학습내용
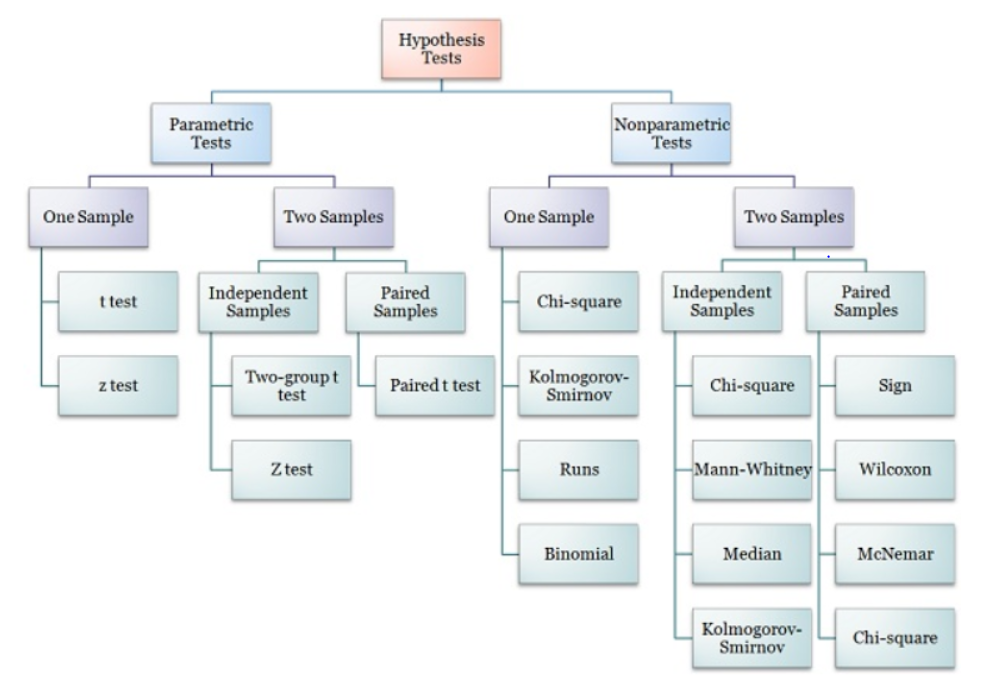
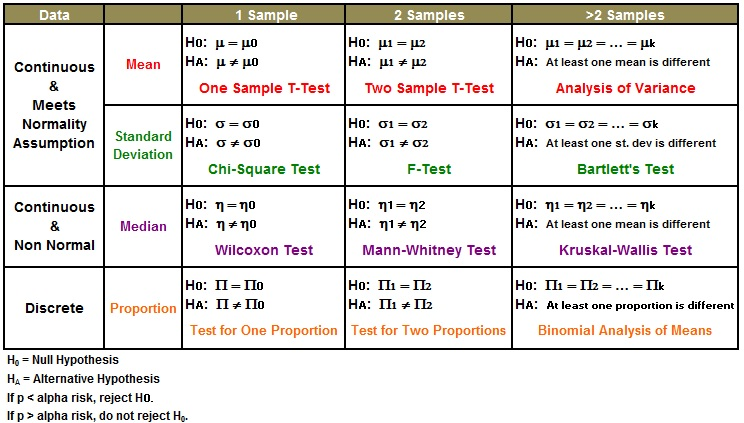
parametric methods, Non parametric methods
parametric methods : 가정된 분포의 모수에 대해 가설을 설정
Non parametric methods : 모집단이 특정 확률 분포를 따른다는 전체를 하지 않는 방식
Categorical 데이터를 위한 모델링
혹은 극단적 outlier가 있는 경우 매우매우 유효한 방식
distribution free method라고 부르기도 함.
ex)
- Kruskal-Wallis Test(비모수적 평균 비교)
x1 = [1, 3, 4, 8, 9]
y1 = [1, 4, 6, 7, 7]
kruskal(x1, y1)- scipy의 정규성 테스트
rom scipy.stats import normaltest
import numpy as np
sample = np.random.poisson(5, 1000) # normal 분포가 아님
normaltest(sample)
# null : 정규분포를 따름
# alternative : 정규분포를 따르지않음Chisquare test
분산비교(기대빈도??) test
주어진 데이터가 유사한 빈도를 나타내는지 확인하는 방법으로 사용
두 집단의 평균이 큰 차이가 없어도 그 평균의 변동이 크다면 결과를 신뢰하기 힘들기 때문에 검증시행
-자유도 : 해당 parameter를 결정짓기 위해 독립적으로 정해질 수 있는 값의 수
import numpy as np
from scipy import stats
#one sample chi-square test
obs = np.array([[18, 22, 20, 15, 23, 22]])
stats.chisquare(obs, f_exp = None ,axis = None) #원래 검증하려면 f_exp에 예측값을 입력해야함
#two way chi-square test, 두 변수간의 연관성이 있는지 없는지 판단해줌.
df = pd.DataFrame({}) #2개의 변수에 대한 crosstab
chi2_contingency(df, correction = False or True) #예이츠 보정의 목적(correction)은 통계적 유의성을 과대 평가하는 것을 막기 위한 것(특히 표본수가 작은 경우)
#result
#1 :chi2 statistic 2 : p-value 3 : degree of freedom 4 : expected value for Observed
#one sample chi-square test
v1 = [5,23,26,19,24,23]
def myChisq(value):
exp = np.array(value).mean()
values = np.power(value-exp,2)/exp
x2 = values.sum()
p_value = 1-stats.chi2.cdf(x2, df=len(value))
return p_value
myChisq(v1)import matplotlib.pyplot as plt
#카이제곱분포 그래프 표현
df = 5 # 자유도
x = linspace(0, 20, 50)
y = chi2.pdf(x,df) #x에 대응하는 카이제곱분포의 y값
plt.figure(figsize=(10, 6))
plt.plot(x, y, 'r--')
plt.show()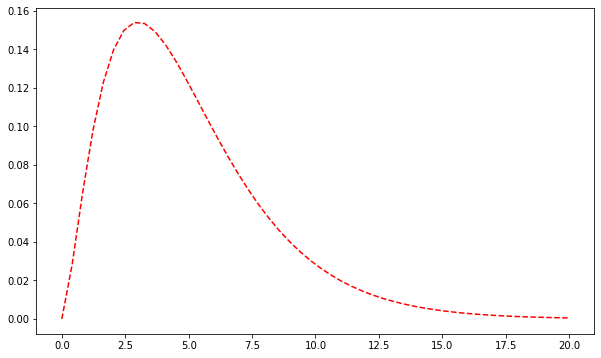
ANOVA
stats.f_oneway(group1, group2, group3)F 검정
- 분산분석(ANOVA)에서 F 검정을 사용, 평균을 비교하기 위한 수단으로 사용하는 것이지 F검정 결과를 직접 이용하지는 않는다.
- F검정은 분산을 비교할 때 사용. ex) 그룹1의 평균 5, 분산 2.0/그룹2의 평균5, 분산 2.1
두 그룹의 평균 차이가 우연에 의한 차이인지 유의한 차이인지를 비교