학습내용
관계형 데이터베이스
- 데이터 : 각 항목에 저장되는 값
- 테이블 : 행과 열로 구성되어 있는 체계화된 데이터
- 필드 : 테이블의 열
- 레코드 : 한 행
- 키 : 각 레코드를 구분할 수 있는 값. 기본키, 외래키 등
ACID
- Atomicity : 하나의 트랜잭션은 전부 성공 or 전부 실패
- Consistency : 트랜잭션 후 데이터베이스 상태는 이전과 같이 유효해야함.
- Isolation : 각 트랜잭션은 독립
- Durability : 로그가 남아야한다.
관계 종류
- 1:1
- 1:N : 흔히 볼 수 있는 관계, N쪽에 외래키를 가지는 경우가 많음
- N:N : 양쪽의 키본키를 가지고 있는 조인 테이블을 형성하여 1:N 관계로 만들어줌.
SQL
SQL : 데이터베이스 용 프로그래밍 언어
- Data Definition Language : 데이터 정의, CREATE DROP 등
- Data Manipulation Language : 데이터 저장, DELETE INSERT UPDATE 등
- Data Control Language : 데이터베이스 접근 권한, GRANT REVOKE 등
- Data Query Language : 쿼리 문법, SELECT 등 / DML의 일부로 말하곤 함.
- Transaction Control Language : 변경사항 수정, COMMIT ROLLBACK 등
많이 사용하는 SQL 작동 순서 :
1. FROM
2. WHERE
3. GROUP BY
4. HAVING
5. SELECT
6. ORDER BY
having과 where의 차이
having은 그룹화한 결과에 대한 필터
where은 그룹화하기 전에 작동하는 필터
# SQL 문법사용 예시
#1. SELECT, count, FROM JOIN, WHERE, GROUP BY, ORDER BY, LIMIT
SELECT c.CustomerId, c.FirstName, count(c.City) as 'City Count'
FROM customers AS c
JOIN employees AS e ON c.SupportRepId = e.EmployeeId
WHERE c.Country = 'Brazil'
GROUP BY c.City
ORDER BY 3 DESC, c.CustomerId ASC
LIMIT 3;
#2. || 값 합치기
SELECT
c.FirstName || ' ' || c.LastName AS 'Customer Name',
e.Firstname || ' ' || e.LastName AS 'Employee Name'
FROM customers AS c
JOIN employees AS e ON c.SupportRepId = e.EmployeeId;
#3. DISTINCT 특성 3개의 유니크한 조합 값들을 선택
SELECT
DISTINCT
특성_1
,특성_2
,특성_3
FROM 테이블_이름;
#4. CASE 파이썬에서의 if문과 같은 기능
SELECT CASE
WHEN CustomerId <= 25 THEN 'GROUP 1'
WHEN CustomerId <= 50 THEN 'GROUP 2'
ELSE 'GROUP 3'
END
FROM customers
#5. 서브쿼리는 소괄호로 감싸져있음, IN
#서브쿼리는 SELECT, FROM, WHERE 절 등에서 사용됨.
SELECT *
FROM customers
WHERE CustomerId IN (SELECT CustomerId FROM customers WHERE CustomerId < 10)
#6. EXISTS 서브뭐리의 존재하는 레코드를 확인, 레코드가 존재한다면 참
SELECT EmployeeId
FROM employees e
WHERE EXISTS (
SELECT 1 #레코드가 존재하는 것만 확인하면 되기때문에 1과 같은 무의미한 값을 지정
FROM customers c
WHERE c.SupportRepId = e.EmployeeId
)
ORDER BY EmployeeId클라우드 데이터베이스
URI 형식을 이용하여 연결을 많이한다.
URI : 인터넷에 있는 자원을 나타내는 유일한 주소
URI 형식
서비스://유저_이름:유저_비밀번호@호스트:포트번호/경로
EX.
서비스: postgres
유저 이름: admin
유저 비밀번호: password
호스트: databases.com
포트번호: 5432
경로 (혹은 데이터베이스 이름): main_dbelephantSQL 서비스를 이용하여 원격으로 postgres 데이터베이스에 연결하여 사용가능.
DOCKER를 이용하여 postgres
컨테이너 실행
$ docker run --name some-postgres -e POSTGRES_PASSWORD=mysecretpassword -d postgres
접속
$ docker exec -it some-postgres psql -h 호스트 이름 -U 유저이름
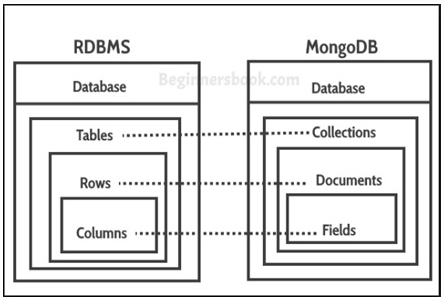
NoSQL
형식이 크게 정해져있지않은 데이터베이스
관계형 데이터베이스에서는 데이터를 쓸 때 스키마에 맞춘다면, NoSQL에서는 데이터를 읽어올 때 스키마에 따라 읽어옴.
NoSQL을 사용하면 좋은 상황
- 데이터의 구조가 거의 또는 전혀 없는 대용량의 데이터를 저장하는 경우
- 클라우 컴퓨팅 및 저장공간을 최대한 활용하는 경우
- 빠르게 서비스를 구축하고 데이터 구조를 자주 업데이트 하는 경우
클라우드 데이터베이스 연결
MongoDB Atlas를 이용하여 데이터베이스 생성
#데이터베이스 생성하여 titanic.csv 파일 데이터베이스 저장하기
import csv
import os
from pymongo import MongoClient
host = 'cluster1.vm90s.mongodb.net'
user = 'user'
password = 'password'
database_name = 'test_db'
collection_name = 'test_records'
MONGO_URI = f"mongodb+srv://{user}:{password}@{host}/{database_name}?retryWrites=true&w=majority" #URI 형태 구축
connection = MongoClient(MONGO_URI)
db = connection.test_db #데이터베이스 접근
db.drop_collection(collection_name) #collection 초기화
records = db.test_records #collection 접근
#collection에 데이터 추가
def add_data():
data = []
with open('titanic.csv') as file: #csv파일 open
filereader = csv.DictReader(file) #dict형태를 하나씩 리스트에 저장시켜 json형태로 만들어줌.
for row in filereader:
row['Survived'] = int(row['Survived'])
row['Pclass'] = int(row['Pclass'])
row['Age'] = float(row['Age'])
row['Siblings/Spouses Aboard'] = int(row['Siblings/Spouses Aboard'])
row['Parents/Children Aboard'] = int(row['Parents/Children Aboard'])
row['Fare'] = float(row['Fare'])
data.append(row)
return data
data = add_data()
records.insert_many(data) #json 형태로 데이터 한번에 저장가능.
#insert_one으로 데이터 하나만 저장가능
#records.find_one()으로 document 하나 불러오기 가능