기간 sleep된 프로세스가 깨어나면 이 프로세스가 실행되느라 다른 프로세스가 기아상태에 빠지게 된다.
» 해결책
CFS는 이를 방지하기 위해 깨어난 작업의 vruntime을 트리에서 찾을 수 있는 가장 작은 vruntime값으로 설정한다.
» 해결책 장점
큰 오버헤드 없이 기아현상을 방지하고 문제를 해결가능
» 해결책 단점
짧은 시간간격으로 자주 sleep되는 프로세스는 cpu배분에 있어 손해를 보게됨
∵ 트리의 가장작은 vruntime보다 적은 cpu를 사용했지만 똑같은 사용시간으로 취급될 수도 있기 때문
• CFS 참고자료
The Battle of the Schedulers : FreeBSD ULE vs Linux CFS
by J. Bouron
: 리눅스 CFS와 Free BSD의 스케줄러를 상세히 비교한 연구
http://egloos.zum.com/rousalome/v/10002542
: 리눅스 운영체제 정리글
미해결 문제
• 입출력 요청이 잦은 프로세스에 불공정한 분배
입출력 요청이 잦은 프로세스는 상기 서술(cfs)과 같이 불공정한 분배를 받을 가능성
• 티켓이나 우선순위 할당방법
» 현재 방식
사용자에게 맞겨놓는 현재 방식은 사실상 해결책이 없어 선택한 차선책이다.
이 문제는 비례배분 스케줄러에서는 미해결 상태이다.
» 범용 스케줄러와의 비교
반면 범용스케줄러에 해당하는 MLFQ와 다른 유사 linux스케줄러는 문제를 더 직관적으로 해결하고 있고 더 널리 사용되고 있다.
» 배분 문제가 중요하지 않은 경우
배분 문제가 중요하지 않을 때는 비례배분 스케줄러들이 유용하게 사용된다.
예를 들어 가상화 데이터센터(혹은 클라우드)등에 윈도우 가상머신과 리눅스 시스템에 각각 cpu의 1/4,3/4를 할당하고 싶다면 비례배분이 간단하고 효과적이다.
.jpg)